树和二叉树宽度优先遍历bfs(链式前向星和vector数组两个方式的代码模拟)

【摘要】 1.宽度优先遍历宽度优先遍历实际上对于我们的这个二叉树而言,实际上就是一层一层的进行这个遍历的过程,也就是按照这个第一层,第二层,第三层的顺序进行基本思想就是下面的这个样子的过程:初始化⼀个空的队列;根节点进入队列,同时标记该节点已经⼊队;当队列不为空时,拿出队列里面的第一个元素,并且进行访问,然后将队列第一个元素的所有孩⼦⼊队,同时打上标记;重复3 过程,直到队列里面没有任何的元素;因此...
1.宽度优先遍历
宽度优先遍历实际上对于我们的这个二叉树而言,实际上就是一层一层的进行这个遍历的过程,也就是按照这个第一层,第二层,第三层的顺序进行
基本思想就是下面的这个样子的过程:
- 初始化⼀个空的队列;
- 根节点进入队列,同时标记该节点已经⼊队;
- 当队列不为空时,拿出队列里面的第一个元素,并且进行访问,然后将队列第一个元素的所有孩⼦⼊队,同时打上标记;
- 重复3 过程,直到队列里面没有任何的元素;
因此通过上面的这个过程大家应该是可以发现,这个核心就是使用的我们的队列实现树的宽度优先遍历的这个过程;
接下来我们还是以此来看一下这个vector数组和链式前向星两个方式对于我们的这个树进行宽度优先遍历的过程把,使用我们上面介绍的这个过程以及这个
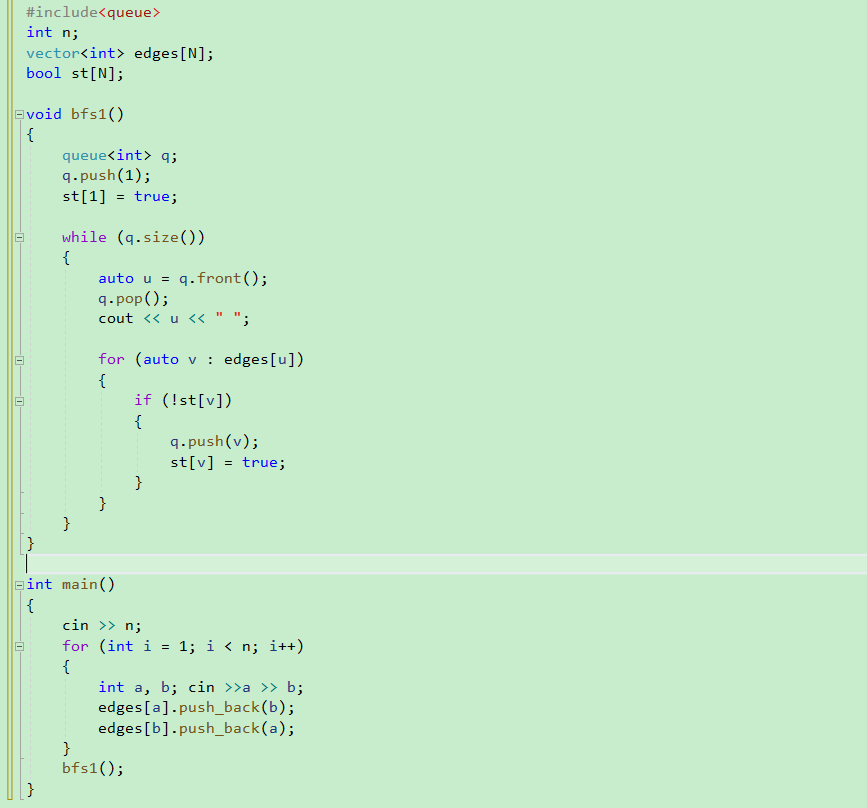
2.vector数组的宽度优先遍历
下面的这个就是我们的vector数组里面的宽度优先遍历:
- 独立封装的这个bfs就是这个代码的核心逻辑啦,定义队列,刚开始入队1,设置为true标志;
- 只要我们的这个队列里面还是存在元素的,这个时候取出来这个队列里面的第一个元素,出队列;
- 根据上面拿到的这个队列里面的第一个元素u进行遍历他的链表里面的元素进行遍历,使用的是auto语法,对于这个子节点,全部加入到这个队列里面去,并且标记位true;
3.链式前向星的宽度遍历
接下来介绍一下这个链式前向星的遍历的方法,再来回顾一下,这个方法实际上就是定义这个h数组,我们的e数组和ne数组,以及这个id;
- 首先是我们的这个里面的add函数,就是把这个b添加到这个a链表里面去,这个使用的是头插的操作,也就是下面的这个add函数里面的四行代码;
- bfs函数里面还是使用的是队列的这个方式,取出来我们的这个队列里面的第一个元素,定义为u,然后这个就直接出去啦,我们记录下来是因为我们后面会使用到;
- h[u]就是找到我们的链表里面的虚拟头结点,进行下面的这个遍历的过程,for循环里面的这个ne[i[就是利用这个链表里面的next指针不断的找到我们的链表里面的下一个元素,找到的这个元素实际上就是u的孩子节点,直接全部push到我们的队列里面去即可,并且进行这个st数组里面的对应位置的标记;

666

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)