LayoutXLM: 面向多语种视觉丰富文档理解的多模态预训练模型


1 引言
目前,针对视觉丰富文档(Visually-rich Document, VrRD)的多模态预训练模型已经在多个文档理解任务上取得了领先的结果,例如表格/票据理解、复杂版面分析、文档图像分类以及文档视觉问答等任务,其优势在于将文本、版面、图像等多模态信息纳入到统一框架中进行联合预训练。LayoutLM [1]与LayoutLMv2 [2]是VrRD多模态预训练模型中的经典工作,不熟悉的读者可以参考笔者的上两篇博文[3, 4],而本次要介绍的LayoutXLM [5] 则是该系列工作的第三篇,针对LayoutLM与LayoutLMv2主要考虑英文文档的情形,进一步考虑了多语种文档理解任务。LayoutXLM是LayoutLMv2在多语种情形下的拓展,预训练数据包含53种语种文档,语言分布如图1所示。

为了评估多语种情况下的VrRD理解能力,作者们构建了多语种表单数据集XFUN,共包括7个语种(中文、日语、西班牙语、法语、意大利语、德语、葡萄牙语),包含人工标注的key-value键值对。
2 方法
模型结构 LayoutLMv2,考虑了文本、版面、图像等多模态信息。
预训练任务 同LayoutLMv2,包括掩码视觉语言模型、文本-图像对齐与文本-图像匹配任务。值得注意的是,在多语种情况下,采用 SentencePiece(LayoutLM v1/v2采用WordPiece)进行分词,获取文本的token序列,无需语种相关的预处理。
预训练数据 采用common crawl [6]爬取多语种PDF,用pymupdf进行文档解析、blingfire进行语种分类(低于0.5分的丢弃),最终获取22M的多语种PDF文档。此外,还采用来自 IIT-CDIP数据的8M扫描英语文档,共计30M文档。
3 XFUND:多语种表格理解基准
3.1 任务描述
Key-Value键值对提取是表单理解中最关键的任务之一,原因是表单中的关键信息常常以Key-Value键值对的形式呈现。例如,文本“姓名:小明”中,”姓名“为Key,而”小明“则是相对应的Value。与FUNSD类似,研究者定义了如下两个任务,分别是语义实体抽取和关系提取。
语义实体抽取 (Semantic Entity Recognition, SER)。给定一个文档 ,包含离散的token集合 ,其中 包含文本内容 及其包围盒坐标 ,模型需要从token序列中抽取出已定义的语义实体。记 为实体类别,则语义实体抽取任务可定义为 ,其中
关系抽取 (Relation Extraction, RE)。给定文档 与 实体类别 ,关系抽取任务用于预测任意两个实体之间是否存在关系、存在何种关系。记 为关系类别,则关系抽取任务可以定义为 ,其中
其中 与 为实体抽取步骤所获得的语义实体。在本论文中,研究者关注Key-Value关系抽取,即集合 仅包含一个关系类别,即两个实体是否是匹配的Key-Value对;Key、Value则是集合 中定义的两个类别。
3.2 数据采集
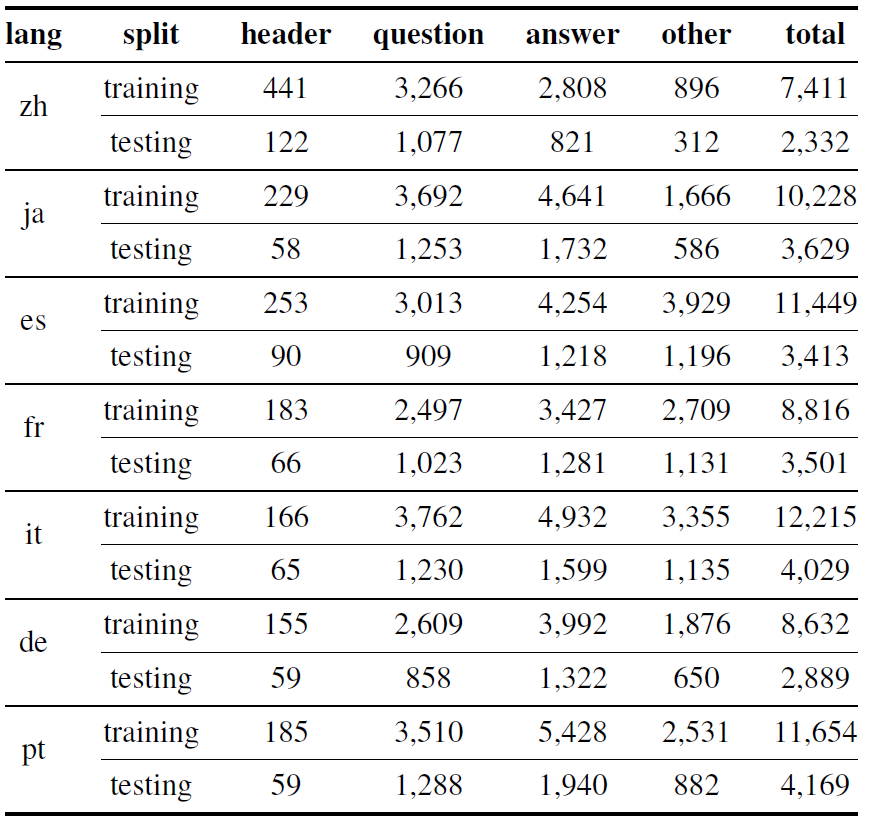
研究者从互联网上爬取7个语种的表单文档,移除其内容,只保留其版式作为模板,并令标注人员通过打印或手写为这些模板填上人工合成的信息。每个模板只使用一次,故每个表格的版式彼此不同。表格填写完成后,扫描为图片,并通过Microsoft Read API进行OCR识别,获取文本内容及其包围盒信息。通过GUI标注工具,标注人员需要标注出文本中的实体与Key-Value对。图2展示了数据集中的两个样例。表格1为数据集的统计信息。

4 实验
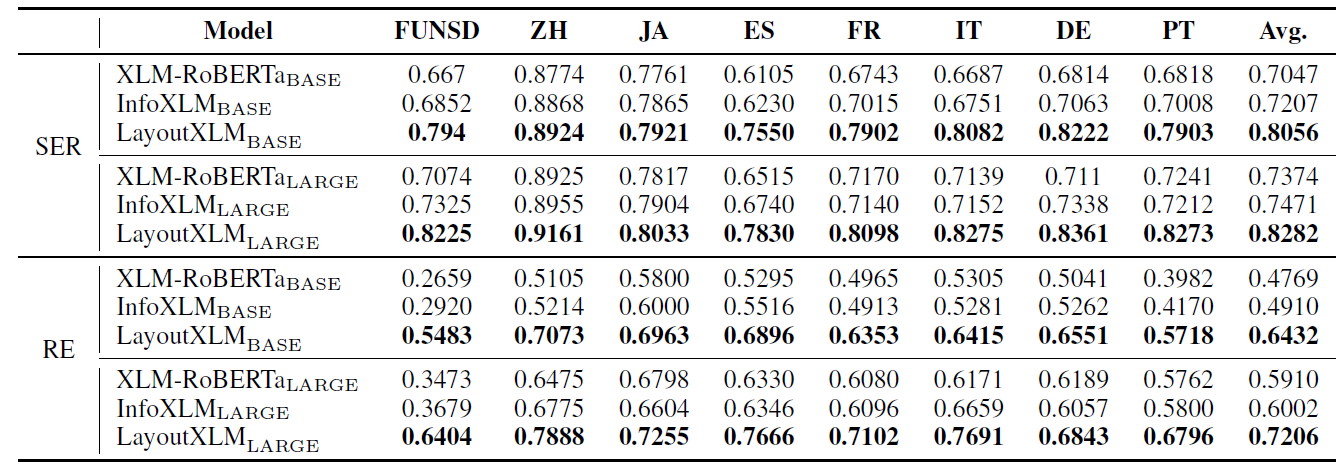
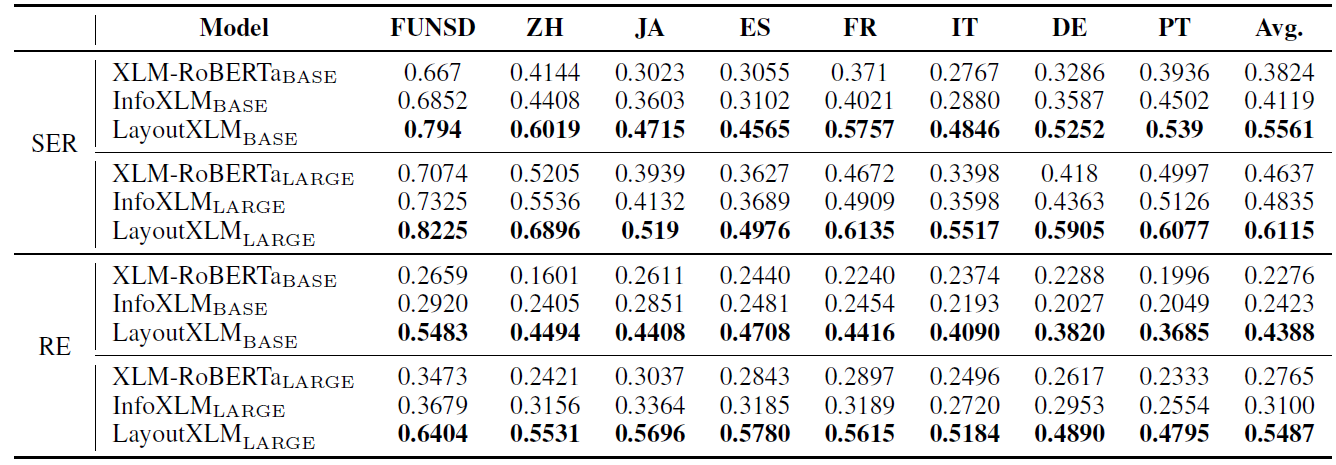
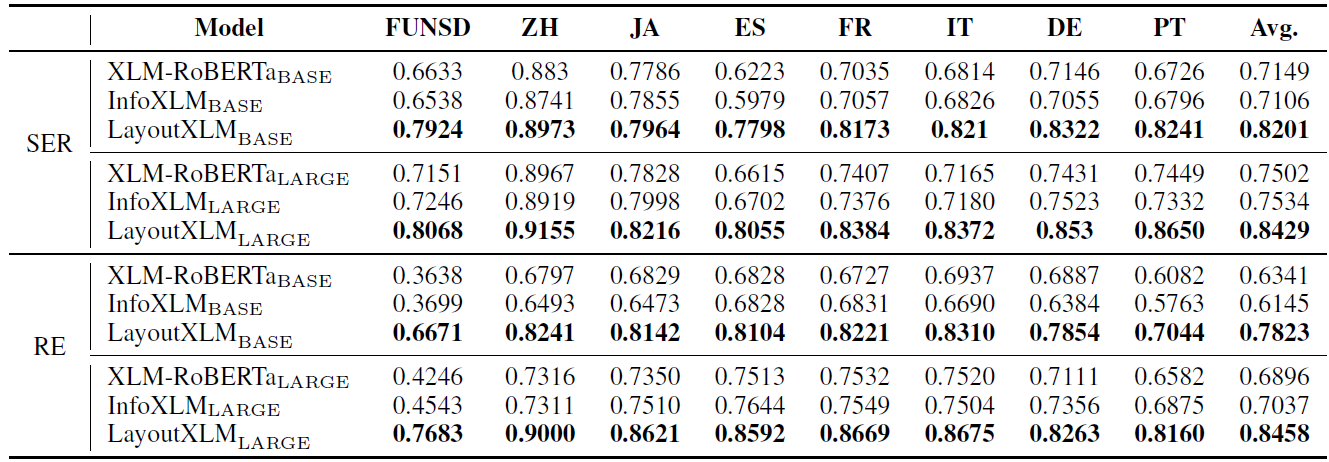
LayoutXLM模型的预训练与微调细节详见论文。此处主要介绍评估LayoutXLM模型性能的三个微调实验。(1) 语种相关微调,即在语种X上微调,在语种X上测试。(2)零样本迁移,即只在英语文档上训练,在其余语种文档上测试。(3)多任务微调,即同时在所有语种上进行微调。三个实验的结果分别见表格2-4。FUNSD数据集只包含英语表单文档,XFUN数据集包含中文、日语、西班牙语、法语、意大利语、德语、葡萄牙语(简称分别为ZH, JA, ES, FR, IT, DE, PT)表单文档。
值得注意的是,在零样本迁移实验中,尽管模型只在英语文档上进行微调,但它仍然可以将知识转移到不同的语言中。对比语种相关微调与多任务微调实验,可以看到多任务微调提高了模型的性能,表明模型可以从多语种文档中学习到共性特征,例如版面或布局的规律、语义的关联等,从而提升精度。在三个实验中,LayoutXLM均优于XLM-RoBERTa 和 InfoXLM 等预训练模型,表明多模态预训练的有效性。
5 结论
LayoutXLM是LayoutLMv2在多语种情形下的拓展,采用了三千万的多语种文档进行预训练,在多语种VrRD理解任务上取得了SOTA性能。纵观LayoutLM、LayoutLMv2与LayoutXLM系列工作,多模态大模型预训练极大推动了文档理解研究,开辟了文档理解研究的新领域,具有很大前景。
[1] Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
[2] Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding. ACL 2021.
[3] https://bbs.huaweicloud.com/blogs/298660
[4] https://bbs.huaweicloud.com/blogs/XXXXX
[5] Xu Y, Lv T, Cui L, et al. LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding. arXiv preprint arXiv:2104.08836, 2021.
[6] https://commoncrawl.org/the-data/get-started/
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习

- 点赞
- 收藏
- 关注作者
评论(0)