【愚公系列】《Python网络爬虫从入门到精通》029-DataFrame数据的增删改查

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据分析的过程中,灵活地对数据进行增删改查(CRUD操作)是至关重要的。Pandas库中的DataFrame对象作为一种强大的数据结构,为我们提供了高效、直观的数据处理能力。无论是数据清洗、预处理,还是后续的分析与可视化,掌握DataFrame的增删改查操作,都是每位数据分析师必不可少的技能。
本文将详细介绍如何在DataFrame中进行数据的增、删、改、查操作。我们将通过具体的示例,帮助你理解如何灵活地管理和操控数据,使你的分析工作更加高效和顺畅。
🚀一、DataFrame数据的增删改查
🔎1.增加数据
🦋1.1 按列增加
方法一:直接赋值
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
df['物理']=[88,79,60,50]
# df.loc[:,'物理'] = [88,79,60,50]
print(df)
# wl =[88,79,60,50]
# df.insert(1,'物理',wl)
# print(df)
输出: 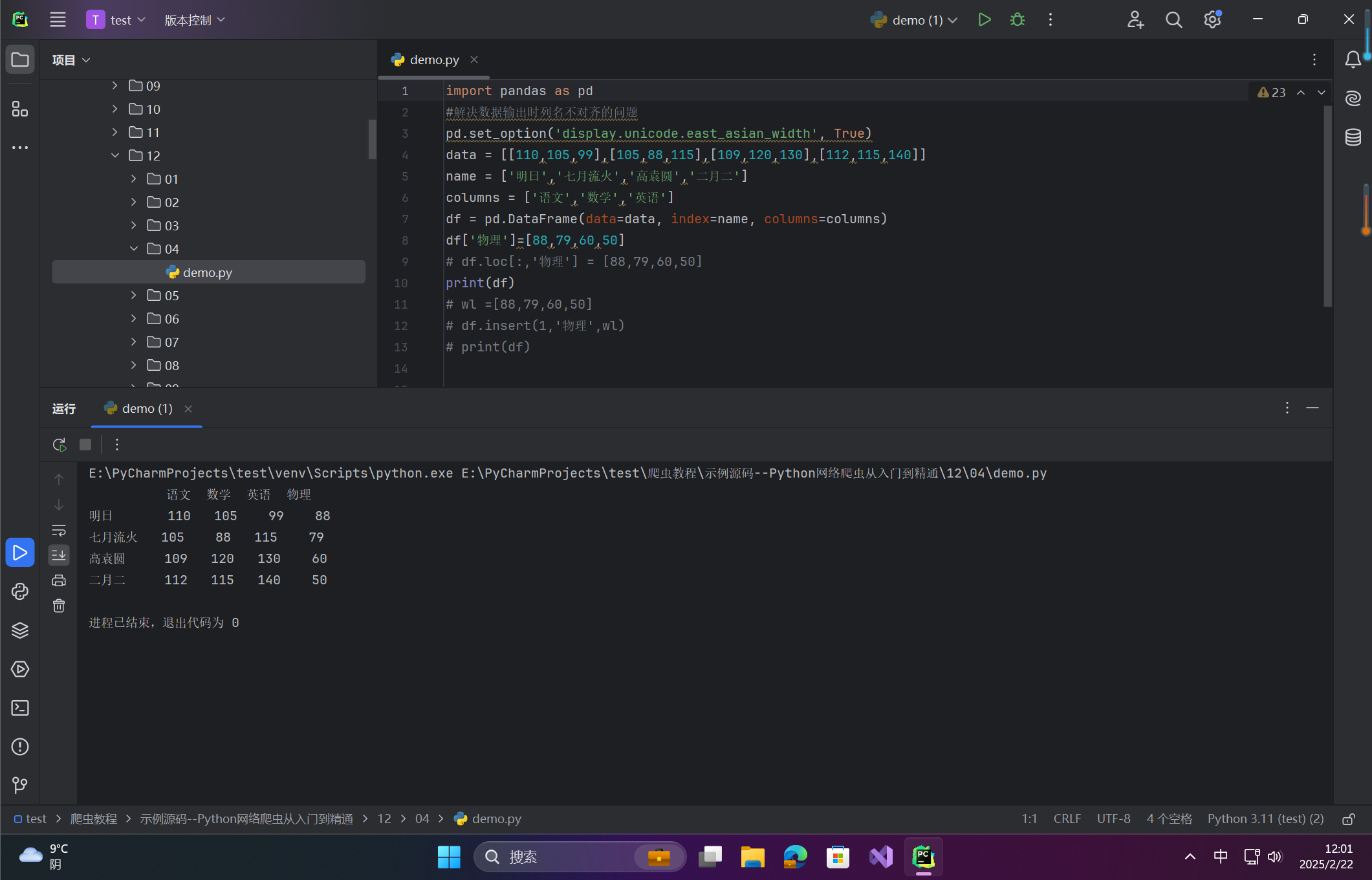
方法二:使用loc属性添加列
df.loc[:, '物理'] = [88, 79, 60, 50] # 等效于直接赋值
方法三:使用insert插入列
wl = [88, 79, 60, 50]
df.insert(1, '物理', wl) # 在第1列后插入新列
print(df)
输出:
语文 物理 数学 英语
明日 110 88 105 99
七月流火 105 79 88 115
高袁圆 109 60 120 130
二月二 112 50 115 140
🦋1.2 按行增加
方法一:使用loc添加单行
df.loc['钱多多'] = [100, 120, 99] # 添加一行数据
print(df)
输出:
语文 数学 英语
明日 110 105 99
七月流火 105 88 115
高袁圆 109 120 130
二月二 112 115 140
钱多多 100 120 99
方法二:使用concat添加多行
df_insert = pd.DataFrame(
{'语文': [100, 123, 138], '数学': [99, 142, 60], '英语': [98, 139, 99]},
index=['钱多多', '童年', '无名']
)
df = pd.concat([df, df_insert], ignore_index=True)
print(df)
输出:
语文 数学 英语
明日 110 105 99
七月流火 105 88 115
高袁圆 109 120 130
二月二 112 115 140
钱多多 100 99 98
童年 123 142 139
无名 138 60 99
🔎2.删除数据
DataFrame.drop() 方法
drop()方法用于删除DataFrame中的行或列。语法格式如下:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
参数说明:
-
labels:
-
表示要删除的行标签或列标签。如果指定了 index或columns,则labels是多余的。
-
-
axis:
-
axis=0:表示按行删除,默认值为0。 -
axis=1:表示按列删除。
-
-
index:
-
删除行的标签,默认为 None。如果指定了该参数,labels可以省略。
-
-
columns:
-
删除列的标签,默认为 None。如果指定了该参数,labels可以省略。
-
-
level:
-
针对有多级索引(MultiIndex)的数据,指定删除的索引级别。 -
level=0:表示按第1级索引删除整行。 -
level=1:表示按第2级索引删除整行。 -
默认值为 None。
-
-
-
inplace:
-
是否对原数组进行修改。 -
False(默认值):返回一个新的DataFrame对象,原DataFrame不受影响。 -
True:原DataFrame会被直接修改,不会返回新的DataFrame。
-
-
-
errors:
-
设定错误处理方式。 -
raise(默认值):如果指定的标签不存在,则抛出错误。 -
ignore:忽略错误,不会抛出异常。
-
-
🦋2.1 删除行列
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
# df.drop(['数学'],axis=1,inplace=True) #删除某列
# df.drop(columns='数学',inplace=True) #删除columns为“数学”的列
# df.drop(labels='数学', axis=1,inplace=True) #删除列标签为“数学”的列
# df.drop(['明日','二月二'],inplace=True) #删除某行
# df.drop(index='明日',inplace=True) #删除index为“明日”的行
# df.drop(labels='明日', axis=0,inplace=True) #删除行标签为“明日”的行
print(df)
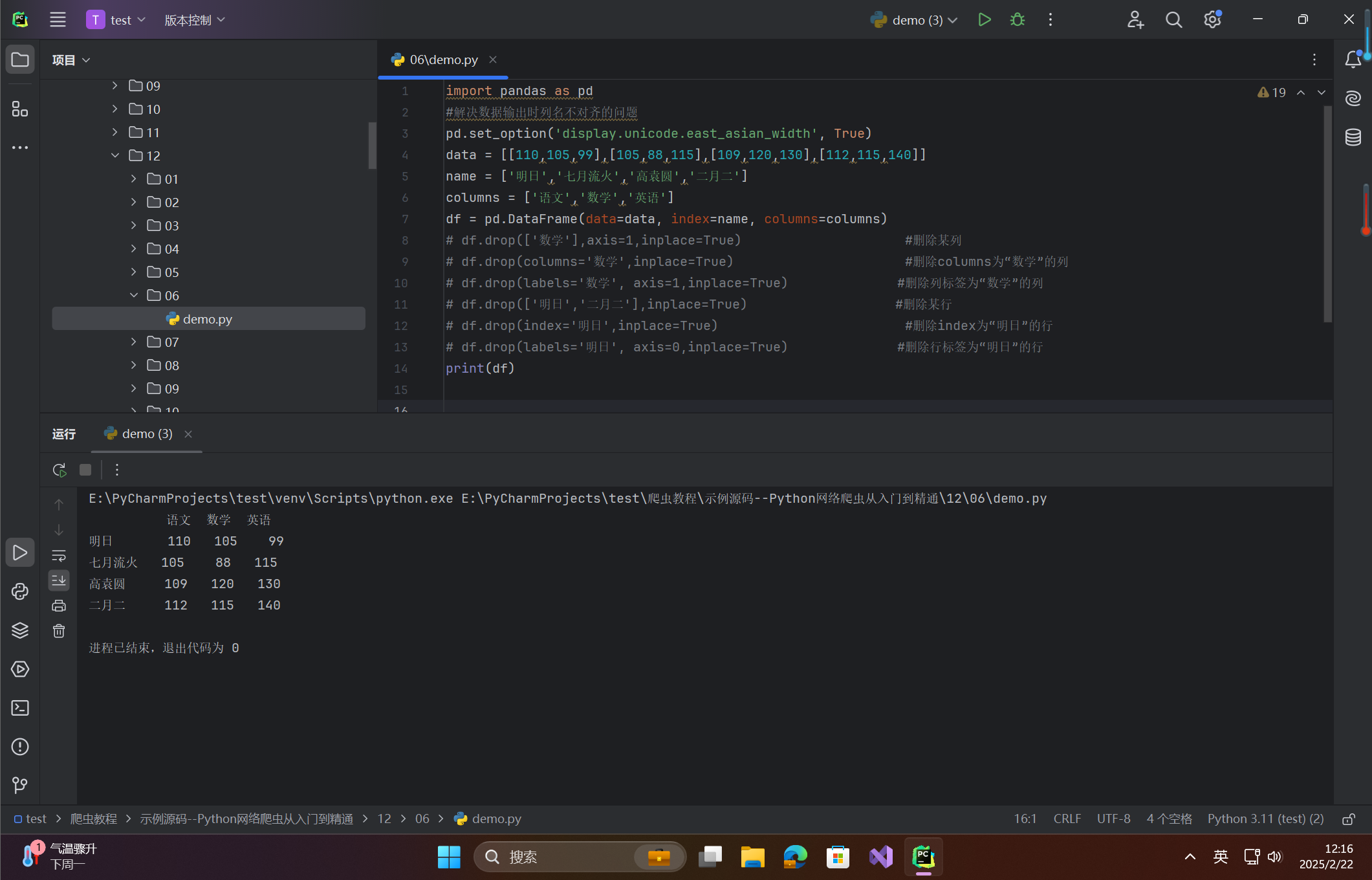 在这里插入图片描述
在这里插入图片描述
🦋2.2 删除满足条件的行
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
# df.drop(index=df[df['数学'].isin([88])].index[0],inplace=True) #删除“数学”包含88的行
# df.drop(index=df[df['语文']<110].index[0],inplace=True) #删除“语文”小于110的行
print(df)
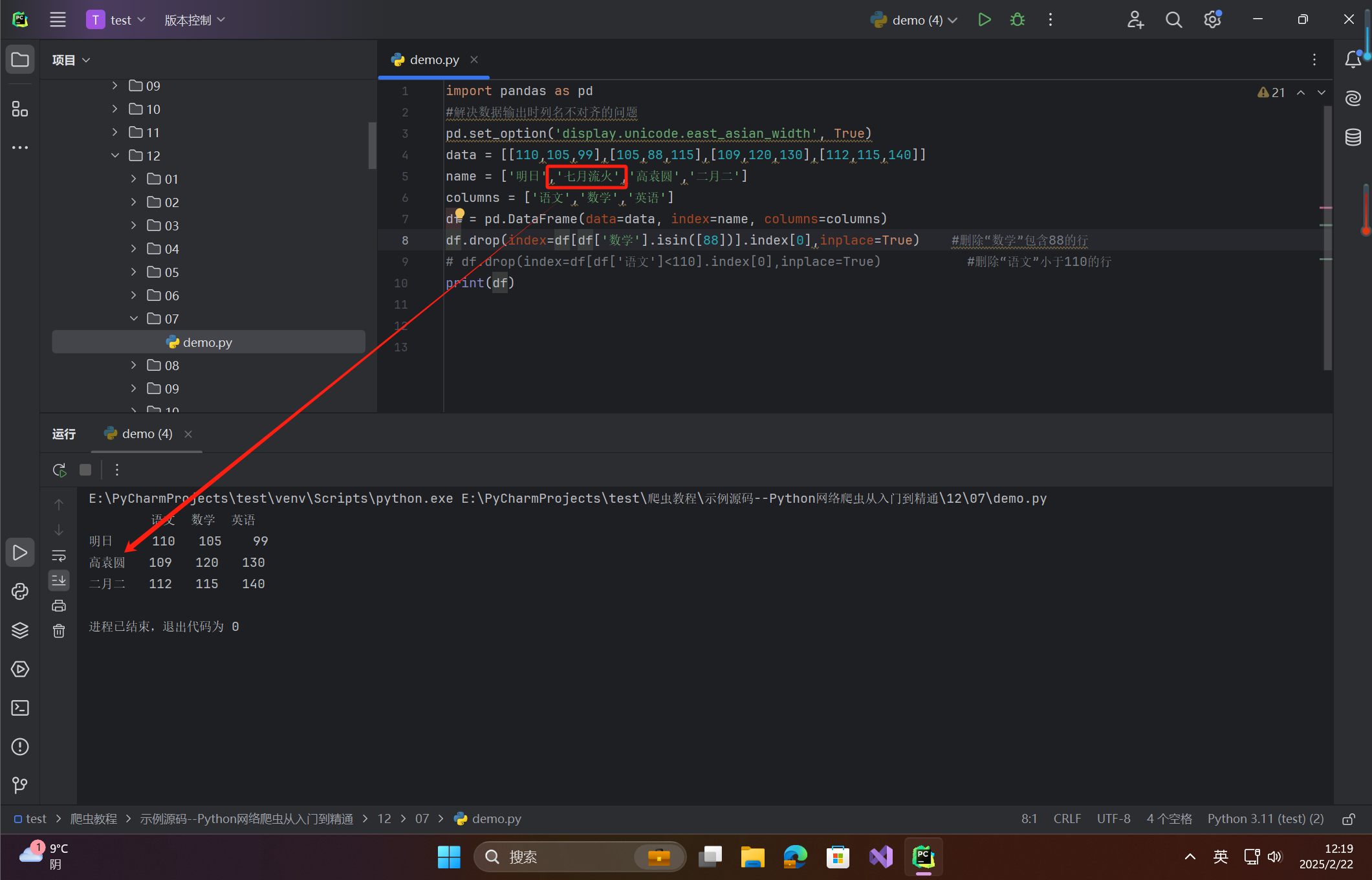 在这里插入图片描述
在这里插入图片描述
🔎3.修改数据
🦋3.1 修改列名
方法一:直接赋值
df.columns = ['语文(上)', '数学(上)', '英语(上)']
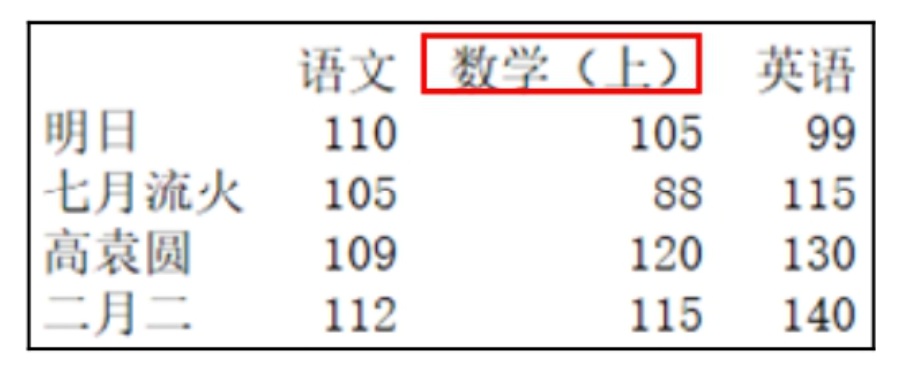 在这里插入图片描述
在这里插入图片描述
方法二:使用rename方法
df.rename(columns={'语文': '语文(上)', '数学': '数学(上)'}, inplace=True)
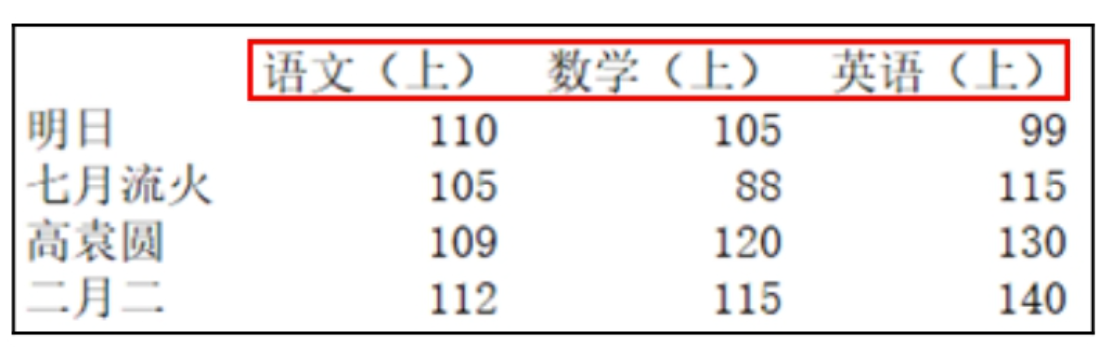 在这里插入图片描述
在这里插入图片描述
🦋3.2 修改行名
df.index = ['1', '2', '3', '4'] # 直接赋值
df.rename({'明日': '1', '七月流火': '2'}, axis=0, inplace=True) # 使用rename
🦋3.3 修改数据
修改整行
df.loc['明日'] = [120, 115, 109] # 修改整行数据
df.loc['明日'] += 10 # 所有值加10
修改整列
df.loc[:, '语文'] = [115, 108, 112, 118] # 修改“语文”列所有值
修改单个值
df.loc['明日', '语文'] = 115 # 修改指定单元格
使用iloc按位置修改
df.iloc[0, 0] = 115 # 修改第1行第1列
df.iloc[:, 0] = [115, 108, 112, 118] # 修改第1列所有值
🔎4.查询数据
🦋4.1 查询列数据
print(df['语文']) # 通过列名获取数据
print(df.语文) # 等效方法(列名为有效标识符时)
🦋4.2 查询行数据
print(df[0:3]) # 获取前3行(包头不包尾)
🦋4.3 查询单个元素
print(df['数学'][2]) # 获取第3行的“数学”列数据
print(df.loc['高袁圆', '语文']) # 通过标签获取
print(df.iloc[2, 0]) # 通过位置获取(第3行第1列)
🔎5.关键点总结
-
增加数据:灵活使用直接赋值、 loc和insert方法。 -
删除数据:通过 drop指定行/列标签或条件。 -
修改数据:通过标签( loc)或位置(iloc)精准操作。 -
查询数据:按列、行或单个元素灵活获取数据。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)