CMSIS-NN:ARM Cortex-M处理器的高效神经网络内核
Lai L, Suda N, Chandra V. Cmsis-nn: Efficient neural network kernels for arm cortex-m cpus[J]. arXiv preprint arXiv:1801.06601, 2018.
引言与背景
物联网设备正在快速增长,预计到2035年将在各个市场领域达到1万亿台。这些IoT边缘设备通常包含传感器,收集音频、视频、温度、湿度、GPS位置和加速度等数据,然后进行处理并与其他节点或云端通信。当前的数据处理模式主要依赖云端分析工具,但随着IoT节点数量的增加,这给网络带宽带来了相当大的负担,并增加了IoT应用的延迟。边缘计算作为一种解决方案,可以直接在数据源头进行处理,从而减少延迟并节省数据通信的能源消耗。
深度神经网络在图像分类、语音识别和自然语言处理等复杂机器学习应用中已经展现出接近人类的性能。然而,由于计算复杂性和资源需求,神经网络的执行主要局限于云计算环境,使用高性能服务器CPU或专用硬件(如GPU或加速器)。本研究探索了在资源受限的微控制器平台上优化神经网络性能,目标是智能IoT边缘节点。
神经网络结构与计算特征
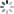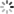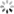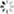
图1:典型深度神经网络结构
论文的第一张图展示了一个典型的深度神经网络架构。图中从左到右依次显示:输入图像(一张猫的照片),经过多个卷积层提取特征,然后是池化层减少维度,最后通过全连接层进行分类。这种层级结构允许网络从低级特征(如边缘和纹理)逐步学习到高级语义特征,最终实现准确的分类。
软件内核架构设计
图2:神经网络内核结构概览
第二张图详细展示了CMSIS-NN的软件架构。顶层是神经网络应用代码,它调用两类函数:NNFunctions和NNSupportFunctions。NNFunctions包含卷积、池化、全连接层和激活函数的实现。NNSupportFunctions提供数据类型转换和激活函数表等辅助功能。这种模块化设计使得内核API保持简单,便于被任何机器学习框架重新定位。
对于卷积和全连接等内核,实现了不同版本。基础版本适用于任何层参数,通用性强。同时还实现了其他优化版本,这些版本可能需要转换输入或对层参数有特定限制,但能提供更好的性能。理想情况下,可以使用简单的脚本解析网络拓扑,自动确定要使用的适当函数。
定点量化的理论基础
神经网络模型传统上使用32位浮点数据表示进行训练。然而,研究表明神经网络即使使用低精度定点表示也能很好地工作。定点量化有助于避免昂贵的浮点计算,并减少存储权重和激活值的内存占用,这对资源受限的平台至关重要。
CMSIS-NN采用的量化方案基于2的幂次缩放的定点格式。对于一个定点数,其实际表示的值为:
实际值=A×2n
其中A是存储的整数值,n是表示小数点位置的整数。这种设计的关键优势在于缩放操作可以通过简单的位移实现,而不需要乘法运算。偏置和输出的缩放因子作为参数传递给内核,缩放通过位移操作实现,因为采用了2的幂次缩放。
核心计算内核的详细实现
支持函数的优化设计
图3:标准q7_t到q15_t数据转换
第三张图展示了CMSIS标准库中的数据转换过程。输入是4个8位数据(A1, A2, A3, A4),首先通过SXTB16指令进行符号扩展,将每个8位数据扩展为16位。然后进行数据重排,确保输出顺序与输入一致。伪代码显示了具体的实现:使用__SXTB16进行符号扩展,然后通过__PKHBT和__PKHTB指令重新组合数据。
图4:优化的数据转换(无重排)
第四张图展示了优化版本的数据转换。这个版本省略了数据重排步骤,直接输出符号扩展后的结果。虽然输出数据的顺序与输入不同,但当两个操作数都使用相同的转换时,顺序差异会相互抵消。这种优化在内循环中特别重要,因为可以显著减少指令数量。
矩阵乘法的深度优化
图5:2×2内核矩阵乘法
第五张图详细展示了矩阵乘法的内循环实现。使用2×2内核意味着每次循环计算2行和2列的点积,产生4个输出。图中显示了如何使用SMLAD指令高效地执行乘累加操作。累加器使用q31_t类型以避免溢出,并用相应的偏置值初始化。
矩阵乘法的计算过程可以表示为:
Sumij=Biasij+k∑Aik×Bkj
其中累加使用32位精度完成,然后根据需要缩放回8位或16位输出。
全连接层的权重重排优化
图6:1×4内核的权重重排
第六张图展示了支持1×4内核的权重重排过程。原始权重矩阵按行存储,重排后每4行的数据交错存储。主要部分的4×4块被分组和交错:A11, A21, A13, A23形成第一组,A33, A43, A12, A22形成第二组,以此类推。额外的列保持交错模式,而剩余的行保持原始顺序。这种重排允许在矩阵-向量乘法中只使用一个指针访问所需的权重数据。
图7:1×4内核计算过程
第七张图详细展示了1×4内核的计算流程。8位输入通过q7_to_q15转换为16位,权重也进行相同转换。由于使用了无重排的转换函数,权重和激活向量的数据顺序在转换后自动匹配。每个内循环迭代处理两个1×4的MAC操作,充分利用SIMD指令的并行性。
卷积层的im2col优化
图8:im2col操作示例
第八张图展示了im2col在2D图像上的操作,使用3×3内核,填充大小为1,步幅为2。输入是一个5×5的图像,im2col将每个3×3的窗口展开为一列。图中清楚地显示了如何将重叠的窗口数据重新组织为矩阵形式,使卷积操作可以通过矩阵乘法实现。这种转换的代价是内存占用增加,因为输入像素在输出矩阵中会重复出现。
图9:3D数据上的卷积
第九张图展示了在3D数据上执行卷积的过程。输入具有高度、宽度和通道三个维度。卷积核在高度和宽度维度上滑动(第一和第二步幅),而在通道维度上覆盖所有通道。这个图清楚地说明了为什么HWC(高度-宽度-通道)数据布局比CHW更高效:在HWC格式中,同一空间位置的所有通道数据是连续存储的。
图10:CHW vs HWC性能对比
第十张图展示了实验结果,比较了CHW和HWC数据布局的性能。横轴是输出通道数,纵轴是运行时间(毫秒)。当输出通道数为0时,表示只执行im2col而不进行矩阵乘法。结果清楚地显示,HWC布局在im2col操作上具有更低的运行时间,而两种布局的矩阵乘法性能相同。这验证了HWC布局的优越性。
池化层的原地操作实现
图11:原地最大池化示例
第十一张图展示了原地最大池化的实现。输入数组[A1, A2, A3, A4, A5]通过比较相邻元素并保留最大值,逐步缩减为更小的数组。伪代码显示了具体实现:使用指针遍历数组,比较并更新值,然后调整步幅继续处理。这种方法避免了额外的内存分配,是内存受限环境下的理想选择。
激活函数的高效实现
图12:优化的ReLU内核
第十二张图详细展示了ReLU函数的SWAR实现。输入的每个q7_t数据的MSB(最高有效位)被用作符号位。通过__ROR和__QSUB8指令,符号位被扩展为完整的字节掩码。如果数字是负数(符号位为1),掩码为0xFF,与原始数据进行AND操作后结果为0。如果是正数,掩码为0x00,保持原值不变。这种实现可以同时处理4个8位数据,实现了4倍的加速。
实验评估与性能分析
实验在NUCLEO-F746ZG Mbed开发板上进行,使用运行在216 MHz的ARM Cortex-M7核心。测试网络是在CIFAR-10数据集上训练的CNN,包含60,000张32×32彩色图像,分为10个类别。
表1:CIFAR-10 CNN的层参数和性能
网络拓扑基于Caffe提供的内置示例,具体层配置如下:
第1层卷积:5×5×3×32滤波器(2.3 KB),输出32×32×32(32 KB),4.9M次操作,耗时31.4毫秒
第2层最大池化:输出16×16×32(8 KB),73.7K次操作,耗时1.6毫秒
第3层卷积:5×5×32×32滤波器(25 KB),输出16×16×32(8 KB),13.1M次操作,耗时42.8毫秒
第4层最大池化:输出8×8×32(2 KB),18.4K次操作,耗时0.4毫秒
第5层卷积:5×5×32×64滤波器(50 KB),输出8×8×64(4 KB),6.6M次操作,耗时22.6毫秒
第6层最大池化:输出4×4×64(1 KB),9.2K次操作,耗时0.2毫秒
第7层全连接:4×4×64×10权重(10 KB),输出10个类别,20K次操作,耗时0.1毫秒
总计:87 KB权重,55 KB激活值,24.7M次操作,99.1毫秒完成一次推理。这相当于每秒处理10.1张图像,CPU的计算吞吐量约为每秒249 MOps。
表2:各层类型的性能提升对比
与基线实现相比,CMSIS-NN内核在各种层类型上都实现了显著的性能提升:
卷积层:基线443.4毫秒 vs CMSIS-NN 96.4毫秒,4.6倍吞吐量提升,4.9倍能效提升
池化层:基线11.83毫秒 vs CMSIS-NN 2.2毫秒,5.4倍吞吐量提升,5.2倍能效提升
ReLU层:基线1.06毫秒 vs CMSIS-NN 0.4毫秒,2.6倍吞吐量和能效提升
总体:基线456.4毫秒 vs CMSIS-NN 99.1毫秒,4.6倍吞吐量提升,4.9倍能效提升
结论
CMSIS-NN成功地在ARM Cortex-M处理器上实现了高效的神经网络推理。通过精心设计的软件内核,包括定点量化、SIMD优化、数据布局优化和内存高效的算法,在资源受限的微控制器上实现了接近实时的神经网络推理。这项工作为智能IoT边缘设备的部署提供了实用的解决方案,使得在数据源头进行智能处理成为可能。
附录:数学推导
A. 定点量化的误差分析
A.1 量化误差的数学表达
设原始浮点值为x,量化后的值为x^,量化函数为:
Q(x)=round(sx)⋅s
其中s=2−n是缩放因子。量化误差ϵ为:
ϵ=x−x^=x−round(sx)⋅s
假设舍入误差均匀分布在[−s/2,s/2]区间,则量化误差的期望和方差为:
E[ϵ]=0
Var[ϵ]=12s2=122−2n
A.2 累积误差分析
在神经网络的前向传播中,每层的量化误差会累积。对于第l层的输出:
y(l)=f(W(l)x(l−1)+b(l))
考虑量化后的计算:
y^(l)=Q(f(W^(l)x^(l−1)+b^(l)))
总误差包含权重量化误差、激活量化误差和计算量化误差的复合效应。使用一阶泰勒展开:
Δy(l)≈∂z∂f∣∣∣∣∣z=W(l)x(l−1)+b(l)[ΔW(l)x(l−1)+W(l)Δx(l−1)+Δb(l)]
B. SIMD指令的计算效率
B.1 MAC操作的并行化
ARM Cortex-M的SMLAD指令可以在一个周期内执行两个16位乘累加操作:
SMLAD(a,b,c)=c+(a0×b0)+(a1×b1)
其中a=[a0,a1]和b=[b0,b1]是打包的16位数据对。
对于长度为N的向量点积,传统实现需要N次乘法和N−1次加法。使用SMLAD,只需要⌈N/2⌉条指令,理论加速比为:
加速比=⌈N/2⌉2N−1≈4(当N较大时)
B.2 数据对齐的影响
当数据未对齐时,需要额外的加载和重排指令。设对齐数据的加载成本为L,未对齐数据需要2L+R(两次加载加一次重排)。效率损失为:
效率=2L+RL=2+R/L1
C. im2col的内存复杂度
C.1 标准im2col内存需求
对于输入尺寸H×W×C,卷积核尺寸K×K,输出尺寸H′×W′,标准im2col需要的内存为:
Mim2col=H′×W′×K×K×C
内存扩展因子为:
扩展因子=H×W×CMim2col=H×WH′×W′×K2
对于步幅s=1,填充p的情况:
扩展因子=H×W(H+2p−K+1)(W+2p−K+1)×K2
C.2 部分im2col的优化
部分im2col只展开n列(n≪H′×W′),内存需求降至:
Mpartial=n×K×K×C
这将内存开销从O(H′W′K2C)降至O(nK2C),其中n是常数(通常为2或4)。
D. 池化层的计算复杂度
D.1 传统窗口池化
对于K×K的池化窗口,步幅为s,传统方法的计算复杂度为:
Owindow=H′×W′×K2×C
其中H′=⌊(H−K)/s⌋+1,W′=⌊(W−K)/s⌋+1。
D.2 分离x-y池化
分离方法先进行x方向池化,再进行y方向池化:
Ox-pool=H×W′×K×C
Oy-pool=H′×W′×K×C
Osplit=Ox-pool+Oy-pool=(H×W′+H′×W′)×K×C
理论加速比为:
加速比=OsplitOwindow=(H×W′+H′×W′)×KH′×W′×K2
当s=K(无重叠)时,加速比约为K/2。
E. 激活函数的查找表设计
E.1 均匀量化查找表
对于输入范围[−xmax,xmax],使用2b个表项,量化步长为:
Δ=2b2xmax
查找表索引计算:
index=⌊Δx+xmax⌋
最大近似误差为:
ϵmax=xmax∣f(x)−LUT[index]∣≤2Δ⋅xmax∣f′(x)∣
E.2 非均匀量化优化
对于sigmoid和tanh等非线性函数,在x=0附近变化剧烈。采用非均匀量化,在[−x0,x0]区间使用更密集的采样:
Δinner=2b12x0
Δouter=2b22(xmax−x0)
其中b1+b2=b,优化分配使得两个区间的最大误差相等:
2Δinner∣x∣<x0max∣f′(x)∣=2Δouterx0<∣x∣<xmaxmax∣f′(x)∣
对 sigmoid 函数 σ(x)=1+e−x1,其导数
σ′(x)=σ(x)(1−σ(x))=41sech2(2x).
步长比
ΔinnerΔouter=σ′(x0)σ′(0)=41sech2(x0/2)41=cosh2(2x0).
取 x0=2,cosh(1)≈1.543,故
ΔinnerΔouter≈2.381,σ′(2)≈0.105.
F. 定点乘法的溢出避免策略
F.1 动态范围分析
对于n位定点数,表示范围为[−2n−1,2n−1−1]。两个n位数相乘,结果需要2n位。累加m个乘积,最坏情况需要额外log2(m)位:
所需位宽=2n+⌈log2(m)⌉
F.2 饱和算术实现
CMSIS-NN使用饱和算术避免溢出。对于累加器acc:
accsat=⎩⎪⎪⎨⎪⎪⎧231−1−231accif acc>231−1if acc<−231otherwise
缩放回输出精度时:
output=satn(round(2shiftaccsat))
其中satn是n位饱和函数。
















评论(0)