2025-12-25:根据质数下标分割数组。用go语言,给定一个整数数组 nums,把数组中下标为质数的位置上的元素划入集合 A

【摘要】 2025-12-25:根据质数下标分割数组。用go语言,给定一个整数数组 nums,把数组中下标为质数的位置上的元素划入集合 A,其余位置的元素划入集合 B。计算并返回两组元素和的绝对差值 |sum(A) - sum(B)|。说明:质数是指大于1且除了1和自身外没有其他因数的正整数;若某组为空,则其和为0。下标按数组的索引(0、1、2…)来判断是否为质数。1 <= nums.length <...
2025-12-25:根据质数下标分割数组。用go语言,给定一个整数数组 nums,把数组中下标为质数的位置上的元素划入集合 A,其余位置的元素划入集合 B。计算并返回两组元素和的绝对差值 |sum(A) - sum(B)|。
说明:质数是指大于1且除了1和自身外没有其他因数的正整数;若某组为空,则其和为0。下标按数组的索引(0、1、2…)来判断是否为质数。
1 <= nums.length <= 100000。
-1000000000 <= nums[i] <= 1000000000。
输入: nums = [-1,5,7,0]。
输出: 3。
解释:
数组中的质数下标是 2 和 3,所以 nums[2] = 7 和 nums[3] = 0 被放入数组 A。
其余元素 nums[0] = -1 和 nums[1] = 5 被放入数组 B。
sum(A) = 7 + 0 = 7,sum(B) = -1 + 5 = 4。
绝对差值是 |7 - 4| = 3。
题目来自力扣3618。
| 步骤 | 核心任务 | 关键点说明 |
|---|---|---|
| 1. 质数表预处理 | 使用埃拉托斯特尼筛法,预先生成一个大小为 mx (100,000) 的布尔数组 np,标记每个数是否为非质数。 |
标记时从2开始,将其倍数标记为非质数。只需遍历到 i*i < mx,因为更大数的倍数已被更小的质数处理过。 |
| 2. 遍历数组并求和 | 遍历输入数组 nums,根据当前下标 i 是否为质数,将元素值累加到不同的和中。 |
质数下标元素值累加到集合A的和;非质数下标元素值累加到集合B的和。直接使用预处理的 np 数组判断,时间复杂度为O(1)。 |
| 3. 计算绝对差值 | 计算集合A之和与集合B之和的绝对差值 ` | sum(A) - sum(B) |
⏱️ 复杂度分析
下面详细分析该算法的时间复杂度和额外空间复杂度。
-
总的时间复杂度:O(mx log log mx + n)。
- 质数筛预处理阶段:埃拉托斯特尼筛法的时间复杂度为 O(mx log log mx)。由于
mx是固定的100,000,这部分时间可视为常数操作,但其计算量在理论分析中仍需计入。 - 主循环阶段:需要遍历整个长度为
n的输入数组nums,每次判断和累加操作都是 O(1) 时间。因此这部分是 O(n)。 - 两者相加,总时间复杂度为 O(mx log log mx + n)。鉴于
n最大为100,000,而mx也是100,000,这个复杂度是高效的。
- 质数筛预处理阶段:埃拉托斯特尼筛法的时间复杂度为 O(mx log log mx)。由于
-
总的额外空间复杂度:O(mx)。
- 算法除了输入数据外,主要使用了固定大小的全局布尔数组
np,其长度为mx(100,000)。这个空间占用是主要的额外开销。 - 其他变量(如累加和)只占用常数空间。因此,总的空间复杂度由预处理数组决定,为 O(mx)。
- 算法除了输入数据外,主要使用了固定大小的全局布尔数组
Go完整代码如下:
package main
import (
"fmt"
)
const mx = 100_000
var np = [mx]bool{true, true} // 0 和 1 不是质数
func init() {
for i := 2; i*i < mx; i++ {
if !np[i] {
for j := i * i; j < mx; j += i {
np[j] = true
}
}
}
}
func splitArray(nums []int) (ans int64) {
for i, x := range nums {
if np[i] {
ans -= int64(x)
} else {
ans += int64(x)
}
}
if ans < 0 {
ans = -ans
}
return
}
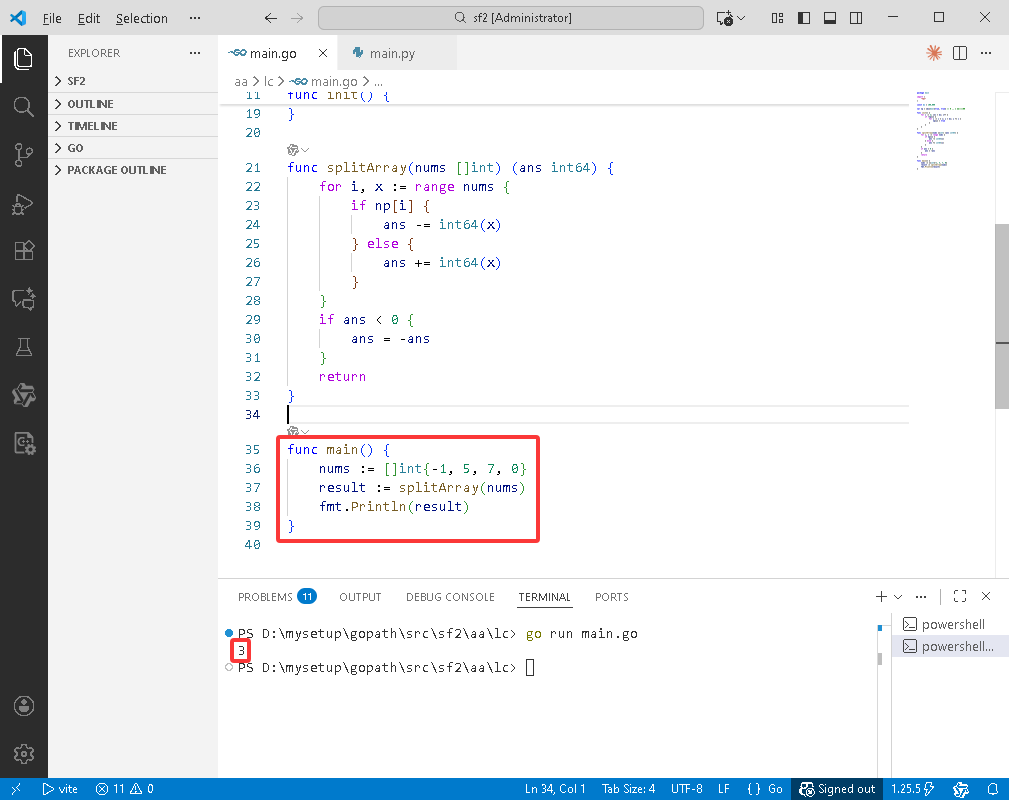
func main() {
nums := []int{-1, 5, 7, 0}
result := splitArray(nums)
fmt.Println(result)
}
Python完整代码如下:
# -*-coding:utf-8-*-
import math
# 预计算质数
mx = 100_000
np = [True] * mx # 初始化所有数为质数
np[0] = np[1] = False # 0 和 1 不是质数
# 埃拉托斯特尼筛法
for i in range(2, int(math.sqrt(mx)) + 1):
if not np[i]:
continue
for j in range(i * i, mx, i):
np[j] = False
def split_array(nums):
ans = 0
for i, x in enumerate(nums):
if np[i]:
ans += x
else:
ans -= x
return abs(ans)
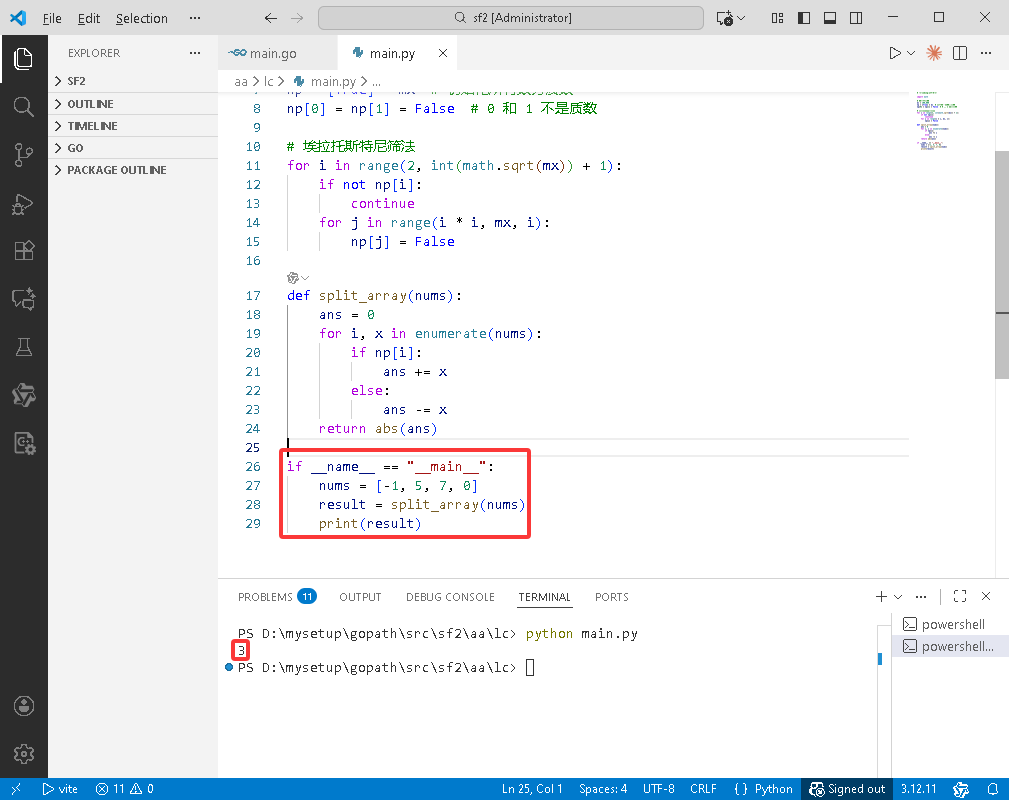
if __name__ == "__main__":
nums = [-1, 5, 7, 0]
result = split_array(nums)
print(result)
C++完整代码如下:
#include <iostream>
#include <vector>
#include <cmath>
#include <cstdint>
const int MX = 100000;
bool np[MX] = {true, true}; // 0 和 1 不是质数
void init() {
for (int i = 2; i * i < MX; i++) {
if (!np[i]) {
for (int j = i * i; j < MX; j += i) {
np[j] = true;
}
}
}
}
int64_t splitArray(const std::vector<int>& nums) {
int64_t ans = 0;
for (int i = 0; i < nums.size(); i++) {
if (np[i]) {
ans -= static_cast<int64_t>(nums[i]);
} else {
ans += static_cast<int64_t>(nums[i]);
}
}
if (ans < 0) {
ans = -ans;
}
return ans;
}
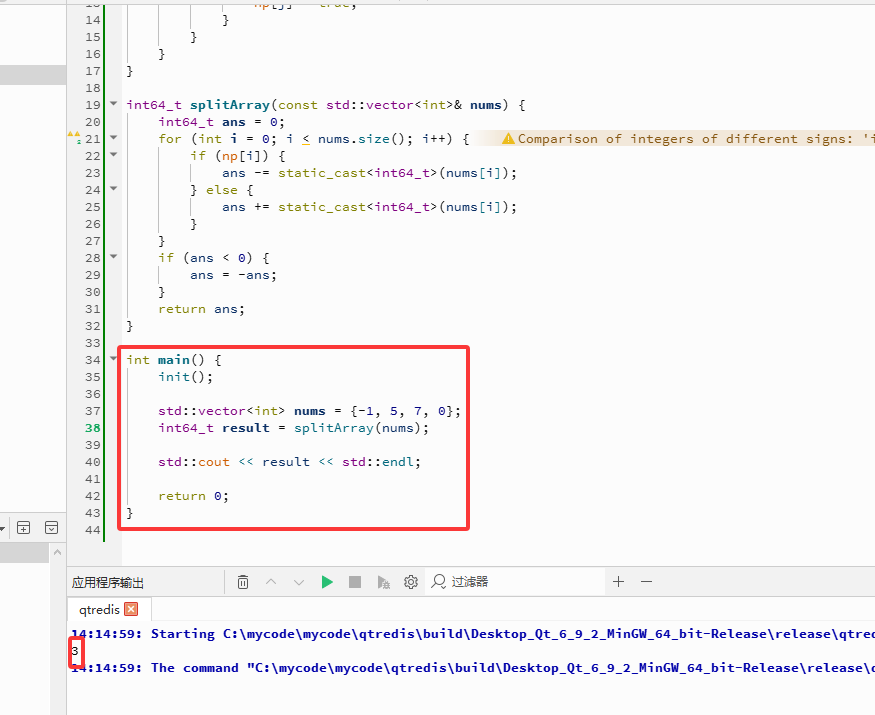
int main() {
init();
std::vector<int> nums = {-1, 5, 7, 0};
int64_t result = splitArray(nums);
std::cout << result << std::endl;
return 0;
}

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)