【愚公系列】《Python网络爬虫从入门到精通》035-DataFrame数据分组统计整理

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据分析过程中,数据的分组统计是揭示数据内在规律的重要方法。无论是对销售数据进行汇总,还是分析用户行为,合理的分组统计可以帮助我们更清晰地理解数据背后的趋势和模式。Pandas库中的DataFrame为我们提供了强大的工具,使得分组统计变得简单而高效。
本文将深入探讨如何在DataFrame中进行数据分组和统计整理。我们将介绍如何使用Pandas的groupby功能,进行多种汇总操作,包括计数、求和、平均值等。同时,我们还会展示如何处理复杂数据场景,比如多重分组和自定义聚合函数。通过具体的示例和实用技巧,帮助你掌握数据分组的核心思路,提高数据分析的准确性和效率。
🚀一、DataFrame数据分组统计整理
🔎1.groupby 方法概述
DataFrame.groupby() 是 Pandas 中用于数据分组统计的核心方法,支持灵活的分组规则和聚合操作,功能类似 SQL 的 GROUP BY。语法如下:
DataFrame.groupby(
by=None,
axis=0,
level=None,
as_index=True,
sort=True,
group_keys=True,
squeeze=False,
observed=False
)
🔎2.参数详解
| 参数 | 说明 |
|---|---|
by |
分组依据:列名、列名列表、字典、Series 或函数 |
axis |
分组方向:0 按列分组(默认),1 按行分组 |
level |
多层索引时指定层级(默认 None) |
as_index |
是否以分组键为索引:True(默认),False 返回普通索引 |
sort |
是否对分组结果排序:True(默认),False 保留原始顺序 |
group_keys |
是否保留分组键:True(默认),False 隐藏分组键 |
observed |
分类数据分组时,是否仅显示观测值:False(默认显示所有值) |
🔎3.分组统计场景与实例
🦋3.1 单列分组统计
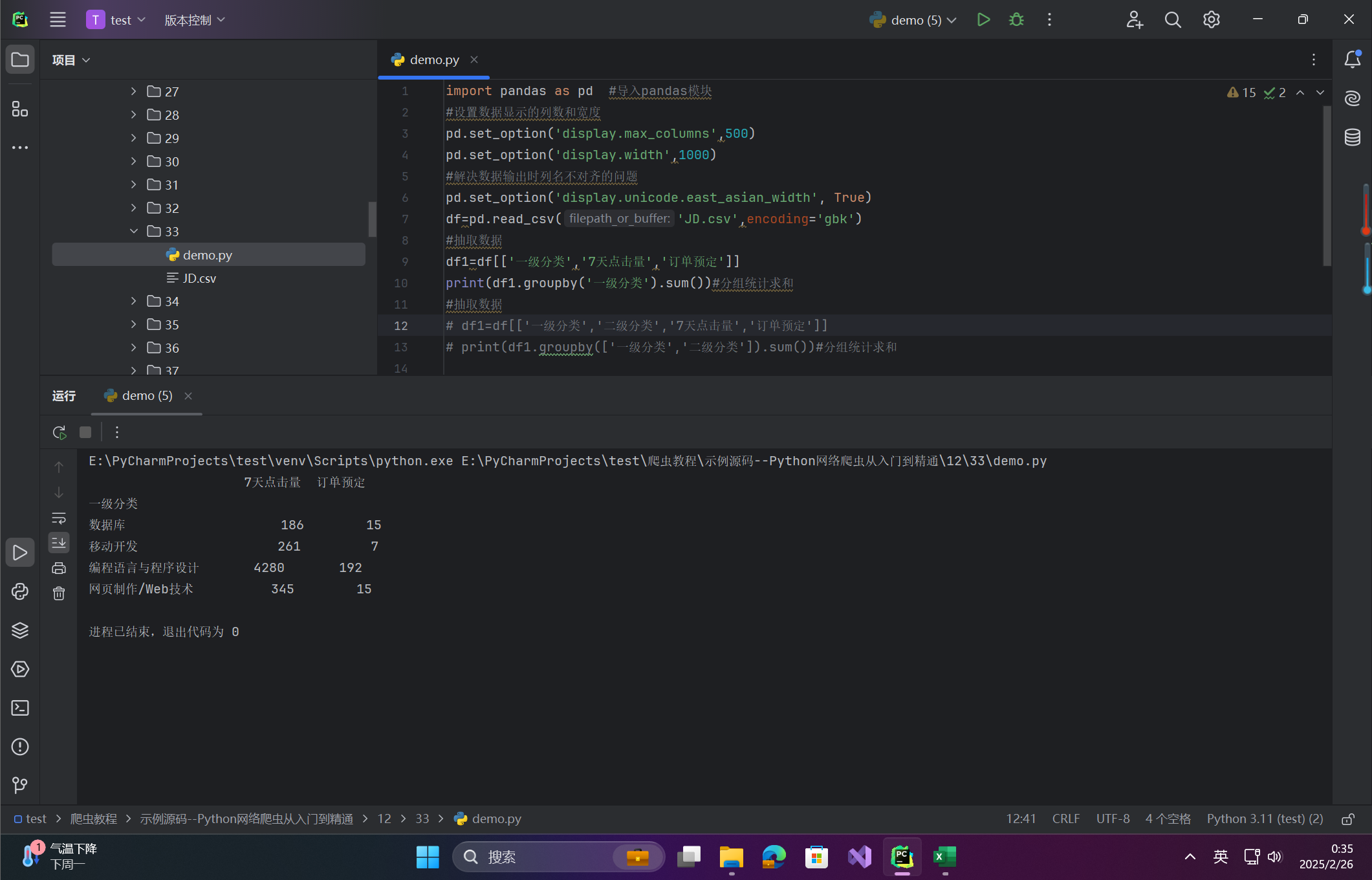
场景:按“一级分类”分组统计销量总和
代码:
import pandas as pd #导入pandas模块
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
print(df1.groupby('一级分类').sum())#分组统计求和
#抽取数据
# df1=df[['一级分类','二级分类','7天点击量','订单预定']]
# print(df1.groupby(['一级分类','二级分类']).sum())#分组统计求和
#抽取数据
# df1=df[['一级分类','二级分类','7天点击量','订单预定']]
# print(df1.groupby('二级分类')['7天点击量'].sum())
输出说明:
-
图:按“一级分类”分组统计的总点击量和订单数。
 在这里插入图片描述
在这里插入图片描述
🦋3.2 多列分组统计
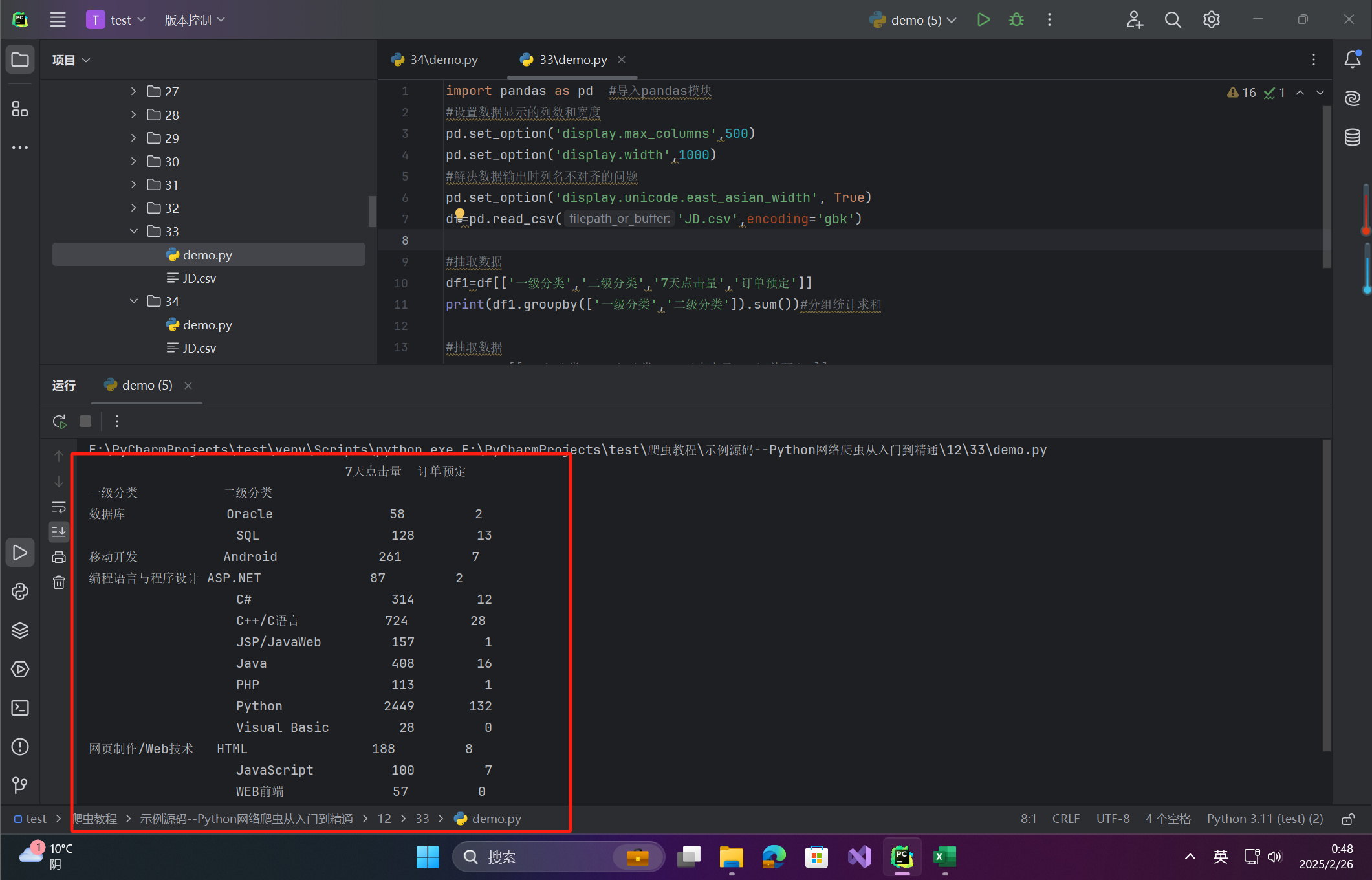
场景:按“一级分类”和“二级分类”分组统计
代码:
# 抽取数据并多列分组求和
df1 = df[['一级分类', '二级分类', '7天点击量', '订单预定']]
result = df1.groupby(['一级分类', '二级分类']).sum()
print(result)
输出说明:
-
图:展示多级分组后的汇总数据。
 在这里插入图片描述
在这里插入图片描述
🦋3.3 分组后指定列计算
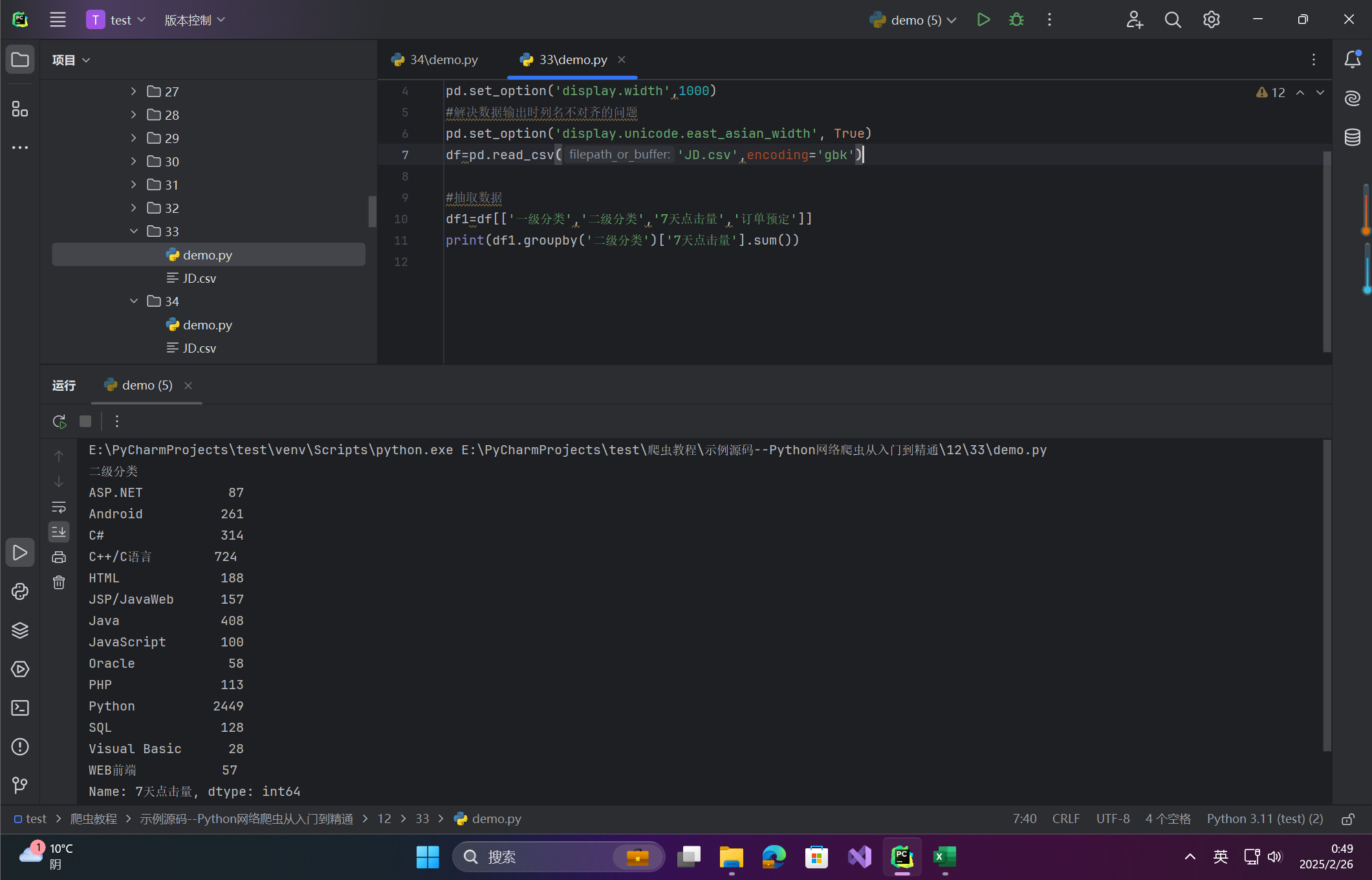
场景:按“二级分类”分组后,仅统计“7天点击量”总和
代码:
# 分组后指定列求和
result = df1.groupby('二级分类')['7天点击量'].sum()
print(result)
输出说明:
-
图:仅显示“二级分类”对应的总点击量。
 在这里插入图片描述
在这里插入图片描述
🔎4.分组数据迭代
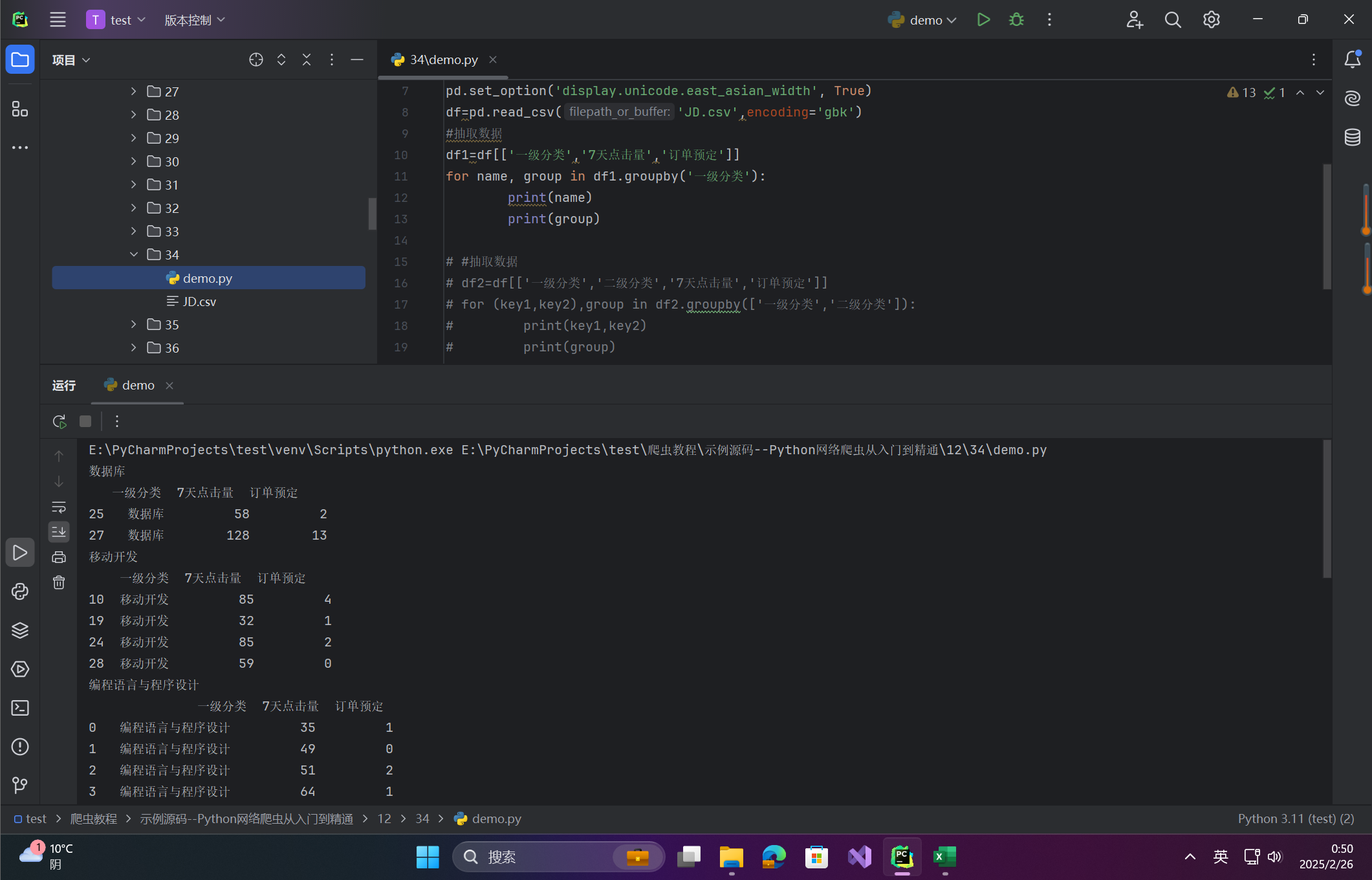
场景:遍历分组数据,逐组分析
代码:
import pandas as pd #导入pandas模块
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
# 按“一级分类”分组迭代
for name, group in df1.groupby('一级分类'):
print(f"分类名称: {name}")
print(group)
# 按多列分组迭代
df2 = df[['一级分类', '二级分类', '7天点击量', '订单预定']]
for (key1, key2), group in df2.groupby(['一级分类', '二级分类']):
print(f"一级分类: {key1}, 二级分类: {key2}")
print(group)
输出说明:
-
图:展示逐组输出的详细数据。
 在这里插入图片描述
在这里插入图片描述
🔎5.通过字典/Series分组统计
🦋5.1 字典分组
场景:将城市销量合并为区域统计(如“北上广”)
代码:
import pandas as pd #导入pandas模块
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
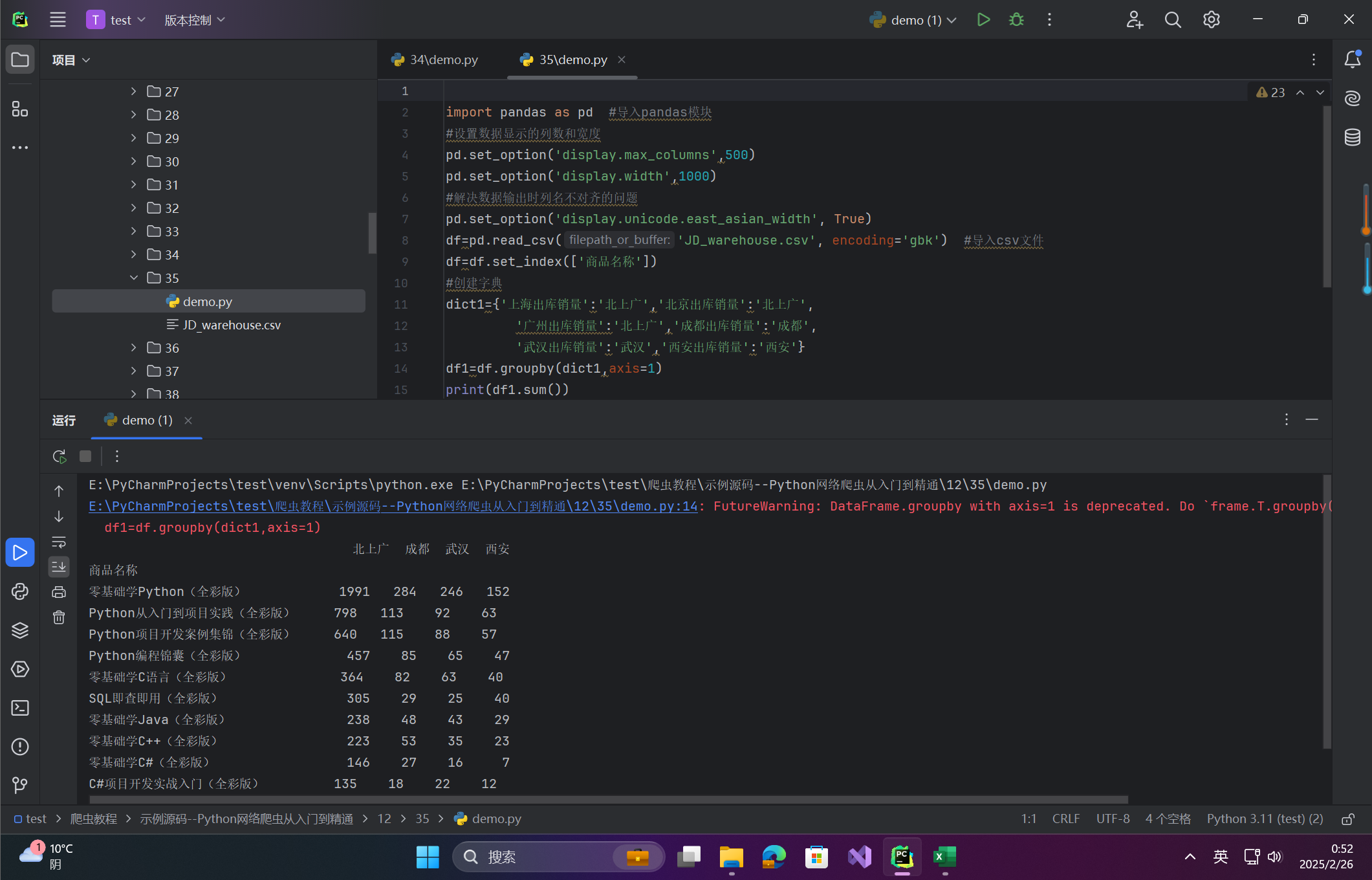
df=pd.read_csv('JD_warehouse.csv', encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
#创建字典
dict1={'上海出库销量':'北上广','北京出库销量':'北上广',
'广州出库销量':'北上广','成都出库销量':'成都',
'武汉出库销量':'武汉','西安出库销量':'西安'}
df1=df.groupby(dict1,axis=1)
print(df1.sum())
输出说明:
-
图:按区域合并后的销量统计。
 在这里插入图片描述
在这里插入图片描述
🦋5.2 Series分组
场景:通过Series对象动态映射分组
代码:
import pandas as pd #导入pandas模块
#设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
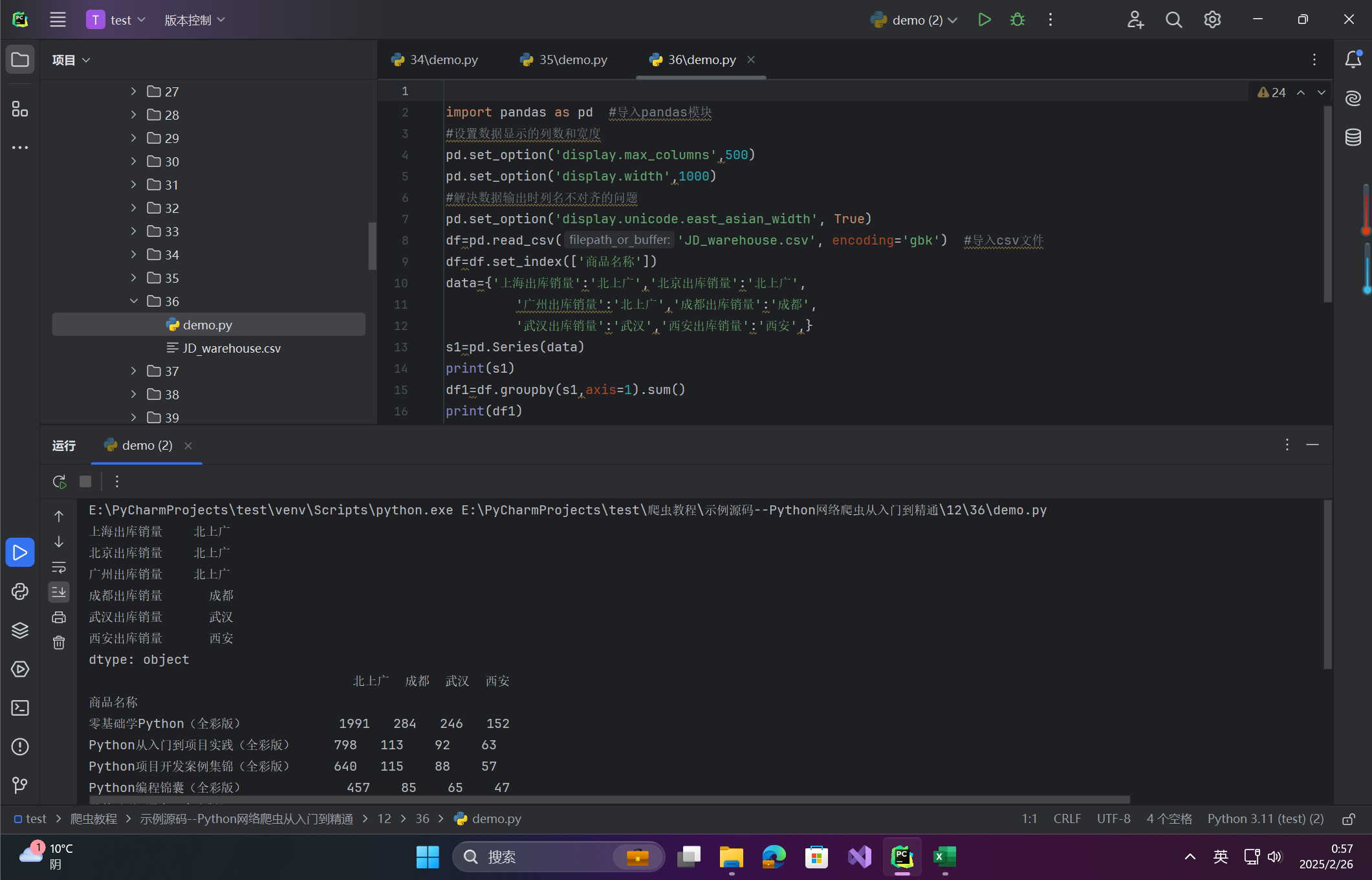
df=pd.read_csv('JD_warehouse.csv', encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
data={'上海出库销量':'北上广','北京出库销量':'北上广',
'广州出库销量':'北上广','成都出库销量':'成都',
'武汉出库销量':'武汉','西安出库销量':'西安',}
s1=pd.Series(data)
print(s1)
df1=df.groupby(s1,axis=1).sum()
print(df1)
输出说明:
-
图:展示通过Series分组后的汇总结果。
 在这里插入图片描述
在这里插入图片描述
🔎6.注意事项
-
分组键类型: -
by参数支持列名、函数、字典或Series,需确保映射关系正确。
-
-
缺失值处理: -
默认忽略缺失值( NaN),可通过dropna=False保留。
-
-
性能优化: -
大数据量时设置 sort=False可提升分组速度。
-
-
多层索引: -
使用 level参数处理多层索引数据的分组。
-
🔎7.附:常见聚合函数
| 函数 | 功能 | 示例代码 |
|---|---|---|
sum() |
求和 | group.sum() |
mean() |
均值 | group.mean() |
max() |
最大值 | group.max() |
min() |
最小值 | group.min() |
count() |
计数 | group.count() |
agg() |
多聚合 | group.agg(['sum', 'mean']) |

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)