【愚公系列】《Python网络爬虫从入门到精通》036-DataFrame日期数据处理

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据分析和处理的过程中,日期数据往往扮演着至关重要的角色。无论是时间序列分析、数据可视化,还是机器学习模型的构建,正确处理日期数据都是确保分析结果准确性的基础。在Python的Pandas库中,DataFrame提供了强大的工具和方法,使得日期数据的处理变得高效而便捷。
本篇文章将深入探讨如何在DataFrame中处理日期数据,包括日期的解析、格式化、时间戳的转换、日期范围的生成以及缺失数据的处理等关键技巧。我们将通过实例演示每个操作的具体应用,帮助你深入理解如何利用Pandas轻松应对各种日期处理需求。
🚀一、DataFrame日期数据处理
🔎1.📅 Pandas日期数据处理:to_datetime方法详解
🦋1.1 日期格式统一的重要性
-
常见问题:同一日期存在多种表达格式 -
解决方案: pandas.to_datetime()方法可实现批量日期格式转换
常见日期格式示例
 在这里插入图片描述
在这里插入图片描述
🦋1.2 to_datetime核心功能
方法语法
pandas.to_datetime(
arg,
errors='ignore',
dayfirst=False,
yearfirst=False,
utc=None,
box=True,
format=None,
exact=True,
unit=None,
infer_datetime_format=False,
origin='unix',
cache=False
)
参数详解
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
arg |
多种 | - | 输入数据(字符串、数组、Series) |
errors |
str | 'ignore' | 错误处理策略: - ignore:保留原值- raise:抛出异常- coerce:转为NaT |
dayfirst |
bool | False | 优先解析日为第一位(如20/01/2020→2020-01-20) |
yearfirst |
bool | False | 优先解析年为第一位(如10/11/12→2010-11-12) |
format |
str | None | 自定义格式字符串(如%Y-%m-%d) |
unit |
str | None | 时间单位(D/s/ms/us/ns),用于解析时间戳 |
infer_datetime_format |
bool | False | 自动推断日期格式 |
🦋1.3 典型应用场景
☀️1.3.1 场景1:单列格式转换
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.DataFrame({'原日期':['14-Feb-20', '02/14/2020', '2020.02.14', '2020/02/14','20200214']})
df['转换后的日期']=pd.to_datetime(df['原日期'])
print(df)
输出结果:
☀️1.3.2 多列组合日期
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df = pd.DataFrame({'year': [2018, 2019,2020],
'month': [1, 3,2],
'day': [4, 5,14],
'hour':[13,8,2],
'minute':[23,12,14],
'second':[2,4,0]})
df['组合后的日期']=pd.to_datetime(df)
print(df)
输出结果:
🦋1.4 高级使用技巧
☀️1.4.1 处理异常数据
# 包含非法日期的数据转换
mixed_dates = ['2023-02-30', 'invalid_date', '2023-12-01']
pd.to_datetime(mixed_dates, errors='coerce') # 输出:[NaT, NaT, 2023-12-01]
☀️1.4.2 自定义格式解析
# 解析非标准格式日期
custom_format = "%d-%b-%y"
pd.to_datetime("14-Feb-20", format=custom_format) # 输出:2020-02-14
☀️1.4.3 时间戳转换
# 处理Unix时间戳(单位:秒)
pd.to_datetime(1612345678, unit='s') # 输出:2021-02-03 04:07:58
🦋1.5 注意事项
-
格式冲突处理:当 dayfirst和yearfirst同时为True时,yearfirst优先级更高 -
性能优化:对重复日期数据设置 cache=True可提升处理速度 -
时区处理:通过 utc=True参数可转换为UTC时间 -
格式推断限制: infer_datetime_format仅适用于简单格式
🦋1.5 完整参数说明表
| 参数 | 详细说明 |
|---|---|
box |
True返回DatetimeIndex,False返回numpy数组 |
origin |
定义参考日期(默认从1970-01-01计算) |
exact |
True要求格式完全匹配,False允许部分匹配 |
建议结合官方文档实践:https://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html
🔎2.📅 Pandas dt对象深度解析
🦋2.1 dt对象核心功能
dt对象是Pandas针对日期型Series设计的属性访问器,可快速提取日期元素与特征信息。使用时需确保Series已转换为datetime类型。
# 基础转换方法
df['日期列'] = pd.to_datetime(df['日期列'])
🦋2.2 常用属性方法速查表
| 分类 | 属性/方法 | 返回值说明 | 示例输出 |
|---|---|---|---|
| 基础元素 | .year |
年份(4位整数) | 2023 |
.month |
月份(1-12) | 12 | |
.day |
日期(1-31) | 25 | |
| 时间特征 | .day_name() |
星期全称(英文) | Monday |
.dayofweek |
星期序号(0=周一,6=周日) | 0 | |
.quarter |
季度(1-4) | 4 | |
| 日期判断 | .is_year_end |
是否年末最后一天(布尔值) | True/False |
.is_leap_year |
是否闰年(布尔值) | True/False | |
| 高级特性 | .hour/.minute/.second |
时分秒(24小时制) | 15/30/45 |
.dayofyear |
年累计天数(1-366) | 359 | |
.weekofyear |
ISO标准周数(1-53) | 52 |
🦋2.3 典型应用场景
☀️2.3.1 场景1:基础日期元素提取
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.DataFrame({'原日期':['2019.1.05', '2019.2.15', '2019.3.25','2019.6.25','2019.9.15','2019.12.31']})
df['日期']=pd.to_datetime(df['原日期'])
print(df)
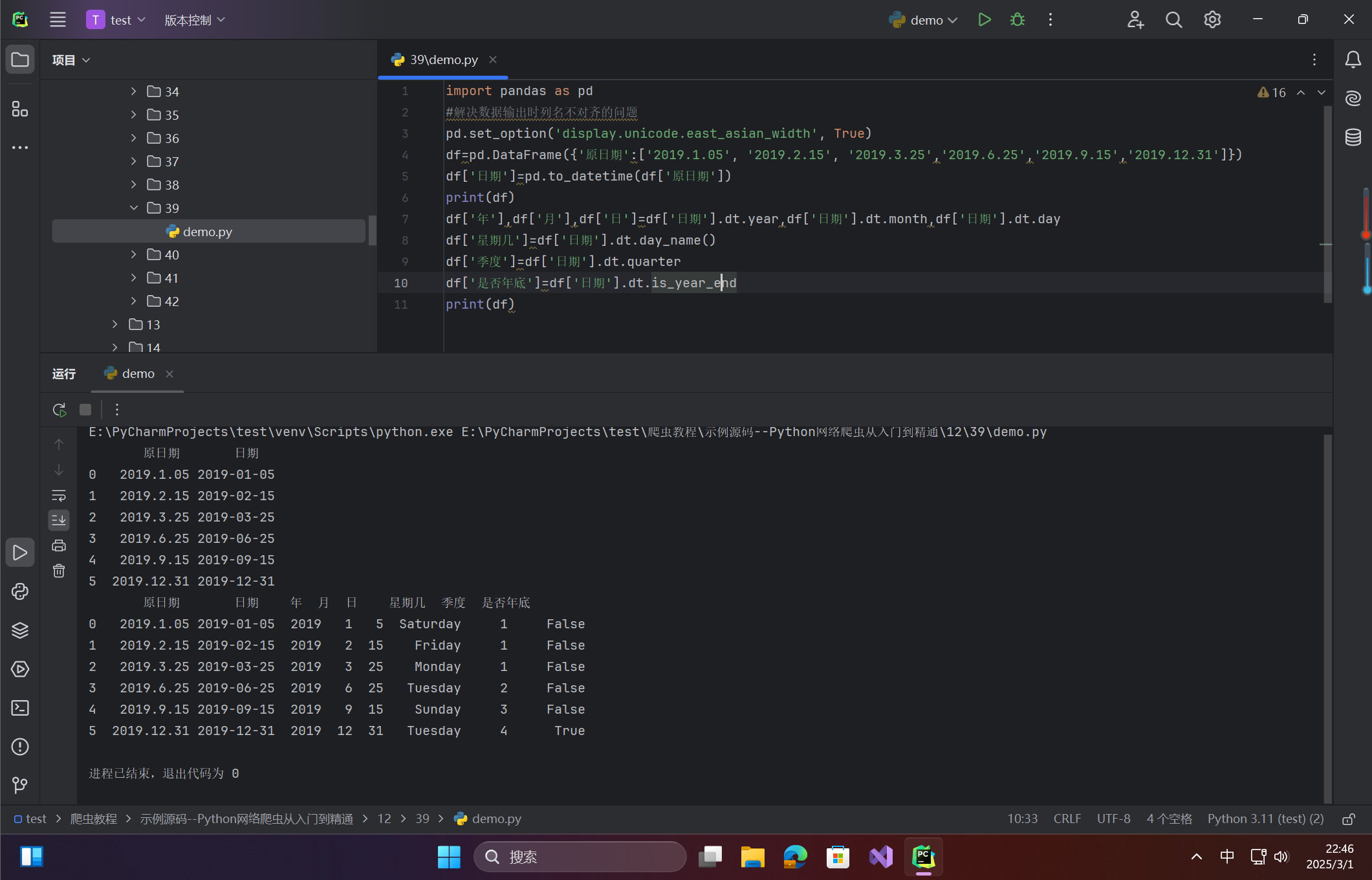
☀️2.3.2 场景2:高级日期特征生成
df['年'],df['月'],df['日']=df['日期'].dt.year,df['日期'].dt.month,df['日期'].dt.day
df['星期几']=df['日期'].dt.day_name()
df['季度']=df['日期'].dt.quarter
df['是否年底']=df['日期'].dt.is_year_end
print(df)
☀️2.3.3 输出结果示例
 在这里插入图片描述
在这里插入图片描述
🦋2.4 高级应用技巧
☀️2.4.1 多条件日期筛选
# 筛选Q4且为工作日的记录
df_q4_weekdays = df[
(df['日期'].dt.quarter == 4) &
(df['日期'].dt.dayofweek < 5)
]
☀️2.4.2 自定义日期特征
# 生成年月标识(YYYY-MM)
df['年月'] = df['日期'].dt.strftime('%Y-%m')
# 计算半年度标识
df['半年度'] = df['日期'].dt.month.apply(lambda x: 'H1' if x <=6 else 'H2')
☀️2.4.3 时间序列分析
# 计算星期平均数据
weekly_avg = df.groupby(df['日期'].dt.day_name())['销售额'].mean()
🦋2.5 注意事项
-
类型验证:操作前需确认Series已转换为 datetime64类型assert pd.api.types.is_datetime64_any_dtype(df['日期']) -
空值处理:日期列存在NaT时会返回NaN,建议先处理缺失值 -
时区意识:若数据包含时区信息,需用 tz_convert统一时区 -
性能优化:避免在循环中频繁调用dt属性,建议向量化操作
🦋2.6 完整方法清单
| 方法 | 说明 |
|---|---|
.normalize() |
去除时间部分(保留日期) |
.ceil(freq) |
向上取整到指定频率(如'H') |
.floor(freq) |
向下取整到指定频率 |
.strftime(format) |
自定义格式化输出 |
.to_period(freq) |
转换为周期对象(如季度周期) |
🔎3.📅 Pandas日期区间数据筛选指南
🦋3.1 核心方法
通过将日期列设为索引,实现快速日期区间筛选。关键步骤:
-
日期列标准化处理 -
设置日期索引 -
使用字符串切片操作
🦋3.2 操作流程
☀️3.2.1 步骤1:数据预处理
import pandas as pd
# 读取数据并提取关键列
df = pd.read_excel('mingribooks.xls')
df1 = df[['订单付款时间', '买家会员名', '联系手机', '买家实际支付金额']]
# 日期列标准化
df1['订单付款时间'] = pd.to_datetime(df1['订单付款时间'])
df1 = df1.sort_values(by='订单付款时间') # 按时间排序
☀️3.2.2 设置日期索引
df1 = df1.set_index('订单付款时间') # 关键操作!
🦋3.3 筛选方式对比
| 筛选需求 | 语法示例 | 说明 |
|---|---|---|
| 整年数据 | df1['2018'] |
获取2018全年数据 |
| 跨年度区间 | df1['2017':'2018'] |
包含2017-2018两年数据 |
| 单月数据 | df1['2018-07'] |
获取2018年7月所有记录 |
| 精确日筛选 | df1['2018-05-06'] |
获取单日数据 |
| 自定义区间 | df1['2018-05-11':'2018-06-10'] |
左闭右闭区间 |
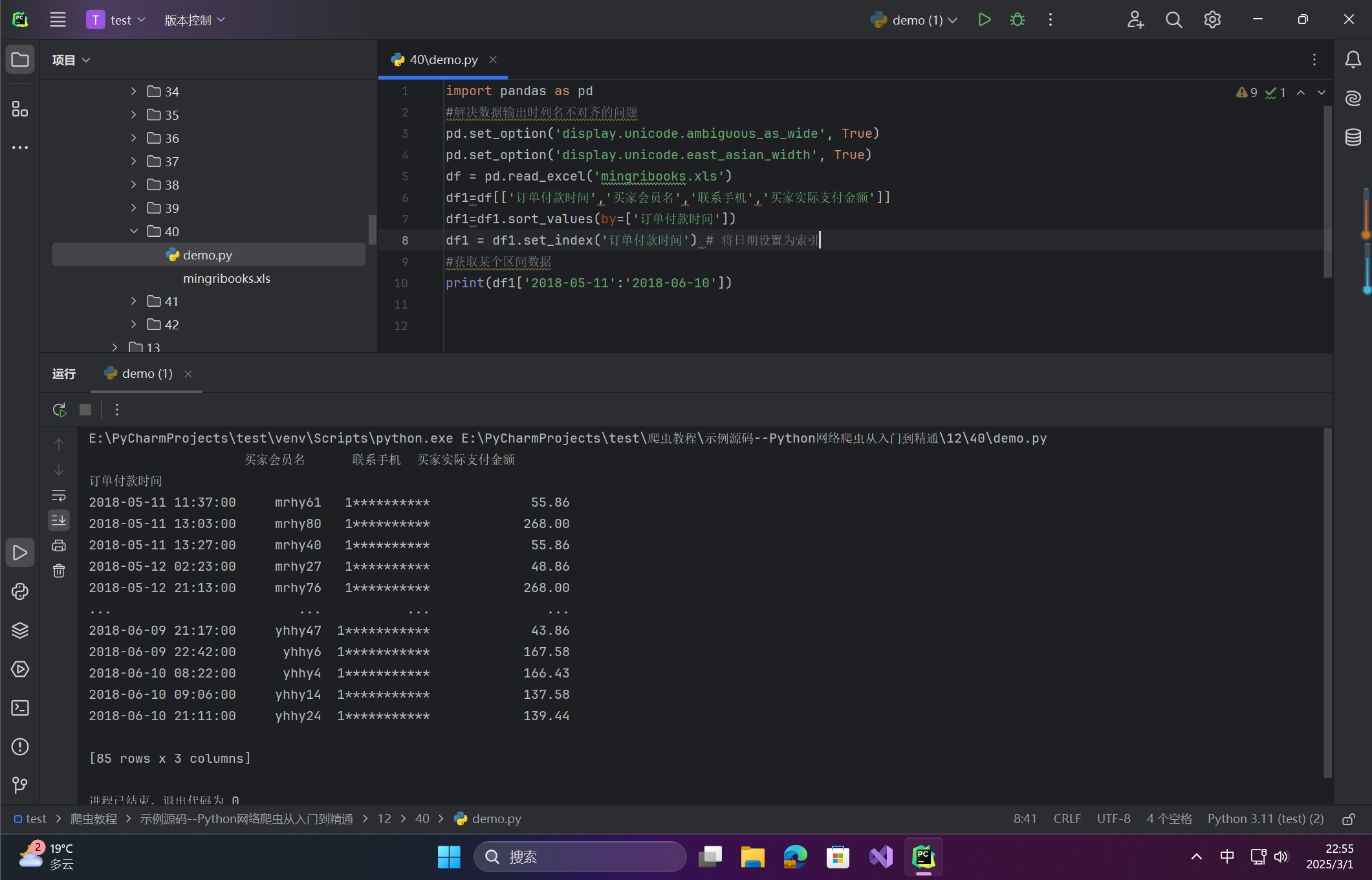
🦋3.4 实战案例演示
案例:获取2018-05-11至2018-06-10订单数据
# 执行筛选
filtered_data = df1['2018-05-11':'2018-06-10']
# 展示结果(示例)
print(filtered_data.head(3))
输出结果示例
| 订单付款时间 | 买家会员名 | 联系手机 | 买家实际支付金额 |
|---|---|---|---|
| 2018-05-11 11:37:00 | mrhy61 | * | 55.86 |
| 2018-05-11 13:03:00 | mrhy801 | * | 268.00 |
| 2018-05-11 13:27:00 | mrhy40 | * | 55.86 |
🦋3.5 注意事项
-
索引必须为日期类型
# 验证索引类型 print(df1.index.dtype) # 应显示datetime64[ns] -
时间范围包含端点
-
df1['start':'end']包含起始和结束日期 -
精确到日时包含该日所有时间点数据
-
-
性能优化建议
# 对已排序索引加速查询 df1 = df1.sort_index().loc['2018-05-11':'2018-06-10'] -
异常处理
try: df1['invalid_date'] except KeyError: print("日期格式错误或超出数据范围")
🦋3.6 高级扩展
☀️3.6.1 时间精度控制
# 按小时筛选
df1['2018-05-11 08':'2018-05-11 12']
☀️3.6.2 复合条件筛选
# 组合金额条件
filtered_data[(filtered_data['买家实际支付金额'] > 100)]
☀️3.6.3 频率重采样
# 按周统计销售额
weekly_sales = df1.resample('W')['买家实际支付金额'].sum()
🦋3.7 完整代码参考
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel('mingribooks.xls')
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1=df1.sort_values(by=['订单付款时间'])
df1 = df1.set_index('订单付款时间') # 将日期设置为索引
#获取某个区间数据
print(df1['2018-05-11':'2018-06-10'])
 在这里插入图片描述
在这里插入图片描述
🔎4.📊 Pandas时间序列统计与展示全攻略
🦋4.1 核心方法对比
| 方法 | 作用 | 适用场景 | 关键参数 |
|---|---|---|---|
.resample() |
按频率重新采样数据 | 统计聚合(求和/均值等) | rule(频率) |
.to_period() |
将时间戳转换为时期对象 | 按周期显示数据 | freq(频率) |
🦋4.2 数据预处理关键步骤
☀️4.2.1 日期索引设置
import pandas as pd
# 读取数据并设置日期索引
df = pd.read_excel('TB2018.xls', usecols=['订单付款时间','买家实际支付金额'])
df = df.set_index(pd.to_datetime(df['订单付款时间'])) # 确保日期为索引
☀️4.2.2 验证索引类型
assert isinstance(df.index, pd.DatetimeIndex), "索引必须为日期类型!"
🦋4.3 频率规则速查表
| 频率代码 | 说明 | 示例 |
|---|---|---|
AS |
按年统计(年初对齐) | 2018-01-01 |
QS |
按季统计(季初对齐) | 2018-01-01(Q1) |
MS |
按月统计(月初对齐) | 2018-01-01 |
W |
按周统计(周日对齐) | 每周日作为周期终点 |
D |
按天统计 | 每日数据 |
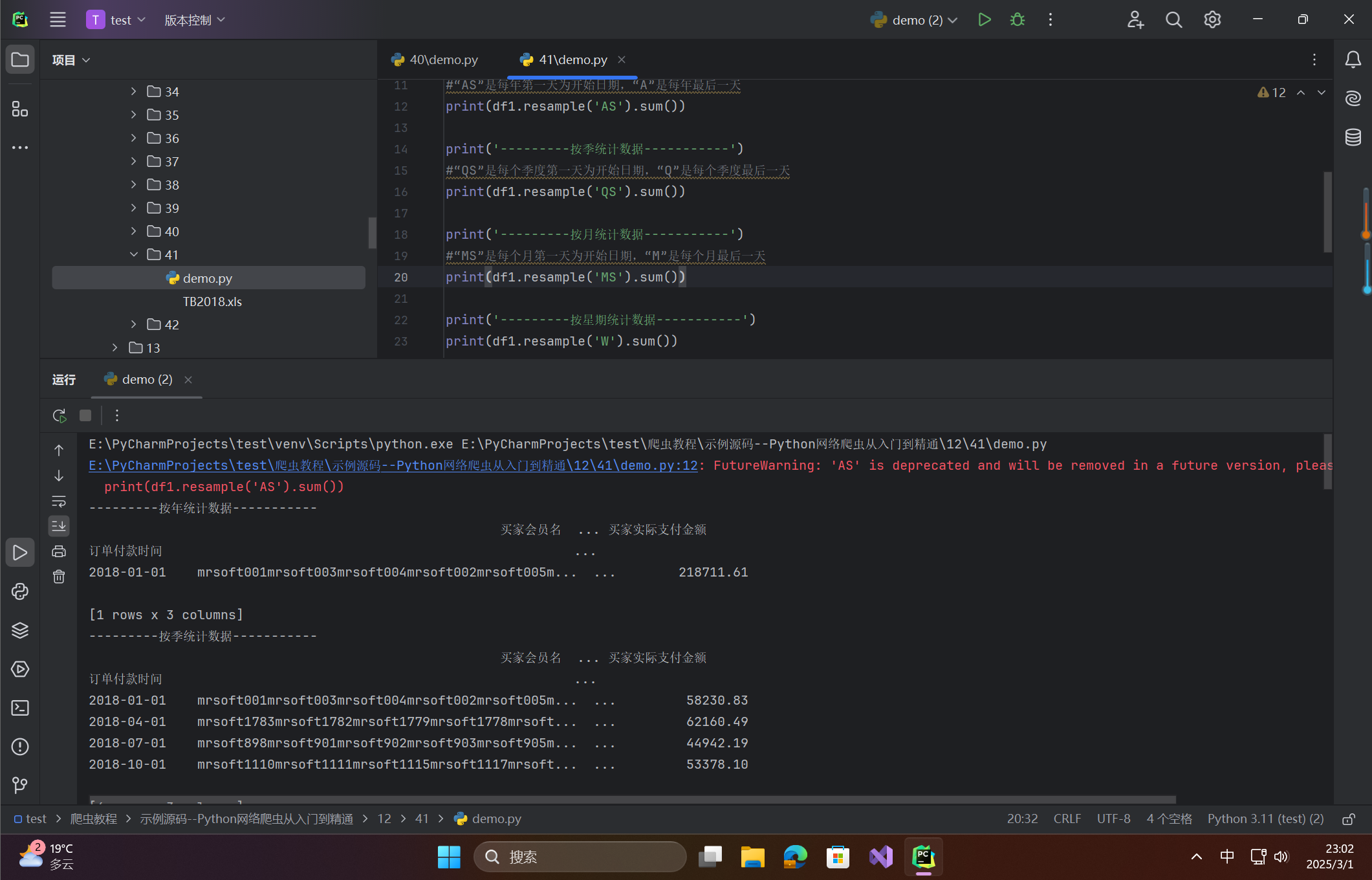
🦋4.4 完整代码参考
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
aa =r'TB2018.xls'
df = pd.DataFrame(pd.read_excel(aa))
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1 = df1.set_index('订单付款时间') # 将date设置为index
print('---------按年统计数据-----------')
#“AS”是每年第一天为开始日期,“A”是每年最后一天
print(df1.resample('AS').sum())
print('---------按季统计数据-----------')
#“QS”是每个季度第一天为开始日期,“Q”是每个季度最后一天
print(df1.resample('QS').sum())
print('---------按月统计数据-----------')
#“MS”是每个月第一天为开始日期,“M”是每个月最后一天
print(df1.resample('MS').sum())
print('---------按星期统计数据-----------')
print(df1.resample('W').sum())
print('---------按天统计数据-----------')
print(df1.resample('D').sum())
 在这里插入图片描述
在这里插入图片描述
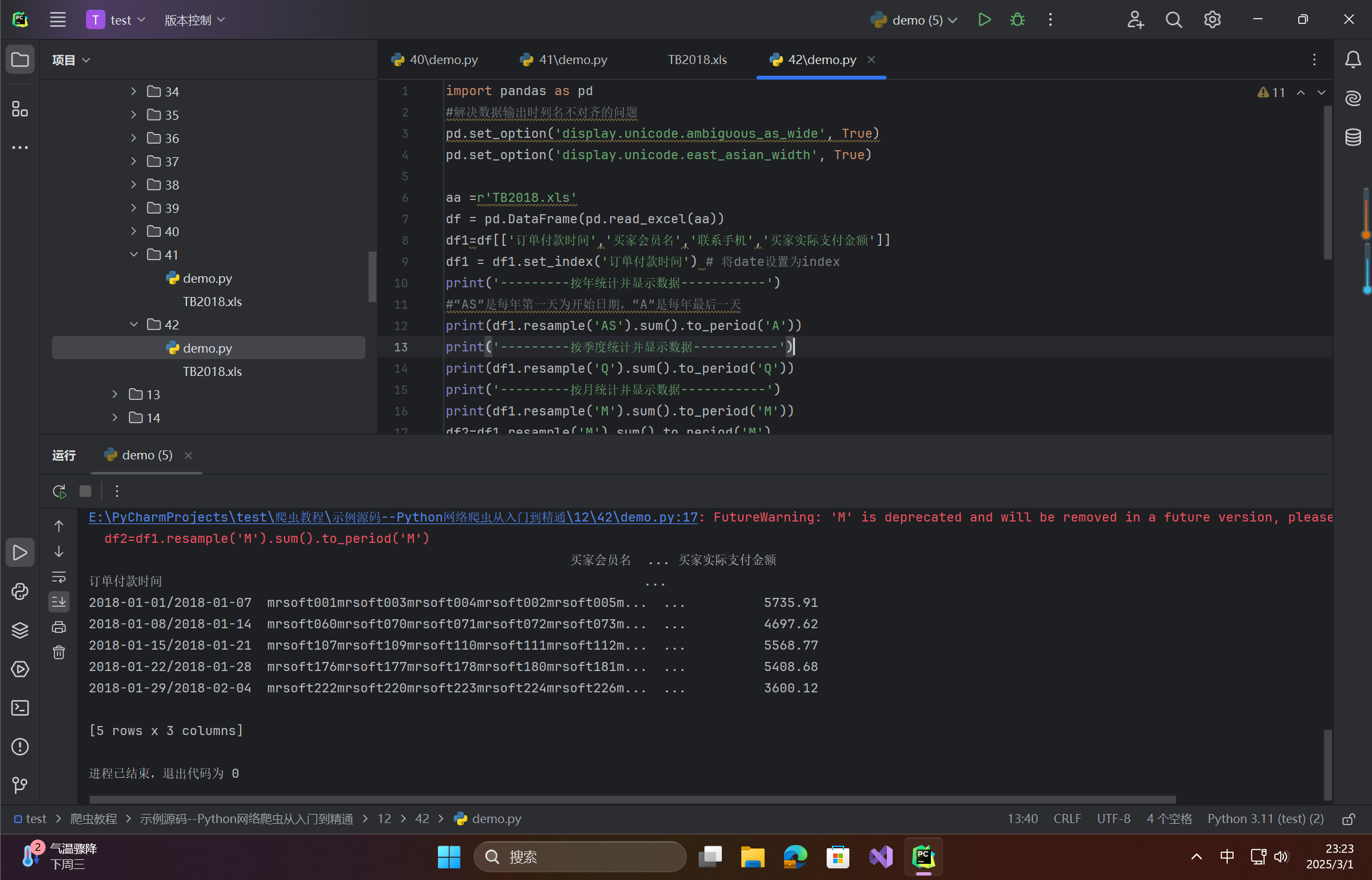
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
aa =r'TB2018.xls'
df = pd.DataFrame(pd.read_excel(aa))
df1=df[['订单付款时间','买家会员名','联系手机','买家实际支付金额']]
df1 = df1.set_index('订单付款时间') # 将date设置为index
print('---------按年统计并显示数据-----------')
#“AS”是每年第一天为开始日期,“A”是每年最后一天
print(df1.resample('AS').sum().to_period('A'))
print('---------按季度统计并显示数据-----------')
print(df1.resample('Q').sum().to_period('Q'))
print('---------按月统计并显示数据-----------')
print(df1.resample('M').sum().to_period('M'))
df2=df1.resample('M').sum().to_period('M')
print('---------按星期统计并显示数据-----------')
print(df1.resample('W').sum().to_period('W').head())
 在这里插入图片描述
在这里插入图片描述
🦋4.5 注意事项
-
日期范围完整性:确保数据覆盖完整周期,缺失日期可能产生空值 -
时区处理:使用 tz_localize统一时区后再进行统计 -
性能优化:大数据集建议先 sort_index()提升处理效率 -
频率兼容性: to_period()的freq参数必须与resample规则匹配

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)