MySQL表的增删改查--你都知道吗?

@[toc]
注释:在SQL中使用 --(空格) + 注释内容 来写注释
CRUD
crud就是增加(create) 查询(retrieve) 更新(update) 删除(delete)四个单词的缩写
###插入
insert into 表名 values (值,值,值…); --(注释) 一次插入一条记录
增加的值的类型要与创建表时的数据的类型匹配
insert into 表名 values(值,值) , (值,值); – 一次插入多条记录
一次插入多行操作的效率比一次插入一条,插入多次要更加快
==待定==(这里要添加一个超链接)
要是输入中文发现报错就说明当前MySQL不支持中文,需要手动修改配置文件来改变字符编码(一劳永逸的办法)
方法二 :
在创建数据库时可以指定字符编码方式
eg: create database customer character set utf8;(每次都要)
insert在指定的列中插入(可以是某一列 也可以是 多个列) 中插入 一个或者多个值
insert into 表名(列名 , 列名) values(值,值);

insert 一次插入多行记录
insert into 表名 values(2,“喜洋洋”),(3,“美羊羊”); //结合上述的demo表
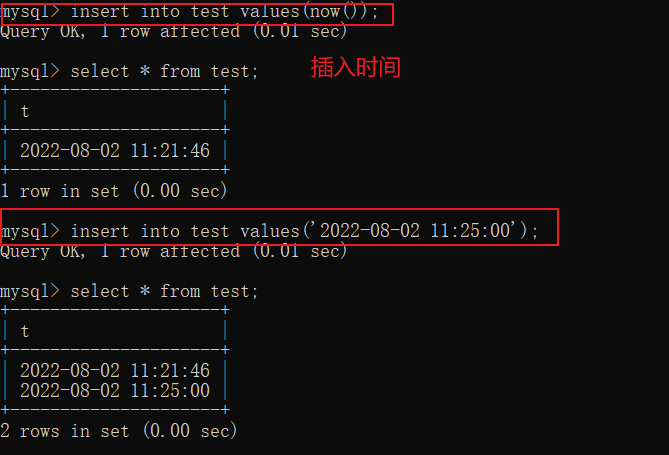
插入日期
首先先创建一个表
create table article(
articleName varchar(20),
create_date datetime
);
插入数据
insert into article values("第一",'2019-1-3 10:34'),
("第二",'2018-12-5 14:45'),
("第三",'2019-3-4 16:34');-- 日期一定要用''引起来
查询
SQL中使用 select 来查询数据
1.全部查找 (查找表中所有的行和列)
select * from 表名 ;
这个命令是十分危险的,select * from 表名,会让服务大规模读取磁盘上的数据,再把数据通过网卡传给客户端
一旦数据太大, 就很有可能把磁盘带宽和网卡带宽直接挤爆,甚至有可能把服务器卡死,无法响应其他的客户端的请求
2.查询某些列的数据
select 列名,列名 from 表名;
相比于上述的全部查询,这里的指定列查询的数据量就会更加小了
查询完显示对应的列之后,展示的只是一个临时表
所有的查询数据都不会改变原本表的数据
3.表达式查询
一边查 一边计算
这里只是临时表展示,并会不改变原本的数据
第三点续: 表达式查询还可以列与列之间进行计算

有上面的图片可以看出来,列名就是临时表的列名
4.给查询结果的列起别名
select 表达式 as 别名 from 表名
5.查询的时候进行去重
在列名之前使用 distinct 去重, 就会对这个列中的数据去重
select distinct 列名 from 表名;
去重也能针对多个列进行去重
但是只有说多个列对应的数据都是一样的,才能实现多个列去重
6.排序(列中数据排序)
升序:select 列名 from 表名 order by 列名;
降序:select 列名 from 表名 order by 列名 desc;
此处的desc是descend, 降低的意思
之前描述表的结构的关键字 desc 是 describe
按语文成绩升序排列
按语文成绩降序排列
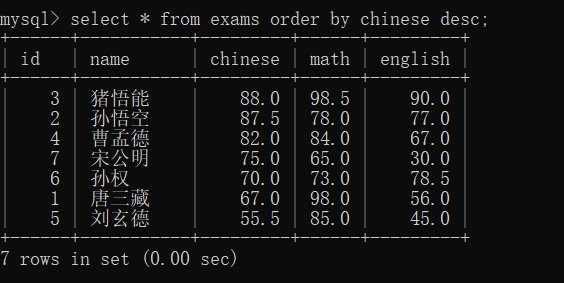
排序还能指定多个列进行了优先级排序
指定多个列的时候,那个列靠前,哪个列的优先级就高
升序:select 列名 from 表名 order by 列名,列名;
降序:select 列名 from 表名 order by 列名 desc,列名 desc; (各自都要降序desc)
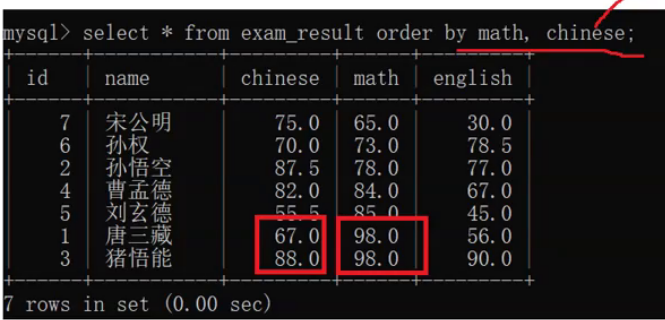
会先按照math进行升序排列,要是发现有两行的数据是一样的,就会按照chinese比较,按照升序输出,存在优先级
降序:
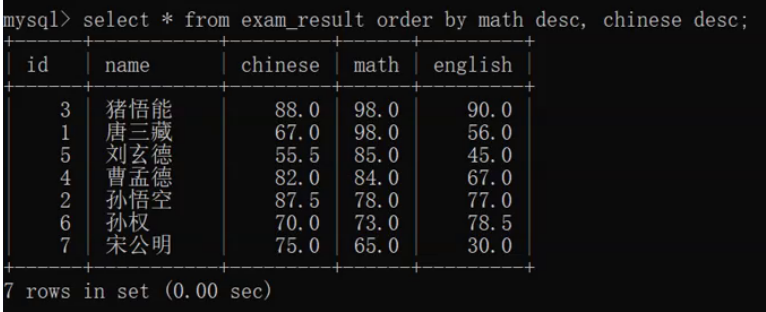
7.条件查询
select * from 表名 where 条件
条件比较多
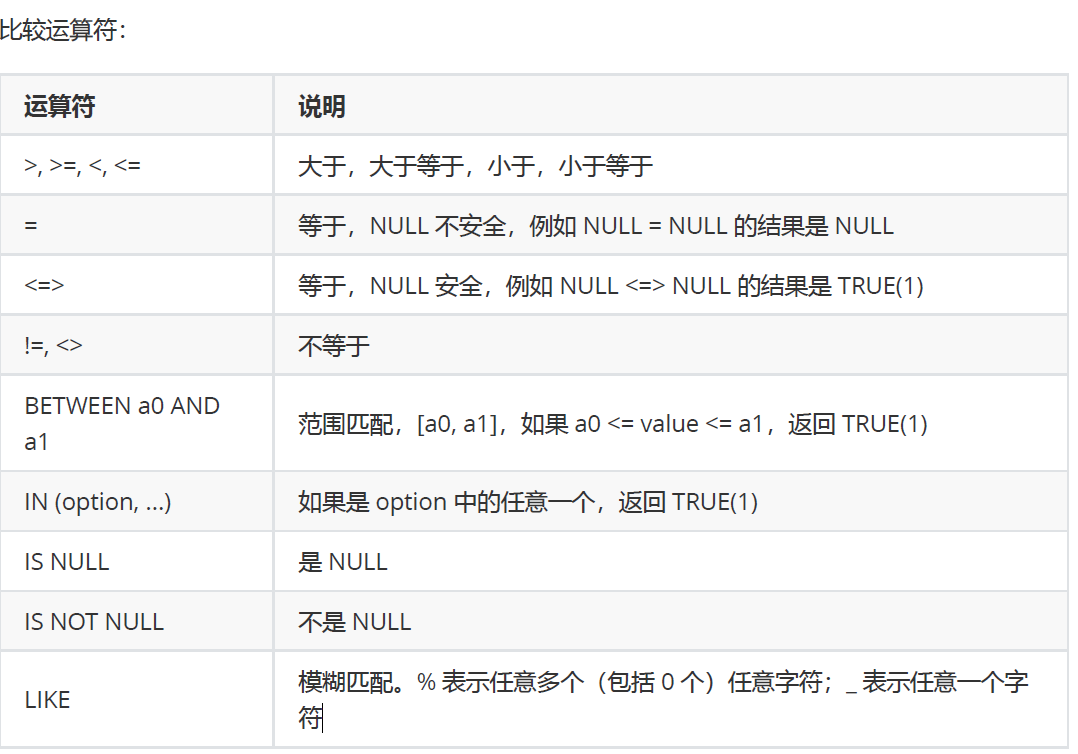
条件查询会先执行,所以不能使用别名
and 比 or 的优先级 高,所以一条语句中同时有and 和 or ,优先执行and
要是想要改变优先级,就加括号
判断是不是空的时候,用的是is null 或者 is not null, 不要用 !=
举例:
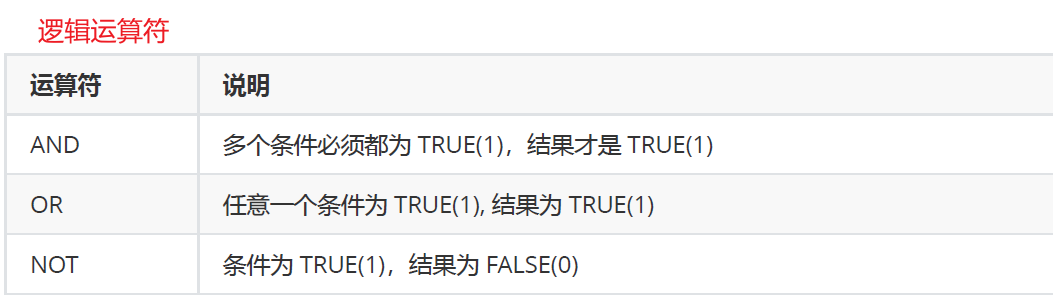
英语成绩不及格的人
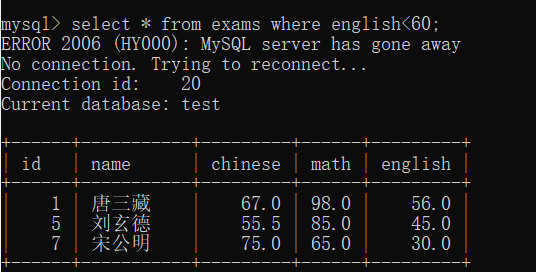
语文成绩好于数学成绩的人

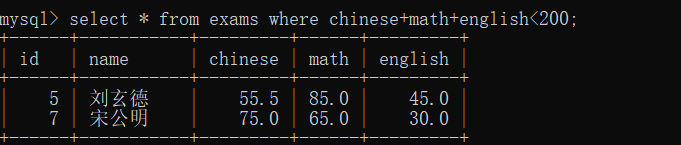
三门成绩之和小于200的人

条件查询是先进行条件判断,再查询数据
所以不认识 total 别名, 要是使用了as 来设立别名就会报错
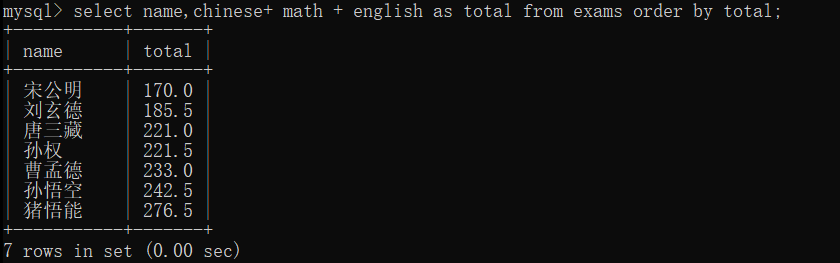
之前的排序就是属于先执行前面,再进行排序,所有可以使用别名
查询语文成绩大于80,并且数学成绩大于80的人
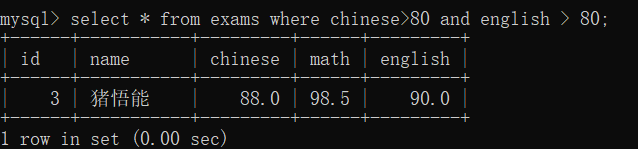
查询语文成绩大于80 或者 数学成绩大于80
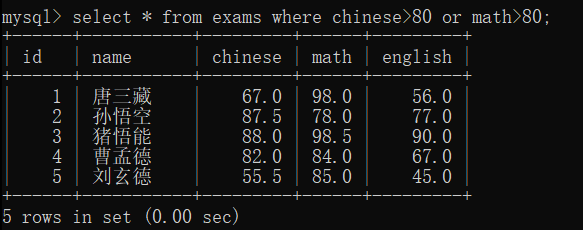
and 和 or 的优先级问题
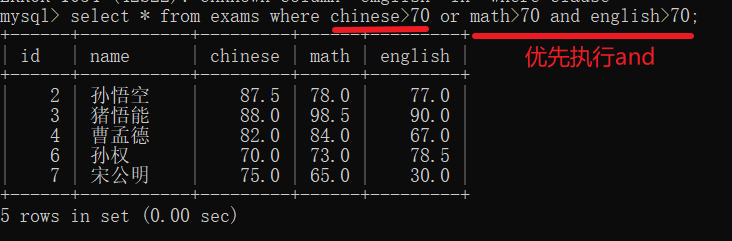
查询语文成绩在80到90之间的人
模糊搜索 like

在进行模糊搜索的时候,% 代表任意多个(包括0个)任意字符 , _ 表示任意一个字符,两个符号存在区别
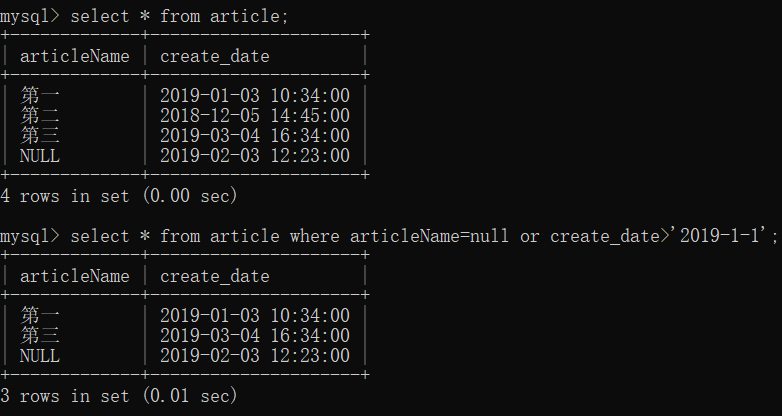
查询日期
select * from article where create_date between '2019-01-01 10:30' and '2019-11-10 16:02';
查询文章名为空或者日期为2019年1月1日之后的文章
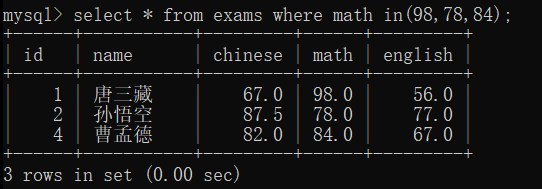
查询包含的指定的数据 (in)
like 模糊查询 依赖一些通配符来表示要匹配的值的形式
% 代替任意个任意字符(可以是0个字符,也可以是1个字符,还可以是多个字符)
_ 代替一个任意字符
null = null (等于) 结果还是null,也就是false;所以就查询不出来
举例:(孙尚香)
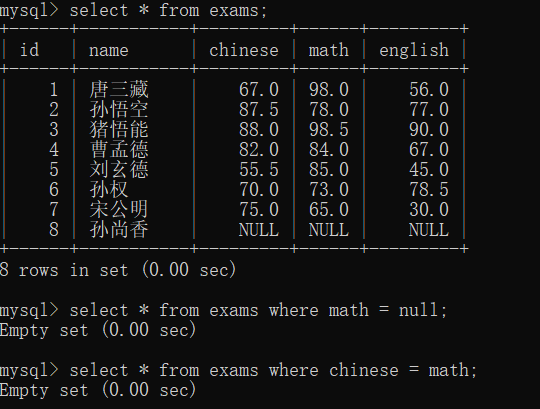
遇到这种情况就可以使用<=>来判断
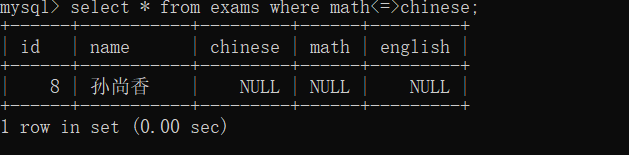
也可以使用is null 和 is not null 来判断null,但是这两种只能判断是否为空的情况 ,<=>适用的范围更广(<=>判断相等)
8.分页查询
有些网站的数据量比较大,一次展示不完,就可以分成多页来展示,limit后面是显示的条数
select * from 表名 limit N; 查询前 N 条 记录
select * from 表名 limit N offset M; 从M条记录开始(不包括第M条记录),查询N条记录
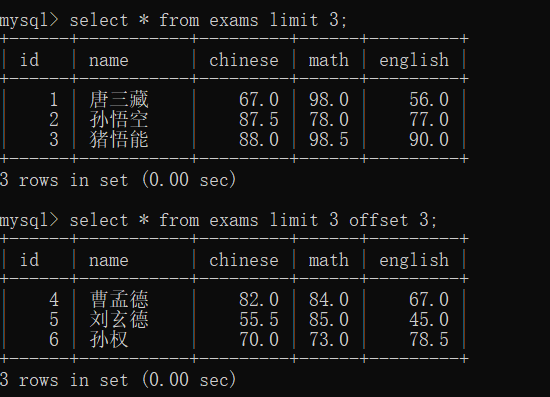
找出总成绩前三名的同学

找出总成绩前三名的同学(排除猪悟能)

需要注意顺序,代码的执行顺序与写的顺序没有关系(条件查询的优先级很高)

修改
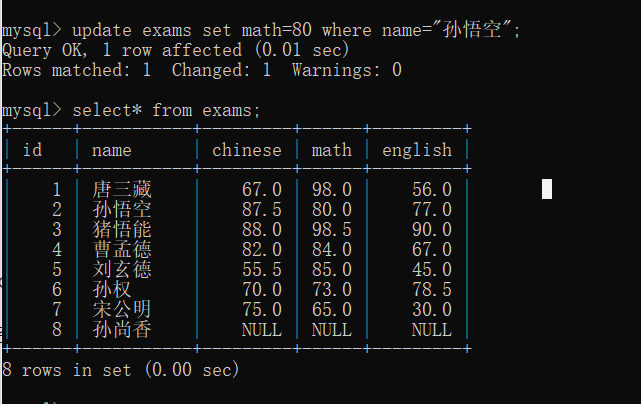
修改就是update
update 表名 set 列名=值,列名= 值 where 条件
将孙悟空的数学成绩改成80分
删除
delete 删除
delete from 表名 where 条件 ; 删除记录
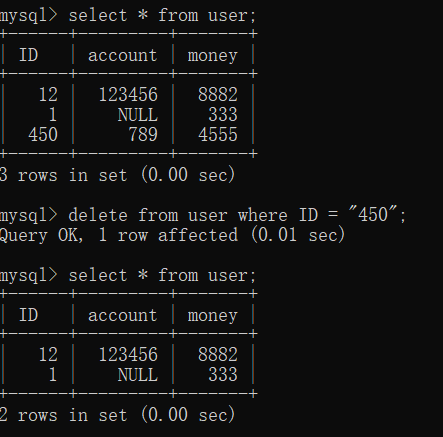
要是后面没有where 条件,就相当于把表清空了
delete 只是把表中的记录删了
drop就是连表和记录都删掉了,但是这两个的差别不大,两者都是十分危险的操作
在数据库中,select 查询是最复杂的,接下来就要学习一些MySQL的进阶操作
数据库约束
数据库中的数据十分的重要,所以一定要对数据库中的数据进行检查,这就是数据库约束
1.not null 创建数据库的时候,在变量类型后面加上, 确保变量不是null

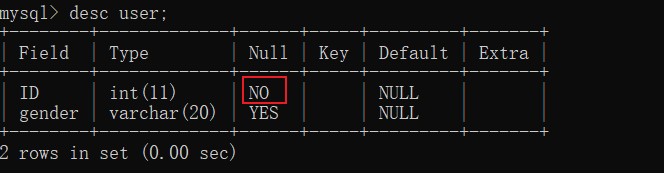

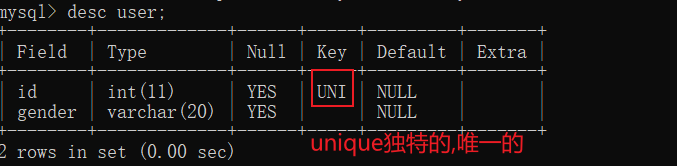
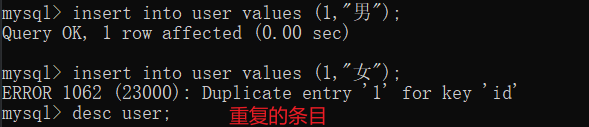
2.unique 值唯一 ,每次插入的时候都会去遍历查看表中有没有相同的数据,要是有的话,就不能插入

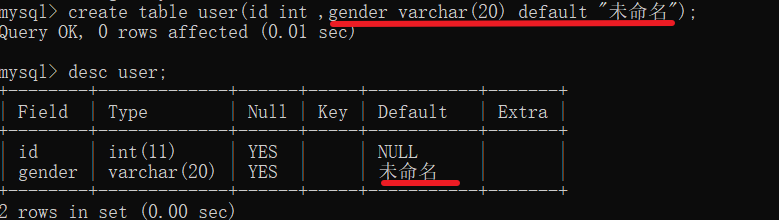
default 值 修改默认值
本来表的默认值是null,可以通过default 来修改默认值
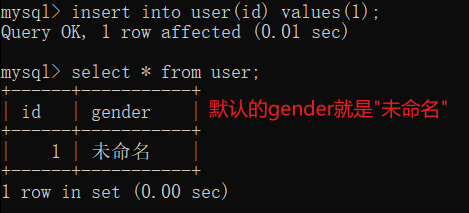
主键 primary key 主键用于身份的标识
主键 primary key 必须是非空的且是唯一的(not null 和 unique 的结合)
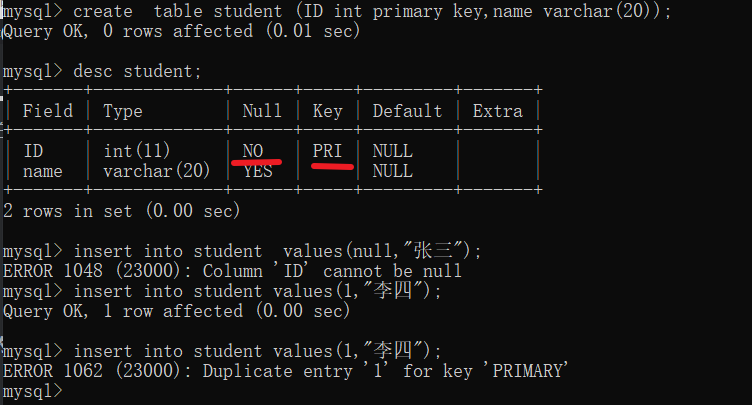
在primary key 后面加上auto_increment 就能实现MySQL的数据自增(自增主键机制) , 这样子插入数据的时候就不必手动设置值了,只要将这列设为null即可由数据库自动分配
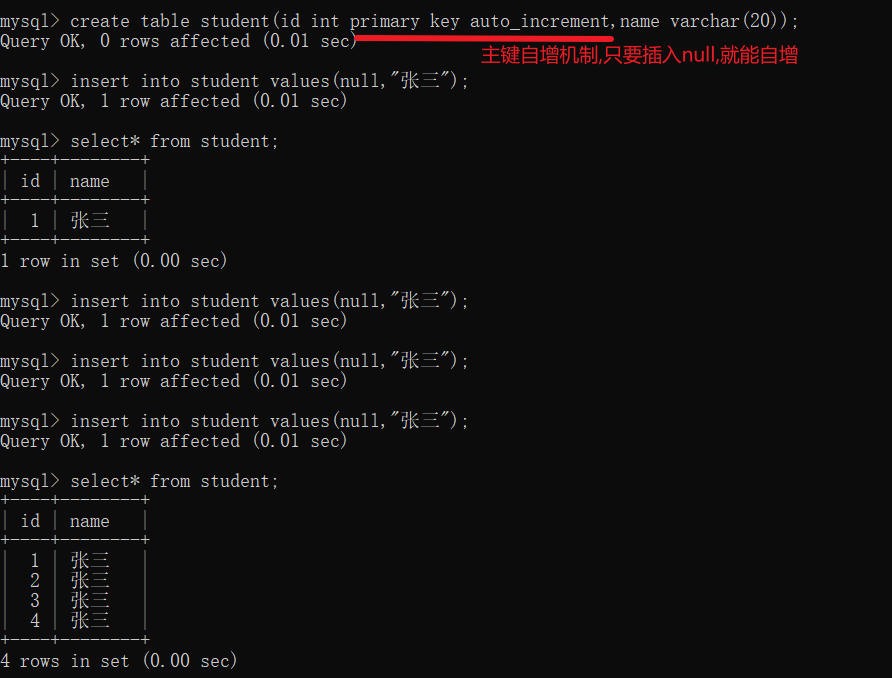

填成null就会自动分配,要是填成别的数,也能接着继续增加
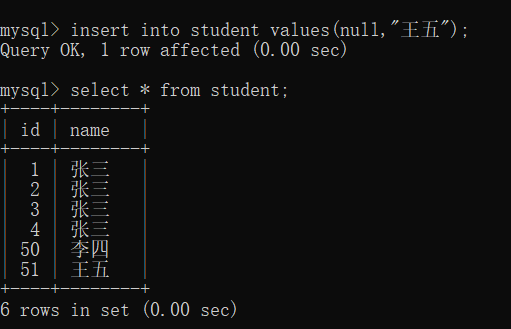
自增主键可以理解为是在MySQL中记录了,要是再插入null自增, 当前最大的id是多少,就在最大值后面继续增加
数据库分布式部署: 数据太多,一台服务器放不下,使用多台机器
分库分表:表太大,就可以拆成两个或多个表,分别在不同的主机上,搭建不同的mysql服务器,每个服务器存储其中的一份
对于分库分表的数据来说,从逻辑上还是同一张表,只是存储在不同的机器上,此时,原有的自增主键就失效了,mysql的自增主键保证单机上数据不重复,不能保证分布式部署时不重复
分布式系统生成唯一ID的方法:
生成公式 = (时间戳 + 主机编号 / 机房编号 + 随机因子) => 计算哈希值
理论上无法保证随机因子一定是随机的,但是在实际中随机因子冲突的概率是很低的,所以在工程中可以忽略不计
foreign key 外键约束

要使用外键,必须要保证子表引用父表的那一列,一定要是primary key 或者是 unique
班级表(约束别的表) – 父表
学生表(被约束的表) --子表
当外键约束建立好了之后,要想在学生表中插入记录,classId就一定要在班级表中存在
所以班级表对学生表产生约束
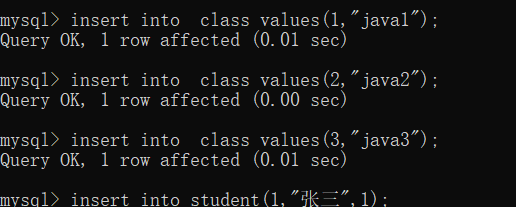

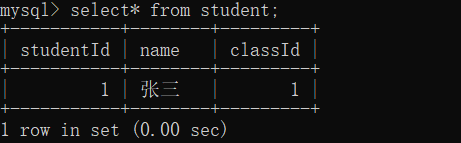
外键约束下,插入数据,会触发查询
往学生表中插入新纪录,就会自动在班级表中查询,看classId是否存在,要是不存在就插入失败,这就是父表对子表的约束
相同的,子表其实对于父表也是由约束的
在子表存在的情况下,要是直接删除父表,就会报错
要是子表中已经引用(使用),父表也是删除不了的
一个实际的问题:(用到了外键 逻辑删除)
卖一件商品在淘宝店铺,订单表就多了一条记录,过了一段时间,商家想要下架该商品,就要把
这个商品的goodsId删除,但是订单表(子表)中依然有goodsId,无法直接删除商品表(父表) 的goodsId , 此时该怎么办?

逻辑删除 : 在电脑中的删除,并不是直接将内容清空,而是将数据标记为"失效",所谓的删除只是对标记为进行了修改
所以,只要在商品表增加一列valid , 要是商品有效,值就是1,无效就是0,这样就可以做到上架下架
数据库的设计
XX项目中,数据库是如何设计的?
这就是在问数据库中有几个表,这些表都是干什么的?每个表中有哪些列,这些列都是干什么的?
数据库设计的主要思路:
- 根据需求,找到"实体"
- 梳理清楚实体之间的关系
所谓的实体类似于面向对象编程设计,"对象"就是需求中的关键性的名词
实体之间的关系有哪些?
一对一关系
一对多关系
多对多关系
没有关系
一般来说,每个实体都会安排一个表
具体实例:

-- 学生与宿舍 m:1
-- 宿舍查房与宿舍 m:1
-- 谁是1谁就会被约束,所以dormitory会在最前面
create table dormitory(
id int primary key,
num varchar(20)
);
create table student(
id int primary key,
name varchar(20),
dorm_id int,
foreign key(dorm_id) references dormitory(id)-- 上面的宿舍就是被约束的
);
create table exam(
id int primary key,
time_date timestamp,--记录考勤的时间
dorm_id int,
foreign key(dorm_id) references dormitory(id)
);

-- 用户和车 1:m
-- 车和违章记录 1:m
-- 题目中表示用户和车都被违章记录约束
create table user(
id int primary key,
name varchar(20)
);
create table car(
id int primary key,
num varchar(20),
user_id int,
foreign key(user_id) references user(id)
);
create table info(
id int primary key,
name varchar(20),
user_id int,
car_id int,
foreign key(user_id) references user(id),
foreign key(car_id) references car(id)
);

-- 食堂与仓口 1:m
-- 仓口与收费 1:m
-- 被约束的是1,所以canteen在最前面
create table canteen(
id int primary key,
name varchar(20)
);
create table hatch( -- 食堂仓口表
id int primary key,
name varchar(20),
canteen_id varchar(20),
foreign key(canteen_id) references canteen(id)
);
create table money(
price int primary key,
name varchar(20),
hatch_id varchar(20),
foreign key(hatch_id) references hatch(id)
);
SQL的新增
插入查询的数据
可以将查询的数据插入到另一个表中
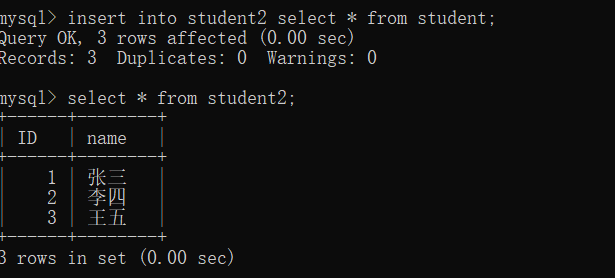
将student的数据插入到student2中

将student中符合条件的数据插入到student2中
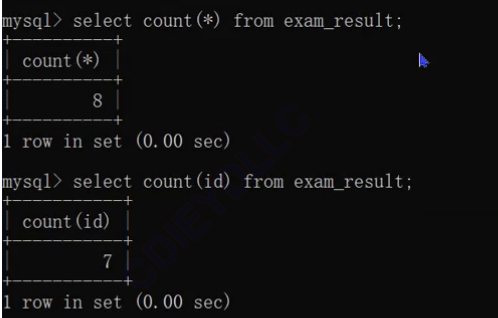
聚合查询
查询时带表达式–把行和行放到一起进行计算
聚合查询–SQL中提供了一些函数,通过这些函数,就能进行 行和行的计算
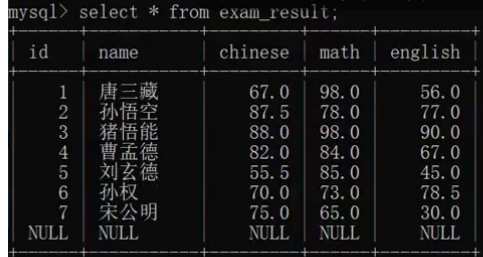
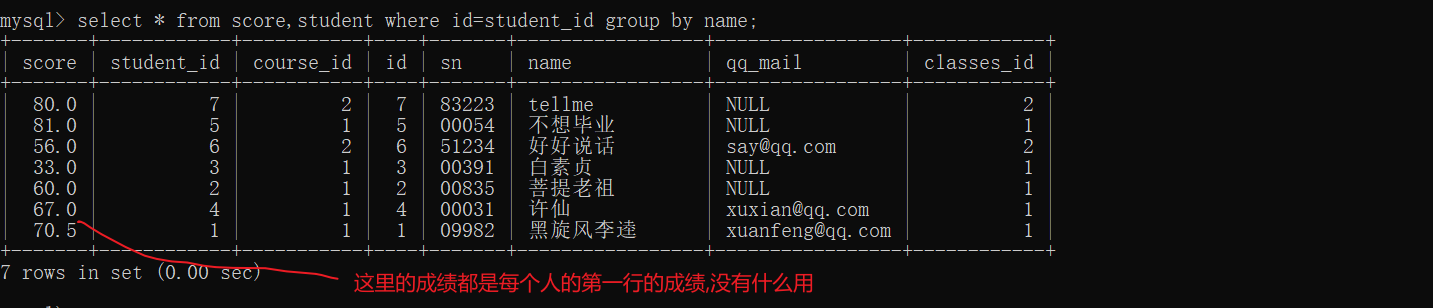
分组查询
group by 列名; – 按照列名分组
根据查询结构,进行分组
根据列名,将值相同的记录分成一组,然后就可以用聚合函数进行数据的聚合了
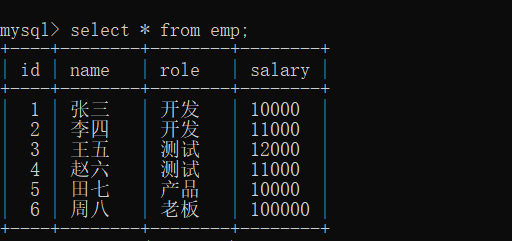
建立一个表
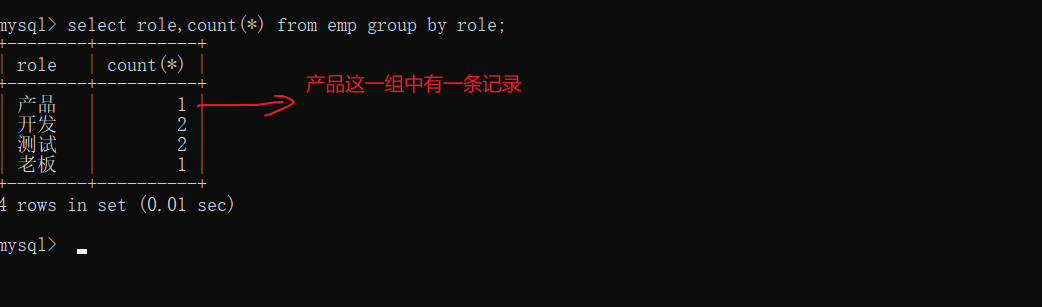 按照职位进行分组,针对分组后,求每一组关于工资的平均值
按照职位进行分组,针对分组后,求每一组关于工资的平均值
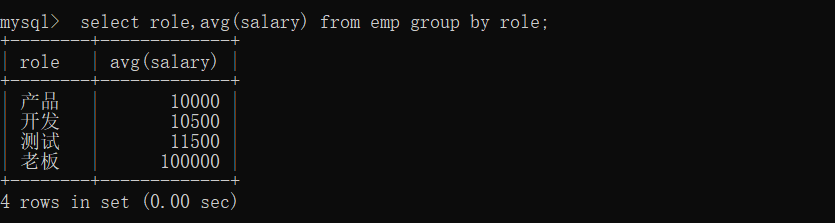
按照职位进行分组,分组后,求每组工资的最大值
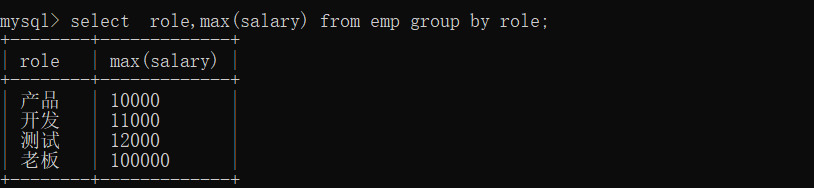
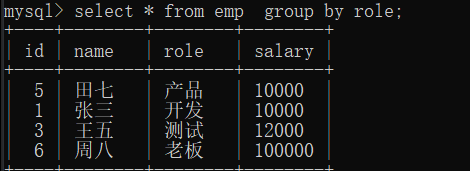
这样写展示的是每一组的第一个记录,其实是没有任何价值的
分组查询有两种情况
- 先条件筛选,再分组( where 条件 group by 列名)
- 先分组,后条件筛选 (group by 列名 having 条件)
举例:
1.计算各个岗位的平均薪资(除去张三)
这就是先除去张三,在进行分组计算
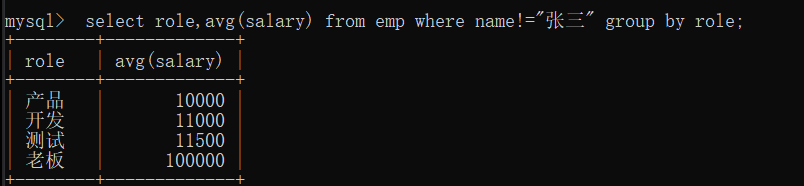
2.计算平均薪资大于10000的岗位
先进行分组,再筛选薪资大于10000的岗位
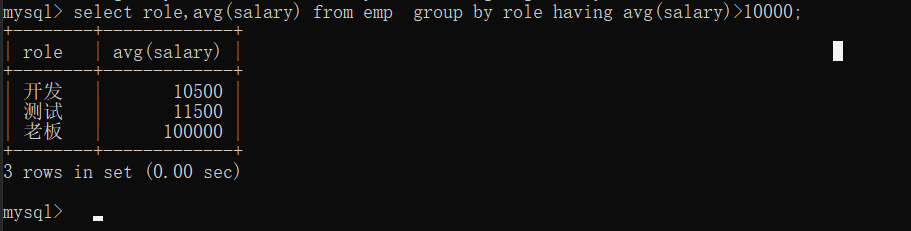
3.求除了张三之外,每个岗位的平均薪资,并且保留平均薪资大于10000的岗位

联合查询/多表查询(重点)
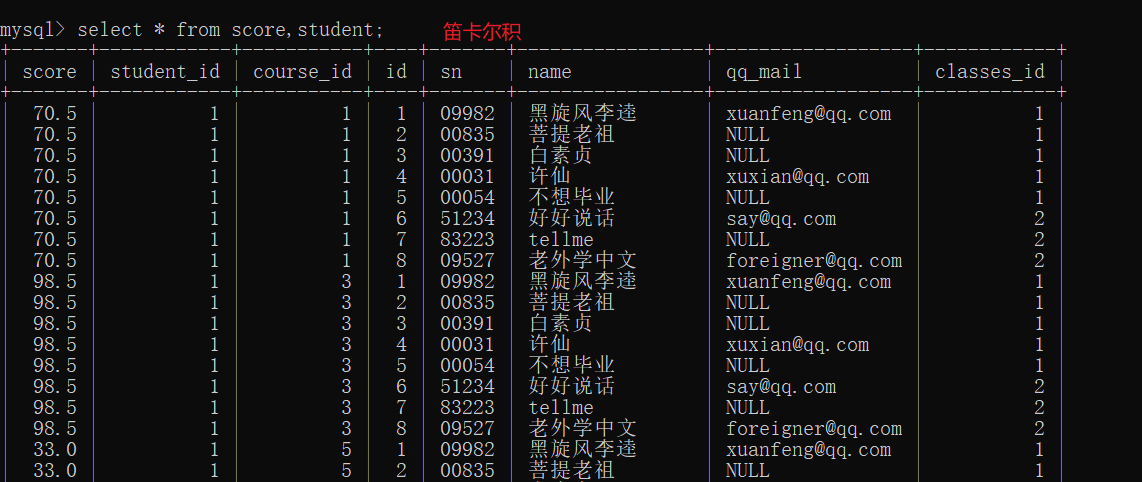
要想理解多表查询,首先要知道笛卡尔积
笛卡尔积就是两个表的记录的排列组合
笛卡尔积的列数就是两张表的列数之和
笛卡尔积的行数就是两张表的行数之积
使用联合查询/多表查询的时候,要是表比较大,计算笛卡尔积的时候,就会十分低效,甚至成为"危险操作"
笛卡尔积是一个简单粗暴的操作,只是进行简单的所有的排列组合,所以这么多的记录是有些是合理的,有些是不合理的,所以要寻找两张表的共同点(连接条件),进行筛选,将不合理的记录删除掉
联合查询/多表查询 = 笛卡尔积 + 连接条件 + 其他条件 (根据具体的需求)
联合查询/多表查询的两种写法
select *(列名) from 表名,表名 where 连接条件; – 内连接
select *(列名) from 表名 join 表名 on 连接条件; – 外连接
笛卡尔积:
连接条件
注意:两个表的列名是可以相同的,多表查询的时候,要是两个表的列是相同的,就用表名.列名加以区分
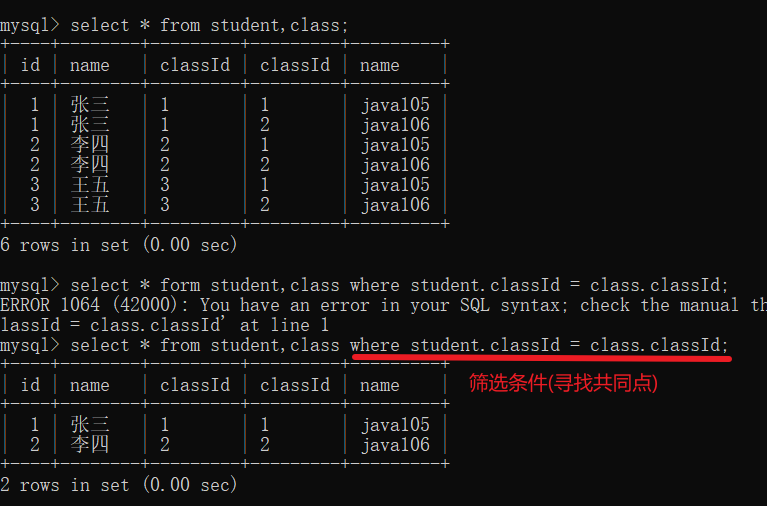
join on写法

举例:
一共有学生表 课程表 成绩表 班级表 4张表
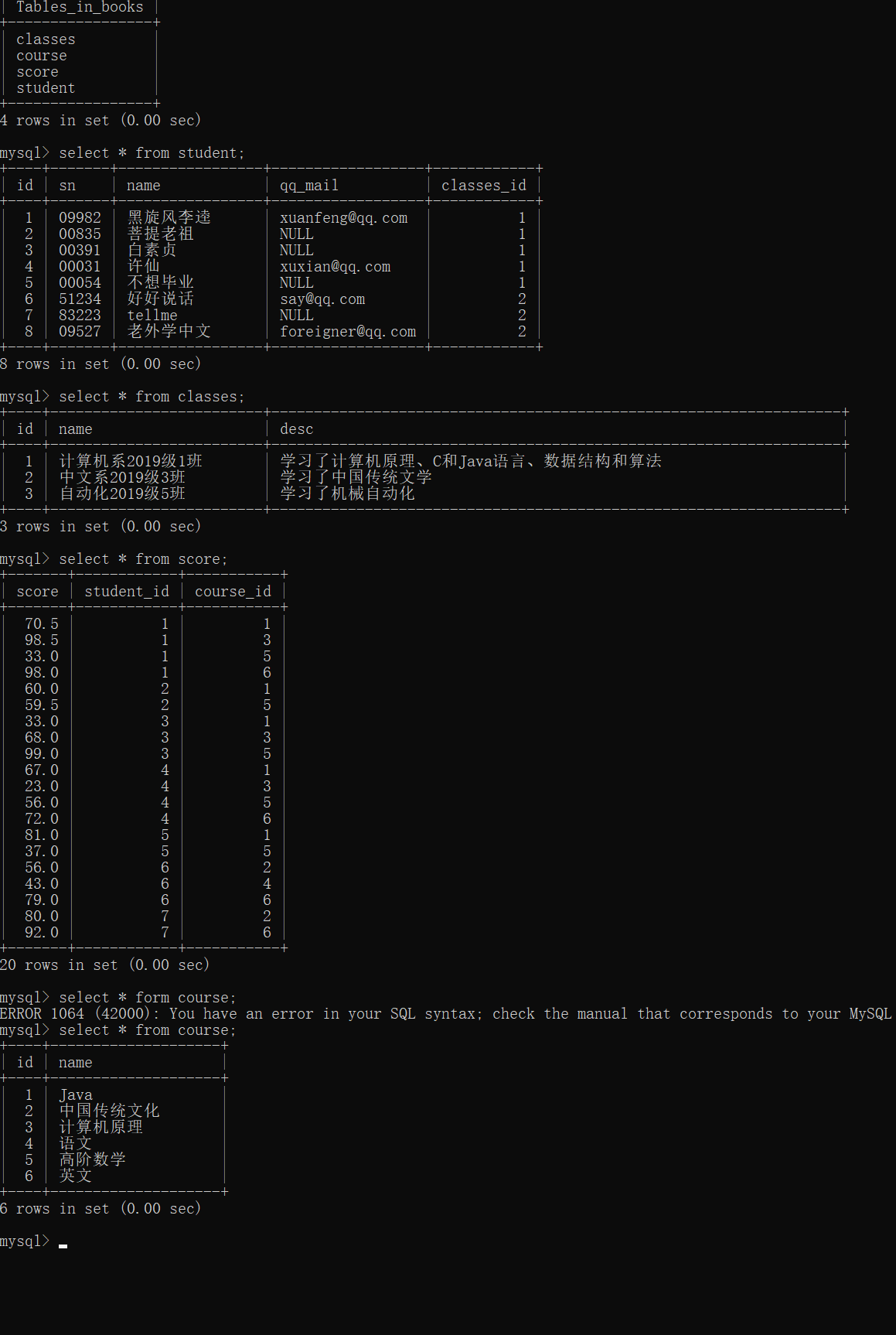
查询许仙同学的成绩
分析:许仙在学生表中,成绩在成绩表中
可以借助多表查询
- 借助笛卡尔积,将score 和 student 进行排列组合
- 给笛卡尔积加上连接条件,筛掉不合理的记录
- 根据"许仙"这个名字进行筛选
- 选择要显示的列
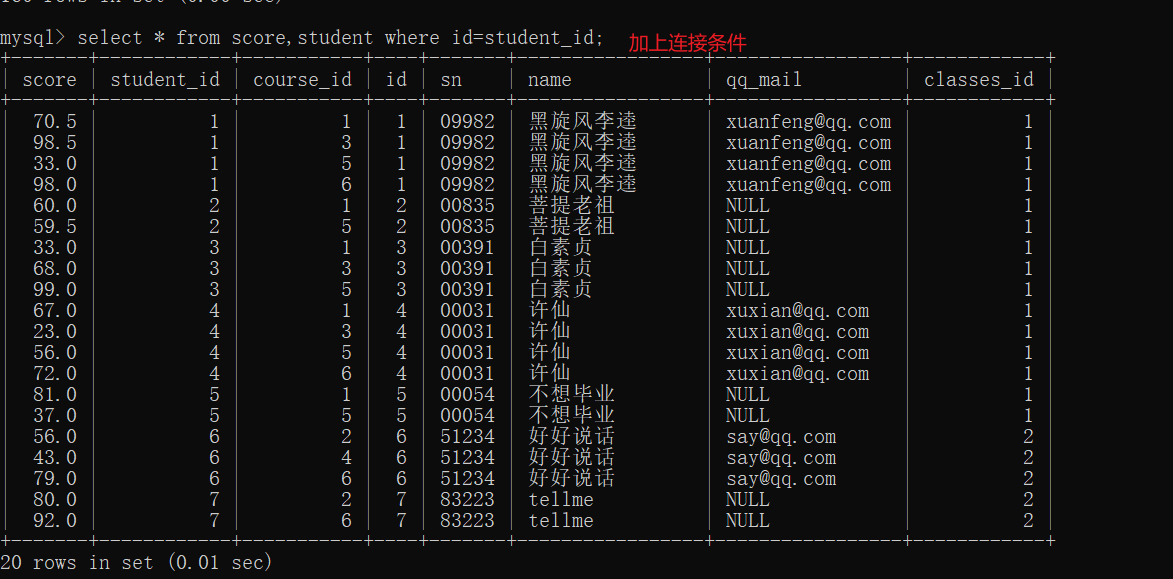
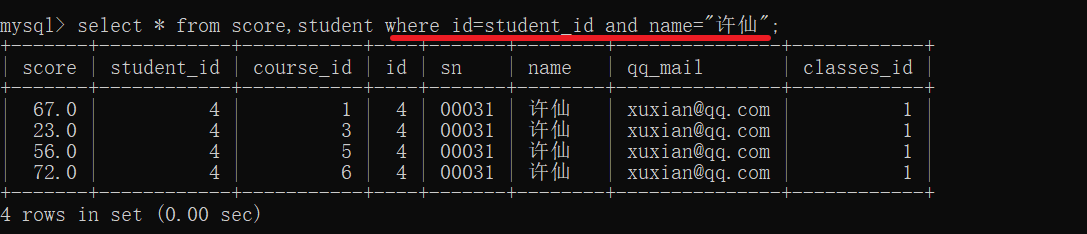

刚开始接触的时候,还是要一点一点进行操作,慢慢写,方便理解也方便排查错误
使用join on写法

查询所有同学的总成绩,以及个人信息
这里要求总成绩,此处的表是按照行来排列的,所以不能使用表达式累加来算,只能根据聚合函数sum
进行计算
还是按照上面的思路一步一步进行操作
- 笛卡尔积(成绩表 学生表)
- 连接条件(精简数据)
- 进行分组
- 计算总成绩(聚合函数–行与行的操作)
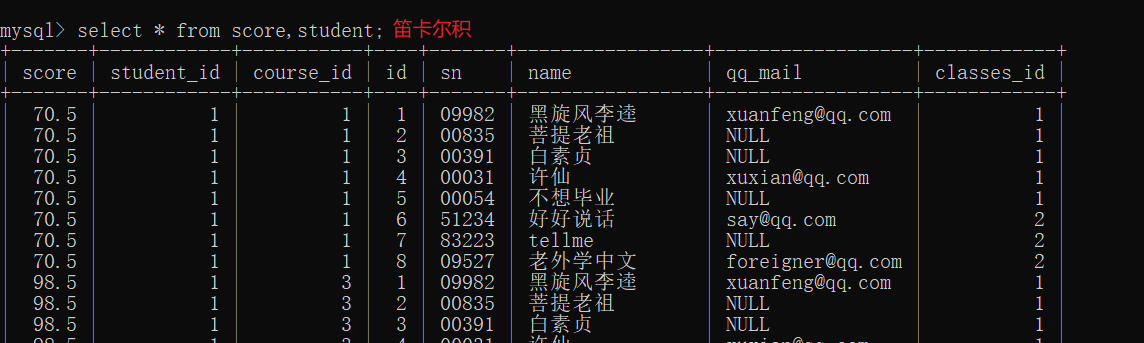
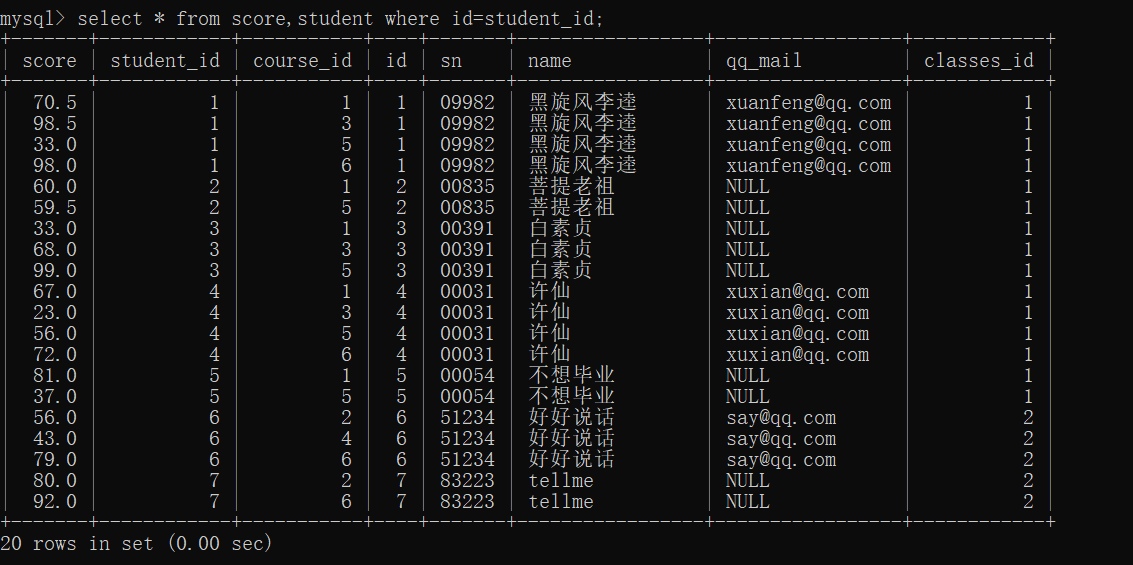
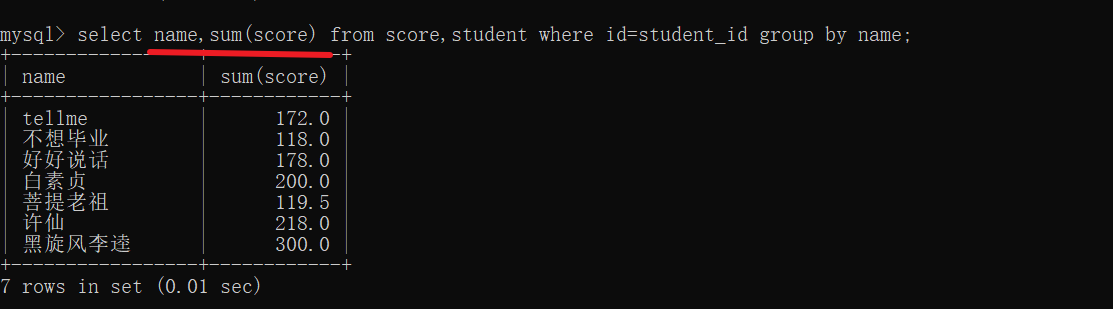
join on写法:
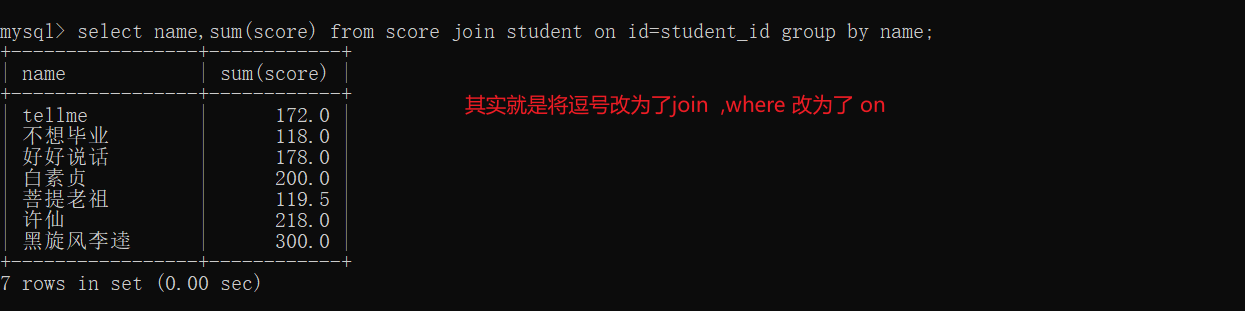
查询出同学的成绩,带有课程名的那种
同学名字在学生表
课程名字在课程表
分数在分数表
- 先算笛卡尔积(三表连接–其实算的速度不慢,只是打印的速度慢)
- 寻找连接条件
- 选择要展示的列即可
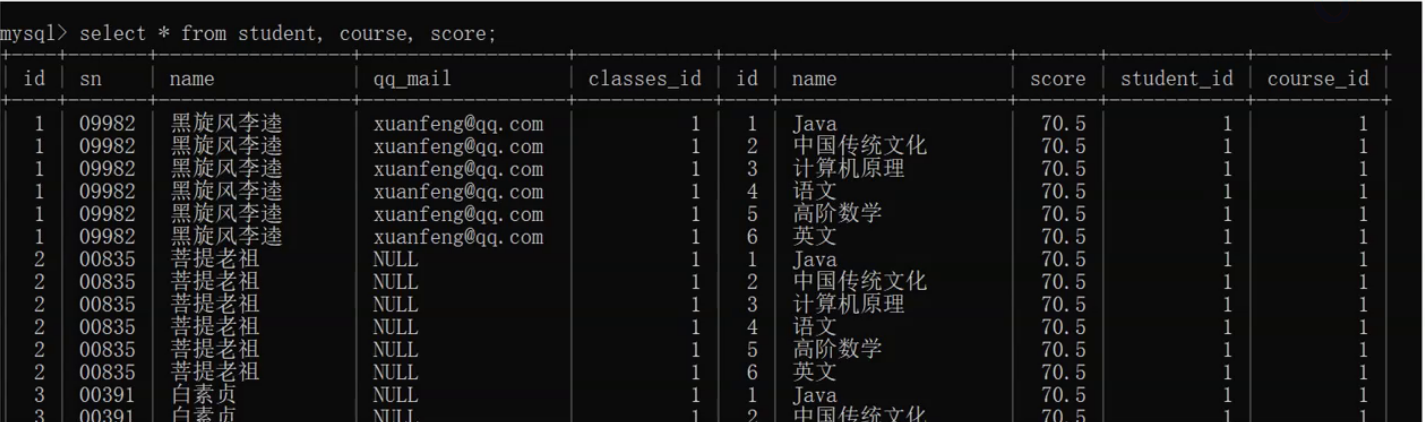
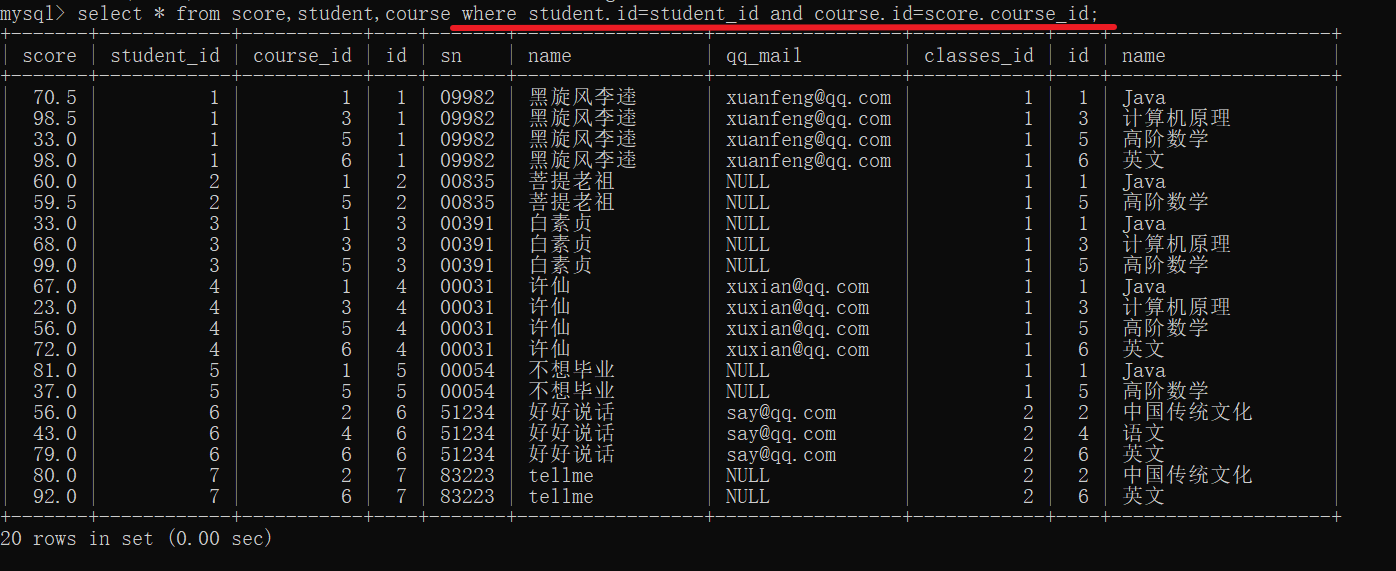
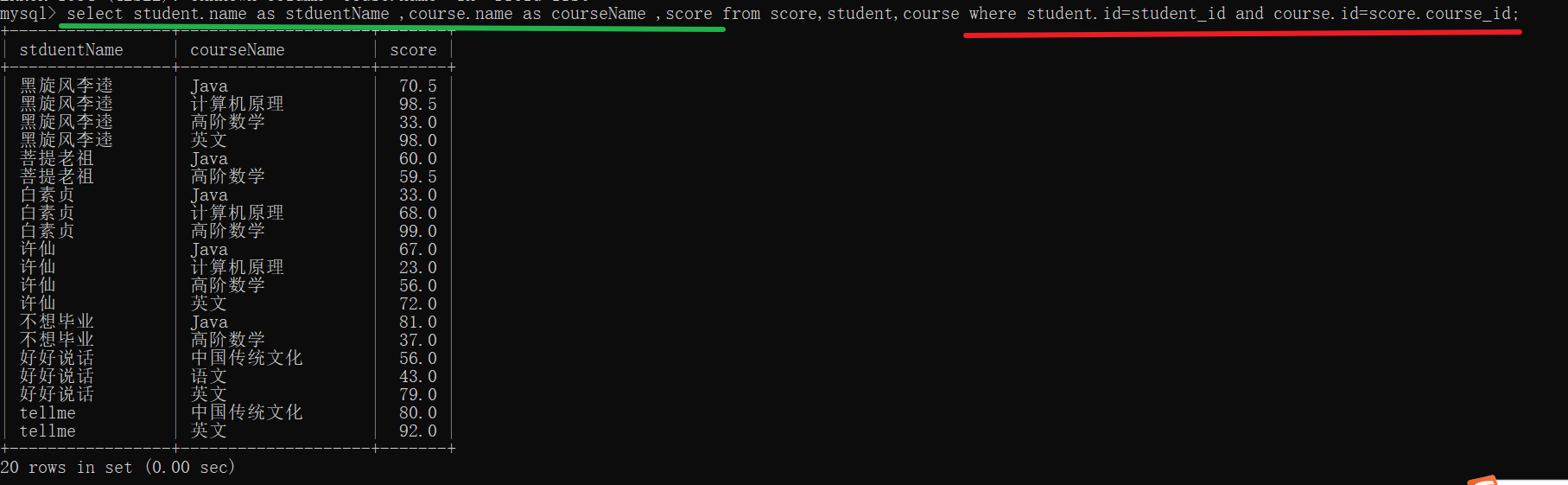
join on 写法(两个表两个表地连接)
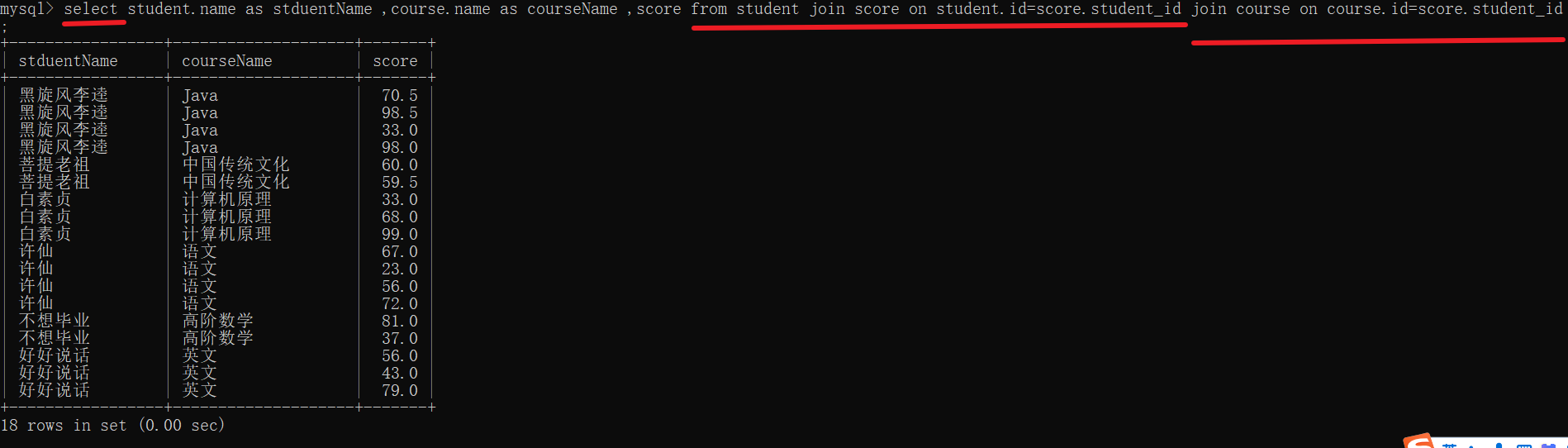
内连接与外连接
select 列名 from 表名,表名 where 连接条件; 内连接
select 列名 from 表名 join 表名 on 连接条件; 使用 join 可以作为内连接也可以作为外连接,写作 left join on 就是左外连接 right join on就是有右外连接

这样子的表是有相互照应体现的,在左表中的记录,在右表中的有体现
此时内连接与外连接是一样的

左表中的3 王五 , 在右表中没有体现,右表中的4 在左表中也没有体现 – 外连接
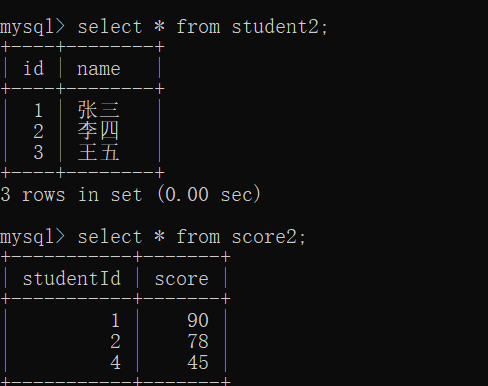
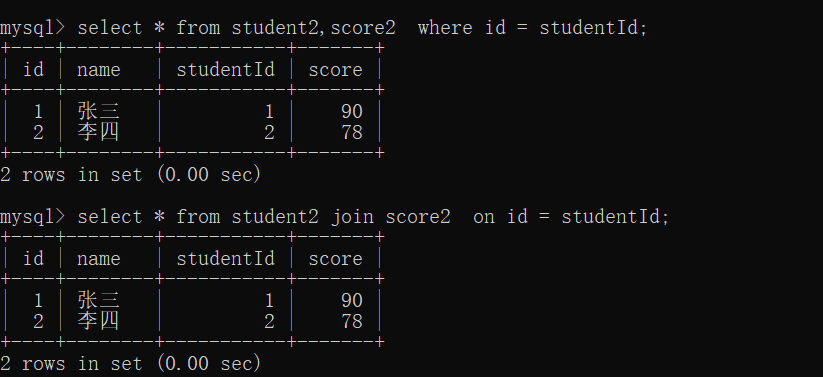
上面就是内连接,将两张表中有对应关系的记录整合在一起
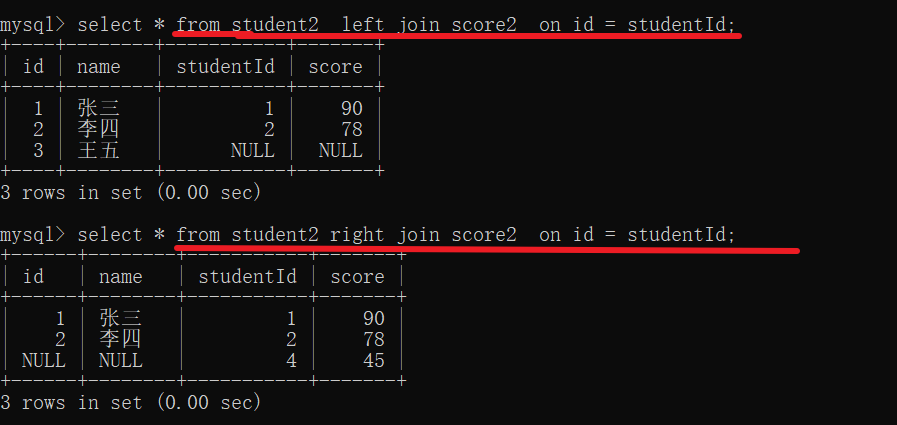
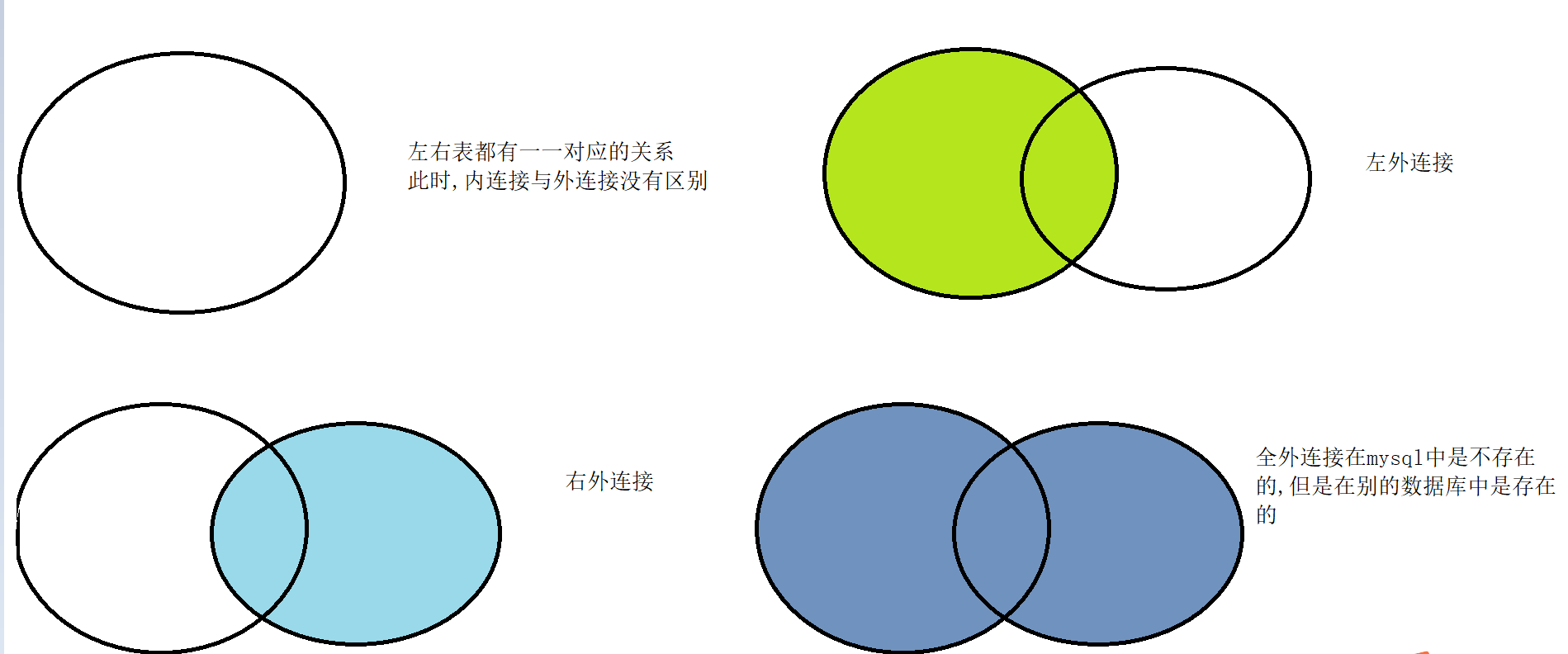
左连接会尽量将左侧表的数据完整地展示出来,右表无法体现就直接置为空
同理,右连接会尽量将右表的数据完整的展示出来,左表无法体现就直接置为空
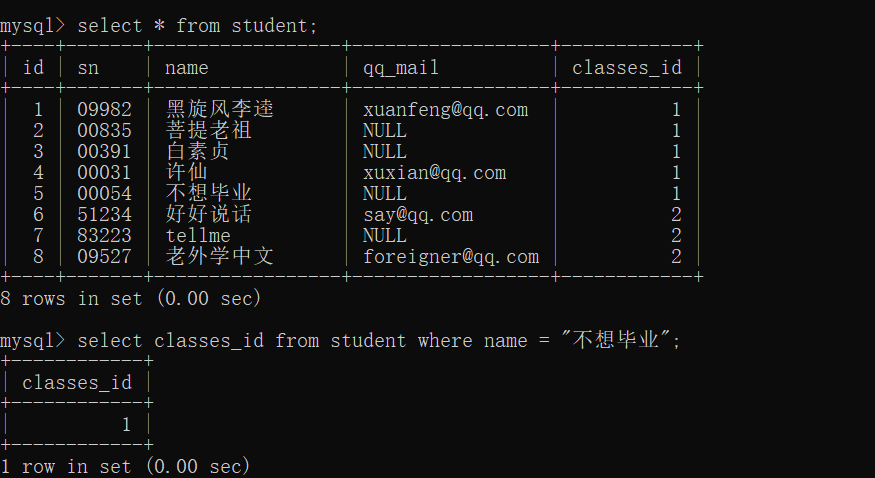
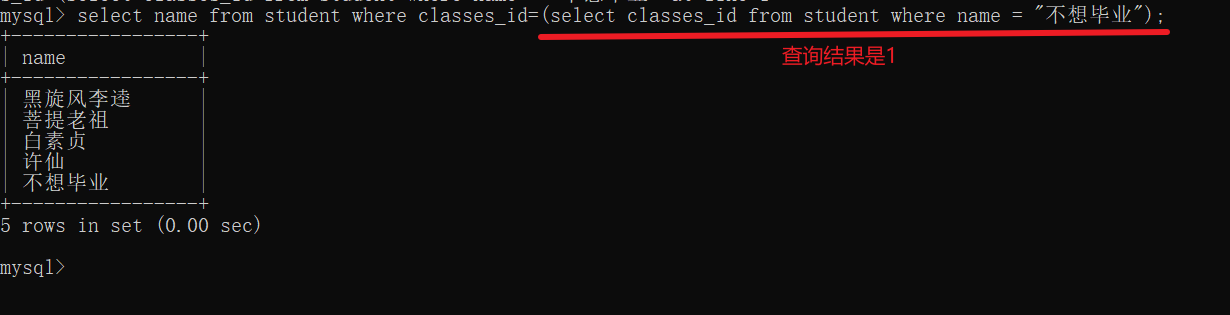
子查询
子查询其实就是套娃,利用上一步的结果作为下一步的条件
注意:上一步的结果必须只有一条记录
要是上一步的结果不止一条,就用in
举例:
寻找和"不想毕业"同班的同学
- 首先先确定"不想毕业"的班级号
- 利用上一步的班级号来查询

合并查询
合并查询就是将查询结果哈合并在一起
union 合并(要是有重复的数据,会进行去重)
union all 合并(不去重,直接合并)
查询名字为"英文"的课程或者id<3
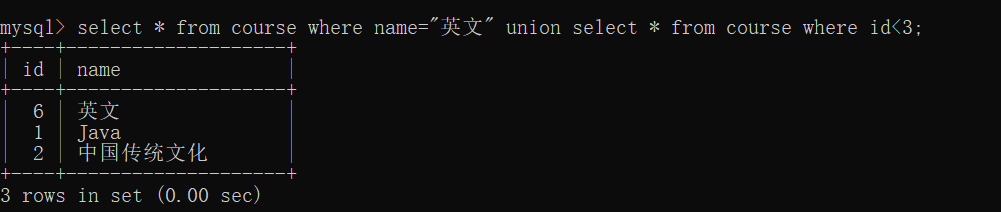
当然,这样子也可以直接就用 or ,使用union只是多了一种选择
小练习:

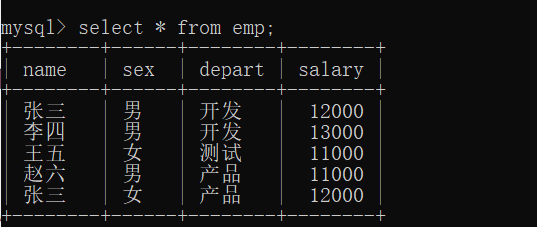
查询男女员工的平均工资
select sex,avg(salary) from emp group by sex;
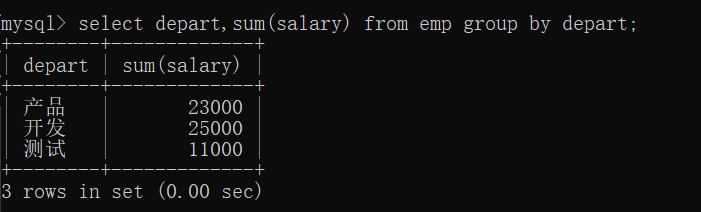
查询各部门的总薪水
select depart,sum(salary) from emp group by depart;
查询总薪水排名第二的部门
select depart,sum(salary) from emp group by depart order by sum(salary) desc limit 1 offset 1;
-- 先按照职位分组,然后按照薪资降序排列,最后只要排名第二的行

第4题
查询姓名重复的员工信息
select depart,avg(salary) from emp where salary>10000 and sex="男" group by depart;

第5题
查询各部门薪水大于10000的男性员工的平均薪水
select depart,avg(salary) from emp where salary>10000 and sex="男" group by depart;


select gpa from user_profile where university = "复旦大学" order by gpa desc limit 1;-- 一定要先是条件 排序 分页这样的顺序

- 点赞
- 收藏
- 关注作者
评论(0)