【愚公系列】《数据可视化分析与实践》009-数据预处理(数据规约与数据转换)


💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node…
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
🚀前言
多样的数据源在短时间内为人们提供了海量的数据,但是这些数据非常容易受到噪声、丢失和数据格式不一致的影响。低质量的数据将干扰数据分析与可视化工作。数据科学家和工程师们通过大量的理论与实践,提出了很多数据预处理的技术,这些技术能帮助我们更好地挖掘数据中的知识和信息,本章将介绍这些数据预处理技术。
🚀一、数据规约与数据转换
数据规约与数据转换是数据预处理流程中,旨在提升数据质量、适配分析模型、并优化计算效率的两个关键环节。它们在理念上有所侧重,但实践中常协同使用。
- 数据规约 是一项旨在通过去除冗余信息、减少数据维度或总体规模来简化数据集,同时尽可能保留其关键信息与内在结构的技术。其主要目标是在不显著损失信息的前提下,降低存储与计算成本,并可能提升后续算法(如机器学习模型)的效率和性能。
- 数据转换 则是将数据从原始的表示形式或结构,转换为另一种更适用于特定分析工具、算法或业务需求的形式。其核心目标是使数据的分布、尺度或形态符合分析方法的前提假设,从而提高分析结果的准确性、可解释性和效率。
在实际应用中,需根据数据的具体特征(如维度、规模、分布)和最终的分析任务(如分类、回归、聚类、可视化),灵活选择和组合这些方法。
🔎1.数据规约
当数据集过于庞大或维度(特征)过多时,直接进行分析会面临计算效率低下、存储成本高昂、“维度灾难”导致模型泛化能力差等问题。数据规约为此提供了系统的解决方案,主要分为三大类:
🦋1.1 维规约
维规约的核心目标是减少特征(属性)的数量,即降低数据的维度。
- 属性子集选择:
- 原理:从原始特征集中,选择一个最优的特征子集。这个子集应包含最具预测力或信息量的特征,同时剔除不相关或冗余的特征。
- 方法:
- 过滤法:基于统计指标(如相关系数、卡方检验、互信息)对每个特征独立评分,选择排名靠前的特征。
- 包装法:将特征选择过程与最终使用的学习算法(如分类器)性能直接挂钩,通过迭代尝试不同的特征子集,选择使模型性能最优的组合。典型方法有递归特征消除。
- 嵌入法:在模型训练过程中自动进行特征选择。例如,Lasso回归的L1正则化会使部分特征的系数变为零,从而间接实现了特征选择。
- 主成分分析(PCA):
- 原理:一种经典的线性降维方法。它通过正交变换,将可能存在相关性的原始特征映射到一组新的、互不相关的特征(主成分)上。这些主成分按照方差从大到小排列,前k个主成分能够最大程度地保留原始数据集的变异信息。
- 应用:常用于高维数据的可视化(降至2D或3D)、数据压缩、以及去除噪声和冗余。例如,在人脸识别中,PCA可用于从大量像素中提取“特征脸”。
- 小波变换:
- 原理:一种信号处理技术,能同时在时域和频域提供良好的局部化分析能力。通过小波变换,可以将数据分解为不同频率的子带。
- 在数据规约中的应用:保留最重要的近似系数(低频部分),而舍弃或压缩细节系数(高频部分),从而实现数据的有效压缩和特征提取,常用于图像和时序数据。
🦋1.2 数量规约
数量规约的核心目标是减少数据记录(样本)的数量,用更紧凑的表示来替代原始数据集。
- 参数方法:
- 原理:假设数据服从某个参数化模型(如线性模型、概率分布),然后仅存储该模型的参数,而非所有数据点。
- 示例:用一条回归线
y = ax + b及其参数(a, b)来代表一组(x, y)数据点;用正态分布的均值μ和标准差σ来代表一组数值数据。
- 非参数方法:
- 直方图:将连续属性的值域划分为若干个区间(箱子),仅存储每个区间的计数值(频数)。这大大减少了数据量,但损失了区间内的具体数值分布。
- 聚类:将整个数据集划分为若干个簇,然后仅存储每个簇的代表(如质心)和大小。分析可以在簇的层面上进行。
- 抽样:从数据集中选取一个有代表性的子集进行分析。常用方法包括简单随机抽样、分层抽样、聚类抽样等。关键在于保证样本能有效代表总体。
🦋1.3 数据压缩
数据压缩使用特定的编码技术来减少数据的存储空间。
- 无损压缩:压缩后的数据可以完全无损地恢复为原始数据。如ZIP、GZIP等通用文件压缩格式,以及PNG图像格式。在数据分析中,适用于任何不能接受信息损失的场景。
- 有损压缩:压缩过程会永久丢弃部分信息,只能近似恢复原始数据。如JPEG图像、MP3音频。在数据规约中,许多降维方法(如PCA, 保留前k个主成分)本质上就是一种有损压缩,在压缩率(数据量减少)和信息损失之间进行权衡。
其他相关方法:
- 离散化:将连续属性转换为分类属性(如将年龄转换为“青年”、“中年”、“老年”),本身就是一种规约,因为它将无限多的可能取值简化为有限的几个类别。
- 概念分层:用更高层次、更抽象的概念替换低层数据。例如,将具体的“日期”聚合为“月份”或“季度”,将“城市”聚合为“省份”。这常用于联机分析处理中的上卷操作。
🔎2.数据转换
数据转换的核心目标是改变数据的尺度、分布或表示形式,使其更贴合后续分析算法的要求。正确的转换可以解决数据尺度不一、分布偏斜等问题,显著提升模型性能。
🦋2.1 归一化与标准化
这是两种最常用的、用于消除特征间量纲影响的转换方法。
-
归一化:
-
目的:将数据线性缩放到一个固定的范围,通常是[0, 1]。
-
公式(最小-最大归一化):

-
特点与适用场景:缩放仅依赖于极值,对异常值非常敏感。适用于边界明确、且需要将数据严格限制在特定范围(如图像像素值归一化到[0,1])的场景。当数据分布不稳定或极值未知时,效果不佳。
-
-
标准化:
-
目的:将数据转换为均值为0,标准差为1的标准正态分布(或接近)。
-
公式(Z-score标准化):
其中,
是属性 (X) 的均值,
是其标准差。 -
特点与适用场景:缩放基于数据的均值和标准差,受异常值影响相对较小(因为均值和标准差本身受异常值影响)。这是最常用的缩放方法,尤其适用于基于距离的算法(如K-均值聚类、K近邻、支持向量机、主成分分析)和梯度下降优化的模型(如逻辑回归、神经网络),因为它能加速收敛并保证各特征对模型的贡献处于同一量级。
-
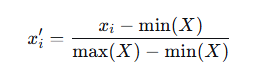
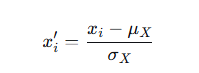
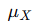

在Excel中的实现:
- 计算最大值:
=MAX(数据区域) - 计算最小值:
=MIN(数据区域) - 计算均值:
=AVERAGE(数据区域) - 计算总体标准差:
=STDEV.P(数据区域)(当数据代表整个总体时使用) - 计算样本标准差:
=STDEV.S(数据区域)(当数据仅为一个样本时使用,更常用) - 然后,利用这些函数的结果,根据上述公式在新列中编写计算公式即可完成转换。
🦋2.2 离散化
离散化是将连续型数据分割为若干区间,并用区间标签(或有序数值)替代原始连续值的过程。
-
目的:
- 适应算法:某些算法(如决策树、朴素贝叶斯)天生更适合处理分类特征。
- 简化模型:降低数据的复杂性,使模式更易理解和解释。
- 处理非线性:有时能将非线性关系转化为线性关系。
- 减少噪声影响:对区间内的微小波动不敏感。
-
常用方法:
- 等宽法:将值域划分为等宽的k个区间。简单直观,但可能因数据分布不均而导致某些区间内数据极少(甚至为空)。
- 示例:将收入0-100万等分为10个区间,每个区间宽度10万。
- 等频法(分位数法):使每个区间包含大致相同数量的数据点。能更好地处理倾斜分布,保证每个区间都有代表性。
- 示例:将学生成绩划分为“优”、“良”、“中”、“差”,确保每个等级学生人数大致相等。
- 基于聚类的方法:先使用聚类算法(如K-Means)将数据点分组,然后将同一簇的数据点划分为一个区间。区间边界由数据本身的自然聚集情况决定,更为合理。
- 示例:在客户细分中,根据消费行为数据聚类,将客户自然分为“高价值”、“中价值”、“低价值”群组。
- 基于业务知识的方法:根据领域经验直接划分。最具解释性。
- 示例:医学上根据BMI指数划分“偏瘦”、“正常”、“超重”、“肥胖”;金融风控中根据信用评分划分风险等级。
- 等宽法:将值域划分为等宽的k个区间。简单直观,但可能因数据分布不均而导致某些区间内数据极少(甚至为空)。
数据规约与数据转换是数据预处理中相辅相成的步骤:
- 当数据“太大”或“太宽”时,考虑数据规约:先用维规约(如PCA、特征选择)降低特征维度,再用数量规约(如抽样)或数据压缩减少样本数量。
- 当数据“不合适”时,考虑数据转换:对于基于距离/梯度的模型,优先进行标准化;对于需要类别输入的模型或为了提升可解释性,进行离散化。
在实践中,通常需要一个迭代过程:转换 → 规约 → 建模 → 评估效果,然后根据结果调整规约与转换的策略。没有一成不变的“最佳”方法,关键在于深入理解数据、分析目标和所用算法的特性,从而做出最合适的技术选择。

- 点赞
- 收藏
- 关注作者
评论(0)