2025-05-18:判断 DFS 字符串是否是回文串。用go语言,给定一棵包含 n 个节点的树,节点编号从 0 到 n-1,根

2025-05-18:判断 DFS 字符串是否是回文串。用go语言,给定一棵包含 n 个节点的树,节点编号从 0 到 n-1,根节点编号为 0。用一个长度为 n 的数组 parent 表示树的结构,其中 parent[i] 代表节点 i 的父节点,且因为 0 是根节点,所以 parent[0] 必定为 -1。
同时给出一个长度为 n 的字符串 s,s[i] 是节点 i 对应的字符。
定义一个全局字符串 dfsStr 和一个递归函数 dfs(x):
-
对节点 x 的所有子节点按编号从小到大依次调用 dfs(y)。
-
递归调用结束后,将节点 x 对应的字符 s[x] 追加到 dfsStr 末尾。
现在,对每个节点 i(0 ≤ i < n),执行以下操作:
-
将 dfsStr 清空。
-
调用 dfs(i)。
-
判断 dfsStr 是否为回文串,若是,则 answer[i] = true;否则 answer[i] = false。
请编写程序返回数组 answer。
n == parent.length == s.length。
1 <= n <= 100000。
对于所有 i >= 1 ,都有 0 <= parent[i] <= n - 1 。
parent[0] == -1。
parent 表示一棵合法的树。
s 只包含小写英文字母。
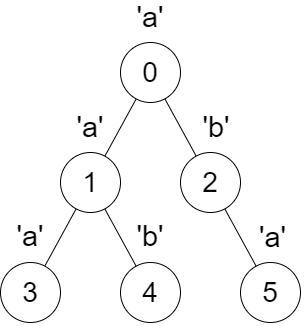
输入:parent = [-1,0,0,1,1,2], s = “aababa”。
输出:[true,true,false,true,true,true]。
解释:
调用 dfs(0) ,得到字符串 dfsStr = “abaaba” ,是一个回文串。
调用 dfs(1) ,得到字符串dfsStr = “aba” ,是一个回文串。
调用 dfs(2) ,得到字符串dfsStr = “ab” ,不 是回文串。
调用 dfs(3) ,得到字符串dfsStr = “a” ,是一个回文串。
调用 dfs(4) ,得到字符串 dfsStr = “b” ,是一个回文串。
调用 dfs(5) ,得到字符串 dfsStr = “a” ,是一个回文串。
题目来自3227。
解决步骤
1. 构建树结构
- 给定
parent数组,构建树的邻接表表示g,其中g[x]是节点x的子节点列表。 - 由于
i是从小到大遍历的,g[p]中的子节点列表自然是有序的(按编号从小到大),无需额外排序。
2. 后序遍历与时间戳记录
- 对每个节点
i,我们需要以i为根进行后序遍历,得到dfsStr。 - 直接对每个节点单独进行后序遍历的时间复杂度是 O(n^2),无法处理 n=1e5 的情况。
- 优化思路:
- 预处理整棵树的后序遍历序列
dfsStr和时间戳nodes。 nodes[i]记录以i为根的子树在后序遍历序列中的区间[begin, end)。- 这样,以
i为根的dfsStr就是dfsStr的[nodes[i].begin, nodes[i].end)子串。
- 预处理整棵树的后序遍历序列
3. 预处理后序遍历和时间戳
- 从根节点
0开始进行一次后序遍历:- 记录每个节点的
begin时间戳(进入该子树时的时间)。 - 遍历所有子节点后,记录当前字符到
dfsStr,并更新end时间戳(离开该子树时的时间+1)。
- 记录每个节点的
- 这样,
dfsStr是整个树的后序遍历结果,nodes[i]记录了以i为根的子树在dfsStr中的区间。
4. Manacher 算法预处理
- 我们需要快速判断
dfsStr的任意子串[l, r)是否为回文串。 - 使用 Manacher 算法预处理
dfsStr,得到每个位置的最长回文半径。 - 将
dfsStr转换为t(插入特殊字符#和边界字符^、$),以便统一处理奇偶长度的回文串。 halfLen[i]表示t中以i为中心的最长回文子串的半径。- 通过
halfLen可以快速判断dfsStr的任意子串是否为回文串:- 子串
[l, r)在t中的中心位置是l + r + 1。 - 如果
halfLen[l + r + 1] > r - l,则[l, r)是回文串。
- 子串
5. 计算答案
- 对于每个节点
i,其对应的dfsStr是dfsStr的[nodes[i].begin, nodes[i].end)子串。 - 使用
isPalindrome(nodes[i].begin, nodes[i].end)判断该子串是否为回文串,结果存入answer[i]。
时间复杂度
- 构建邻接表
g:O(n)。 - 后序遍历和时间戳记录:O(n)(每个节点访问一次)。
- Manacher 算法预处理:O(n)。
- 计算答案:O(n)(每个节点判断一次,
isPalindrome是 O(1))。
- 总时间复杂度:O(n)。
额外空间复杂度
- 邻接表
g:O(n)。 dfsStr:O(n)。nodes数组:O(n)。t和halfLen:O(n)。
- 总额外空间复杂度:O(n)。
Go完整代码如下:
package main
import (
"fmt"
)
func findAnswer(parent []int, s string) []bool {
n := len(parent)
g := make([][]int, n)
for i := 1; i < n; i++ {
p := parent[i]
// 由于 i 是递增的,所以 g[p] 必然是有序的,下面无需排序
g[p] = append(g[p], i)
}
// dfsStr 是后序遍历整棵树得到的字符串
dfsStr := make([]byte, n)
// nodes[i] 表示子树 i 的后序遍历的开始时间戳和结束时间戳+1(左闭右开区间)
nodes := make([]struct{ begin, end int }, n)
time := 0
var dfs func(int)
dfs = func(x int) {
nodes[x].begin = time
for _, y := range g[x] {
dfs(y)
}
dfsStr[time] = s[x] // 后序遍历
time++
nodes[x].end = time
}
dfs(0)
// Manacher 模板
// 将 dfsStr 改造为 t,这样就不需要讨论 n 的奇偶性,因为新串 t 的每个回文子串都是奇回文串(都有回文中心)
// dfsStr 和 t 的下标转换关系:
// (dfsStr_i+1)*2 = ti
// ti/2-1 = dfsStr_i
// ti 为偶数,对应奇回文串(从 2 开始)
// ti 为奇数,对应偶回文串(从 3 开始)
t := append(make([]byte, 0, n*2+3), '^')
for _, c := range dfsStr {
t = append(t, '#', c)
}
t = append(t, '#', '$')
// 定义一个奇回文串的回文半径=(长度+1)/2,即保留回文中心,去掉一侧后的剩余字符串的长度
// halfLen[i] 表示在 t 上的以 t[i] 为回文中心的最长回文子串的回文半径
// 即 [i-halfLen[i]+1,i+halfLen[i]-1] 是 t 上的一个回文子串
halfLen := make([]int, len(t)-2)
halfLen[1] = 1
// boxR 表示当前右边界下标最大的回文子串的右边界下标+1
// boxM 为该回文子串的中心位置,二者的关系为 r=mid+halfLen[mid]
boxM, boxR := 0, 0
for i := 2; i < len(halfLen); i++ { // 循环的起止位置对应着原串的首尾字符
hl := 1
if i < boxR {
// 记 i 关于 boxM 的对称位置 i'=boxM*2-i
// 若以 i' 为中心的最长回文子串范围超出了以 boxM 为中心的回文串的范围(即 i+halfLen[i'] >= boxR)
// 则 halfLen[i] 应先初始化为已知的回文半径 boxR-i,然后再继续暴力匹配
// 否则 halfLen[i] 与 halfLen[i'] 相等
hl = min(halfLen[boxM*2-i], boxR-i)
}
// 暴力扩展
// 算法的复杂度取决于这部分执行的次数
// 由于扩展之后 boxR 必然会更新(右移),且扩展的的次数就是 boxR 右移的次数
// 因此算法的复杂度 = O(len(t)) = O(n)
for t[i-hl] == t[i+hl] {
hl++
boxM, boxR = i, i+hl
}
halfLen[i] = hl
}
// t 中回文子串的长度为 hl*2-1
// 由于其中 # 的数量总是比字母的数量多 1
// 因此其在 dfsStr 中对应的回文子串的长度为 hl-1
// 这一结论可用在 isPalindrome 中
// 判断左闭右开区间 [l,r) 是否为回文串 0<=l<r<=n
// 根据下标转换关系得到 dfsStr 的 [l,r) 子串在 t 中对应的回文中心下标为 l+r+1
// 需要满足 halfLen[l+r+1]-1 >= r-l,即 halfLen[l+r+1] > r-l
isPalindrome := func(l, r int) bool { return halfLen[l+r+1] > r-l }
ans := make([]bool, n)
for i, p := range nodes {
ans[i] = isPalindrome(p.begin, p.end)
}
return ans
}
func main() {
parent := []int{-1, 0, 0, 1, 1, 2}
s := "aababa"
result := findAnswer(parent, s)
fmt.Println(result)
}
Rust完整代码如下:
use std::cmp::min;
fn find_answer(parent: &[i32], s: &str) -> Vec<bool> {
let n = parent.len();
let mut g = vec![Vec::new(); n];
for i in 1..n {
let p = parent[i] as usize;
// 由于 i 递增,g[p] 本身有序,无需排序
g[p].push(i);
}
// dfsStr 存储整棵树的后序遍历字符串
let mut dfs_str = vec![0u8; n];
// nodes[i] 记录子树 i 的后序遍历区间 (begin, end)
let mut nodes = vec![(0, 0); n];
let mut time = 0;
fn dfs(
x: usize,
g: &Vec<Vec<usize>>,
s: &[u8],
nodes: &mut Vec<(usize, usize)>,
dfs_str: &mut Vec<u8>,
time: &mut usize,
) {
nodes[x].0 = *time;
for &y in &g[x] {
dfs(y, g, s, nodes, dfs_str, time);
}
dfs_str[*time] = s[x];
*time += 1;
nodes[x].1 = *time;
}
dfs(0, &g, s.as_bytes(), &mut nodes, &mut dfs_str, &mut time);
// Manacher 算法处理 dfs_str
// 转换字符串 t: ^#a#b#c#...#$
let mut t = Vec::with_capacity(n * 2 + 3);
t.push(b'^');
for &c in &dfs_str {
t.push(b'#');
t.push(c);
}
t.push(b'#');
t.push(b'$');
let m = t.len();
// half_len[i]: 以 t[i] 为中心的最长回文半径(包含中心)
let mut half_len = vec![0; m - 2];
half_len[1] = 1;
let mut box_m = 0;
let mut box_r = 0;
for i in 2..half_len.len() {
let mut hl = 1;
if i < box_r {
hl = min(half_len[box_m * 2 - i], box_r - i);
}
while t[i - hl] == t[i + hl] {
hl += 1;
box_m = i;
box_r = i + hl;
}
half_len[i] = hl;
}
// 判断子串 [l, r) 是否回文
// 对应t中的中心位置为 l + r + 1
let is_palindrome = |l: usize, r: usize| half_len[l + r + 1] > r - l;
let mut ans = vec![false; n];
for i in 0..n {
let (begin, end) = nodes[i];
ans[i] = is_palindrome(begin, end);
}
ans
}
fn main() {
let parent = vec![-1, 0, 0, 1, 1, 2];
let s = "aababa";
let result = find_answer(&parent, s);
println!("{:?}", result);
}
Python完整代码如下:
# -*-coding:utf-8-*-
from typing import List
def find_answer(parent: List[int], s: str) -> List[bool]:
n = len(parent)
g = [[] for _ in range(n)]
# 建树,parent[i] 为 i 的父节点,i从1开始
for i in range(1, n):
p = parent[i]
# i 按升序遍历保证子节点列表有序,无需再排序
g[p].append(i)
dfs_str = [''] * n
nodes = [{'begin': 0, 'end': 0} for _ in range(n)]
time = 0
def dfs(x: int):
nonlocal time
nodes[x]['begin'] = time
for y in g[x]:
dfs(y)
dfs_str[time] = s[x]
time += 1
nodes[x]['end'] = time
dfs(0)
# Manacher 算法预处理,将 dfs_str 转换为新的串 t
# 用特殊字符分割,简化回文判断,避免奇偶问题
t = ['^']
for c in dfs_str:
t.append('#')
t.append(c)
t.append('#')
t.append('$')
half_len = [0] * (len(t) - 2)
half_len[1] = 1
box_m, box_r = 0, 0
for i in range(2, len(half_len)):
hl = 1
if i < box_r:
hl = min(half_len[box_m * 2 - i], box_r - i)
while t[i - hl] == t[i + hl]:
hl += 1
box_m, box_r = i, i + hl
half_len[i] = hl
def is_palindrome(l: int, r: int) -> bool:
# 判断 dfs_str[l:r] 是否回文
# 回文中心在 t 中位置为 l + r + 1
# half_len[i] 表示回文半径,回文长度 = half_len[i] * 2 - 1
# 由于分隔符的关系,dfs_str 对应子串长度 = r - l,判断条件为 half_len[l+r+1] > r-l
return half_len[l + r + 1] > (r - l)
ans = [False] * n
for i in range(n):
p = nodes[i]
ans[i] = is_palindrome(p['begin'], p['end'])
return ans
if __name__ == "__main__":
parent = [-1, 0, 0, 1, 1, 2]
s = "aababa"
result = find_answer(parent, s)
print(result) # 输出示例 [True, True, True, False, False, True]

- 点赞
- 收藏
- 关注作者
评论(0)