【愚公系列】《Python网络爬虫从入门到精通》046-验证码识别(字符验证码)

🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟
📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主!
👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"挖山不止"的毅力为开发者们搬开知识道路上的重重阻碍!
💎【行业认证·权威头衔】 ✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家 ✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主 ✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】 🎖 连续三年蝉联"华为云十佳博主"(2022-2024) 🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023) 🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】 覆盖全栈技术矩阵: ◾ 编程语言:.NET/Java/Python/Go/Node... ◾ 移动生态:HarmonyOS/iOS/Android/小程序 ◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙 ◾ 游戏开发:Unity3D引擎深度解析 每日更新硬核教程+实战案例,助你打通技术任督二脉!
💌【特别邀请】 正在构建技术人脉圈的你: 👍 如果这篇推文让你收获满满,点击"在看"传递技术火炬 💬 在评论区留下你最想学习的技术方向 ⭐ 点击"收藏"建立你的私人知识库 🔔 关注公众号获取独家技术内参 ✨与其仰望大神,不如成为大神!关注"愚公搬代码",让坚持的力量带你穿越技术迷雾,见证从量变到质变的奇迹!✨ |
🚀前言
在之前的内容中,我们已经学习了如何使用Python进行各类网络爬虫的编写与优化。然而,在实际的爬虫项目中,我们经常会遇到验证码的挑战,它是阻止自动化程序访问的重要手段之一。
本篇文章,我们将深入探讨验证码识别中的一种常见类型——字符验证码。验证码识别是爬虫自动化中的一项重要技能,掌握它将大大提升我们的爬虫项目的效率和成功率。
在这篇文章中,我们将会介绍:
-
验证码的基本原理:了解验证码的作用和常见类型。 -
字符验证码识别的基本方法:从简单的图像处理到使用OCR(光学字符识别)技术。 -
实战:使用Python和相关库进行字符验证码识别:包括Pillow、Tesseract-OCR等工具的使用。
通过这篇文章的学习,你将能够掌握字符验证码识别的基本方法,并将其应用到你的爬虫项目中,使你的爬虫能够更加智能和高效。让我们一同开启验证码识别的探索之旅吧!
🚀一、字符验证码识别
🔎1.字符验证码特点
-
包含数字、字母、斑点或混淆曲线的图片验证码。 -
识别流程: -
定位网页中验证码的HTML位置 -
下载验证码图片 -
使用Tesseract-OCR进行识别
-
🔎2.搭建OCR环境
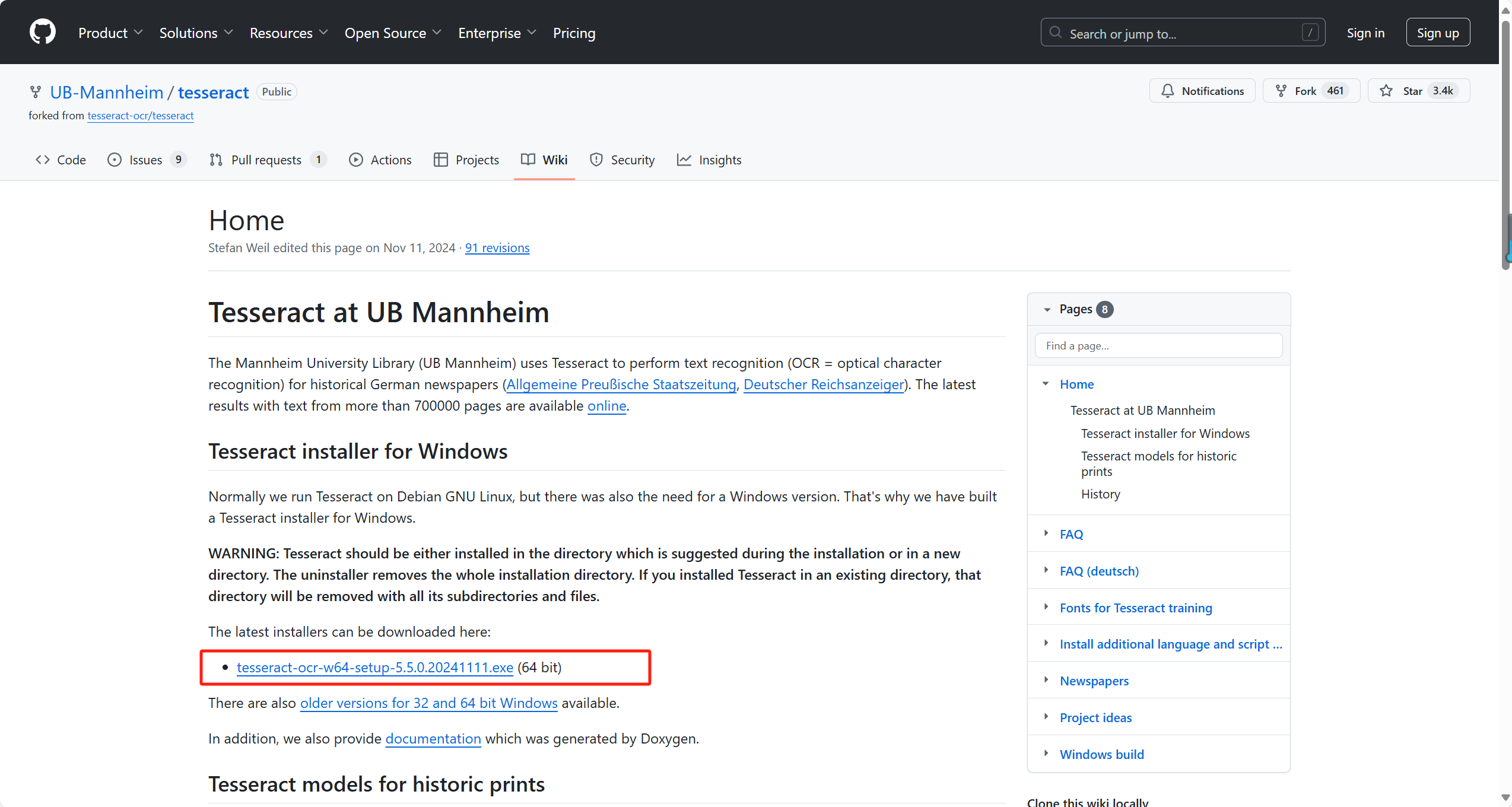
步骤1:安装Tesseract-OCR
-
下载地址:https://github.com/UB-Mannheim/tesseract/wiki

-
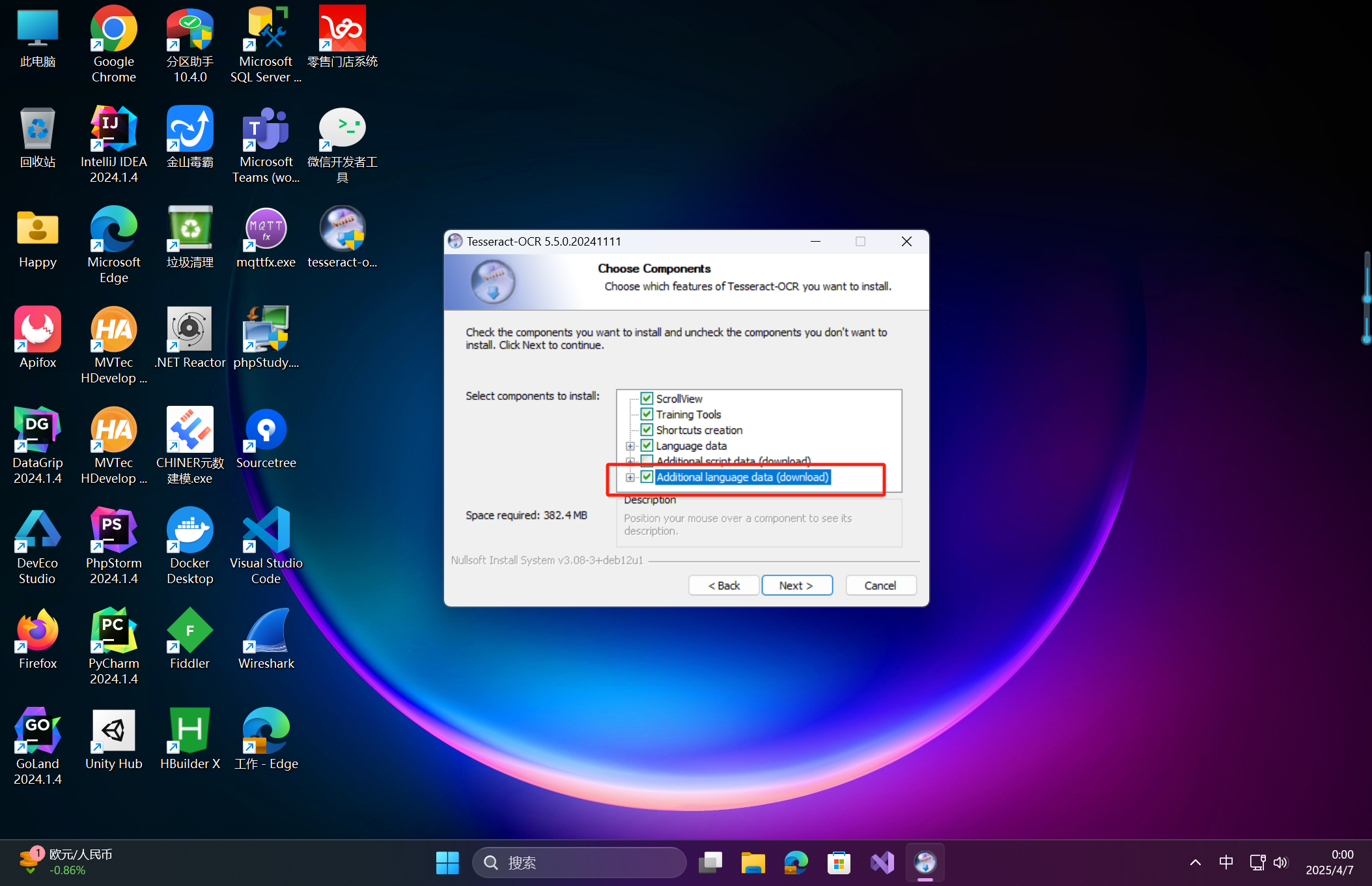
选择对应系统版本(如Windows 64位),安装时勾选 Additional language data 以支持多语言识别。
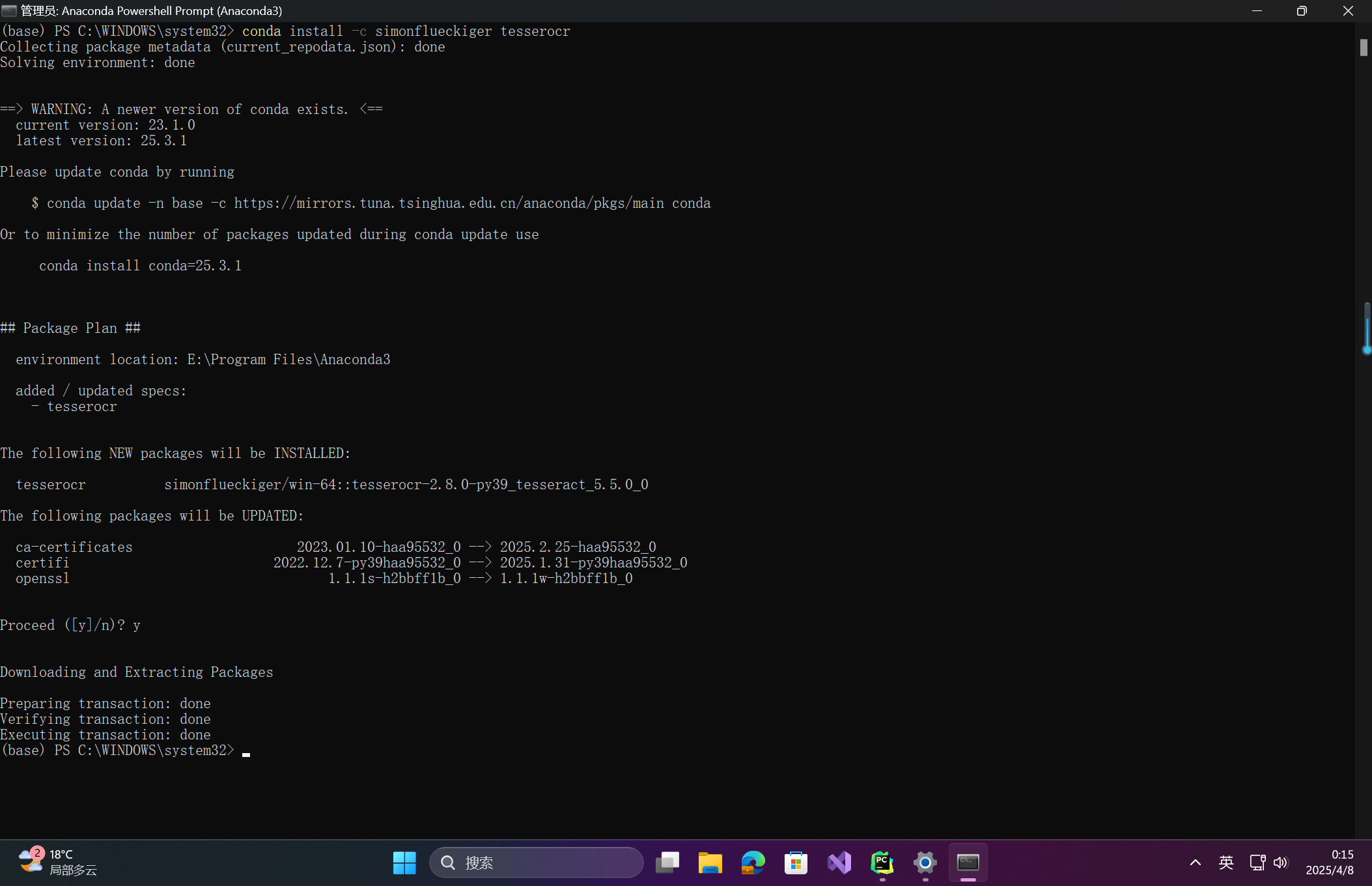
步骤2:安装Python依赖
# 安装tesserocr模块
pip install tesserocr
# 若使用Anaconda且安装失败,改用以下命令
conda install -c simonflueckiger tesserocr
 在这里插入图片描述
在这里插入图片描述
🔎3.下载验证码图片
示例:下载测试网页验证码
-
测试地址:http://localhost:8080/demo5/ -
实现代码: import requests # 导入网络请求模块 import urllib.request # 导入urllib.request模块 from fake_useragent import UserAgent # 导入随机请求头 from bs4 import BeautifulSoup # 导入解析html header = {'User-Agent':UserAgent().random} # 创建随机请求头 url = 'http://localhost:8080/demo5/' # 网页请求地址 # 发送网络请求 response = requests.get(url,header) response.encoding='utf-8' # 设置编码方式 html = BeautifulSoup(response.text,"html.parser") # 解析html src = html.find('img').get('src') img_url = url+src # 组合验证码图片请求地址 urllib.request.urlretrieve(img_url,'code.png') # 下载并设置图片名称
🔎4.识别验证码
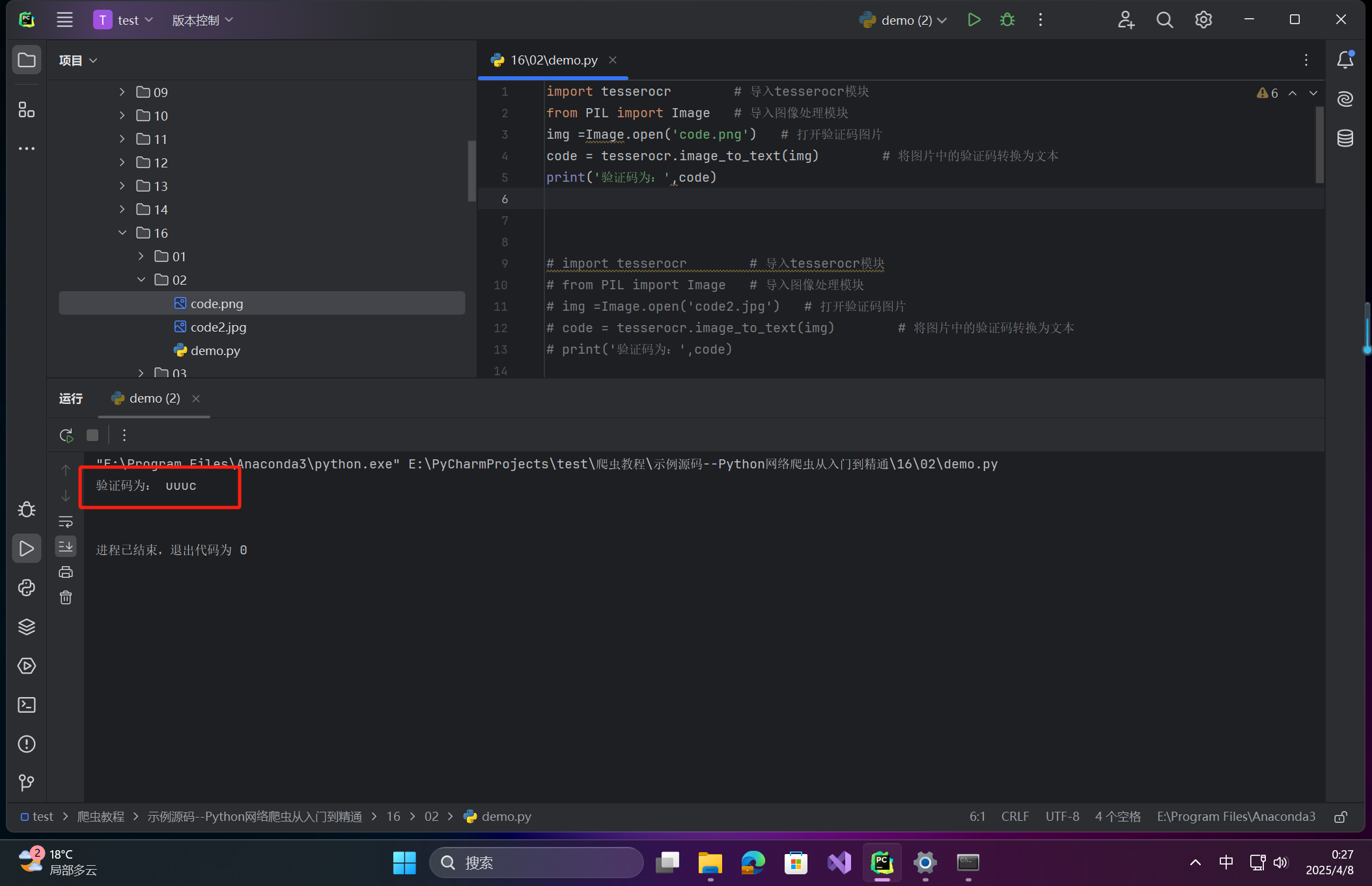
基础识别(无干扰线)
import tesserocr # 导入tesserocr模块
from PIL import Image # 导入图像处理模块
img =Image.open('code.png') # 打开验证码图片
code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本
print('验证码为:',code)
 在这里插入图片描述
在这里插入图片描述
处理干扰线的验证码
-
灰度处理
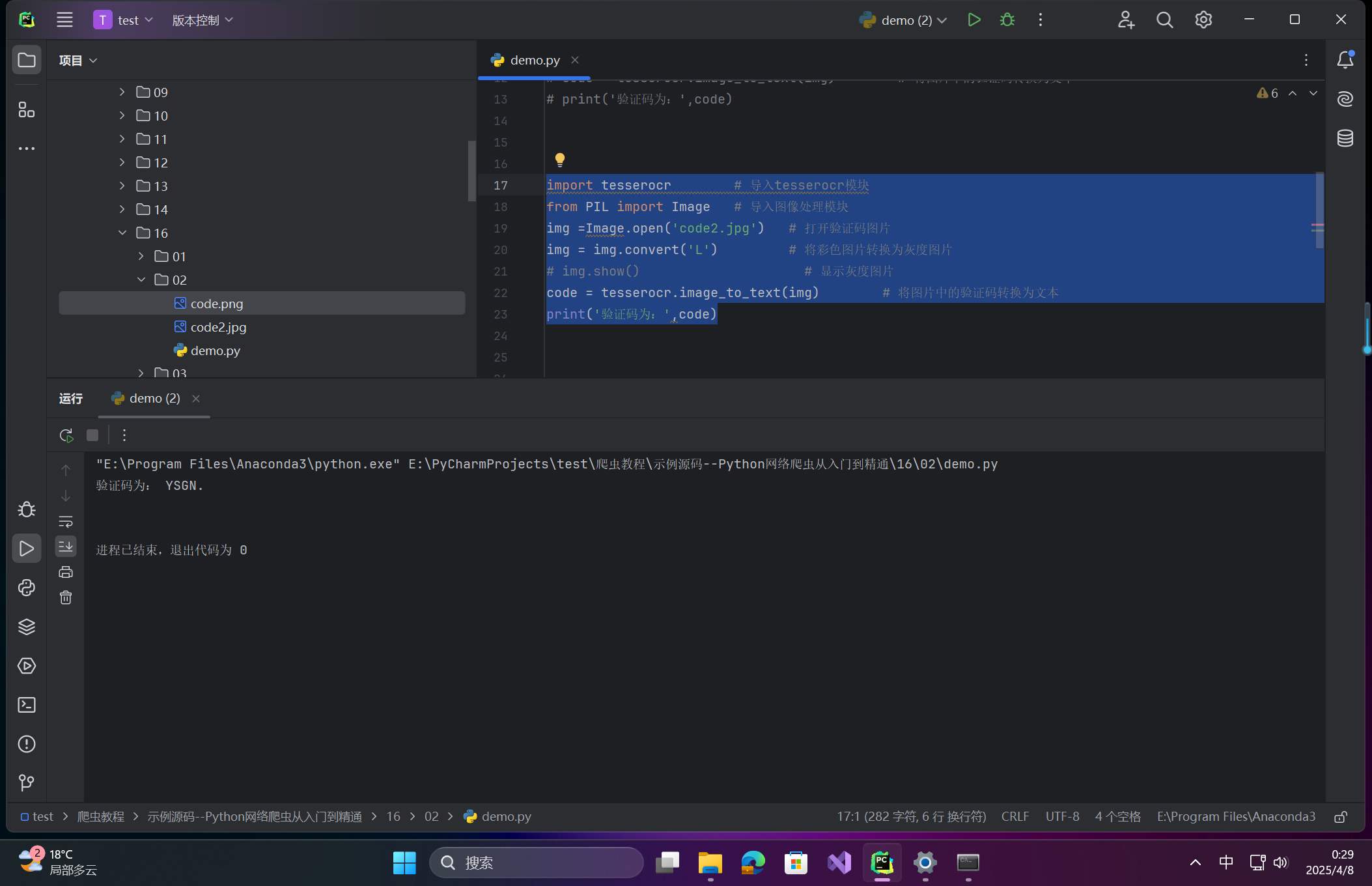
import tesserocr # 导入tesserocr模块 from PIL import Image # 导入图像处理模块 img =Image.open('code2.jpg') # 打开验证码图片 img = img.convert('L') # 将彩色图片转换为灰度图片 # img.show() # 显示灰度图片 code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本 print('验证码为:',code)在这里插入图片描述 -
二值化处理
import tesserocr # 导入tesserocr模块 from PIL import Image # 导入图像处理模块 img =Image.open('code2.jpg') # 打开验证码图片 img = img.convert('L') # 将彩色图片转换为灰度图片 t = 155 # 设置阀值 table = [] # 二值化数据的列表 for i in range(256): # 循环遍历 if i <t: table.append(0) else: table.append(1) img = img.point(table,'1') # 将图片进行二值化处理 img.show() # 显示处理后图片 code = tesserocr.image_to_text(img) # 将图片中的验证码转换为文本 print('验证码为:',code) # 打印验证码
 在这里插入图片描述
在这里插入图片描述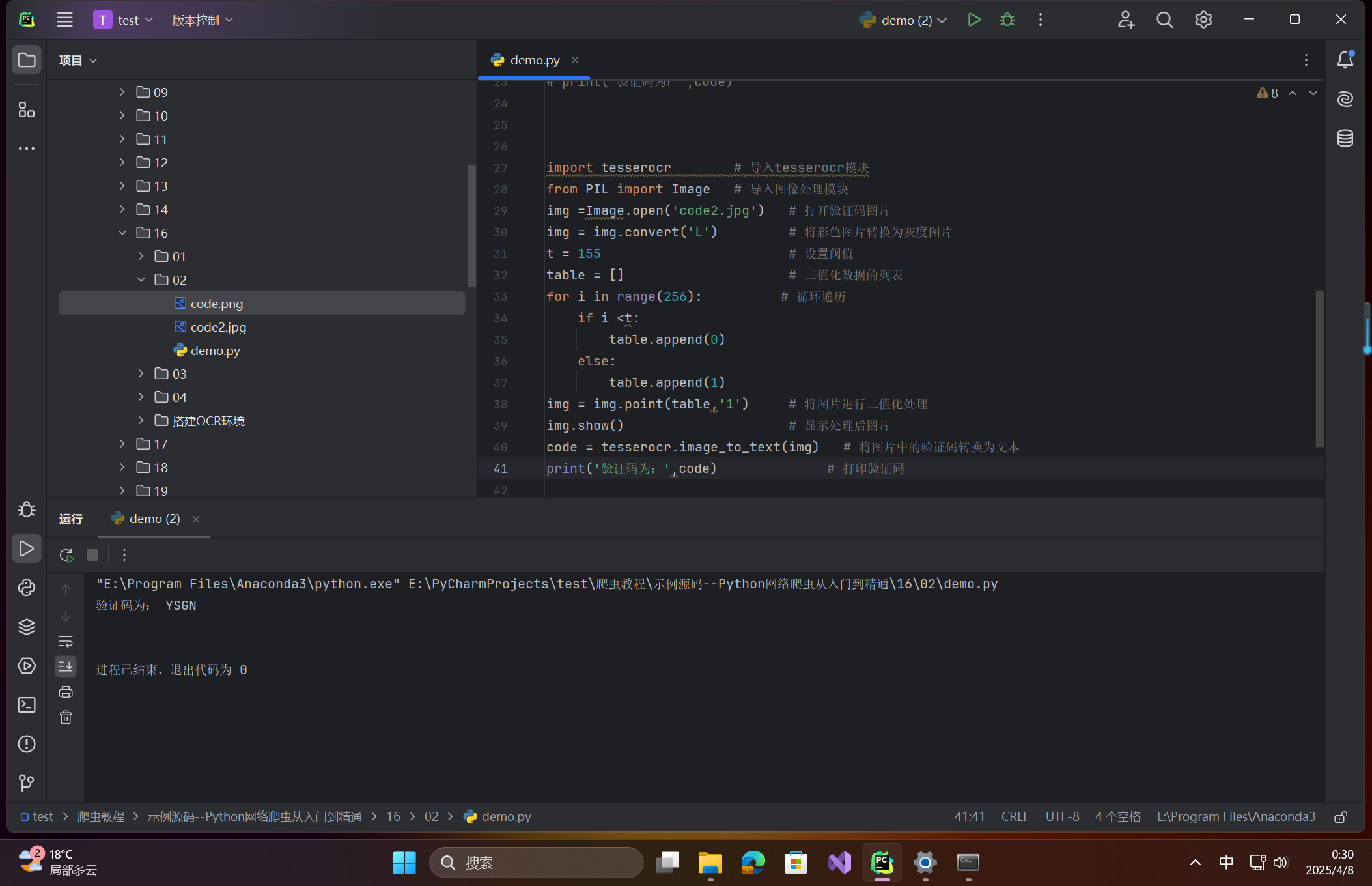 在这里插入图片描述
在这里插入图片描述
🔎5.注意事项
-
识别优化:通过调节二值化阈值(如 threshold=155)可提升识别精度。 -
干扰处理:若仍有误识别,需结合降噪、分割等图像预处理技术。 -
局限性:OCR对复杂干扰(密集噪点、扭曲变形)效果有限,需结合深度学习模型。

- 点赞
- 收藏
- 关注作者
评论(0)