【愚公系列】《数据可视化分析与实践》004-数据采集(数据采集概述)


💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node…
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
🚀前言
数据采集是数据分析和可视化的前提和基础。本章主要介绍数据的来源和数据采集方法,并提供一些常用数据集的获取方法。
🚀一、数据采集概述
数据采集,又称为数据获取,是数据分析和数据可视化流程的起点。它是指根据特定的分析需求和研究目标,采用适当的方法、技术和工具,从各种源头系统地获取所需数据的过程。在大数据时代,数据采集的内涵已大大扩展,它一般指从传感器、智能设备、企业信息系统、社交网络和互联网平台等广泛来源,获取RFID(射频识别)数据、传感器数据、用户行为数据、社交网络交互数据及移动互联网数据等各种类型的结构化、半结构化及非结构化数据。高效、准确、合法的数据采集是后续所有数据处理、分析与可视化工作成功的基础。
🔎1.数据的来源
数据的来源非常广泛,根据产生数据的主体、方式和场景,主要可以划分为以下几大类。
🦋1.1 政府数据
政府数据是指各级政府部门及公共机构在履行其行政管理、公共服务和社会治理职能过程中,收集、产生、管理和拥有的各类数据资源。这类数据具有权威性、宏观性和公共性的特点。
- 涵盖范围极广:包括但不限于公安、交通、医疗、卫生、就业、社保、地理、文化、教育、科技、环境、金融、统计、气象等领域的数据。例如,人口普查数据、企业工商注册信息、道路交通流量数据、空气质量监测数据等。
- 数据形式多样:既包括传统的结构化统计数据(如GDP、CPI),也包括地理空间数据、政策文本、公开报告等。
- 开放趋势:随着“数据开放”运动的推进,许多国家和地区建立了政府数据开放平台(如中国的“中国政府网数据开放平台”、data.gov等),向公众和企业提供可机器读取的数据集,以促进创新和透明治理。
- 延伸数据:也包括政府为管理服务需求而采集的外部大数据,如网络舆情监控数据、卫星遥感数据等。
🦋1.2 企业业务数据
企业业务数据是指企业在日常运营、生产、销售、服务及管理等核心业务流程中自然产生的数据。这些数据是企业资产的核心组成部分,直接反映了企业的经营状况和市场动态。
- 核心数据类型:
- 客户数据:客户基本信息、购买历史、服务记录、反馈意见等。
- 交易数据:订单、销售记录、支付流水、发票信息等。
- 运营数据:采购记录、库存水平、物流信息、生产计划与执行数据等。
- 财务数据:资产负债表、利润表、现金流量表及各类明细账。
- 人力资源数据:员工信息、考勤记录、绩效考核、培训记录等。
- 存储系统:通常存储在企业的各类信息系统中,如ERP(企业资源计划)、CRM(客户关系管理)、SCM(供应链管理)、OA(办公自动化)等系统数据库中。
- 价值:通过深度分析企业业务数据,管理者可以进行精准决策、优化业务流程、预测市场趋势、提升客户满意度,从而增强企业核心竞争力。
🦋1.3 物联网数据
物联网数据是由部署在物理世界中的各种智能设备、传感器、执行器通过感知、测量和通信产生的海量、实时、连续的数据流。
- 技术基础:主要依靠传感器技术、条形码、二维码、RFID(射频识别)、GPS/北斗等定位技术来获取数据。
- 数据特点:具有实时性、连续性、时空关联性和多模态性(如温度、湿度、压力、图像、声音、位置等)。
- 应用领域:
- 智能家居:智能电表、安防摄像头、环境传感器数据。
- 智能交通:车辆GPS轨迹、道路监控视频、交通信号灯状态数据。
- 智能工业/工业4.0:生产线设备运行参数、能耗数据、产品质量检测图像。
- 智能医疗:可穿戴健康监测设备数据、远程生命体征监测数据。
- 挑战:数据体量巨大、传输与存储成本高、需要高效的流处理技术。
🦋1.4 互联网数据
互联网数据是指在互联网空间中,由用户、平台、应用和服务交互产生的大量、多样、快速变化的数据。它是大数据中增长最快、最活跃的部分。
- 产生主体:每一个互联网用户(人、机器、程序)都是数据的创造者。
- 核心数据类型:
- 用户生成内容:社交媒体上的帖文、评论、图片、视频;电商网站的商品评价;博客、论坛文章等。
- 用户行为数据:网页点击流、搜索记录、停留时长、APP使用日志、购买行为等。
- 平台运营数据:新闻资讯、在线视频/音乐内容、商品信息、服务列表等。
- 设备与环境信息:IP地址、设备型号、浏览器类型、网络运营商、粗略位置信息等。
- 特点:非结构化或半结构化为主(文本、图像、视频、JSON/XML)、蕴含丰富的用户意图和社交关系、价值密度相对较低但洞察潜力巨大。
🔎2.数据采集的方法
面对不同来源、不同类型、不同访问权限的数据,需要采用针对性的采集方法。归纳起来,主要有以下3种主流的数据采集方法体系。
🦋2.1 利用ETL工具采集
ETL(Extract, Transform, Load)是数据仓库和商业智能领域的核心流程,专用于从异构数据源中抽取数据,并为企业分析提供清洁、整合、统一的数据视图。
- 抽取:从各种异构的源系统(如Oracle、MySQL、SQL Server、平面文件、API等)中提取数据。
- 转换:对抽取的数据进行清洗、校验、格式化、标准化、聚合、计算衍生指标等系列操作,解决数据不一致、不完整、有错误等问题。
- 加载:将转换后的数据加载到目标数据存储系统中,通常是数据仓库、数据湖或数据集市。
- 工具代表:传统工具有Informatica PowerCenter、IBM DataStage、Oracle Data Integrator;开源工具有Apache NiFi、Talend、Kettle (PDI);云原生服务有AWS Glue、Azure Data Factory、阿里云DataWorks。
- 适用场景:主要用于企业内部结构化数据的定期批量集成与同步,是构建企业级数据分析平台的基础。
🦋2.2 日志文件采集
日志文件是软件系统、应用程序或网络设备自动生成的,用于记录其运行状态、事件、错误和用户操作的文本文件。日志采集是监控系统健康和了解用户行为的关键。
- 日志内容:包括时间戳、日志级别(INFO, WARN, ERROR)、进程ID、事件描述、错误代码、用户IP、请求参数等。
- 价值:用于应用程序性能监控、安全审计、用户行为分析、故障诊断和系统优化。
- 采集挑战:分布式系统下日志分散在各服务器;数据量大且实时生成;格式不统一。
- 专用采集框架:为解决上述挑战,发展出高可靠、高可扩展的日志收集系统:
- Apache Flume:一个分布式、可靠、高可用的海量日志聚合系统,基于流式架构,适合将大量日志数据从不同源移动至中心化数据存储(如HDFS、HBase)。
- Apache Kafka:不仅是一个消息队列,更是强大的分布式流处理平台,常作为日志和事件数据的实时管道,连接数据源和处理应用。
- 其他:Facebook的Scribe、Hadoop的Chukwa等。
图2-1 Flume日志文件采集系统架构图
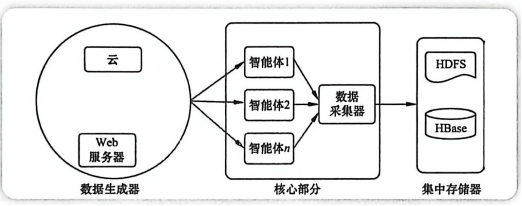
🦋2.3 互联网数据采集
互联网数据采集是指利用自动化技术,从开放的互联网资源中定向抓取、提取和汇聚信息的过程。常见的方法有以下4种:
-
下载或购买现成数据集
- 公开数据集:许多研究机构、政府、企业和竞赛平台会公开高质量的数据集。例如,Kaggle数据集、UCI机器学习库、各国政府开放数据门户、学术机构共享数据等。这是获取数据最直接、最合规的方式。
- 商业数据产品:向数据提供商(如数据堂、聚合数据、天眼查等)购买经过清洗、标注、整合的特定领域数据集。
-
使用网络爬虫技术爬取数据
- 定义:网络爬虫(Web Crawler/Spider)是一个自动下载网页内容、解析并提取结构化信息的程序或脚本。
- 流程:通常从种子URL开始,下载页面,解析并提取目标数据和新的链接,再将新链接加入队列循环处理。
- 工具与框架:
- 编程库:Python的
Scrapy(强大框架)、BeautifulSoup/lxml(解析库)、Requests(HTTP库)。 - 可视化工具:八爪鱼采集器、后羿采集器、Web Scraper(浏览器插件)等,降低了非编程人员的使用门槛。
- 编程库:Python的
- 法律与伦理:必须遵守
robots.txt协议,尊重网站版权和个人隐私,避免对目标网站造成过大访问压力。
-
通过API获取数据
- 定义:API(Application Programming Interface,应用程序编程接口)是网站或服务官方提供的、规范化的数据交互通道。
- 优势:数据格式标准(通常为JSON或XML)、获取效率高、稳定性好、通常是官方认可的数据获取方式。
- 应用:广泛用于获取社交媒体数据(微博、Twitter API)、地图服务(高德、百度地图API)、金融数据(证券交易所、财经数据API)、天气数据等。
- 限制:通常有调用频率、数据范围和用户身份的限制(需要API Key),部分高级功能可能需要付费。
-
制作并发放调查问卷获取数据
- 适用场景:当研究所需的数据尚不存在于任何现有记录或网络时,如用户满意度、特定人群的观点态度、新产品概念测试等。
- 流程:设计问卷→选择样本→发放与回收→数据清洗与分析。
- 在线工具:问卷星、问卷网、腾讯问卷、Google Forms、SurveyMonkey等提供了便捷的创建、分发和基础分析功能。
- 关键:问卷设计的科学性(避免诱导性、歧义性问题)和样本的代表性决定了数据的质量。
🔎3.数据源和数据集
在数据采集和管理的语境中,明确“数据源”和“数据集”这两个紧密相关但又不同的概念至关重要。
🦋3.1 数据源
- 定义:数据源是数据的原始出处或存储位置,它关注的是数据的“来源”和“存储”。它是一个逻辑或物理的实体,能够提供数据。
- 形式多样:可以是一个简单的文本文件(
.txt,.csv)、一个电子表格(.xlsx)、一个关系型数据库(MySQL, PostgreSQL)、一个NoSQL数据库(MongoDB, Redis)、一组API接口、一个实时数据流(Kafka Topic),甚至是来自传感器的连续信号。 - 特点:数据源是持续“活”的,可能不断有新的数据产生或更新。它是数据提取和集成操作的对象。
🦋3.2 数据集
- 定义:数据集是针对特定分析目的,从数据源中提取、加工并组织好的一个数据集合。它关注的是数据的“内容”和“结构”,是一个相对静态的、用于分析的数据产品。
- 典型结构:通常以表格形式呈现。每一列代表一个特征、属性或变量;每一行代表一个观测、实例或记录。例如,一个“客户数据集”的列可能包括
客户ID、姓名、年龄、城市、消费金额,每一行则是一个具体客户的信息。 - 目的:数据集是数据分析、机器学习建模和数据可视化的直接输入。它被设计成便于进行统计计算、模式发现和可视化呈现的形式。
🦋3.3 两者关系
- 数据源包含数据集:一个数据源可以包含一个或多个数据集。例如,一个公司的CRM数据库(数据源)中,可以导出“2023年客户交易数据集”、“高价值客户画像数据集”等多个具体的数据集。
- 数据集源自数据源:数据集总是从一个或多个数据源中派生而来。它是对数据源中原始数据进行选择、过滤、清洗、转换和聚合后的结果。
- 比喻:可以将数据源想象成一个水库,里面储存着原水(原始数据)。而数据集则是根据不同用途(如饮用水、灌溉水)从水库中抽取并经过处理(过滤、消毒)后,装在不同容器(表格、文件)中供人直接使用的水。
理解这种区别有助于在数据项目中清晰地规划:从哪个数据源,提取和准备出什么样的数据集,以服务于最终的分析与可视化目标。

- 点赞
- 收藏
- 关注作者
评论(0)