dify 1.9.0:知识编排与工作流引擎的全新升级


在 Dify 1.9.0 版本中,官方带来了两个重量级新能力:知识管道(Knowledge Pipeline) 与 基于队列的图执行引擎(Queue-based Graph Engine)。这次更新不仅彻底重构了文档处理架构,还让复杂工作流的并行执行变得更加稳定、可控,为企业级 AI 应用的落地提供了坚实基础。本文将详细解读新特性、使用场景、升级指南以及未来规划。
🚀 介绍
在 Dify 1.9.0 中,我们引入了两个重要的新功能:知识管道(Knowledge Pipeline) 和 基于队列的图引擎(Queue-based Graph Engine)。
知识管道 提供了一个模块化、可扩展的知识摄取与处理流程,而 基于队列的图引擎 则让工作流执行更加稳健和可控。
我们相信,这两项功能将帮助你更顺畅地构建和调试 AI 应用,并期待你们的使用体验,以便我们持续改进。
📚 知识管道(Knowledge Pipeline)
✨ 简介
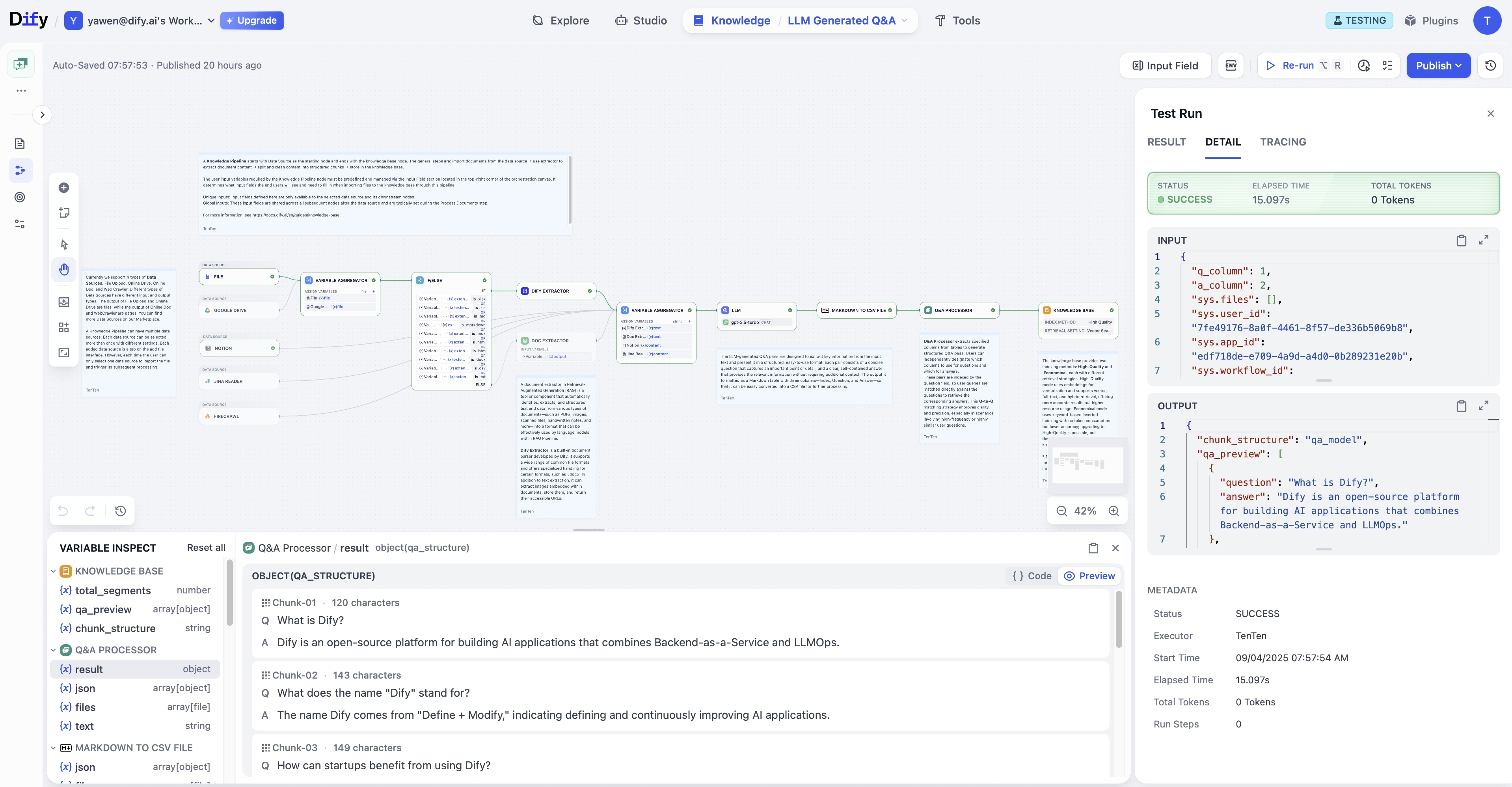
全新的知识管道编排界面,引入了一次基础架构升级,重新塑造了文档处理的设计和执行方式。它提供了更加模块化和灵活的工作流,让用户可以编排管道的每一个阶段。
配合市场中丰富而强大的插件,用户能够灵活集成不同的数据源和处理工具。
这种架构最终能帮助用户构建高度定制、特定领域的 RAG 解决方案,以满足企业在可扩展性、适应性和精确性方面不断增长的需求。
❓ 我们为什么需要它?
在此之前,Dify 的 RAG 用户在实际落地过程中依然会遇到一些长期存在的挑战——例如:
- 🔗 数据源集成受限
- 🖼️ 丢失关键信息(如表格、图片)
- ✂️ 分块(chunk)效果不理想
这些问题都会导致回答质量下降,并影响模型的整体表现。
为此,我们将 Dify 中的 RAG 重新构想为开放且模块化的架构,使开发者、集成商和领域专家能够从 数据导入 到 分块存储与检索,构建符合自身需求的文档处理管道。
🛠️ 核心能力
🧩 知识管道架构
知识管道是一个专注于文档摄取的可视化、基于节点的编排系统。
它提供了一种可定制化的自动化路径,用于复杂文档处理,使得细粒度的内容转换成为可能,并将原始内容与结构化、可检索的知识连接起来。
开发者可以像拼拼图一样一步一步构建工作流,让文档处理更易于观察和调整。
📑 模板 & Pipeline DSL
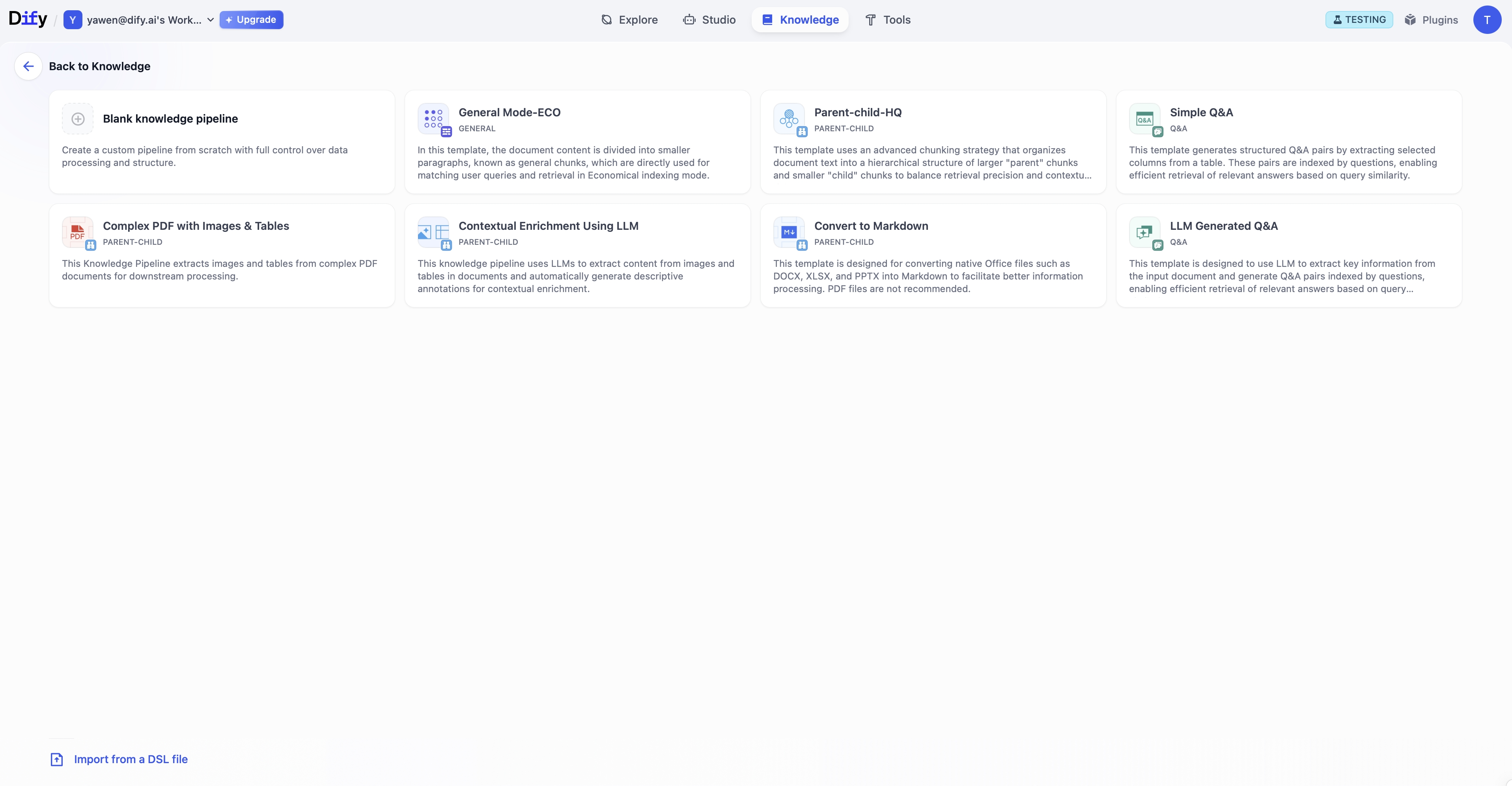
- ⚡ 可通过官方模板快速上手
- 🔄 通过导入/导出的 DSL 文件,自定义并共享管道,实现更高的可复用性与协作性
🔌 可定制化数据源与工具
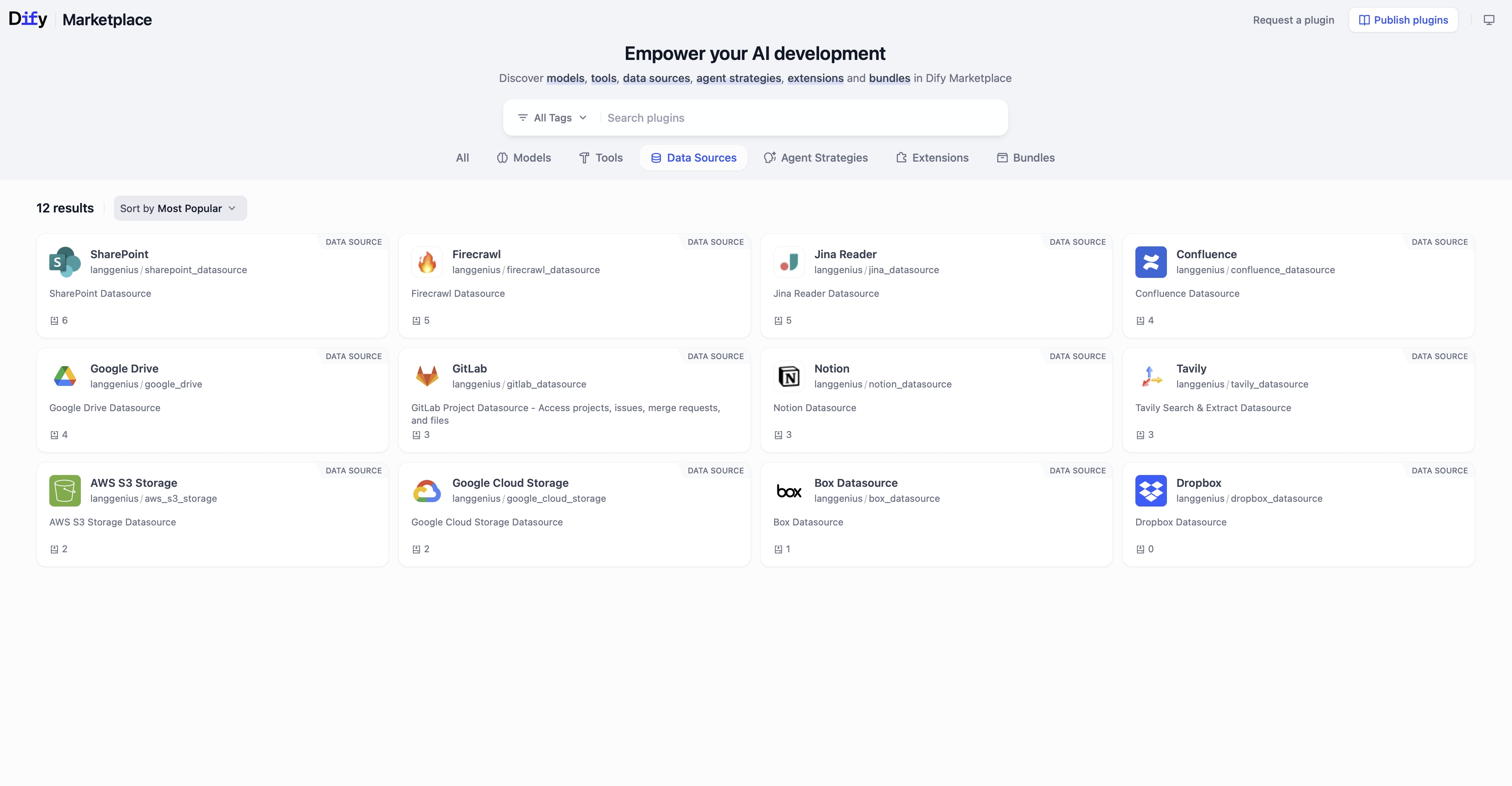
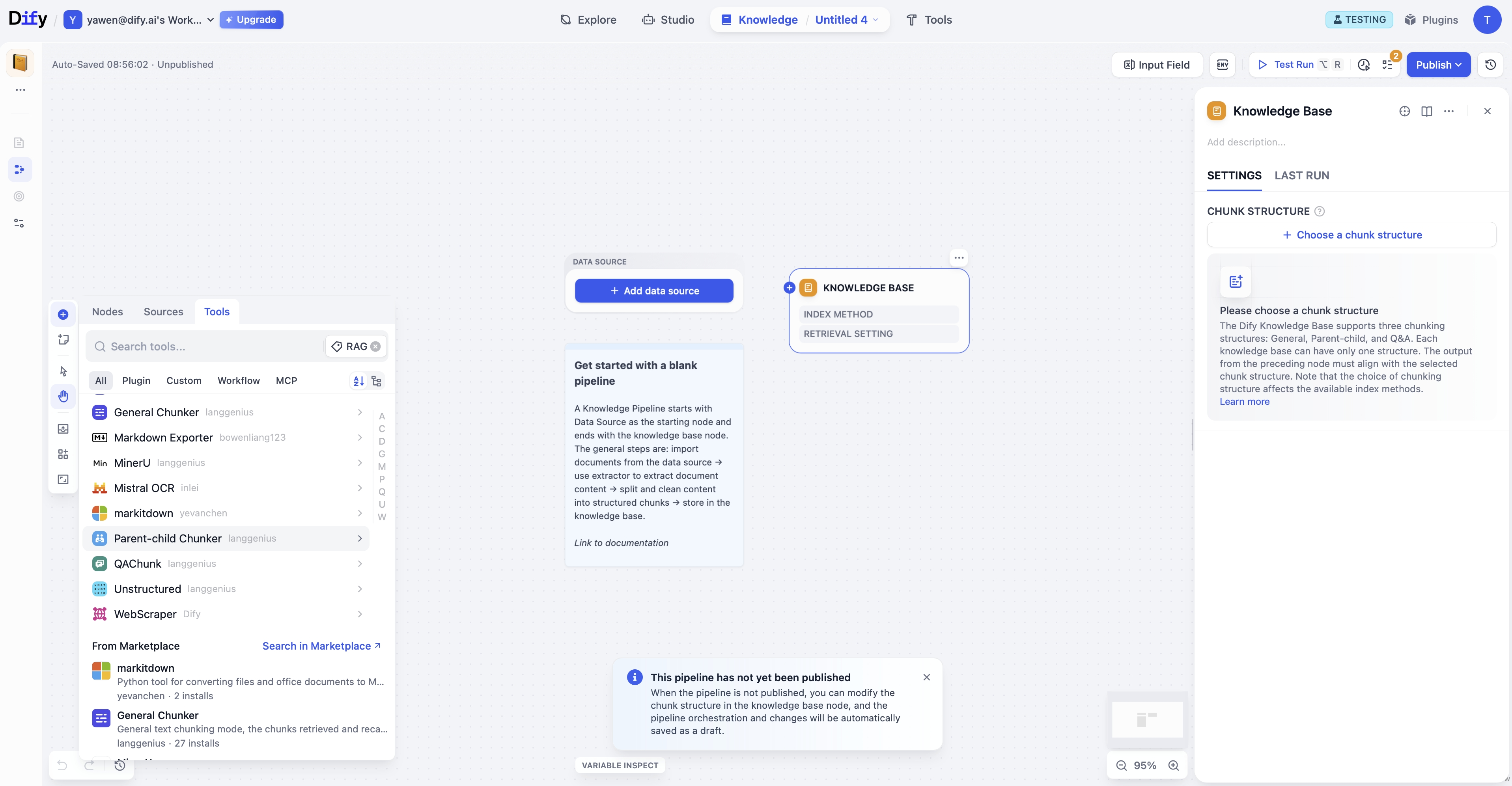
每个知识库都可以支持多个数据源。
你可以通过基于插件的数据摄取框架,无缝集成本地文件、在线文档、云盘以及网络爬虫等多种来源。
开发者也可以通过新的数据源插件扩展生态系统,而市场中的处理器插件则能应对更专业的场景,例如:公式识别、电子表格处理、图片解析等——确保数据摄取的准确性和结构化表示。
🧾 全新的分块(Chunking)策略
除了**通用模式(General)和父子模式(Parent-Child)**之外,我们新增了 Q&A 处理器插件,可支持问答结构的分块方式。
这拓展了更多应用场景,并在检索精度与上下文完整性之间取得平衡。
🖼️ 图片提取与检索
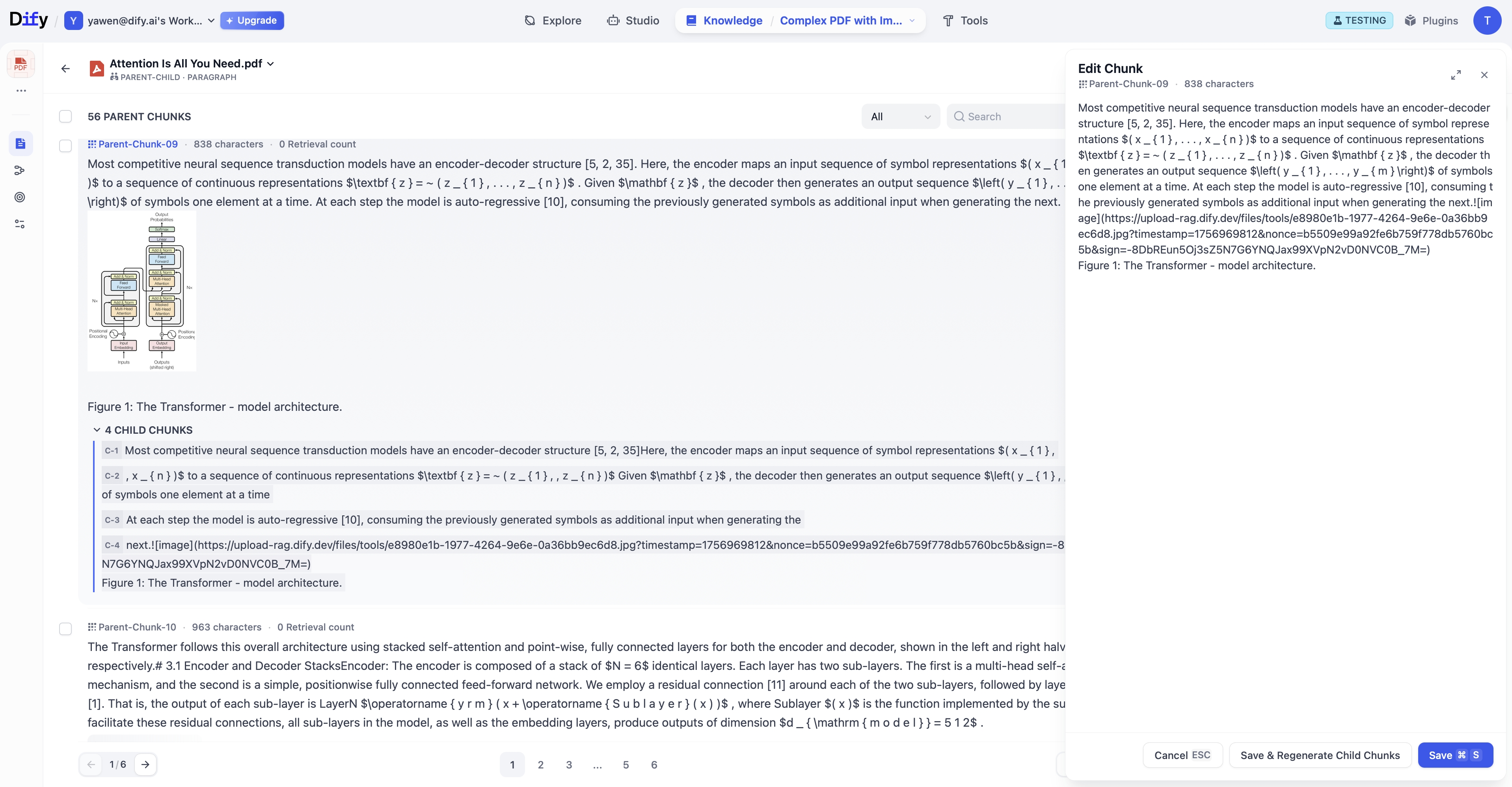
可以从多种格式的文档中提取图片,将其以 URL 形式 存储到知识库中,并支持文本与图像混合输出,从而提升 LLM(大语言模型)的回答质量。
🧪 测试运行与调试支持
在发布一个管道之前,你可以:
▶️ 独立执行单个步骤或节点
🔍 详细查看中间变量
👀 在变量检查器中以 Markdown 格式预览字符串变量
这让你可以在管道的每个阶段进行安全的迭代与调试。
🔄 一键迁移旧版知识库
可通过一次操作,无缝将现有的知识库转换为知识管道架构,确保平滑过渡,并兼容历史数据。
🌟 为什么重要
知识管道让知识管理过程变得更加透明,可调试,并易于扩展。
它并不是终点,而是未来功能增强的基础,例如:
- 多模态检索
- 人机协作(Human-in-the-loop)
- 企业级数据治理
我们期待看到你如何应用它,并欢迎你反馈体验。
⚙️ 基于队列的图引擎(Queue-based Graph Engine)
❓ 我们为什么需要它?
过去,在设计具有并行分支的工作流时,经常会遇到以下问题:
- 🌀 难以管理分支状态并重现错误
- ❌ 调试信息不足
- 🧱 执行逻辑过于僵化,缺乏灵活性
这些问题降低了复杂工作流的可用性。 为了解决这些痛点,我们围绕队列调度重新设计了执行引擎,从而提升了并行任务的管理能力。
🛠️ 核心能力
📋 队列调度模型(Queue Scheduling Model)
所有任务会进入一个统一的队列,由调度器管理任务的依赖关系与执行顺序。
这种方式减少了并行执行的错误,并让工作流拓扑更加直观。
🎯 灵活的执行起点
执行可以从任何节点开始,支持部分运行、恢复执行或子图调用。
🌊 流式处理组件(Stream Processing Component)
新增 ResponseCoordinator,用于处理来自多个节点的流式输出,例如:
- LLM 按 token 生成的实时结果
- 长时间运行任务的分阶段结果
🕹️ 命令机制(Command Mechanism)
通过 CommandProcessor,工作流可以在执行过程中暂停、恢复或终止,支持外部控制。
🧩 GraphEngineLayer
新增的插件层允许在无需修改核心代码的情况下扩展引擎功能:
- 可监控执行状态
- 发送命令
- 支持自定义监控
快速开始(Quickstart)
先决条件
- Dify 版本:1.9.0 或更高
如何启用
- 默认启用,无需额外配置
- 调试模式:设置
DEBUG=true以启用DebugLoggingLayer
执行限制:
WORKFLOW_MAX_EXECUTION_STEPS=500
WORKFLOW_MAX_EXECUTION_TIME=1200
WORKFLOW_CALL_MAX_DEPTH=10
工作线程配置(可选):
WORKFLOW_MIN_WORKERS=1
WORKFLOW_MAX_WORKERS=10
WORKFLOW_SCALE_UP_THRESHOLD=3
WORKFLOW_SCALE_DOWN_IDLE_TIME=30
适用于所有工作流。
更可控的并行分支
执行流程:
开始 ─→ 统一任务队列 ─→ WorkerPool 调度
├─→ 分支1执行
└─→ 分支2执行
↓
聚合器
↓
结束
改进点:
- 所有任务进入单一队列,由 Dispatcher 管理。
- WorkerPool 会根据负载自动扩缩容。
- ResponseCoordinator 管理流式输出,保证顺序正确。
示例:命令机制
from core.workflow.graph_engine.manager import GraphEngineManager
# 发送停止命令
GraphEngineManager.send_stop_command(
task_id="workflow_task_123",
reason="紧急停止:资源限制已超出"
)
提示:暂停/恢复功能将在未来版本中支持。
示例:GraphEngineLayer
FAQ
此版本是否专注于性能?
不是。本次重点在于稳定性、清晰性以及并行分支的正确性,性能提升只是次要收益。
可订阅的事件类型有哪些?
图级事件
- GraphRunStartedEvent
- GraphRunSucceededEvent
- GraphRunFailedEvent
- GraphRunAbortedEvent
节点级事件
- NodeRunStartedEvent
- NodeRunSucceededEvent
- NodeRunFailedEvent
- NodeRunRetryEvent
容器节点事件
- IterationRunStartedEvent
- IterationRunNextEvent
- IterationRunSucceededEvent
- LoopRunStartedEvent
- LoopRunNextEvent
- LoopRunSucceededEvent
流式输出事件
- NodeRunStreamChunkEvent
如何调试工作流执行?
- 启用
DEBUG=true查看详细日志 - 使用
DebugLoggingLayer记录事件 - 通过
GraphEngineLayer添加自定义监控
未来规划(Future Plans)
本次更新只是起点,后续改进包括:
- 调试工具:可视化界面实时查看执行状态与变量
- 智能调度:利用历史数据优化调度策略
- 更完整的命令支持:增加暂停、恢复、断点调试
- 人机协作(Human in the Loop):在执行过程中支持人工干预
- 子图功能:增强模块化与复用性
- 多模态嵌入:支持除文本以外更丰富的内容类型
我们期待收到你的反馈与使用体验,以进一步优化该引擎的实用性。
升级指南(Upgrade Guide)
重要提示
升级后,你必须运行以下迁移命令,以转换现有的数据源凭证。
此步骤是必需的,以确保与新版本兼容:
uv run flask transform-datasource-credentials
Docker Compose 部署
- 备份你自定义的 docker-compose YAML 文件(可选)
cd docker
cp docker-compose.yaml docker-compose.yaml.$(date +%s).bak
- 获取主分支的最新代码
git checkout 1.9.0
git pull origin 1.9.0
- 停止服务(需在 docker 目录执行)
docker compose down
- 备份数据
tar -cvf volumes-$(date +%s).tgz volumes
- 升级服务
docker compose up -d
- 容器启动后迁移数据
docker exec -it docker-api-1 uv run flask transform-datasource-credentials
源码部署(Source Code Deployments)
-
停止 API Server、Worker 和 Web 前端服务。
-
获取发布分支的最新代码:
git checkout 1.9.0
- 更新 Python 依赖:
cd api
uv sync
- 运行迁移脚本:
uv run flask db upgrade
uv run flask transform-datasource-credentials
重要提示(针对 Beta 版本用户)
如果你当前使用的是 v2.0.0-beta.1 或 v2.0.0-beta.2,必须运行以下迁移脚本进行升级。
⚠️ 警告:这是一个破坏性操作,将造成数据丢失。
该迁移脚本会永久删除以下数据:
- 所有现有的知识管道(Knowledge Pipelines)
- 所有相关的数据集凭证(Dataset Credentials)
请务必在执行前备份所有必要信息。
迁移命令:
uv run flask db downgrade cf7c38a32b2d
uv run flask db upgrade
uv run flask transform-datasource-credentials
最后
重新启动 API Server、Worker 和 Web 前端服务。
📦 更新内容(What’s Changed)
- 修复:改进 MyScale 向量搜索操作的错误日志记录
- 修复:遵循 JSONSchema 规范:使用
number代替float - 杂务:将 pnpm 版本更新至 10.15.1
- 杂务:符合 RFC 6750,并改进 Bearer Token 拆分逻辑
- 修复:数据库内部服务器错误
- 杂务:增强 basedpyright-check 脚本以支持路径参数
- 重构/优化:提升类型安全性并解决类型检查问题
- 修复:统一下拉菜单中的图标样式
- 杂务:改进生成会话名称的追踪信息
- 杂务:移除
Graph类中的无用代码 - 新增:工作流转换器的基于测试容器的测试
- 修复:在暗色模式下统一配置变量类型选择器的文本颜色
- 修复:旧的自定义模型未显示凭证名称
- 修复:
TypeSelector组件样式 - 修复:PNG/JPEG 导出问题
- 小修:修正
get_app_model的delete()方法模式 - 修复:推荐应用从数据库读取逻辑
- 杂务:升级 weaviate-client 至最新版 v3
- 修复:当插件调用回调时,EndUser 没有关联到 Session
- 功能(工作流):支持将节点粘贴到嵌套块中
- 功能:为 i18next 增加 TypeScript 类型安全及自动维护
- 修复:更新账户资料
- 修复:重置密码功能
- 杂务:移除无用的 mypy 脚本
- 重构/优化:改进类型检查配置
- 修复:确保使用 Weave 记录时执行步骤顺序正确
- 示例:正则表达式执行
- 修复:Firecrawl 请求负载中移除无效的键
- 修复:分块详情弹窗的回答不换行
- 改动:转为
RefObject使用 - 杂务:清理部分
# type: ignore注释 - 重构:改进插件版本校验以支持完整语义化版本
- 示例:类型按钮示例
- 示例:只读示例
- 修复:子分块 API 因 UUID 类型比较导致 404
- 修复:循环节点在满足条件时未退出
- 示例:懒加载示例
- 示例:移除
useEffect使用示例 - 新增:为 Python SDK 的
ChatClient类添加类型注释 - 功能:为 LLMNode 增加推理格式处理以支持标签处理
- 功能:测试容器添加文档索引
- 新增:更多数据类
- 移除:不带类型的
list、dict、Sequence、None、Any - 功能(Web):添加渐进式 Web 应用(PWA)支持
- 修复:在安装表单中将文本颜色标准化为
text-secondary - 杂务:翻译 i18n 文件并更新类型定义
- 修复:解决
configs模块中的类型错误 - 功能:测试容器支持批量清理文档
- 示例:
no-unstable-context-value示例 - 修复:将失败的索引标记为已创建
- 杂务:在版本控制中忽略 PWA 生成文件
- 修复:移除工作流文件预览文档
- 修复:迭代节点使用正确的变量段类型
- 修复:在
useBatchUpdateDocMetadata中修正queryKey并添加测试用例 - 修复:确保 UI 中 DSL 导出的行为一致
- 重构/优化:改进
models模块的类型注释 - 示例:保持添加与移除一致
- 重构:升级 React 19 的
ref作为 props - 示例:增加更多断言
- 修复:
curr_message_tokens未关联值的问题 - 杂务:翻译 i18n 文件并更新类型定义
- 修复:参数提取器在聊天模型中为提示模式使用正确的 Prompt
- 新增:更多类型定义
- 杂务:移除异常的账户登录
- 功能:添加基于测试容器的清理数据集任务测试
- 功能:添加 MCP 服务器请求头支持
- 小修:修复
PrecessRule字符拼写错误 - 杂务:翻译 i18n 文件并更新类型定义
- 修复:当没有追踪提供者时,确保性能追踪按钮可见
- 功能:重构邮件注册逻辑
- 功能:测试容器批量创建分段索引
- 修复:错误的 URL 参数解析导致
user_id获取失败 - 新功能:在 DSL 导出时可选择是否加密数据集 ID
- 回退:“feat: email register refactor” 功能
- 重构:更新
pyrightconfig.json,使用 ignore 字段以优化类型检查配置 - 修复/禁用:禁止使用常量二元表达式
- 修复:验证码输入框使用正确的
maxLength属性 - 修复:LLM 节点设置面板中 X 轴滚动条问题
- 修复:
tenant_id在插件反向调用封装中检索终端用户时不够明确 - 小修:修复部分翻译不匹配问题
- 支持:输出节点中的锚点滚动
- 示例:添加 UUID 示例
- 新功能:为 Notion 文档清理任务添加基于测试容器的测试
- 修复(容器测试):批量创建分段位置排序问题
- 新功能:凭证策略(Credential Policy)
- 修复:在负载均衡中不允许使用凭证
- 修复(MCP):
current_user在 MCP 请求中未被正确设置 - 修复:Flask 响应格式问题:200 ->
{}, 200 - 新功能:添加自定义 JSON Schema 验证
- 修复:在
service_api中创建空知识库接口时的错误问题 - 新功能:在补充节点信息时改变历史记录
- 修复:设置头像后未更新
- 回退:“example of remove useEffect” 示例
- 添加:为所有封装添加类型定义
- 修复:在 Explore 模式下打开的判断逻辑
- 修复:在自动修复工作流中使用
--fix而不是--fix-only - 添加:库测试
- 重构:更新
pyrightconfig以扫描所有 API 文件 - 修复(MCP):正确处理同时包含数字和字符串的数组
- 杂项:感谢 bump-pydantic
- 修复:basedpyright 类型错误
- 修复:优化停止思考计时器的条件
- 添加:字符串枚举规则
- 修复:为账户创建添加密码验证
- 新功能:为创建分段到索引任务添加测试容器
- 修复:
inner_api中get_user_tenant逻辑 - 测试:改进测试
- 重构:将控制台基础 API 模块部分迁移到 Flask-RESTX
- 更新:批量更新 SQL
- 修复:移除工作流组件字段的粘性定位
- 修复:数据集页面 500 错误
- 新功能:企业 CD
- 杂项:支持 Zendesk 小组件
- 安全(API):修复模型配置与聊天消息 API 中的权限提升漏洞
- 新功能:为处理数据集向量索引任务添加测试容器测试
- 修复:应用名称溢出问题
- 修复:日志时间显示错误
- 测试:移除打印代码
- 修复:
get_conversational_variable中has_more分页逻辑 - 新功能:为删除索引段任务添加测试容器测试
- 修复:删除上传文件的 GET 接口
- 添加:自动修复 pnpm
- 杂项(依赖):在 /web 中将 mermaid 从 11.4.1 升级到 11.10.0
- 移除
WorkflowByIdApi.patch中冗余的parse_args调用 - 测试:在 mock 中使用
autospec=True - 修复:单步系统文件错误
- 修复(日期选择器):处理字符串日期以避免崩溃
- 修复/禁用:禁止使用不安全的可选链操作
- 修复:在创建应用时支持传递默认应用模式
- 强制更新搜索方法为
keyword_search - 新功能:邮箱注册重构
- 修复:前端登录安全问题
- 重构:集中管理默认终端用户 Session ID 常量
- 杂项:翻译 i18n 文件并更新类型定义
- 修复:过滤掉临时边缘数据以同步工作流草稿
- 重构:更新控制台端点的 API 路由和文档
- 修复:解决分段(segment)删除的竞争条件
- 功能:为
VarType添加整数类型 - 修复:浏览器页面缩小时关闭按钮无法点击的问题
- 修复:当
startNode有defaultValue时无法修改值的问题 - 杂务:对部分字符串枚举使用
StrEnum和auto() - 功能(压力测试):使用 Locust 添加综合压力测试套件
- 功能:为索引任务添加“禁用分段”的测试容器
- 修复:改进 “GotoAnything” 命令面板的多项用户体验
- [测试]:加快 Hypothesis 策略以避免
too_slow错误 - 功能:为 “GotoAnything” 命令菜单添加循环滚动
- 修复:允许变量检查器中出现空值
- 功能:为 “索引任务的禁用分段” 添加基于测试容器的测试
- 功能:增强 Makefile,添加代码质量命令及默认帮助
- 示例文件:示例(适用于所有)
- 杂务:翻译 i18n 文件并更新类型定义
- Bug 修复:Faker 随机生成的邮箱实际对应测试数据库中的现有账号,导致测试失败
- 改进:使用
typing.Literal完善类型提示并增加类型标注 - 杂务:升级 pnpm 至
v10.16.0 - 优化:
_merge_splits函数改为使用enumerate代替手动索引跟踪 - [杂务/重构]:使用
__all__指定导出成员 - 功能:用户消息支持生成提示词
- 重构:更新应用(app)和数据集(datasets)端点的 API 路由与文档
- 依赖更新:Dependabot 相关改动
- 依赖更新:将
/api中的transformers从4.53.3升级到4.56.1 - 依赖更新:将
/api中的clickzetta-connector-python从0.8.102升级到0.8.104 - 依赖更新(开发):将
/web中的sass从1.89.2升级到1.92.1 - 依赖更新:将
/web中的scheduler从0.23.2升级到0.26.0 - 依赖更新(开发):将
/web中的@next/bundle-analyzer从15.5.0升级到15.5.3 - 依赖更新:将
/web中的@lexical/text从0.30.0升级到0.35.0 - 杂务:添加 ast-grep 规则以将
Optional[T]转换为T | None - 修复:解决
devalue原型链污染漏洞 - 发布:
e-1.8.1版本 - 修复(MCP):阻止被掩码的请求头覆盖真实值
- 修复(Web):
custom-tool的output_schema.properties缺失type属性 - 更正:修复拼写错误
- 杂务:翻译 i18n 文件并更新类型定义
- 修复(测试):解决
disable_segments_from_index_task测试中的顺序依赖问题 - Bug 修复:修改循环变量时循环终止条件错误的问题
- 功能:为“文档索引任务”添加测试容器
- 聊天 UI:移除暗色模式下聊天气泡的透明度
- 代码检查:ruff 检查预览
- 增强:LLM 模型配置校验增加激活状态检查
- 重构:移除文档文件中的 Claude 特有引用
- 修复:Lindorm VDB 优化
- 修复:纠正 PR #25628 引入的错误 API 端点路由
总结
Dify 1.9.0 的两个核心升级 Knowledge Pipeline 与 Queue-based Graph Engine,分别从知识处理和工作流执行两大维度提升了系统的可扩展性、可调试性与稳定性。对于需要构建精确、高效、可维护的 AI 应用的团队来说,这无疑是一次重要的架构进化。

- 点赞
- 收藏
- 关注作者
评论(0)