2025-05-19:找到初始输入字符串Ⅰ。用go语言,Alice 在电脑上输入一个字符串时,可能会因为按键时间过长,导致某个字

【摘要】 2025-05-19:找到初始输入字符串Ⅰ。用go语言,Alice 在电脑上输入一个字符串时,可能会因为按键时间过长,导致某个字符被重复输入多次。尽管她尽力避免犯错,但最终的输入结果最多只有一次此类重复错误。给定一个字符串 word,表示她输入后显示在屏幕上的内容。请你计算,有多少种不同的字符串,可能是她最初想输入的原始内容。换句话说,统计所有可能的原始字符串数量,使得经过最多一次重复按键导...
2025-05-19:找到初始输入字符串Ⅰ。用go语言,Alice 在电脑上输入一个字符串时,可能会因为按键时间过长,导致某个字符被重复输入多次。尽管她尽力避免犯错,但最终的输入结果最多只有一次此类重复错误。
给定一个字符串 word,表示她输入后显示在屏幕上的内容。请你计算,有多少种不同的字符串,可能是她最初想输入的原始内容。换句话说,统计所有可能的原始字符串数量,使得经过最多一次重复按键导致的字符延长后,能得到 word 这个字符串。
1 <= word.length <= 100。
word 只包含小写英文字母。
输入:word = “abbcccc”。
输出:5。
解释:
可能的字符串包括:“abbcccc” ,“abbccc” ,“abbcc” ,“abbc” 和 “abcccc”。
题目来自力扣3300。
解决思路
-
识别连续字符序列:首先,我们需要找到
word中所有连续的相同字符的序列。例如,“abbcccc” 可以分解为:- ‘a’:1 次
- ‘b’:2 次
- ‘c’:4 次
-
可能的原始字符序列:
- 对于每个连续的字符序列,如果其长度大于 1,则可以认为是由于重复按键导致的。因此,我们可以选择是否对该序列进行“还原”(即减少一个字符)。
- 对于长度为
n的连续字符序列:- 如果不进行还原,则原始序列长度仍为
n。 - 如果进行还原,则原始序列长度为
n-1(前提是n > 1)。
- 如果不进行还原,则原始序列长度仍为
- 由于最多只能有一次还原操作,因此我们需要考虑所有可能的序列中选择最多一个序列进行还原。
-
计数规则:
- 初始情况:不进行任何还原,原始字符串就是
word本身。这是一种情况。 - 对于每个长度大于 1 的连续字符序列,可以选择对其进行还原。每个这样的选择都会对应一种新的原始字符串。
- 因此,总的不同原始字符串数量为:1(不还原) + 所有可以还原的连续字符序列的数量。
- 初始情况:不进行任何还原,原始字符串就是
-
具体步骤:
- 遍历
word,识别所有连续的相同字符的序列。 - 对于每个序列,如果其长度
> 1,则它可以被还原(即长度减 1)。 - 统计所有可以还原的序列的数量
k,则总的不同原始字符串数量为k + 1。
- 遍历
算法流程
- 初始化
count = 1(对应不还原的情况)。 - 遍历
word,记录当前连续字符的长度。 - 每当遇到一个新的字符或字符串结束时:
- 如果前一个连续字符的长度
> 1,则count += 1(因为可以还原一次)。 - 对于长度
> 1的连续字符序列,可以还原的次数是length - 1(但每次只能选择一个还原,因此每个序列贡献1到count)。 - 实际上,对于每个连续序列,如果长度
> 1,则可以贡献1到count(因为可以选择是否还原该序列中的某个重复字符,但只能选一个)。 - 但根据示例,对于 “cccc”(长度 4),可以还原为 “ccc”、“cc” 或 “c”,即 3 种选择。这与之前的理解矛盾。
- 重新思考:对于长度为
n的连续序列,可以还原的位置是n-1个(即选择哪个重复的字符被去掉)。但题目要求最多一次还原,因此可以选择其中一个位置还原,或者不还原。 - 因此,对于每个连续序列,如果长度
> 1,则贡献n-1种还原方式。 - 但题目要求最多一次还原,因此总数量是:
- 不还原:1
- 选择一个位置还原:sum over all possible single reductions.
- 因此,对于 “abbcccc”:
- ‘b’:长度 2,可以还原 1 种(去掉一个 ‘b’)。
- ‘c’:长度 4,可以还原 3 种(去掉一个 ‘c’ 的三种方式)。
- 总计:1 (no) + 1 (b) + 3 © = 5。
- 如果前一个连续字符的长度
代码逻辑
给定的代码 possibleStringCount 的逻辑:
- 初始化
ans = 1(不还原的情况)。 - 遍历
word,检查word[i-1] == word[i]:- 如果相等,说明当前字符与前一个字符相同,可能是重复的,因此
ans++。 - 实际上,这是在统计所有可能的“可以还原的位置”:
- 对于连续
n个相同字符,有n-1个位置可以还原(即ans += n-1)。 - 但代码中
ans++是在每次连续时增加,因此对于连续n个字符,ans会增加n-1次。 - 例如 “bb”:
ans从 1 开始,i=1时word[0] == word[1],ans++→ 2。 - “ccc”:初始
ans=1,i=1:ans=2,i=2:ans=3→ 总共增加 2。 - 因此,
ans的值为1 + sum over all consecutive sequences (length - 1)。 - 这与我们的分析一致。
- 对于连续
- 如果相等,说明当前字符与前一个字符相同,可能是重复的,因此
复杂度分析
- 时间复杂度:
O(n),其中n是word的长度。我们只需要遍历字符串一次。 - 额外空间复杂度:
O(1),只使用了常数级别的额外空间(几个变量)。
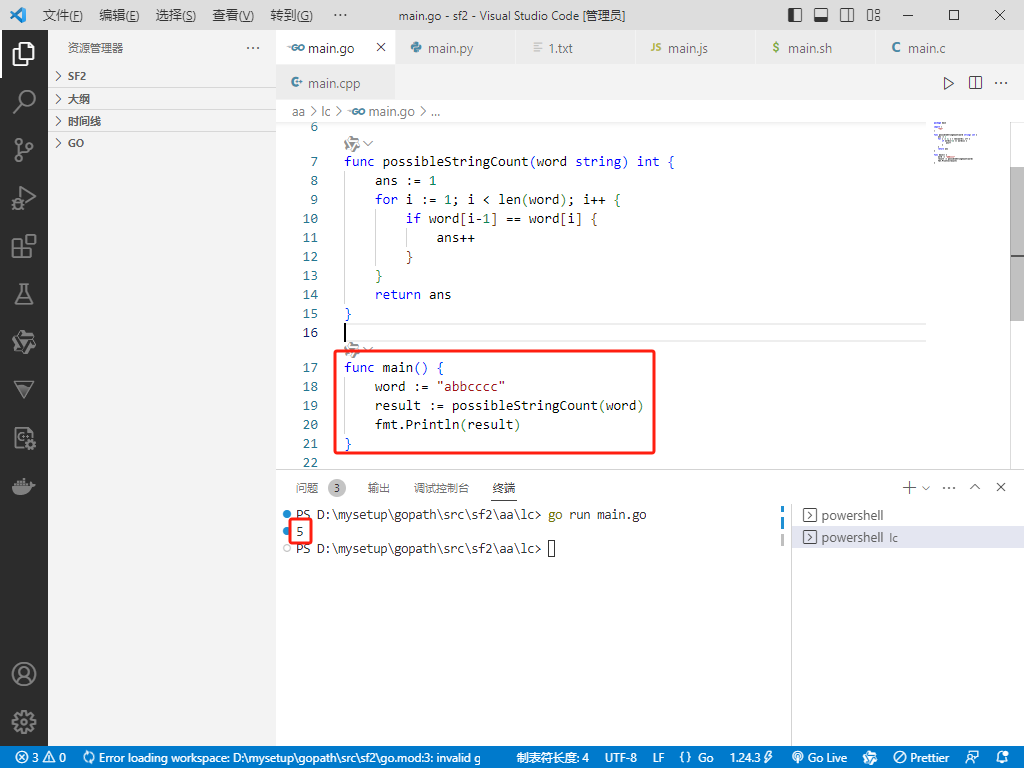
Go完整代码如下:
package main
import (
"fmt"
)
func possibleStringCount(word string) int {
ans := 1
for i := 1; i < len(word); i++ {
if word[i-1] == word[i] {
ans++
}
}
return ans
}
func main() {
word := "abbcccc"
result := possibleStringCount(word)
fmt.Println(result)
}
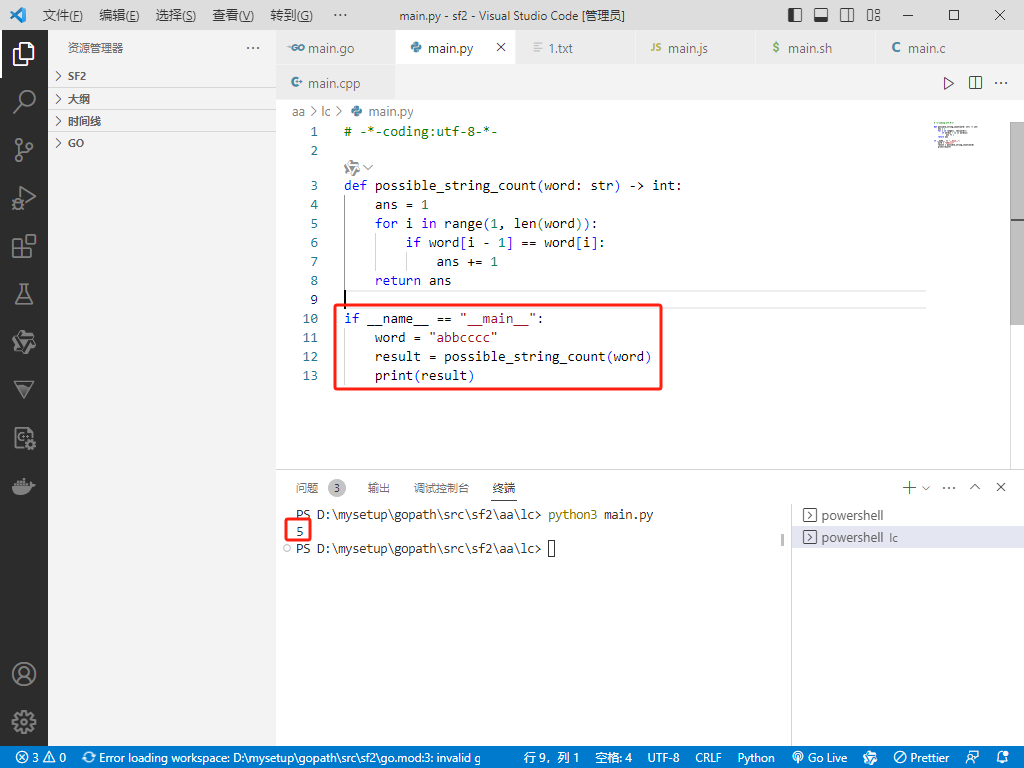
Python完整代码如下:
# -*-coding:utf-8-*-
def possible_string_count(word: str) -> int:
ans = 1
for i in range(1, len(word)):
if word[i - 1] == word[i]:
ans += 1
return ans
if __name__ == "__main__":
word = "abbcccc"
result = possible_string_count(word)
print(result)
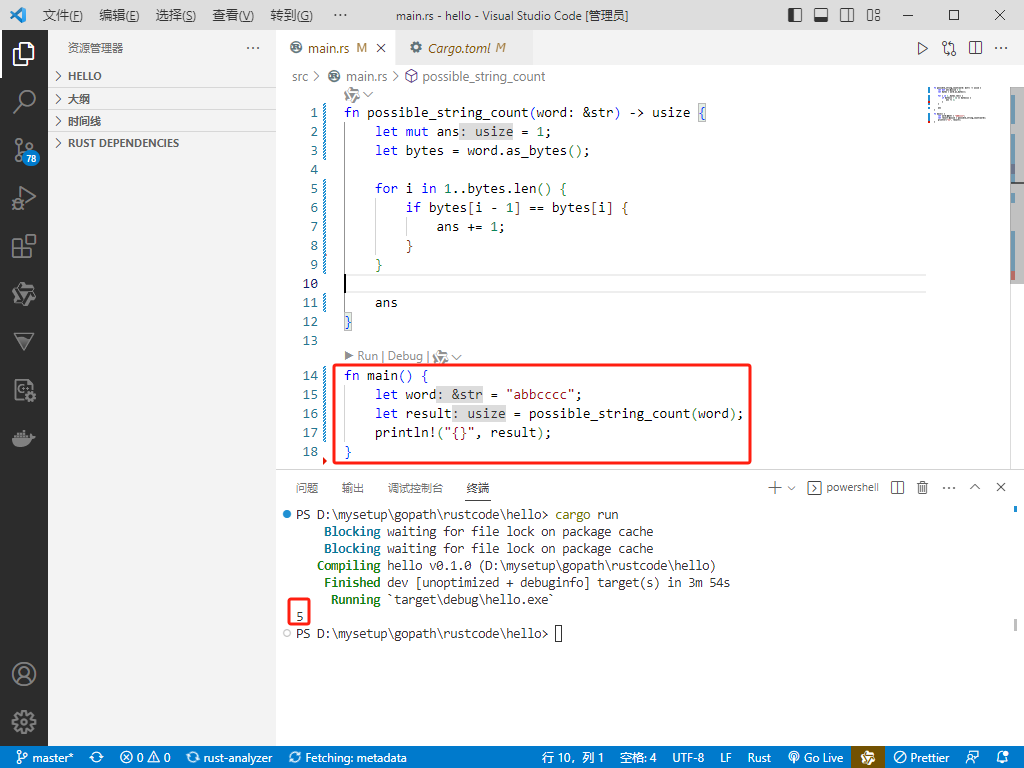
Rust完整代码如下:
fn possible_string_count(word: &str) -> usize {
let mut ans = 1;
let bytes = word.as_bytes();
for i in 1..bytes.len() {
if bytes[i - 1] == bytes[i] {
ans += 1;
}
}
ans
}
fn main() {
let word = "abbcccc";
let result = possible_string_count(word);
println!("{}", result);
}

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)