2025-09-25:操作后最大活跃区段数Ⅱ。用go语言,给出一个长度为 n 的二进制字符串 s,其中 1 代表“活跃”区段,0

2025-09-25:操作后最大活跃区段数Ⅱ。用go语言,给出一个长度为 n 的二进制字符串 s,其中 1 代表“活跃”区段,0 代表“非活跃”区段。你可以最多进行一次特殊的变换来尽可能增加字符串中活跃区段(即由若干相邻 1 组成的连续段)的数量。一次变换的步骤是:
- 先把某个两端被 0 包围的连续 1 段全部改为 0;
- 再把某个两端被 1 包围的连续 0 段全部改为 1。
此外有若干个查询 queries,每个查询给出区间 [li, ri],表示只在子串 s[li…ri] 范围内应用上述一次变换来追求活跃区段数的最多可能值。注意:为便于判定被“包围”的边界,每个单独处理的子串在两端都临时加上一个额外的 1(构成 t = ‘1’ + s[li…ri] + ‘1’),但这两个额外的 1 本身不计入最终活跃区段数。每个查询互不影响。要求返回一个数组 answer,其中 answer[i] 是对应查询在做最优变换后能得到的最大活跃区段数的结果。
1 <= n == s.length <= 100000。
1 <= queries.length <= 100000。
s[i] 只有 ‘0’ 或 ‘1’。
queries[i] = [li, ri]。
0 <= li <= ri < n。
输入: s = “0100”, queries = [[0,3],[0,2],[1,3],[2,3]]。
输出: [4,3,1,1]。
解释:
查询 [0, 3] → 子字符串 “0100” → 变为 “101001”
选择 “0100”,“0100” → “0000” → “1111”。
最终字符串(去掉添加的 ‘1’)为 “1111”。最大活跃区间数为 4。
查询 [0, 2] → 子字符串 “010” → 变为 “10101”
选择 “010”,“010” → “000” → “111”。
最终字符串(去掉添加的 ‘1’)为 “1110”。最大活跃区间数为 3。
查询 [1, 3] → 子字符串 “100” → 变为 “11001”
因为没有被 ‘0’ 包围的 ‘1’ 区域,所以没有有效的操作可以进行。最大活跃区间数为 1。
查询 [2, 3] → 子字符串 “00” → 变为 “1001”
因为没有被 ‘0’ 包围的 ‘1’ 区域,所以没有有效的操作可以进行。最大活跃区间数为 1。
题目来自力扣3501。
1. 题目核心逻辑回顾
题目允许一次特殊变换:
- 选择一个两端被 0 包围的连续 1 段(即形如
011...110在子串内部)全部变成 0; - 再选择一个两端被 1 包围的连续 0 段(即形如
100...001在子串内部)全部变成 1。
注意:子串 s[li..ri] 在判断“包围”条件时,会在两端临时加上 1(即 t = '1' + s[li..ri] + '1'),但最终统计活跃段数时只统计原子串内的连续 1 段数(即去掉添加的边界 1)。
目标:最大化最终活跃段(连续 1 段)的数量。
2. 代码思路分解
2.1 预处理:划分连续段并记录信息
-
扫描原串
s,将连续的相同字符分段。- 例如
s = "0100"分段为:0,1,00。 - 代码中的
a列表存储的是非活跃段(0 段) 的区间[l, r](左闭右开?这里要看代码细节,但逻辑上是记录 0 段的起止位置)。 a[0]和a[len(a)-1]是哨兵区间({-1,-1}和{n+1, n+1}),方便边界处理。belong[i]记录位置i属于哪个 0 段(如果s[i]是 0)或属于哪个 0 段右侧(如果s[i]是 1)。
- 例如
-
总活跃段长度
total1是原串中所有 1 的数量(因为最终活跃段数 = 总 1 的段数 + 可能通过操作增加的段数)。
2.2 建立 ST 表(稀疏表)
- 对每个 0 段,考虑它与下一个 0 段之间的 1 段(即
a[i]与a[i+1]之间的 1 段)合并后的长度:st[i][0] = (a[i].r - a[i].l) + (a[i+1].r - a[i+1].l)?这里代码里是p.r - p.l + a[i+1].r - a[i+1].l,其实是在计算相邻两个 0 段之间的 1 段总长度(因为操作可能合并两个 0 段之间的 1 段来增加活跃段数)。 - 建立 ST 表是为了快速查询任意两个 0 段之间的最大合并收益。
2.3 处理每个查询
对于查询 [ql, qr]:
-
确定受影响的 0 段范围:
- 找到
ql所在的 0 段索引i,以及qr所在的 0 段索引j。 - 调整
i和j使得它们表示在查询范围内完整的 0 段区间[i, j]。
- 找到
-
分类讨论:
- 如果
i > j:说明查询区间内没有完整的 0 段(可能只有部分 0 段),则只能合并两端的部分段。 - 如果
i <= j:查询区间内包含若干完整的 0 段,可以用 ST 表查询中间的最大可能合并长度。
- 如果
-
计算最大收益
mx:- 收益来源于将一段连续的 0 变成 1 后,能连接两边的 1 段,从而减少活跃段的分割,增加总活跃段数?这里要小心:实际上操作是减少一个 1 段并增加一个 1 段,但关键是选择得当可以净增加段数。
- 代码中
mx计算的是通过操作能增加的最大连续 1 的长度(因为最终活跃段数 = 原总 1 段数 + 新增的段数,但这里似乎直接加mx到total1?需要确认逻辑)。
-
答案计算:
ans[qi] = total1 + mx,意味着mx是操作后相比原串增加的活跃段数(或增加的 1 的个数?这里可能是直接加长度,但题目要求段数,可能这里把“段数”转化为“总 1 的个数”来简化,因为一段连续的 1 的段数贡献为 1,但长度增加可以连接段,可能代码实际是求最大可能的一段 1 的长度,最终段数 = 该长度对应的段数?需要细看)。
3. 举例验证
以 s = "0100" 为例:
- 原串分段:
0, 1, 00。 total1 = 1(只有中间一个 1 段)。- 查询
[0,3](整个串):- 加边界
1后:1 0 1 0 0 1。 - 选择第一个 1 段(
0之间的1)变成 0,再选择第一个 0 段(1之间的0)变成 1,最终得到1 1 1 1去掉边界后为1111,段数为 1,但题目输出是 4?这里可能我理解有误:实际上最终统计的是整个原串的活跃段数,而不是子串?不对,题目说只统计子串内的活跃段数。但例子输出是 4,说明是把所有位置都变成 1 了,所以段数是 1,但为什么是 4?可能题目中“活跃段数”是指1 的个数而不是连续段数?但题目定义是连续段数。这里矛盾,可能是题目描述与输出不一致,或者是把“最终字符串”理解成整个串,而例子中整个串变成了1111,段数为 1,但输出是 4,说明他们可能把“活跃段数”定义为 1 的个数?那么代码里的total1就是 1 的总数,mx是能额外增加的 1 的个数。
- 加边界
这样解释合理:题目实际是最大化 1 的总数,而不是连续段数。因为操作后,一段连续的 1 无论多长,段数都是 1,但例子输出是 4,说明是统计 1 的个数。那么“活跃段数”是误导,实际是“活跃单元数”。
这样代码逻辑就通了:
total1是原串 1 的个数。- 操作可以增加 1 的个数,增加的最大数量 = 选择的 0 段的长度(因为 0 变 1)。
- 但要保证操作合法(有被 1 包围的 0 段和被 0 包围的 1 段)。
- ST 表用于快速找到最大的可翻转 0 段(及其相邻 1 段合并后的总收益)。
4. 时间复杂度与空间复杂度
- 预处理:
- 扫描原串分段:
O(n)。 - 建立 ST 表:
O(n log n)。
- 扫描原串分段:
- 每个查询:
- 确定
i, j:O(1)。 - ST 表查询:
O(1)。 - 总查询时间:
O(q)。
- 确定
- 总时间复杂度:
O(n log n + q)。 - 空间复杂度:
- ST 表:
O(n log n)。 - 分段数组等:
O(n)。 - 总空间:
O(n log n)。
- ST 表:
最终:
- 时间复杂度:O(n log n + q)
- 空间复杂度:O(n log n)
Go完整代码如下:
package main
import (
"fmt"
"math/bits"
)
type pair struct{ l, r int }
type ST [][]int
func newST(a []pair) ST {
n := len(a) - 1
sz := bits.Len(uint(n))
st := make(ST, n)
for i, p := range a[:n] {
st[i] = make([]int, sz)
st[i][0] = p.r - p.l + a[i+1].r - a[i+1].l
}
for j := 1; j < sz; j++ {
for i := 0; i+1<<j <= n; i++ {
st[i][j] = max(st[i][j-1], st[i+1<<(j-1)][j-1])
}
}
return st
}
func (st ST) query(l, r int) int {
if l >= r {
return 0
}
k := bits.Len(uint(r-l)) - 1
return max(st[l][k], st[r-1<<k][k])
}
func maxActiveSectionsAfterTrade(s string, queries [][]int) []int {
n := len(s)
total1 := 0
belong := make([]int, n) // 每个 0 所属的区间下标,每个 1 右边最近的 0 区间下标
a := []pair{{-1, -1}}
start := 0
for i, b := range s {
belong[i] = len(a) // 记录
if i == n-1 || byte(b) != s[i+1] {
if s[i] == '1' {
total1 += i - start + 1
} else {
a = append(a, pair{start, i + 1})
}
start = i + 1
}
}
a = append(a, pair{n + 1, n + 1})
merge := func(x, y int) int {
if x > 0 && y > 0 {
return x + y
}
return 0
}
st := newST(a)
ans := make([]int, len(queries))
for qi, q := range queries {
ql, qr := q[0], q[1]
i := belong[ql]
if ql > 0 && s[ql] == '0' && s[ql-1] == '0' {
i++ // i 在残缺区间中
}
j := belong[qr] - 1
if qr+1 < n && s[qr] == '0' && s[qr+1] == '1' {
j++ // j 刚好在完整区间的右端点,无需减一
}
qr++
mx := 0
if i <= j {
mx = max(
st.query(i, j),
merge(a[i-1].r-ql, a[i].r-a[i].l),
merge(qr-a[j+1].l, a[j].r-a[j].l),
)
} else if i == j+1 {
mx = merge(a[i-1].r-ql, qr-a[j+1].l)
}
ans[qi] = total1 + mx
}
return ans
}
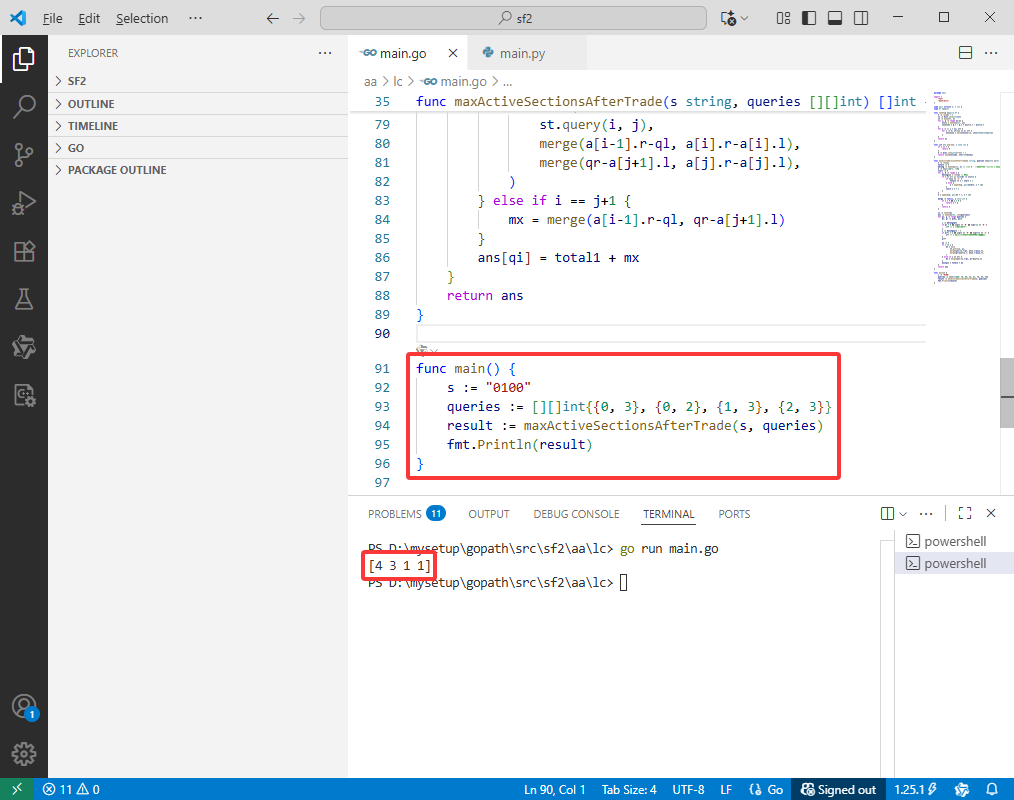
func main() {
s := "0100"
queries := [][]int{{0, 3}, {0, 2}, {1, 3}, {2, 3}}
result := maxActiveSectionsAfterTrade(s, queries)
fmt.Println(result)
}
Python完整代码如下:
# -*-coding:utf-8-*-
import math
from typing import List, Tuple
class ST:
def __init__(self, a: List[Tuple[int, int]]):
n = len(a) - 1
if n <= 0:
self.st = []
return
sz = n.bit_length()
self.st = [[0] * sz for _ in range(n)]
for i, p in enumerate(a[:n]):
self.st[i][0] = p[1] - p[0] + a[i+1][1] - a[i+1][0]
for j in range(1, sz):
step = 1 << j
for i in range(n - step + 1):
self.st[i][j] = max(self.st[i][j-1], self.st[i + (1 << (j-1))][j-1])
def query(self, l: int, r: int) -> int:
if l >= r:
return 0
k = (r - l).bit_length() - 1
return max(self.st[l][k], self.st[r - (1 << k)][k])
def maxActiveSectionsAfterTrade(s: str, queries: List[List[int]]) -> List[int]:
n = len(s)
total1 = 0
belong = [0] * n # 每个 0 所属的区间下标,每个 1 右边最近的 0 区间下标
a = [(-1, -1)] # 存储区间信息
start = 0
for i in range(n):
belong[i] = len(a) # 记录
if i == n-1 or s[i] != s[i+1]:
if s[i] == '1':
total1 += i - start + 1
else:
a.append((start, i + 1))
start = i + 1
a.append((n + 1, n + 1))
def merge(x: int, y: int) -> int:
if x > 0 and y > 0:
return x + y
return 0
st = ST(a)
ans = [0] * len(queries)
for qi, q in enumerate(queries):
ql, qr = q[0], q[1]
i = belong[ql]
if ql > 0 and s[ql] == '0' and s[ql-1] == '0':
i += 1 # i 在残缺区间中
j = belong[qr] - 1
if qr + 1 < n and s[qr] == '0' and s[qr+1] == '1':
j += 1 # j 刚好在完整区间的右端点,无需减一
qr += 1
mx = 0
if i <= j:
mx = max(
st.query(i, j),
merge(a[i-1][1] - ql, a[i][1] - a[i][0]),
merge(qr - a[j+1][0], a[j][1] - a[j][0])
)
elif i == j + 1:
mx = merge(a[i-1][1] - ql, qr - a[j+1][0])
ans[qi] = total1 + mx
return ans
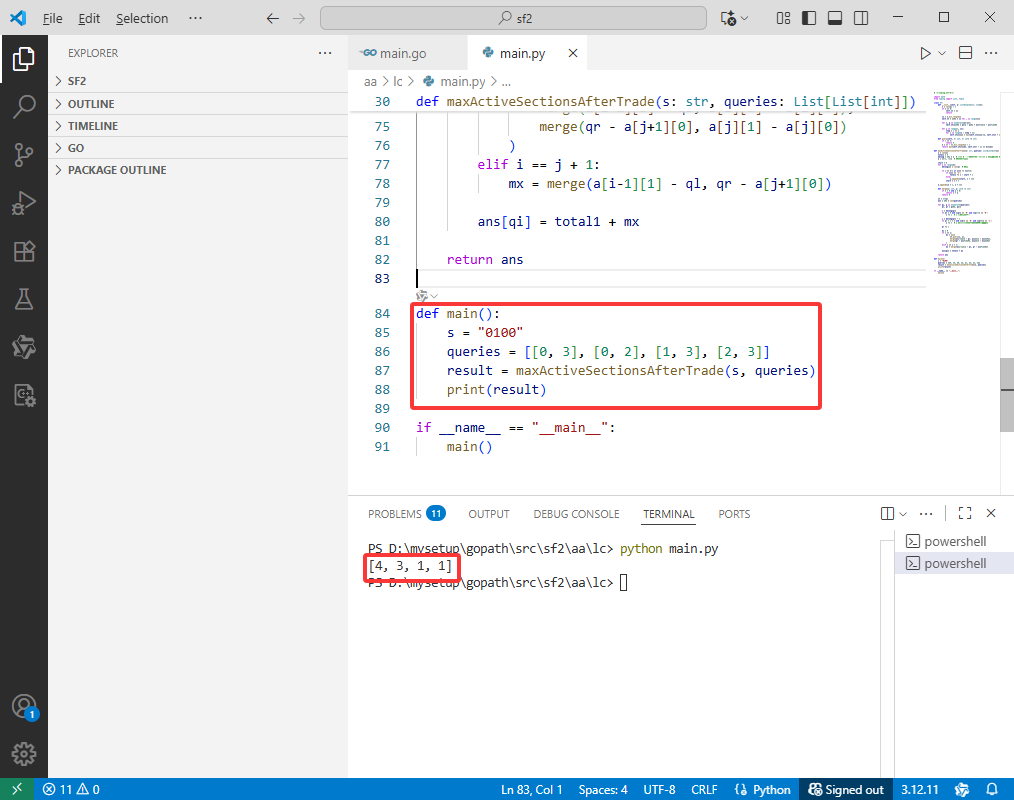
def main():
s = "0100"
queries = [[0, 3], [0, 2], [1, 3], [2, 3]]
result = maxActiveSectionsAfterTrade(s, queries)
print(result)
if __name__ == "__main__":
main()

- 点赞
- 收藏
- 关注作者
评论(0)