2025-07-21:不重叠区间的最大得分。用go语言,给定一个二维整数数组 intervals,其中每个元素 interval

【摘要】 2025-07-21:不重叠区间的最大得分。用go语言,给定一个二维整数数组 intervals,其中每个元素 intervals[i] = [li, ri, weighti] 表示一个区间,起点是 li,终点是 ri,权重是 weighti。你最多可以选出 4 个互不重叠的区间,使得这些被选区间的权重总和最大。这里的“互不重叠”指的是两个区间之间没有任何交集,且如果两个区间在边界点(左端点...
2025-07-21:不重叠区间的最大得分。用go语言,给定一个二维整数数组 intervals,其中每个元素 intervals[i] = [li, ri, weighti] 表示一个区间,起点是 li,终点是 ri,权重是 weighti。你最多可以选出 4 个互不重叠的区间,使得这些被选区间的权重总和最大。
这里的“互不重叠”指的是两个区间之间没有任何交集,且如果两个区间在边界点(左端点或右端点)重合,也视为重叠,不能同时选择。
最终需要返回一个数组,包含所选区间的下标,最多 4 个,并且在所有得分最高的组合中,选出字典序最小的那一个。
1 <= intervals.length <= 5 * 10000。
intervals[i].length == 3。
intervals[i] = [li, ri, weighti]。
1 <= li <= ri <= 1000000000。
1 <= weighti <= 1000000000。
输入: intervals = [[5,8,1],[6,7,7],[4,7,3],[9,10,6],[7,8,2],[11,14,3],[3,5,5]]。
输出: [1,3,5,6]。
解释:
可以选择下标为 1、3、5 和 6 的区间,其权重分别为 7、6、3 和 5。
题目来自力扣3414。
问题描述
给定一组区间,每个区间有左端点、右端点和权重。要求选择最多4个互不重叠的区间,使得这些区间的权重总和最大。如果有多个组合的权重总和相同,则选择字典序最小的那个组合。返回所选区间的下标。
解决步骤
-
数据预处理:
- 将每个区间及其原始下标存储为一个元组(
tuple),包含左端点(l)、右端点(r)、权重(weight)和原始下标(i)。 - 根据右端点对所有区间进行排序。这样做的目的是为了方便后续的动态规划处理,因为按右端点排序后,可以更容易地找到不与当前区间重叠的前驱区间。
- 将每个区间及其原始下标存储为一个元组(
-
动态规划初始化:
- 定义一个动态规划数组
f,其中f[i][j]表示从前i个区间中选择最多j个不重叠区间时的最大权重和及其对应的区间下标组合。 f是一个二维数组,大小为(n+1) x 5,其中n是区间的数量。5是因为最多可以选择 4 个区间(包括 0 个区间的情况)。
- 定义一个动态规划数组
-
动态规划填充:
- 遍历排序后的区间,对于每个区间
t,尝试将其加入到已有的选择中。 - 对于每个可能的区间数量
j(从 1 到 4):- 找到所有右端点小于当前区间
t的左端点的区间。这些区间可以与t不重叠。这一步通过二分查找实现,找到第一个右端点大于等于t.l的区间,其左边的区间就是可能的前驱。 - 计算两种情况的权重和:
- 不选择当前区间
t:直接继承f[i][j]的值。 - 选择当前区间
t:权重和为f[k][j-1].sum + t.weight,其中k是前驱区间的数量。
- 不选择当前区间
- 比较这两种情况,选择权重和较大的那个。如果权重和相同,选择字典序较小的下标组合。
- 更新
f[i+1][j]为当前最优解。
- 找到所有右端点小于当前区间
- 遍历排序后的区间,对于每个区间
-
结果提取:
- 最终的最大权重和及其对应的区间下标组合存储在
f[n][4]中。 - 返回
f[n][4].id,即所选区间的下标。
- 最终的最大权重和及其对应的区间下标组合存储在
时间复杂度
- 排序区间:
O(n log n)。 - 动态规划填充:
- 外层循环遍历
n个区间。 - 内层循环遍历 4 个可能的区间数量。
- 对于每个区间和数量,需要进行一次二分查找(
O(log n))。 - 因此,动态规划部分的时间复杂度为
O(n * 4 * log n) = O(n log n)。
- 外层循环遍历
- 总时间复杂度:
O(n log n)。
空间复杂度
- 存储排序后的区间:
O(n)。 - 动态规划数组
f:O(n * 5) = O(n)。 - 存储每个状态的区间下标组合:最坏情况下可能需要
O(n * 4)的空间(每个状态存储最多 4 个下标)。 - 总空间复杂度:
O(n)。
总结
- 时间复杂度:
O(n log n)。 - 空间复杂度:
O(n)。
Go完整代码如下:
package main
import (
"fmt"
"slices"
"sort"
)
func maximumWeight(intervals [][]int) []int {
type tuple struct{ l, r, weight, i int }
a := make([]tuple, len(intervals))
for i, interval := range intervals {
a[i] = tuple{interval[0], interval[1], interval[2], i}
}
slices.SortFunc(a, func(a, b tuple) int { return a.r - b.r })
n := len(intervals)
type pair struct {
sum int
id []int
}
f := make([][5]pair, n+1)
for i, t := range a {
k := sort.Search(i, func(k int) bool { return a[k].r >= t.l })
for j := 1; j < 5; j++ {
s1 := f[i][j].sum
// 为什么是 f[k] 不是 f[k+1]:上面算的是 >= t.l,-1 后得到 < t.l,但由于还要 +1,抵消了
s2 := f[k][j-1].sum + t.weight
if s1 > s2 {
f[i+1][j] = f[i][j]
continue
}
newId := slices.Clone(f[k][j-1].id)
newId = append(newId, t.i)
slices.Sort(newId)
if s1 == s2 && slices.Compare(f[i][j].id, newId) < 0 {
newId = f[i][j].id
}
f[i+1][j] = pair{s2, newId}
}
}
return f[n][4].id
}
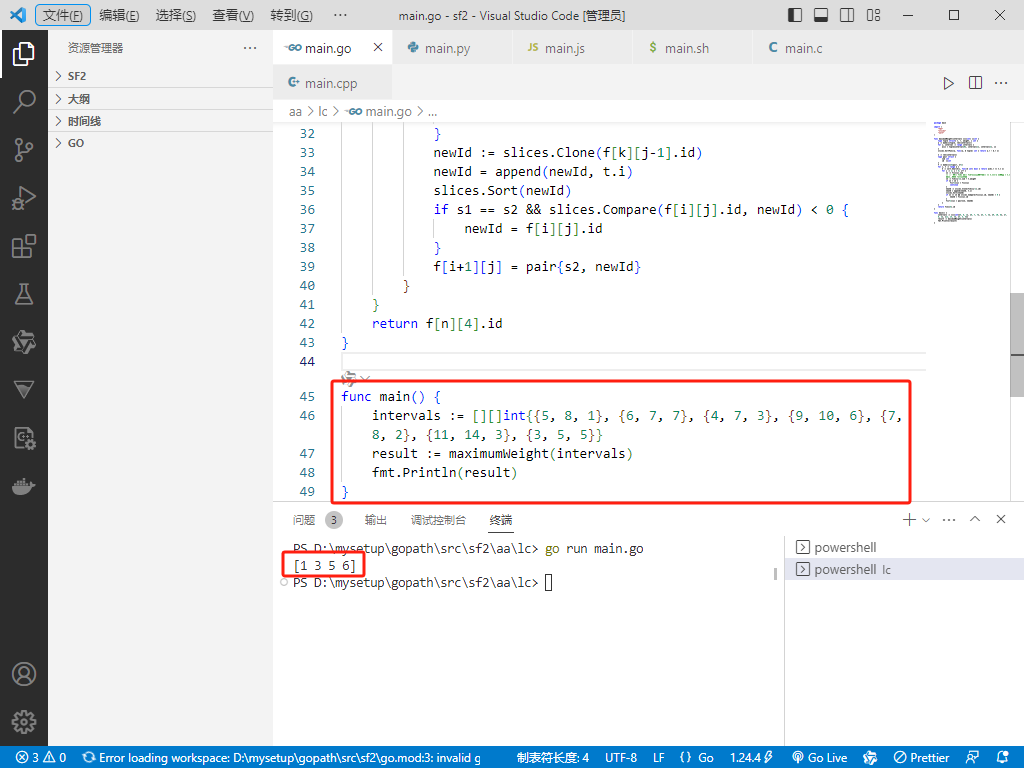
func main() {
intervals := [][]int{{5, 8, 1}, {6, 7, 7}, {4, 7, 3}, {9, 10, 6}, {7, 8, 2}, {11, 14, 3}, {3, 5, 5}}
result := maximumWeight(intervals)
fmt.Println(result)
}
Python完整代码如下:
# -*-coding:utf-8-*-
from bisect import bisect_left
from copy import deepcopy
def maximumWeight(intervals):
# 定义元组结构 l, r, weight, 原始下标 i
a = [(l, r, w, i) for i, (l, r, w) in enumerate(intervals)]
# 按右端点排序
a.sort(key=lambda x: x[1])
n = len(intervals)
# f[i][j] 存储选前 i 个区间,选 j 个区间时的最大权重和及对应的id列表
# 初始化为 sum=0,id=[]
f = [[{'sum':0, 'id':[]} for _ in range(5)] for _ in range(n+1)]
# 右端点单独提取,方便二分查找
ends = [item[1] for item in a]
for i, (l, r, w, idx) in enumerate(a):
# 找到第一个右端点 >= l 的区间位置
k = bisect_left(ends, l)
for j in range(1,5):
s1 = f[i][j]['sum'] # 不选第 i 个区间
# 选第 i 个区间,更新权重和
# f[k][j-1] 是不与当前区间重叠的组合
s2 = f[k][j-1]['sum'] + w
if s1 > s2:
f[i+1][j] = f[i][j]
elif s1 < s2:
new_id = deepcopy(f[k][j-1]['id'])
new_id.append(idx)
new_id.sort()
f[i+1][j] = {'sum': s2, 'id': new_id}
else: # s1 == s2,比较字典序,选字典序更小的
new_id = deepcopy(f[k][j-1]['id'])
new_id.append(idx)
new_id.sort()
if f[i][j]['id'] and f[i][j]['id'] < new_id:
f[i+1][j] = f[i][j]
else:
f[i+1][j] = {'sum': s2, 'id': new_id}
# j=0 情况继承不变
f[i+1][0] = f[i][0]
return f[n][4]['id']
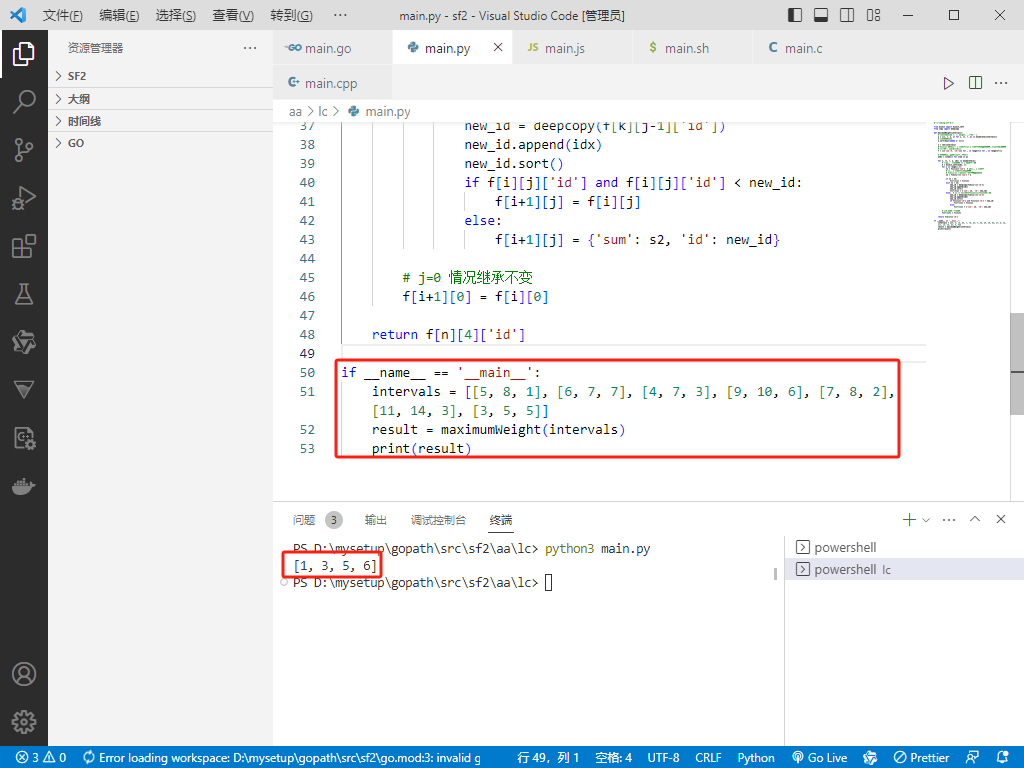
if __name__ == '__main__':
intervals = [[5, 8, 1], [6, 7, 7], [4, 7, 3], [9, 10, 6], [7, 8, 2], [11, 14, 3], [3, 5, 5]]
result = maximumWeight(intervals)
print(result)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)