Redis系列之什么是布隆过滤器?

Redis系列之什么是布隆过滤器?
1、前言
前面的学习,我们知道了Redis的很多应用场景,但是最常见的还是缓存,“性能不够,缓存来凑”,在一些高并发的场景合理的使用缓存,还是可以减缓系统压力的。
画流程图表示缓存的一个典型场景:客户端发送请求,会先去缓存里读取数据,能读到数据,直接返回,不能命中缓存,再去读数据库,然后再预热到缓存里
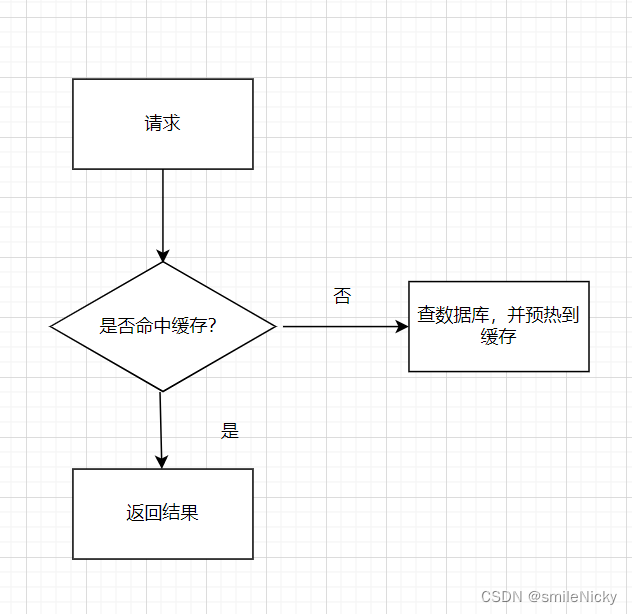
但是这个场景有个严重的缺陷,假如有海量的请求每次请求都不能命中缓存,那就会直接访问到数据库,很容易造成数据库压力过大,这种场景就是面试中经常问到的redis缓存穿透的场景。要避免这种情况的出现,我们可以加一层过滤,如果没命中缓存,直接返回就行,避免了大量请求访问到数据库。
2、学习计划
- 知道什么是布隆过滤器
- 布隆过滤器的构建原理
- 布隆过滤器的适用场景
3、什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制数组。布隆过滤器有一系列随机映射函数,可以用于检索一个元素是否在一个集合中。
- 优点:占用空间和查询速度很快,比起使用Set去重会节省90%的空间,而且查询速度也很快
- 缺点:删除困难,也会有误识别率。简单来说,布隆过滤器识别存在某个数据时,可能集合里并不存在,识别集合中不存在某个数据,那就是不存在,所以布隆过滤器的误识别率是针对存在的数据来说的
4、布隆过滤器是如何构建的?
布隆过滤器本质就是一个二进制的数组,用0和1表示。
我们以电商场景中的订单编码为例,假如有一个订单编码code1,生成过程会进行布隆过滤器的去重,如图所示,这里只进行3次hash
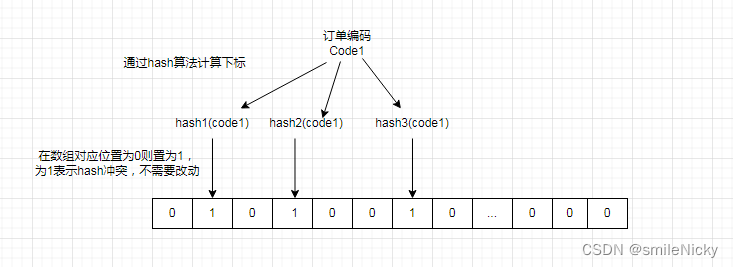
Hash规则:如果hash后,原始下标为0,则将其从0变为1,如果是1的话,则不做改动
画流程图,布隆过滤器的执行过程
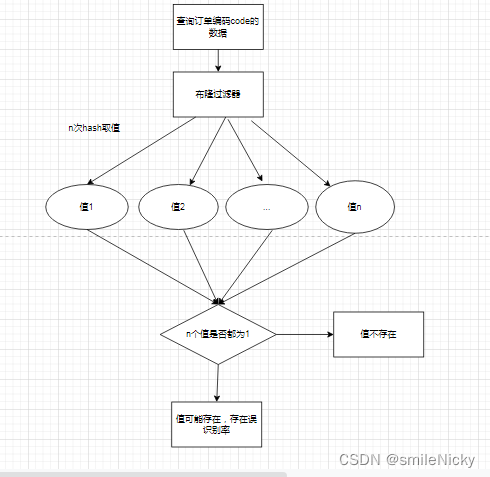
5、如何避免布隆过滤器误识别?
布隆过滤器存在一定的误识别率,要提高其识别准确度,可以从两方面入手
- 增加二进制数组的长度,数组长度越长,hash后的数据会更加离散,hash冲突的概率会越小
- 增加hash的次数,hash次数越多,冲突的概率越小
布隆过滤器识别数据存在的情况,不是特别准确的,存在一定误识别率,原因是存在hash冲突,可能会误识别
6、Redis中的布隆过滤器
Redis官方提供的布隆过滤器到了Redis4.0之后才作为一个插件加载到Redis Server中,给Redis提供了强大的布隆去重功能。
为了方便安装维护,可以直接使用docker来安装:
# docker pull rebloom插件
docker pull redislabs/rebloom
# 启动插件
docker run -p6379:6379 redislabs/rebloom
# 进入redis客户端,验证是否安装成功
redis-cli
- 1
- 2
- 3
- 4
- 5
- 6
7、布隆过滤器基本使用
下面通过一下简单命令,体验一下,在Redis中布隆过滤器有两个最基本的命令,bf.add添加元素,bf.exists查询元素是否存在,如果想要一次性添加多个,就需要用到bf.madd指令,如果需要一次性查询多个元素是否存在,需要用到bf.mexists指令
127.0.0.1:6379> bf.add testusername user1
(integer) 1
127.0.0.1:6379> bf.add testusername user2
(integer) 1
127.0.0.1:6379> bf.add testusername user3
(integer) 1
127.0.0.1:6379> bf.exists testusername user1
(integer) 1
127.0.0.1:6379> bf.exists testusername user2
(integer) 1
127.0.0.1:6379> bf.exists testusername user3
(integer) 1
127.0.0.1:6379> bf.exists testusername user4
(integer) 0
127.0.0.1:6379> bf.madd testusername user4 user5 user6
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.mexists testusername user4 user5 user6 user7
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
8、布隆过滤器的应用场景
- 用于避免缓存穿透的发生,可以提高系统稳定性和高可用
- 新闻系统的推荐,用布隆过滤器识别用户已经看过的新闻,避免重复推送
- 爬虫程序对URL的去重,避免爬取相同的URL地址
参考资料
本博客参考网上博客的资料,也参考书籍的资料,书籍可以学习钱文品大佬的《Redis 深度历险:核心原理与应用实践 | 钱文品 著》
文章来源: smilenicky.blog.csdn.net,作者:smileNicky,版权归原作者所有,如需转载,请联系作者。
原文链接:smilenicky.blog.csdn.net/article/details/120187027

- 点赞
- 收藏
- 关注作者
评论(0)