【愚公系列】《Python网络爬虫从入门到精通》037-文件的存取

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在网络爬虫的开发过程中,数据的存取是一个至关重要的环节。无论是从网页抓取来的文本、图片,还是其他格式的数据,如何高效、准确地存储和读取这些信息,直接关系到爬虫的性能和后续数据分析的效果。在《Python网络爬虫从入门到精通》的第037篇文章中,我们将深入探讨文件的存取方法,帮助你在爬虫项目中灵活运用这些技巧。
本篇文章将涵盖文件的基本读写操作,包括如何使用Python的内置函数以及流行的第三方库来处理各类文件格式,如文本文件、CSV文件和JSON文件等。通过具体的实例,我们将演示如何将抓取的数据有效地保存到文件中,以及如何从文件中读取数据进行进一步处理。这些技能不仅能提升你在爬虫项目中的开发效率,还能帮助你更好地管理和利用数据。
🚀一、文件的存取
🔎1.📝 Python文件操作详解:TXT文件存储与读取
🦋1.1 文件存储基础
☀️1.1.1 open()函数核心参数
file = open(filename, mode='r', buffering=-1)
| 参数 | 说明 | 常用值 |
|---|---|---|
filename |
文件路径(相对/绝对) | "data.txt" |
mode |
文件访问模式 | r/w/a/r+/rb等 |
buffering |
缓冲策略(0=无缓冲,1=行缓冲,>1=缓冲区大小) | 默认系统缓冲设置 |
☀️1.1.2 文件模式详解
| 模式 | 说明 | 适用场景 |
|---|---|---|
r |
只读模式(默认) | 读取现有文件 |
w |
写入模式(覆盖原有内容) | 创建新文件/清空重写 |
a |
追加模式(在文件末尾添加) | 日志文件记录 |
r+ |
读写模式(指针在开头) | 需要同时读写操作 |
rb |
二进制只读 | 处理非文本文件 |
wb |
二进制写入 | 保存图片/视频 |
🦋1.2 实战存储示例
import requests # 导入网络请求模块
from bs4 import BeautifulSoup # html解析库
url = 'http://quotes.toscrape.com/tag/inspirational/' # 定义请求地址
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
response = requests.get(url,headers) # 发送网络请求
if response.status_code==200: # 如果请求成功
#创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(response.text, features="lxml")
text_all = soup.find_all('span',class_='text') # 获取所有显示励志名句的span标签
txt_file = open('data.txt','w',encoding='utf-8') # 创建open对象
for i,value in enumerate(text_all): # 循环遍历爬取内容
txt_file.write(str(i)+value.text+'\n') # 写入每条爬取的励志名句并在结尾换行
txt_file.close() # 关闭文件操作
输出文件示例: 
🦋1.3 文件读取技术
☀️1.3.1 读取指定字符
with open('message.txt', 'r', encoding='utf-8') as f:
content = f.read(9) # 读取前9个字符
print(content) # 输出:Python的强
☀️1.3.2 指针定位读取
with open('message.txt', 'r', encoding='utf-8') as f:
f.seek(11) # 跳过前11个字节(汉字占2字节)
part = f.read(8) # 读取后续8字符
print(part) # 输出:大到你无法
字符计算规则:
-
英文/数字:1字节/字符 -
中文:2字节/字符
☀️1.3.3 逐行读取
print("\n","="*20,"Python经典应用","="*20,"\n")
with open('message.txt','r') as file: # 打开保存Python经典应用信息的文件
number = 0 # 记录行号
while True:
number += 1
line = file.readline()
if line =='':
break # 跳出循环
print(number,line,end= "\n") # 输出一行内容
print("\n","="*20,"over","="*20,"\n")
输出示例: 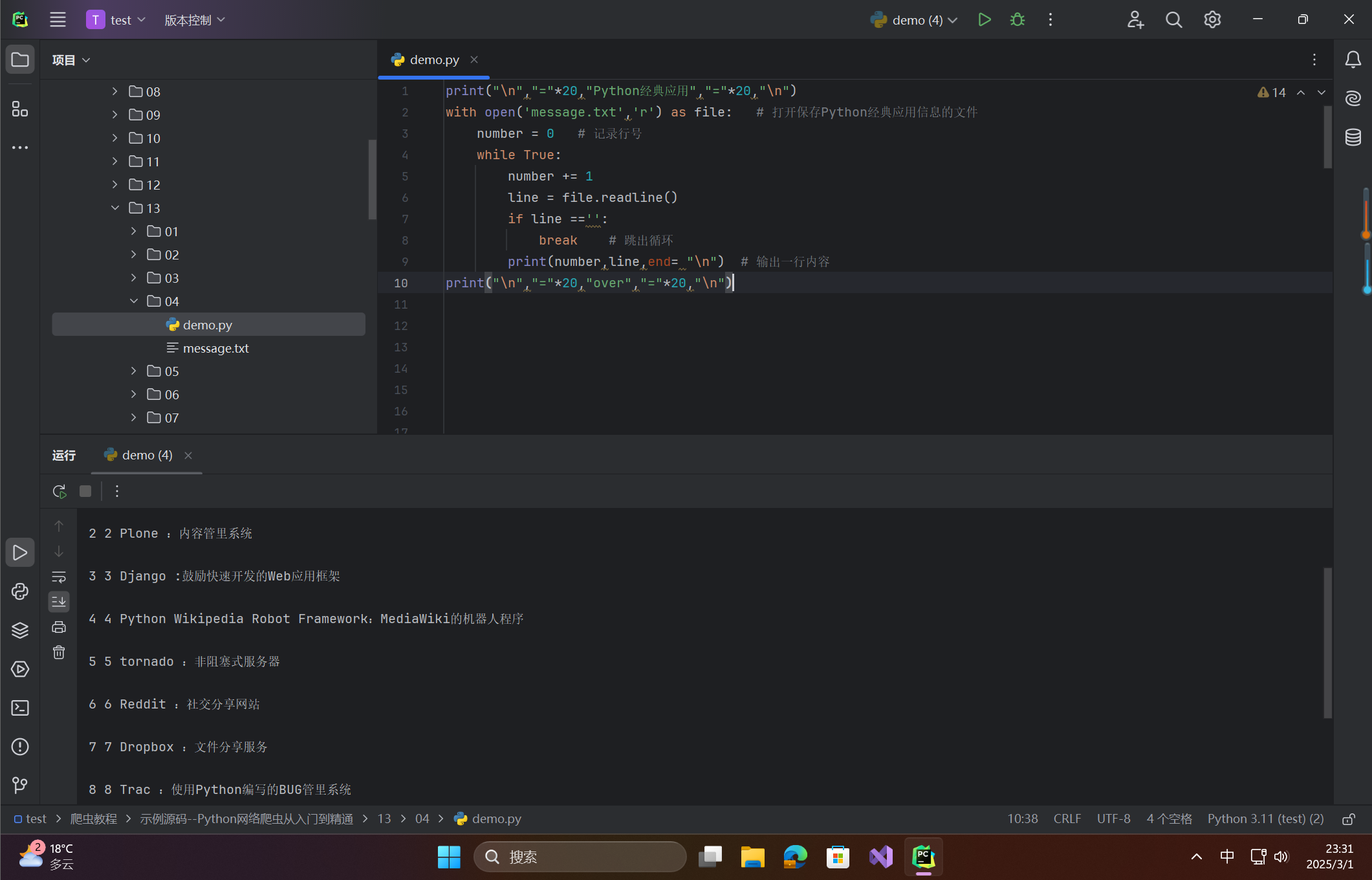
☀️1.3.4 批量读取所有行
print("\n","="*20,"Python经典应用","="*20,"\n")
with open('message.txt','r') as file: # 打开保存Python经典应用信息的文件
message = file.readlines() # 读取全部信息
print(message) # 输出信息
print("\n","="*25,"over","="*25,"\n")
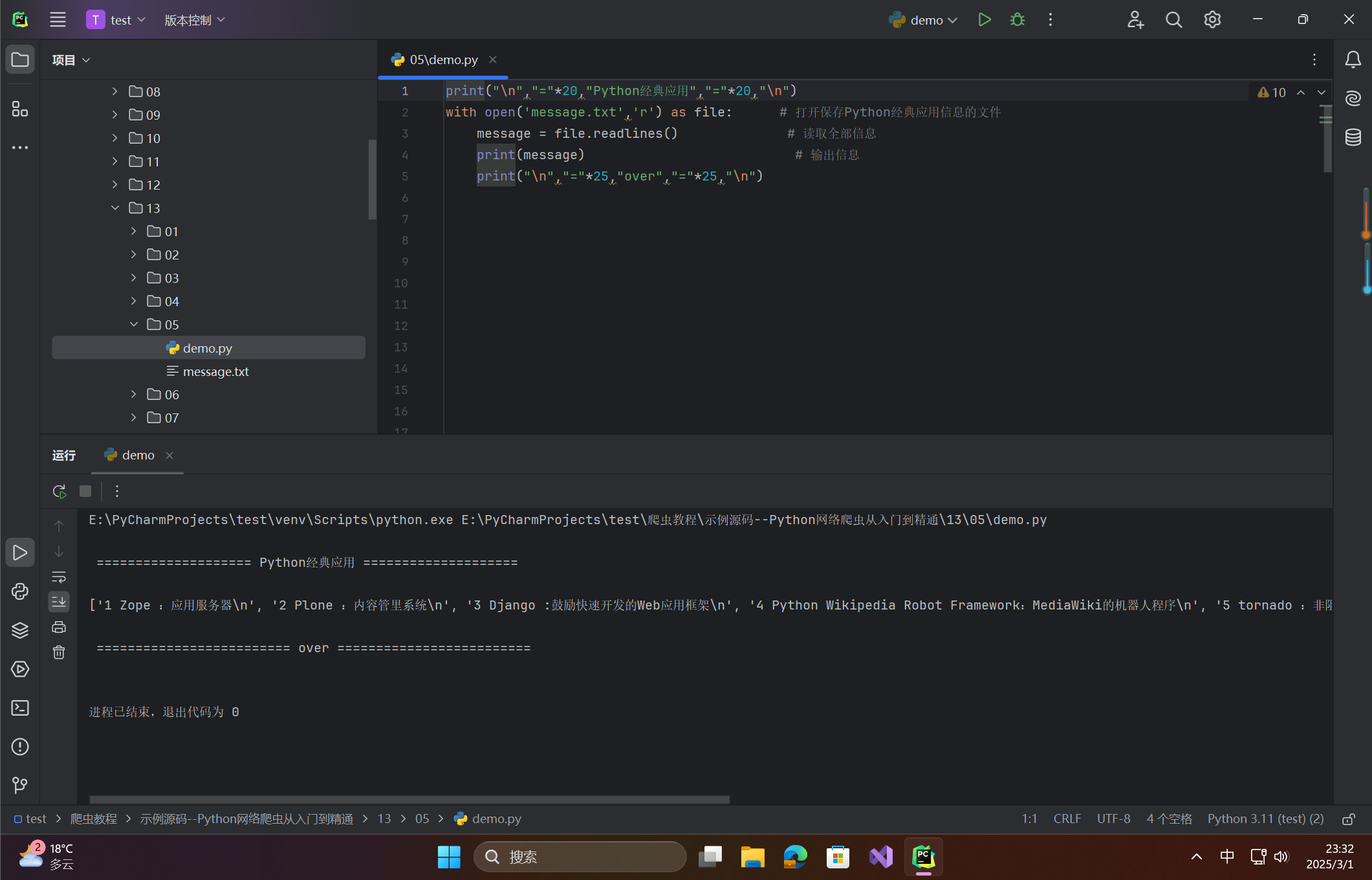 在这里插入图片描述
在这里插入图片描述
🦋1.4 关键注意事项
-
文件关闭必要性
使用with语句自动管理文件开关,避免资源泄漏 -
编码一致性原则
存储与读取使用相同编码(推荐UTF-8) -
大文件处理策略
# 分块读取(适合超大文件) chunk_size = 1024 with open('large_file.txt', 'r') as f: while chunk := f.read(chunk_size): process(chunk) -
异常处理机制
try: with open('data.txt', 'r') as f: content = f.read() except FileNotFoundError: print("文件不存在!") except UnicodeDecodeError: print("编码格式错误!")
🦋1.5 性能对比测试
| 方法 | 10MB文件 | 1GB文件 | 内存占用 |
|---|---|---|---|
read() |
0.02s | 2.1s | 高 |
readline() |
0.15s | 15.3s | 低 |
readlines() |
0.03s | 2.4s | 高 |
| 生成器逐行 | 0.18s | 18.2s | 极低 |
优化建议:大文件优先使用迭代器逐行处理
with open('big_data.txt') as f:
for line in f: # 内存友好的逐行读取
process(line)
🦋1.6 扩展应用:CSV交互
import csv
# TXT转CSV
with open('data.txt', 'r') as txt_file, open('data.csv', 'w') as csv_file:
writer = csv.writer(csv_file)
for line in txt_file:
writer.writerow([line.strip()])
🔎2.📊 Pandas数据存储指南:CSV与Excel文件操作详解
🦋2.1 CSV文件存储技术
☀️2.1.1 核心方法:DataFrame.to_csv()
df.to_csv(
path_or_buf=None, # 文件路径/缓冲区对象
sep=',', # 分隔符(默认逗号)
na_rep='', # 缺失值占位符
float_format=None, # 浮点数格式(如"%.2f")
columns=None, # 指定存储列
header=True, # 是否包含列名
index=True, # 是否保留行索引
mode='w', # 写入模式('w'覆盖/'a'追加)
encoding=None, # 文件编码(推荐'utf-8-sig')
line_terminator='\n'# 换行符
)
☀️2.1.2 参数速查表
| 参数 | 说明 | 示例值 |
|---|---|---|
path_or_buf |
文件路径或缓冲区对象 | 'data.csv' |
sep |
列分隔符 | '\t'(制表符) |
na_rep |
缺失值替代标记 | 'NULL' |
float_format |
浮点数格式控制 | "%.3f"(保留3位小数) |
columns |
指定存储列(列表形式) | ['A','C'] |
index |
是否保留行索引 | False(去除索引列) |
☀️2.1.3 实战示例
import pandas as pd
data = {'A': [1,2,3], 'B': [4,5,6], 'C': [7,8,9]}
df = pd.DataFrame(data)
# 基础存储
df.to_csv('basic.csv')
# 进阶设置(无索引/指定列/自定义分隔符)
df.to_csv('advance.csv',
index=False,
columns=['A','C'],
sep='|',
float_format="%.1f")
☀️2.1.4 文件输出对比
| 编辑器 | 无索引模式 | 默认模式 |
|---|---|---|
| PyCharm | `A | B |
| Excel | 三列完整显示 | 首列为自动生成的索引 |
🦋2.2 Excel文件存储技术
☀️2.2.1 核心方法:DataFrame.to_excel()
df.to_excel(
excel_writer, # 文件路径/ExcelWriter对象
sheet_name='Sheet1', # 工作表名称
na_rep='', # 缺失值占位符
float_format=None, # 浮点数格式化
columns=None, # 指定存储列
header=True, # 保留列名
index=True, # 保留行索引
startrow=0, # 起始行(从0开始)
startcol=0, # 起始列(从0开始)
engine=None # 写入引擎('openpyxl'/'xlsxwriter')
)
☀️2.2.2 参数速查表
| 参数 | 说明 | 示例值 |
|---|---|---|
sheet_name |
目标工作表名称 | '销售数据' |
startrow |
数据起始行(跳过标题行可用1) | 2 |
startcol |
数据起始列 | 1(B列开始) |
engine |
指定写入引擎 | 'openpyxl'(.xlsx) |
☀️2.2.3 实战示例
import pandas as pd
data = {
'编号': ['mr001','mr002','mr003','mr004'],
'体育': [34.5,33,35,39],
'语文': [110,110,105,108],
'数学': [108,110,105,101],
'英语': [99,110,101,112]
}
df = pd.DataFrame(data)
# 基础存储
df.to_excel('basic.xlsx')
# 进阶设置(指定位置/去除索引)
df.to_excel('advance.xlsx',
sheet_name='成绩表',
index=False,
startrow=1,
startcol=1)
☀️2.2.4 Excel文件输出效果
| 设置项 | 文件显示效果 |
|---|---|
| 默认参数 | 包含索引列,数据从A1单元格开始 |
| index=False | 无索引列,数据列紧凑排列 |
| startrow=1 | 数据从第2行开始(可预留标题行) |
🦋2.3 格式控制技巧
☀️2.3.1 浮点数精度控制
# CSV保留两位小数
df.to_csv('data.csv', float_format="%.2f")
# Excel科学计数法显示
df.to_excel('data.xlsx', float_format="%.2E")
☀️2.3.2 中文编码处理
# CSV文件解决中文乱码
df.to_csv('中文数据.csv', encoding='utf-8-sig')
# Excel文件指定编码
with pd.ExcelWriter('中文数据.xlsx', engine='openpyxl') as writer:
df.to_excel(writer, encoding='utf-8')
☀️2.3.3 多工作表操作
with pd.ExcelWriter('multi_sheet.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet1')
df2.to_excel(writer, sheet_name='Sheet2')
🦋2.4 常见问题解决方案
| 问题现象 | 原因分析 | 解决方案 |
|---|---|---|
| CSV打开中文乱码 | 编码格式不兼容 | 使用encoding='utf-8-sig' |
| Excel无法保存.xlsx | 缺少写入引擎 | pip install openpyxl |
| 丢失小数点后精度 | 未指定浮点格式 | 设置float_format="%.4f" |
| 追加数据覆盖原内容 | 模式设置为'w'(默认覆盖) | 使用mode='a'(需配合engine) |
🦋2.5 格式对比与选择建议
| 格式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| CSV | 跨平台/体积小/易读 | 无格式控制/不支持多工作表 | 数据交换/简单分析 |
| Excel | 支持复杂格式/多工作表 | 文件较大/依赖特定软件打开 | 商业报表/可视化展示 |

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)