2025-06-20:连接两棵树后最大目标节点数目Ⅰ。用go语言,你有两棵无向树,第一棵包含 n 个节点,节点编号范围是 [0,

2025-06-20:连接两棵树后最大目标节点数目Ⅰ。用go语言,你有两棵无向树,第一棵包含 n 个节点,节点编号范围是 [0, n - 1],第二棵包含 m 个节点,编号范围是 [0, m - 1]。
给定两个二维数组 edges1 和 edges2,分别表示两棵树的边。edges1 长度为 n - 1,其中 edges1[i] = [a_i, b_i] 表示第一棵树中节点 a_i 和节点 b_i 之间存在一条边;edges2 长度为 m - 1,其中 edges2[i] = [u_i, v_i] 表示第二棵树中节点 u_i 和节点 v_i 之间存在一条边。同时给定一个整数 k。
定义:若两节点 u 和 v 之间的路径上边数不超过 k,则称 u 是 v 的目标节点。注意每个节点都包含它自身(因为路径长度为 0 ≤ k)。
任务是返回一个长度为 n 的数组 answer,其中 answer[i] 表示:在第一棵树中固定节点 i,将其与第二棵树中的某个节点连接一条边后,计算第一棵树中节点 i 的目标节点数量的最大可能值。每次连接只添加一条边,且各次计算相互独立,也就是说每次计算完成后需恢复原状(移除刚才添加的边)。
总结来说,就是对第一棵树的每个节点 i,考虑怎么选择一个第二棵树上的节点与之连接(新加一条边),使得连接后第一棵树中以 i 为中心路径长度不超过 k 的目标节点数量最大,求出这个最大值组成答案数组。
2 <= n, m <= 1000。
edges1.length == n - 1。
edges2.length == m - 1。
edges1[i].length == edges2[i].length == 2。
edges1[i] = [ai, bi]。
0 <= ai, bi < n。
edges2[i] = [ui, vi]。
0 <= ui, vi < m。
输入保证 edges1 和 edges2 都表示合法的树。
0 <= k <= 1000。
输入:edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]], k = 2。
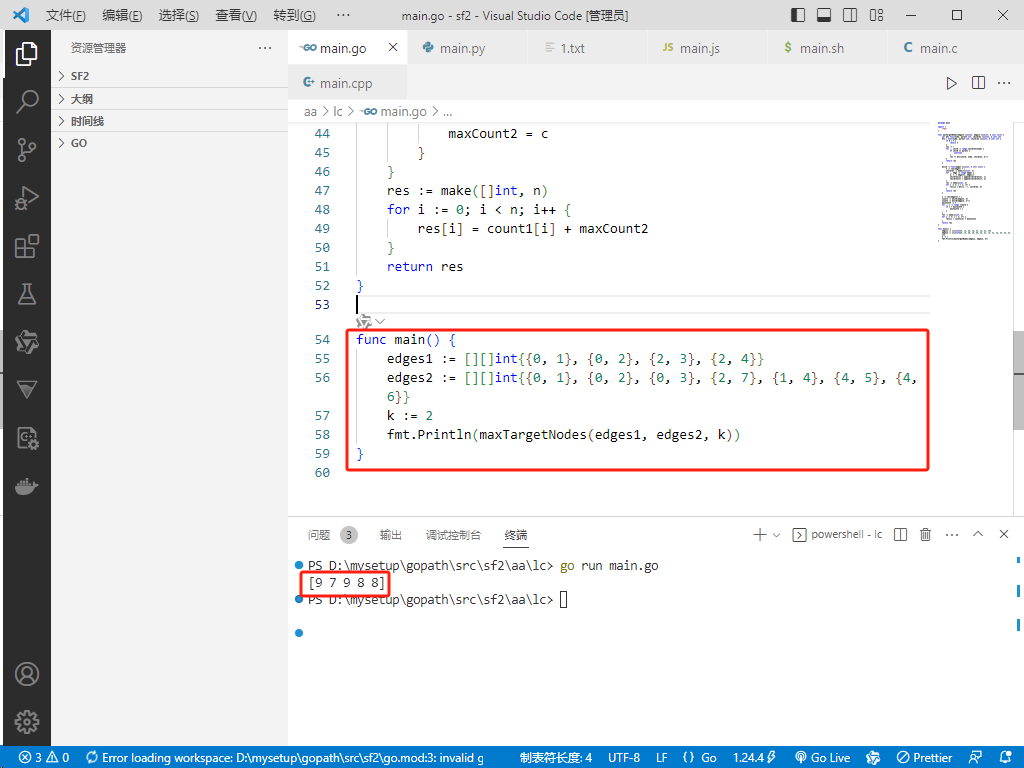
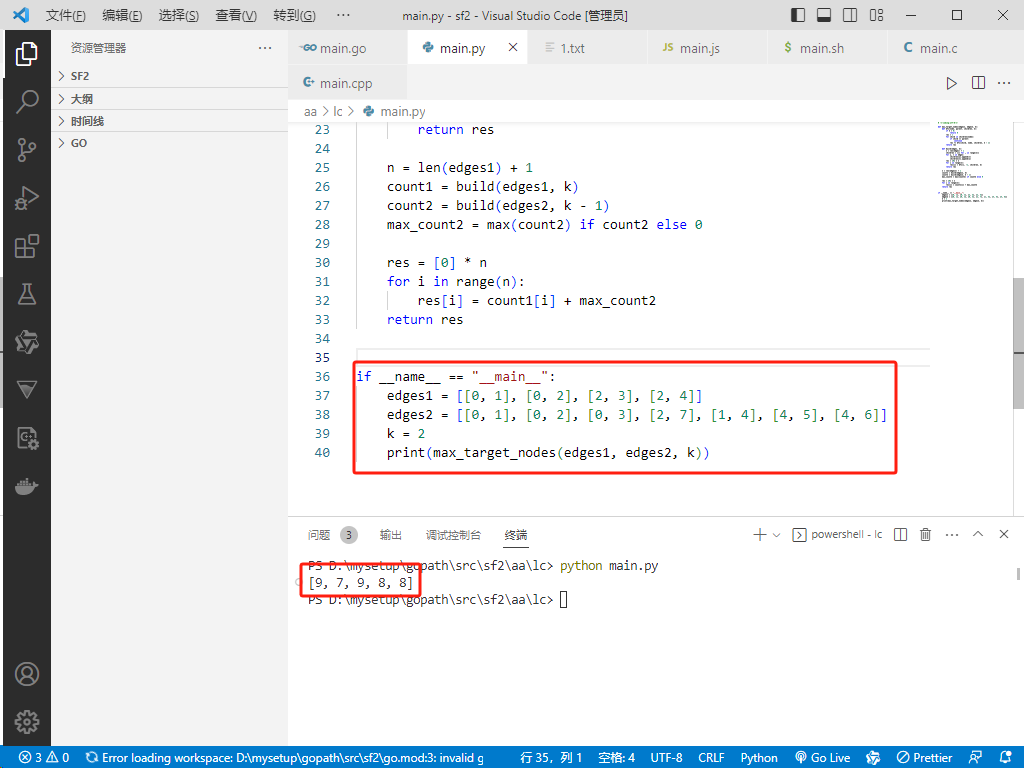
输出:[9,7,9,8,8]。
解释:
对于 i = 0 ,连接第一棵树中的节点 0 和第二棵树中的节点 0 。
对于 i = 1 ,连接第一棵树中的节点 1 和第二棵树中的节点 0 。
对于 i = 2 ,连接第一棵树中的节点 2 和第二棵树中的节点 4 。
对于 i = 3 ,连接第一棵树中的节点 3 和第二棵树中的节点 4 。
对于 i = 4 ,连接第一棵树中的节点 4 和第二棵树中的节点 4 。
题目来自力扣3372。
解决步骤
-
构建两棵树的邻接表:
- 对于第一棵树
edges1,构建邻接表children1,表示每个节点的邻居。 - 对于第二棵树
edges2,构建邻接表children2,表示每个节点的邻居。
- 对于第一棵树
-
计算第一棵树的每个节点的目标节点数量(不连接第二棵树):
- 对于第一棵树的每个节点
i,使用深度优先搜索(DFS)计算以i为中心、路径长度不超过k的节点数量。这个数量记为count1[i]。 - DFS 的过程是从
i出发,遍历所有可能的路径,统计距离不超过k的节点数量。
- 对于第一棵树的每个节点
-
计算第二棵树的每个节点的目标节点数量(以
k-1为限制):- 对于第二棵树的每个节点
j,使用 DFS 计算以j为中心、路径长度不超过k-1的节点数量。这个数量记为count2[j]。 - 因为连接
i和j后,从i到第二棵树的节点的路径长度会增加 1(因为需要经过新加的边),所以第二棵树的限制是k-1。
- 对于第二棵树的每个节点
-
找到第二棵树中的最大
count2[j]:- 遍历
count2数组,找到其中的最大值maxCount2。这个值表示第二棵树中某个节点j的最大贡献。
- 遍历
-
计算最终结果:
- 对于第一棵树的每个节点
i,其最大目标节点数量是count1[i] + maxCount2。这是因为:count1[i]是第一棵树中距离i不超过k的节点数量。maxCount2是第二棵树中距离某个j不超过k-1的节点数量,连接i和j后,这些节点也会成为i的目标节点。
- 因此,
answer[i] = count1[i] + maxCount2。
- 对于第一棵树的每个节点
时间复杂度
- 构建邻接表:
- 两棵树的邻接表构建都是
O(n + m),因为每条边被处理一次。
- 两棵树的邻接表构建都是
- 计算
count1:- 对于第一棵树的每个节点
i,进行一次 DFS,每次 DFS 的时间复杂度是O(n)(因为树有n-1条边)。 - 总时间复杂度是
O(n^2)。
- 对于第一棵树的每个节点
- 计算
count2:- 对于第二棵树的每个节点
j,进行一次 DFS,每次 DFS 的时间复杂度是O(m)。 - 总时间复杂度是
O(m^2)。
- 对于第二棵树的每个节点
- 找到
maxCount2:- 遍历
count2数组,时间复杂度是O(m)。
- 遍历
- 计算最终结果:
- 遍历
count1数组,时间复杂度是O(n)。
- 遍历
- 总时间复杂度是
O(n^2 + m^2)。
空间复杂度
- 邻接表:
children1和children2的空间复杂度是O(n + m)。
count1和count2:- 空间复杂度是
O(n + m)。
- 空间复杂度是
- DFS 的递归栈:
- 最坏情况下是
O(n)或O(m)。
- 最坏情况下是
- 总空间复杂度是
O(n + m)。
总结
- 时间复杂度:
O(n^2 + m^2)。 - 空间复杂度:
O(n + m)。
Go完整代码如下:
.
package main
import (
"fmt"
)
func maxTargetNodes(edges1 [][]int, edges2 [][]int, k int) []int {
var dfs func(node, parent int, children [][]int, k int) int
dfs = func(node, parent int, children [][]int, k int) int {
if k < 0 {
return 0
}
res := 1
for _, child := range children[node] {
if child == parent {
continue
}
res += dfs(child, node, children, k-1)
}
return res
}
build := func(edges [][]int, k int) []int {
n := len(edges) + 1
children := make([][]int, n)
for _, edge := range edges {
u, v := edge[0], edge[1]
children[u] = append(children[u], v)
children[v] = append(children[v], u)
}
res := make([]int, n)
for i := 0; i < n; i++ {
res[i] = dfs(i, -1, children, k)
}
return res
}
n := len(edges1) + 1
count1 := build(edges1, k)
count2 := build(edges2, k-1)
maxCount2 := 0
for _, c := range count2 {
if c > maxCount2 {
maxCount2 = c
}
}
res := make([]int, n)
for i := 0; i < n; i++ {
res[i] = count1[i] + maxCount2
}
return res
}
func main() {
edges1 := [][]int{{0, 1}, {0, 2}, {2, 3}, {2, 4}}
edges2 := [][]int{{0, 1}, {0, 2}, {0, 3}, {2, 7}, {1, 4}, {4, 5}, {4, 6}}
k := 2
fmt.Println(maxTargetNodes(edges1, edges2, k))
}
Python完整代码如下:
.
# -*-coding:utf-8-*-
def max_target_nodes(edges1, edges2, k):
def dfs(node, parent, children, k):
if k < 0:
return 0
res = 1
for child in children[node]:
if child == parent:
continue
res += dfs(child, node, children, k - 1)
return res
def build(edges, k):
n = len(edges) + 1
children = [[] for _ in range(n)]
for u, v in edges:
children[u].append(v)
children[v].append(u)
res = [0] * n
for i in range(n):
res[i] = dfs(i, -1, children, k)
return res
n = len(edges1) + 1
count1 = build(edges1, k)
count2 = build(edges2, k - 1)
max_count2 = max(count2) if count2 else 0
res = [0] * n
for i in range(n):
res[i] = count1[i] + max_count2
return res
if __name__ == "__main__":
edges1 = [[0, 1], [0, 2], [2, 3], [2, 4]]
edges2 = [[0, 1], [0, 2], [0, 3], [2, 7], [1, 4], [4, 5], [4, 6]]
k = 2
print(max_target_nodes(edges1, edges2, k))

- 点赞
- 收藏
- 关注作者
评论(0)