【愚公系列】《Python网络爬虫从入门到精通》032-DataFrame导入外部数据

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据分析的过程中,数据的获取是至关重要的一步。对于使用Pandas库的分析师而言,DataFrame不仅是处理和分析数据的强大工具,它还为我们提供了便捷的方式来导入外部数据。无论是从CSV文件、Excel表格,还是数据库和API获取数据,掌握如何将外部数据导入DataFrame将极大地提升我们的工作效率和数据分析能力。
本文将深入探讨在Pandas中如何导入外部数据到DataFrame,包括常见数据格式的读取方法和注意事项。我们将通过具体的示例,指导你一步步掌握数据导入的技巧,帮助你轻松处理各种数据源。
🚀一、DataFrame导入外部数据
Pandas支持多种数据格式的导入,包括Excel、CSV、TXT和HTML网页数据。
🔎1.导入Excel文件(.xls/.xlsx)
🦋1.1 read_excel() 核心参数详解
-
基础参数
| 参数 | 类型 | 说明 | 示例值 |
|---|---|---|---|
io |
str | 文件路径 | 'sales.xlsx' |
sheet_name |
int/str/list | 指定工作表 | 0, 'Sheet1', [0,2] |
header |
int | 列名所在行 | 0(默认取首行) |
names |
list | 自定义列名 | ['ID','Amount'] |
 在这里插入图片描述
在这里插入图片描述
-
行列控制
| 参数 | 功能 | 典型场景 |
|---|---|---|
index_col |
设置行索引列 | index_col=0(首列作为索引) |
usecols |
选择特定列 | [0,3] 或 'A:C,E' |
skiprows |
跳过起始行 | skiprows=3(跳过前3行) |
skipfooter |
跳过末尾行 | skipfooter=2(跳过最后2行) |
-
数据清洗
| 参数 | 作用 | 示例 |
|---|---|---|
dtype |
指定列类型 | {'Price':float} |
na_values |
定义空值标识 | na_values=['N/A'] |
converters |
列数据转换器 | {'ID': str}(强制转字符串) |
🦋1.2 关键功能实现示例
-
基础导入
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True) # 解决列对齐问题
# 读取默认第一个Sheet
df = pd.read_excel('1月.xlsx')
print(df.head())
 在这里插入图片描述
在这里插入图片描述
-
多Sheet处理
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_excel('1月.xlsx',sheet_name='莫寒')
print(df.head()) #输出前5条数据
# 读取多个Sheet(返回字典结构)
multi_sheets = pd.read_excel('年度数据.xlsx', sheet_name=[0, '季度汇总'])
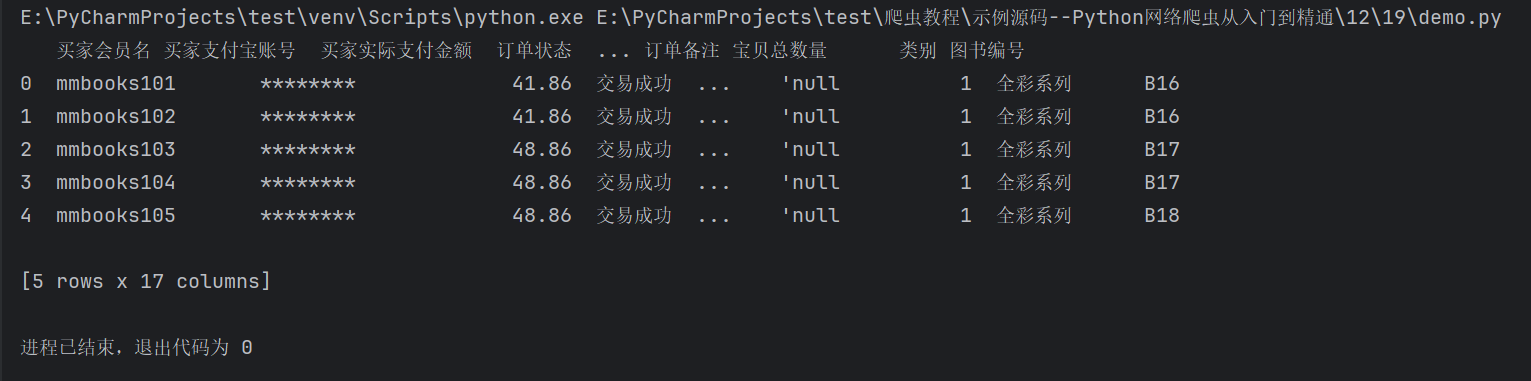 在这里插入图片描述
在这里插入图片描述
-
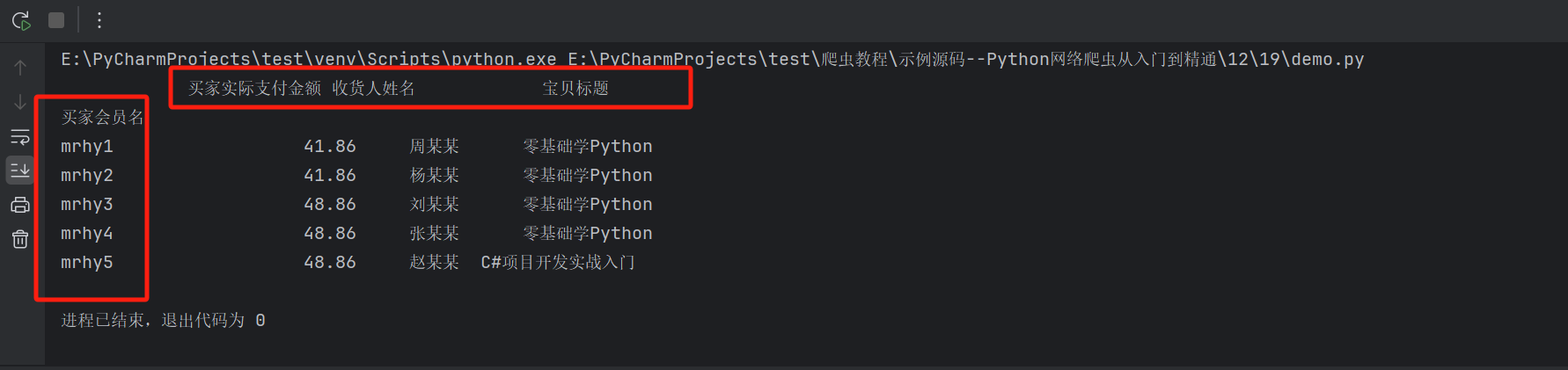
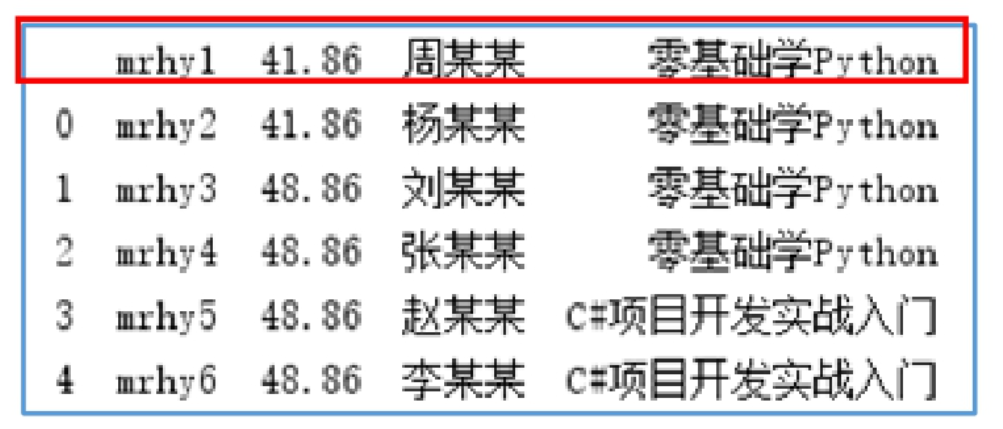
行列索引控制 当excel导入时,行列索引会自动生成如下: 
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1=pd.read_excel('1月.xlsx',index_col=0) #“买家会员名”为行索引
print(df1.head()) #输出前5条数据
# 自定义列名(当无表头时)
df_custom = pd.read_excel('无标题数据.xlsx', header=1)
# 自定义列名(当无表头时)
df_custom = pd.read_excel('无标题数据.xlsx', header=None)
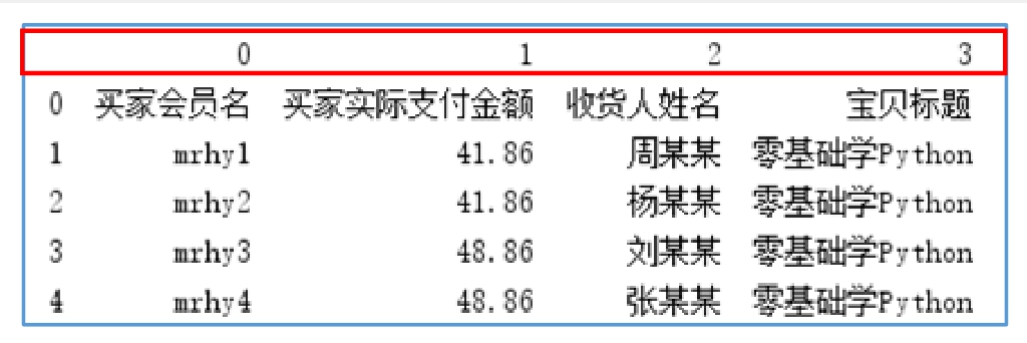
-
选择性列导入
# 按列位置选择(索引从0开始)
df_cols_index = pd.read_excel('1月.xlsx', usecols=[0, 3])
# 按列名选择(精确匹配)
df_cols_name = pd.read_excel('1月.xlsx', usecols=['买家会员名', '宝贝标题'])
 在这里插入图片描述
在这里插入图片描述  在这里插入图片描述
在这里插入图片描述
🦋1.3 路径处理规范
-
路径类型对比 | 类型 | 写法 | 适用场景 | |------|------|----------| | 相对路径 |
'data/1月.xlsx'| 项目内文件 | | 绝对路径 |'C:/Users/Project/data.xlsx'| 系统级固定路径 | | 原始字符串 |r'C:\raw\path.xlsx'| Windows路径转义 | -
常见错误规避
# 错误写法(未处理转义字符)
df_error = pd.read_excel('C:\new\data.xlsx') # 引发路径错误
# 正确解决方案
df_correct = pd.read_excel(r'C:\new\data.xlsx') # 使用原始字符串
🦋1.4 高级应用场景
-
大数据分块读取
# 分块读取大型文件(按每1万行处理)
chunk_size = 10000
chunks = pd.read_excel('大型数据集.xlsx', chunksize=chunk_size)
for chunk in chunks:
process(chunk) # 自定义处理函数
-
动态列类型推断
# 智能识别日期列(需配合日期解析器)
date_parser = lambda x: pd.to_datetime(x, format='%Y%m%d')
df_dates = pd.read_excel('带日期数据.xlsx', parse_dates=['订单日期'], date_parser=date_parser)
-
数据验证技巧
# 检查导入结果完整性
assert not df.empty, "数据为空!检查文件路径或工作表名称"
assert '买家会员名' in df.columns, "关键字段缺失!"
🦋1.5 性能优化建议
-
引擎选择:大文件优先使用 openpyxl引擎(通过engine='openpyxl'指定) -
内存管理:对于超大型文件,使用 read_excel()的dtype参数指定列类型可减少内存占用 -
缓存机制:将预处理后的数据保存为Feather格式加速后续读取:
df.to_feather('cache.feather')
df_cache = pd.read_feather('cache.feather')
🔎2.导入CSV文件
🦋2.1 read_csv() 核心参数分类解析
-
文件基础配置
| 参数 | 类型 | 必填 | 说明 | 典型值 |
|---|---|---|---|---|
filepath_or_buffer |
str | ✔ | 文件路径/URL | 'data.csv' |
sep/delimiter |
str | 列分隔符 | ',', '\t' |
|
encoding |
str | 文件编码 | 'utf-8', 'gbk' |
-
数据结构控制
| 参数 | 功能 | 应用场景 |
|---|---|---|
header |
列名所在行号 | header=0(默认首行为列名) |
names |
自定义列名 | names=['id','amount'] |
index_col |
指定索引列 | index_col='user_id' |
usecols |
选择特定列 | [0,2] 或 '列A,列C' |
-
数据清洗强化
| 参数 | 作用 | 示例 |
|---|---|---|
dtype |
强制列类型 | {'price':float} |
parse_dates |
日期解析 | parse_dates=['order_time'] |
na_values |
定义空值标识 | na_values=['N/A','NULL'] |
🦋2.2 关键功能实现示例
1. 基础读取(含编码处理)
import pandas as pd
#设置数据显示的最大列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df1=pd.read_csv('1月.csv',encoding='gbk') #导入csv文件,并指定编码格式
print(df1.head()) #输出前5条数据
输出样例: 
2. 动态日期解析
# 自动识别日期格式并转换
df_dates = pd.read_csv(
'订单数据.csv',
parse_dates=['下单时间', '支付时间'],
date_parser=lambda x: pd.to_datetime(x, format='%Y/%m/%d %H:%M')
)
3. 大数据分块处理
# 分块读取(适合内存不足场景)
chunk_size = 10000
chunks = pd.read_csv('大型数据.csv', chunksize=chunk_size)
for chunk in chunks:
process(chunk) # 自定义处理函数
🦋2.3 编码问题深度解决方案
-
编码探测流程
import chardet
# 自动检测文件编码
with open('未知编码.csv', 'rb') as f:
result = chardet.detect(f.read(10000))
encoding = result['encoding']
df = pd.read_csv('未知编码.csv', encoding=encoding)
-
编码错误应急方案
# 尝试常见编码格式
encodings = ['utf-8', 'gbk', 'gb2312', 'latin1']
for enc in encodings:
try:
df = pd.read_csv('问题文件.csv', encoding=enc)
break
except UnicodeDecodeError:
continue
🦋2.4 高级应用场景
1. 正则表达式分隔符
# 处理不规则分隔符(如多个空格)
df = pd.read_csv('日志数据.csv', sep='\s+') # \s+匹配任意空白符
2. 流式处理JSON字段
# 解析CSV中的JSON列
import json
df = pd.read_csv('含JSON列的数据.csv', converters={
'json_field': lambda x: json.loads(x)
})
🦋2.5 常见错误排查表
| 错误现象 | 原因分析 | 解决方案 |
|---|---|---|
UnicodeDecodeError |
编码不匹配 | 使用chardet检测实际编码 |
ParserError: Error tokenizing data |
分隔符错误 | 指定sep='\t'或engine='python' |
| 日期列识别为字符串 | 未启用日期解析 | 设置parse_dates=True |
| 内存溢出 | 文件过大 | 使用chunksize分块读取 |
🦋2.6 性能优化建议
-
类型预定义:通过
dtype参数指定列类型可减少40%内存占用dtype_map = {'用户ID': 'int32', '金额': 'float32'} df = pd.read_csv('data.csv', dtype=dtype_map) -
低内存模式:使用
low_memory=False关闭类型推断(适合列类型已知的场景) -
高效格式转换:将清洗后的数据存储为Parquet格式提升后续读取速度
df.to_parquet('processed_data.parquet')
🔎3.导入TXT文本文件
🦋3.1 TXT文件读取核心逻辑
-
与CSV的本质区别
| 特性 | CSV文件 | TXT文件 |
|---|---|---|
| 默认分隔符 | 逗号, |
无固定分隔符 |
| 编码规范 | 通常有标准编码 | 可能含特殊字符集 |
| 数据规整度 | 结构化程度高 | 需要自定义解析规则 |
-
关键控制参数
| 参数 | 类型 | 必填 | 说明 | 典型值 |
|---|---|---|---|---|
sep |
str | ✔ | 自定义分隔符 | '\t', '|' |
engine |
str | 解析引擎 | 'python'(复杂分隔符时) |
|
skipinitialspace |
bool | 跳过分隔符后空格 | True |
🦋3.2 标准操作流程示例
-
基础读取(制表符分隔)
import pandas as pd
# 设置显示优化(解决中文对齐问题)
pd.set_option('display.unicode.east_asian_width', True)
# 读取制表符分隔的TXT文件
df = pd.read_csv('1月.txt', sep='\t', encoding='gbk') # 必须显式指定分隔符
print(df.head(2))
输出样例: 

-
处理不规则分隔符
# 使用正则表达式匹配多个空格
df_space = pd.read_csv('日志数据.txt', sep='\s+', engine='python')
# 处理混合分隔符(如"|"和空格)
df_mixed = pd.read_csv('复杂数据.txt', sep='\s*\|\s*', engine='python')
🦋3.3 特殊场景处理方案
-
含注释行的处理
# 跳过以"#"开头的注释行
df = pd.read_csv('带注释的数据.txt',
sep='\t',
comment='#',
encoding='gbk')
-
非标准表头处理
# 手动指定列名(当文件无表头时)
columns = ['会员ID', '支付金额', '收货人', '商品名称', '时间']
df = pd.read_csv('无表头数据.txt',
sep='\t',
header=None,
names=columns)
🦋3.4 工程化问题解决方案
-
编码探测与自动处理
from charset_normalizer import detect
# 自动检测文件编码
with open('未知编码.txt', 'rb') as f:
result = detect(f.read(10000))
file_encoding = result['encoding']
df = pd.read_csv('未知编码.txt',
sep='\t',
encoding=file_encoding)
-
大文件分块读取
# 分块处理(每次读取1万行)
chunk_size = 10000
chunks = pd.read_csv('大型日志.txt',
sep='\t',
chunksize=chunk_size,
encoding='gbk')
for i, chunk in enumerate(chunks):
print(f"Processing chunk {i+1}")
process_data(chunk) # 自定义处理函数
🦋3.5 错误排查速查表
| 错误类型 | 典型表现 | 解决方案 |
|---|---|---|
ParserError |
列数不一致 | 检查分隔符是否正确,使用error_bad_lines=False跳过错误行 |
UnicodeDecodeError |
乱码 | 尝试encoding='gb18030'(兼容GBK扩展) |
| 内存溢出 | MemoryError | 启用chunksize分块读取或使用Dask库 |
🦋3.6 性能优化技巧
-
类型预定义:通过
dtype参数减少内存占用dtype_spec = { '买家会员名': 'category', '买家实际支付金额': 'float32' } df = pd.read_csv('1月.txt', sep='\t', dtype=dtype_spec, encoding='gbk') -
使用高效分隔符:将TXT转换为Pipe分隔格式可提升读取速度
# 存储为管道符分隔文件 df.to_csv('优化数据.psv', sep='|', index=False) -
二进制模式读取:对于超大型文件,使用低层API加速
import io with open('巨型文件.txt', 'rb') as f: buffer = io.BufferedReader(f) df = pd.read_csv(buffer, sep='\t')
🔎4.导入HTML网页
🦋4.1 read_html() 核心能力边界
-
适用场景特征
-
仅抓取 <table>标签包裹的结构化数据 -
适合静态网页(无需JavaScript渲染) -
支持分页表格自动合并(需手动构建URL列表)
-
性能对比(解析器选择)
| 解析器 | 速度 | 依赖性 | 容错性 |
|---|---|---|---|
lxml |
快 | 需安装 | 低 |
html5lib |
慢 | 需安装 | 高 |
beautifulsoup4 |
中 | 需配置 | 中 |
🦋4.2 核心参数技术解析
| 参数 | 类型 | 必填 | 功能说明 | 典型值 |
|---|---|---|---|---|
io |
str | ✔ | URL/HTML内容 | 'http://example.com' |
match |
str | 正则匹配表格标题 | 'Player Stats' |
|
flavor |
str | 解析引擎 | 'lxml'(默认) |
|
attrs |
dict | 表格属性过滤 | {'id': 'salary-table'} |
🦋4.3 标准操作流程
-
基础抓取(单页表格)
import pandas as pd
# 抓取单页表格(自动检测所有<table>)
tables = pd.read_html('http://www.espn.com/nba/salaries')
df = tables[0] # 选择第一个表格
print(df.head())
-
多页数据聚合
import pandas as pd
df = pd.DataFrame()
url_list = ['http://www.espn.com/nba/salaries/_/seasontype/4']
for i in range(2, 13):
url = 'http://www.espn.com/nba/salaries/_/page/%s/seasontype/4' % i
url_list.append(url)
#遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
#列表解析:遍历dataframe第3列,以子字符串$开头
df = df[[x.startswith('$') for x in df[3]]]
print(df)
df.to_csv('NBA.csv',header=['RK','NAME','TEAM','SALARY'], index=False)
 在这里插入图片描述
在这里插入图片描述
🦋4.4 高级应用场景
-
精准定位表格
# 通过表格属性定位
target_table = pd.read_html(
'http://example.com',
attrs={'class': 'data-table'},
match='Player Salary' # 正则匹配表格标题
)[0]
-
动态渲染页面处理
# 配合Selenium处理JS渲染
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://dynamic-page.com')
html = driver.page_source
dfs = pd.read_html(html)
driver.quit()
🦋4.5 数据清洗规范
-
列名标准化
# 重置列名(适用于多层表头)
df.columns = ['排名', '球员姓名', '球队', '薪资']
-
货币格式化
# 转换薪资为数值类型
df['薪资'] = df['薪资'].str.replace('$', '').str.replace(',', '').astype(float)
🦋4.6 错误排查与优化
-
依赖缺失解决方案
# 安装必备库
pip install lxml html5lib beautifulsoup4
-
反爬虫绕过策略
# 添加请求头模拟浏览器
dfs = pd.read_html(
'http://protected-site.com',
headers={'User-Agent': 'Mozilla/5.0'}
)
-
SSL证书错误处理
# 禁用SSL验证(慎用)
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
🦋4.7 工程化存储方案
-
增量存储模式
# 追加模式写入CSV(保留历史)
final_df.to_csv('nba_salaries.csv', mode='a', header=False, index=False)
-
数据库直存
from sqlalchemy import create_engine
engine = create_engine('postgresql://user:pass@localhost/db')
final_df.to_sql('nba_salaries', engine, if_exists='replace')
🦋4.8 性能优化指标
| 优化策略 | 效果提升 | 实现代码 |
|---|---|---|
| 限制解析表格数 | 减少内存占用30% | pd.read_html(..., max_tables=2) |
| 列类型预定义 | 加速后续处理40% | dtype={'薪资': 'float64'} |
| 并行请求加速 | 缩短抓取时间70% | 使用concurrent.futures线程池 |
🔎5.路径处理技巧
-
相对路径: -
./data.xlsx:当前目录下的data.xlsx。 -
../data/data.xlsx:上级目录的data文件夹中的文件。
-
-
绝对路径: df = pd.read_excel(r"C:\Users\Project\data.xlsx") # Windows路径需加r
🔎6.常见错误与解决
-
编码错误:
-
错误提示: UnicodeDecodeError: 'utf-8' codec can't decode byte... -
解决:明确指定编码格式(如 encoding="gbk")。
-
-
缺失依赖库:
-
错误提示: ImportError: lxml not found -
解决:运行 pip install lxml。
-
-
网络请求失败:
-
错误提示: HTTPError: 403 Forbidden -
解决:添加请求头模拟浏览器访问或使用代理。
-
🔎7.总结
-
Excel:灵活指定Sheet、索引列和导入列。 -
CSV/TXT:注意分隔符和编码格式。 -
HTML:依赖外部库,需处理反爬机制。 -
路径:优先使用相对路径,避免硬编码绝对路径。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)