2025-12-04:第 K 小的路径异或和。用go语言,给出一棵以节点 0 为根的无向树,节点编号为 0..n-1,父节点信息

2025-12-04:第 K 小的路径异或和。用go语言,给出一棵以节点 0 为根的无向树,节点编号为 0…n-1,父节点信息由数组 par 给出,每个节点 i 还带有一个整数标签 vals[i]。定义每个节点 u 的“根到 u 的异或值”为沿着从根 0 到节点 u 的路径上所有节点的 vals 的按位异或(包含端点)。
对于每个查询 queries[j] = [u_j, k_j],考虑以 u_j 为根的子树中所有节点 v 的根到 v 的异或值,取这些异或值的不同(去重后)集合并按从小到大排序,返回该序列的第 k_j 个数;如果不同的异或值个数不足 k_j,则答案为 -1。
说明:这里的“子树”指节点 u 及其所有后代节点(即从根到这些节点的路径都经过 u)。最终要求返回一个数组,数组中第 j 个元素对应第 j 个查询的答案。
1 <= n == vals.length <= 5 * 10000。
0 <= vals[i] <= 100000。
par.length == n。
par[0] == -1。
对于 [1, n - 1] 中的 i,0 <= par[i] < n。
1 <= queries.length <= 5 * 10000。
queries[j] == [uj, kj]。
0 <= uj < n。
1 <= kj <= n。
输出保证父数组 par 表示一棵合法的树。
输入:par = [-1,0,1], vals = [5,2,7], queries = [[0,1],[1,2],[1,3],[2,1]]。
输出:[0,7,-1,0]。
解释:
路径异或值:
节点 0:5
节点 1:5 XOR 2 = 7
节点 2:5 XOR 2 XOR 7 = 0
子树与不同路径异或值:
0 的子树:以节点 0 为根的子树包含节点 [0, 1, 2],路径异或值为 [5, 7, 0]。不同的异或值为 [0, 5, 7]。
1 的子树:以节点 1 为根的子树包含节点 [1, 2],路径异或值为 [7, 0]。不同的异或值为 [0, 7]。
2 的子树:以节点 2 为根的子树包含节点 [2],路径异或值为 [0]。不同的异或值为 [0]。
查询:
queries[0] = [0, 1]:节点 0 的子树中,第 1 小的不同路径异或值为 0。
queries[1] = [1, 2]:节点 1 的子树中,第 2 小的不同路径异或值为 7。
queries[2] = [1, 3]:由于子树中只有两个不同路径异或值,答案为 -1。
queries[3] = [2, 1]:节点 2 的子树中,第 1 小的不同路径异或值为 0。
输出:[0, 7, -1, 0]
题目来自力扣3590。
🏗️ 步骤1:构建树结构
代码首先根据父节点数组 par 构建树的邻接表表示 g。节点 0 是根节点。对于每个非根节点 i(i 从 1 到 n-1),根据 par[i] 找到其父节点,并将 i 添加到父节点的子节点列表中。这样,g[p] 就存储了节点 p 的所有直接子节点,形成了树的连接关系。
🔄 步骤2:DFS遍历与路径异或值计算
通过一次深度优先搜索(DFS)遍历树,同时完成两件事:
- 计算路径异或值:从根节点
0开始,维护一个累积异或值xor。访问每个节点x时,将xor与当前节点的标签值vals[x]进行异或操作,得到从根节点到x的路径异或值。这个值被存储在数组a中,存储的位置由全局 DFS 序计数器dfn决定。 - 记录DFS序范围:同时,为每个节点
x记录一个区间[ranges[x].l, ranges[x].r)。这个区间是左闭右开的,它表示在 DFS 序中,以x为根的子树所包含的所有节点的索引范围。ranges[x].l是节点x自身的开始位置,ranges[x].r是其最后一个后代节点之后的位置。
这个步骤利用了异或运算的一个重要性质:树中任意两节点 u 和 v 之间的路径异或值,等于它们各自到根节点的路径异或值的异或结果,即 xor[u] ^ xor[v]。但在此问题中,我们关注的是每个节点自身到根节点的路径异或值。
📊 步骤3:离散化路径异或值
数组 a 现在包含了所有节点到根节点的路径异或值(按DFS序排列)。为了后续高效处理(尤其是在使用莫队算法时),需要将这些可能很大的整数值映射到一个小范围的整数索引上:
- 将数组
a克隆一份得到b。 - 对
b进行排序并去重,得到一个有序且无重复的异或值列表。 - 然后,遍历原始数组
a,将每个异或值替换为它在排序去重后列表b中的索引位置。这个过程称为离散化。完成后,a中存储的不再是原始的异或值,而是其在b中的下标(从0开始)。
🔍 步骤4:使用莫队算法处理查询
查询要求找出给定节点子树中所有不同路径异或值按升序排列后的第 k 小的值。代码使用莫队算法来高效处理这些离线查询:
- 查询分块与排序:根据每个查询对应的子树在DFS序中的区间范围(即
[ranges[u].l, ranges[u].r)),将查询分组。计算一个合适的块大小qBlockSize,通常与n / sqrt(查询数量)相关。然后根据查询区间的左端点所在的块ID对查询进行排序,同一块内的查询再根据右端点进行奇偶化排序,以减少指针移动的总距离。 - 维护区间计数:莫队算法维护一个当前处理的区间
[l, r),以及两个核心数组:cnt数组:记录在当前区间[l, r)内,每个离散化后的异或值(即a中的索引)出现的次数。blockUniqueCnt数组:这是一个分块计数数组,用于快速查找第k小的不同值。它将离散化后的值域(0到m-1,m是不同异或值的个数)分成若干块,blockUniqueCnt[i]记录第i块中当前区间内至少出现一次的值的个数(即不同值的个数)。
- 移动指针处理查询:按排序后的顺序依次处理每个查询。通过移动指针
l和r来调整当前区间,使其与查询区间一致。在移动指针时,调用move函数更新cnt和blockUniqueCnt数组。当向区间内加入一个新位置i时,对应值v = a[i]的计数cnt[v]增加,如果从0变为1,则其所在值块的blockUniqueCnt[v/cBlockSize]加1;反之,当从区间内移除一个位置时,进行相反的操作。
✅ 步骤5:回答每个查询
对于每个查询,当莫队算法的当前区间 [l, r) 调整到与查询区间一致后:
- 当前区间对应着查询节点
u_j的子树在DFS序上的所有节点。 cnt数组反映了这个子树内每个离散化路径异或值出现的频率。由于我们关心的是不同的异或值,所以只需要关注哪些值的cnt大于0。- 为了找到第
k_j小的不同异或值,代码遍历值域块数组blockUniqueCnt:- 顺序检查每个值块,如果第
k_j小的值不在当前块,则k减去该块内不同值的个数(blockUniqueCnt[i])。 - 当找到某个块
i,其blockUniqueCnt[i]>= 当前的k时,就在这个块内线性扫描,找到第k个cnt值大于0的离散化值索引j。 - 这个索引
j对应着离散化前列表b中的原始异或值b[j],这就是答案。
- 顺序检查每个值块,如果第
- 如果遍历完所有块,
k仍然大于0,说明子树中不同的异或值个数不足k_j,则答案为-1。
⏱️ 时间复杂度分析
- 树构建与DFS遍历:O(n)
- 离散化:排序和去重操作的时间复杂度为 O(n log n)
- 莫队算法处理查询:
- 排序所有查询:O(nq log nq),其中
nq是查询数量。 - 指针移动:在莫队算法中,左右指针的移动次数平均为 O(n √nq)
- 每个查询的回答:由于值域分块,查找第
k小值的复杂度为 O(√m),其中m是不同路径异或值的数量(m ≤ n)。
- 排序所有查询:O(nq log nq),其中
总时间复杂度大致为 O(n log n + nq log nq + n √nq + nq √n)。在给定的约束条件下(n, nq <= 50000),这个复杂度是可行的。
💾 空间复杂度分析
- 树结构的邻接表:O(n)
- 存储路径异或值、DFS序范围的数组:O(n)
- 离散化映射数组:O(n)
- 莫队算法所需的计数数组
cnt和值域块数组blockUniqueCnt:O(n) - 存储查询及中间结果:O(nq)
总额外空间复杂度为 O(n + nq)。
这个过程通过巧妙结合DFS序、离散化、莫队算法和值域分块,高效地解决了树上路径异或值的第K小查询问题。
Go完整代码如下:
package main
import (
"fmt"
"math"
"slices"
"sort"
)
func kthSmallest(par []int, vals []int, queries [][]int) []int {
n := len(par)
g := make([][]int, n)
for i := 1; i < n; i++ {
p := par[i]
g[p] = append(g[p], i)
}
a := make([]int, n)
ranges := make([]struct{ l, r int }, n) // 左闭右开 [l,r)
dfn := 0
var dfs func(int, int)
dfs = func(x, xor int) {
ranges[x].l = dfn
xor ^= vals[x]
a[dfn] = xor
dfn++
for _, y := range g[x] {
dfs(y, xor)
}
ranges[x].r = dfn
}
dfs(0, 0)
// 排序去重
b := slices.Clone(a)
slices.Sort(b)
b = slices.Compact(b)
// 离散化
for i, v := range a {
a[i] = sort.SearchInts(b, v) // 从 0 开始
}
nq := len(queries)
qBlockSize := int(math.Ceil(float64(n) / math.Sqrt(float64(nq*2))))
type query struct{ bid, l, r, k, qid int } // 左闭右开 [l,r)
qs := make([]query, nq)
for i, q := range queries {
p := ranges[q[0]]
qs[i] = query{p.l / qBlockSize, p.l, p.r, q[1], i}
}
slices.SortFunc(qs, func(a, b query) int {
if a.bid != b.bid {
return a.bid - b.bid
}
// 奇偶化排序
if a.bid%2 == 0 {
return a.r - b.r
}
return b.r - a.r
})
m := len(b)
cBlockSize := int(math.Sqrt(float64(m)))
blockUniqueCnt := make([]int, (m-1)/cBlockSize+1)
cnt := make([]int, m+1)
move := func(i, delta int) {
v := a[i]
if delta > 0 {
if cnt[v] == 0 {
blockUniqueCnt[v/cBlockSize]++
}
cnt[v]++
} else {
cnt[v]--
if cnt[v] == 0 {
blockUniqueCnt[v/cBlockSize]--
}
}
}
ans := make([]int, len(qs))
l, r := 0, 0
for _, q := range qs {
for ; l < q.l; l++ {
move(l, -1)
}
for l > q.l {
l--
move(l, 1)
}
for ; r < q.r; r++ {
move(r, 1)
}
for r > q.r {
r--
move(r, -1)
}
k := q.k
for i, c := range blockUniqueCnt {
if k <= c {
for j := i * cBlockSize; ; j++ {
if cnt[j] == 0 {
continue
}
k--
if k == 0 {
ans[q.qid] = b[j]
break
}
}
break
}
k -= c
}
if k > 0 {
ans[q.qid] = -1
}
}
return ans
}
func main() {
par := []int{-1, 0, 1}
vals := []int{5, 2, 7}
queries := [][]int{{0, 1}, {1, 2}, {1, 3}, {2, 1}}
result := kthSmallest(par, vals, queries)
fmt.Println(result)
}
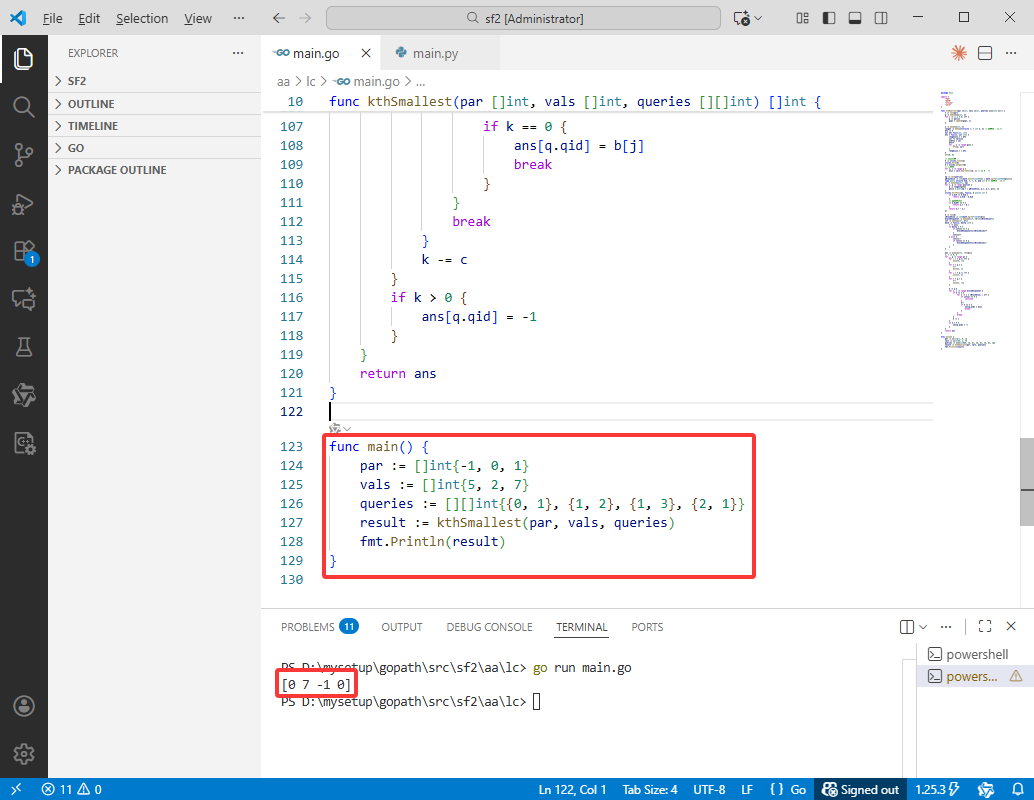
Python完整代码如下:
# -*-coding:utf-8-*-
import math
from typing import List
import bisect
class Solution:
def kthSmallest(self, par: List[int], vals: List[int], queries: List[List[int]]) -> List[int]:
n = len(par)
# 构建树结构
g = [[] for _ in range(n)]
for i in range(1, n):
p = par[i]
g[p].append(i)
# 欧拉序(DFS序)
a = [0] * n
ranges = [[0, 0] for _ in range(n)] # 左闭右开 [l, r)
dfn = 0
def dfs(x: int, xor_val: int):
nonlocal dfn
ranges[x][0] = dfn
xor_val ^= vals[x]
a[dfn] = xor_val
dfn += 1
for y in g[x]:
dfs(y, xor_val)
ranges[x][1] = dfn
dfs(0, 0)
# 离散化
b = sorted(set(a))
# 将a转换为离散化后的值(从0开始)
for i in range(n):
a[i] = bisect.bisect_left(b, a[i])
m = len(b)
nq = len(queries)
# 莫队分块大小
q_block_size = math.ceil(n / math.sqrt(nq * 2)) if nq > 0 else math.ceil(math.sqrt(n))
queries_with_id = []
for i, q in enumerate(queries):
p = ranges[q[0]]
block_id = p[0] // q_block_size
queries_with_id.append((block_id, p[0], p[1], q[1], i))
# 莫队排序:按块排序,块内奇偶化排序
queries_with_id.sort(key=lambda x: (x[0], x[2] if x[0] % 2 == 0 else -x[2]))
# 值域分块
c_block_size = math.ceil(math.sqrt(m)) if m > 0 else 1
block_cnt = (m - 1) // c_block_size + 1
block_unique_cnt = [0] * block_cnt
cnt = [0] * (m + 1)
def move(idx: int, delta: int):
v = a[idx]
if delta > 0:
if cnt[v] == 0:
block_unique_cnt[v // c_block_size] += 1
cnt[v] += 1
else:
cnt[v] -= 1
if cnt[v] == 0:
block_unique_cnt[v // c_block_size] -= 1
ans = [0] * nq
l, r = 0, 0
for block_id, ql, qr, k, qid in queries_with_id:
# 移动左指针
while l < ql:
move(l, -1)
l += 1
while l > ql:
l -= 1
move(l, 1)
# 移动右指针
while r < qr:
move(r, 1)
r += 1
while r > qr:
r -= 1
move(r, -1)
# 查找第k小的不同值
current_k = k
found = -1
for i in range(block_cnt):
if current_k <= block_unique_cnt[i]:
# 在这个块内查找
start = i * c_block_size
end = min(start + c_block_size, m)
for j in range(start, end):
if cnt[j] > 0:
current_k -= 1
if current_k == 0:
found = b[j]
break
if found != -1:
break
else:
current_k -= block_unique_cnt[i]
ans[qid] = found
return ans
# 测试代码
if __name__ == "__main__":
solution = Solution()
par = [-1, 0, 1]
vals = [5, 2, 7]
queries = [[0, 1], [1, 2], [1, 3], [2, 1]]
result = solution.kthSmallest(par, vals, queries)
print(result)
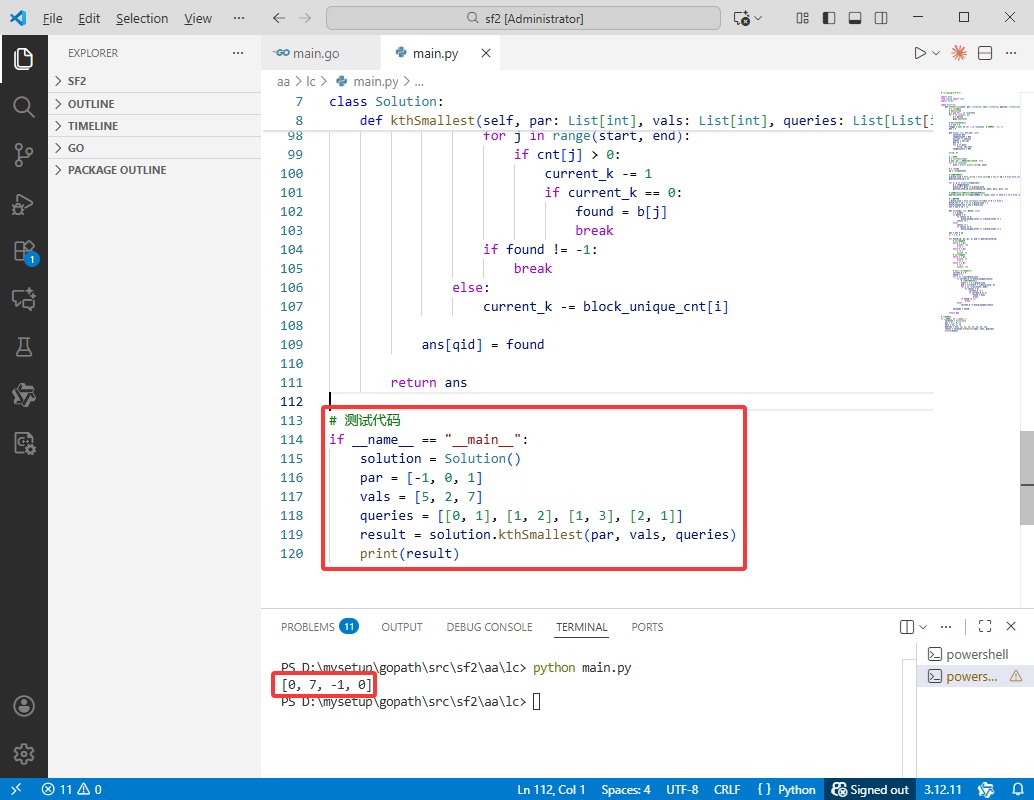
C++完整代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Range {
int l, r; // 左闭右开 [l, r)
};
struct Query {
int bid, l, r, k, qid;
};
vector<int> kthSmallest(vector<int>& par, vector<int>& vals, vector<vector<int>>& queries) {
int n = par.size();
vector<vector<int>> g(n);
for (int i = 1; i < n; i++) {
int p = par[i];
g[p].push_back(i);
}
vector<int> a(n);
vector<Range> ranges(n);
int dfn = 0;
function<void(int,int)> dfs = [&](int x, int xorsum) {
ranges[x].l = dfn;
xorsum ^= vals[x];
a[dfn] = xorsum;
dfn++;
for (int y : g[x]) {
dfs(y, xorsum);
}
ranges[x].r = dfn;
};
dfs(0, 0);
// 排序去重
vector<int> b = a;
sort(b.begin(), b.end());
b.erase(unique(b.begin(), b.end()), b.end());
// 离散化
for (int &v : a) {
v = lower_bound(b.begin(), b.end(), v) - b.begin();
}
int nq = queries.size();
int qBlockSize = ceil((double)n / sqrt((double)nq * 2.0));
vector<Query> qs(nq);
for (int i = 0; i < nq; i++) {
auto &q = queries[i];
Range p = ranges[q[0]];
qs[i] = { p.l / qBlockSize, p.l, p.r, q[1], i };
}
sort(qs.begin(), qs.end(), [&](const Query& A, const Query& B){
if (A.bid != B.bid) return A.bid < B.bid;
if (A.bid % 2 == 0) return A.r < B.r;
return A.r > B.r;
});
int m = b.size();
int cBlockSize = sqrt((double)m);
vector<int> blockUniqueCnt((m - 1) / cBlockSize + 1);
vector<int> cnt(m + 1, 0);
auto move = [&](int i, int delta) {
int v = a[i];
if (delta > 0) {
if (cnt[v] == 0) {
blockUniqueCnt[v / cBlockSize]++;
}
cnt[v]++;
} else {
cnt[v]--;
if (cnt[v] == 0) {
blockUniqueCnt[v / cBlockSize]--;
}
}
};
vector<int> ans(nq);
int l = 0, r = 0;
for (auto &q : qs) {
while (l < q.l) { move(l, -1); l++; }
while (l > q.l) { l--; move(l, 1); }
while (r < q.r) { move(r, 1); r++; }
while (r > q.r) { r--; move(r, -1); }
int k = q.k;
bool found = false;
for (int i = 0; i < (int)blockUniqueCnt.size(); i++) {
if (k <= blockUniqueCnt[i]) {
for (int j = i * cBlockSize; j < m; j++) {
if (cnt[j] == 0) continue;
k--;
if (k == 0) {
ans[q.qid] = b[j];
found = true;
break;
}
}
break;
}
k -= blockUniqueCnt[i];
}
if (!found) {
ans[q.qid] = -1;
}
}
return ans;
}
int main() {
vector<int> par = {-1, 0, 1};
vector<int> vals = {5, 2, 7};
vector<vector<int>> queries = {{0, 1}, {1, 2}, {1, 3}, {2, 1}};
vector<int> result = kthSmallest(par, vals, queries);
for (int v : result) cout << v << " ";
cout << "\n";
}

- 点赞
- 收藏
- 关注作者
评论(0)