【愚公系列】《Python网络爬虫从入门到精通》026-多进程爬虫

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在信息爆炸的时代,数据的获取变得愈发重要。网络爬虫作为一种高效的数据采集工具,广泛应用于各个领域。然而,随着网络数据量的急剧增加,单线程爬虫的效率已难以满足需求。此时,多进程爬虫应运而生,成为提升数据抓取效率的重要手段。
本文将探讨多进程爬虫的基本原理、优势以及实现方法,帮助你理解如何通过并行处理来加速数据采集过程。无论你是爬虫开发的新手,还是希望优化现有爬虫的工程师,这篇文章都将为你提供实用的指导和深入的见解。
🚀一、多进程爬虫
多线程虽然能实现并发,但受限于进程内的资源。使用multiprocessing模块和Pool进程池可实现真正的多进程爬虫,显著提升效率。以下以爬取电影网站信息为例,演示多进程爬虫的实现。
🔎1.分析请求地址
-
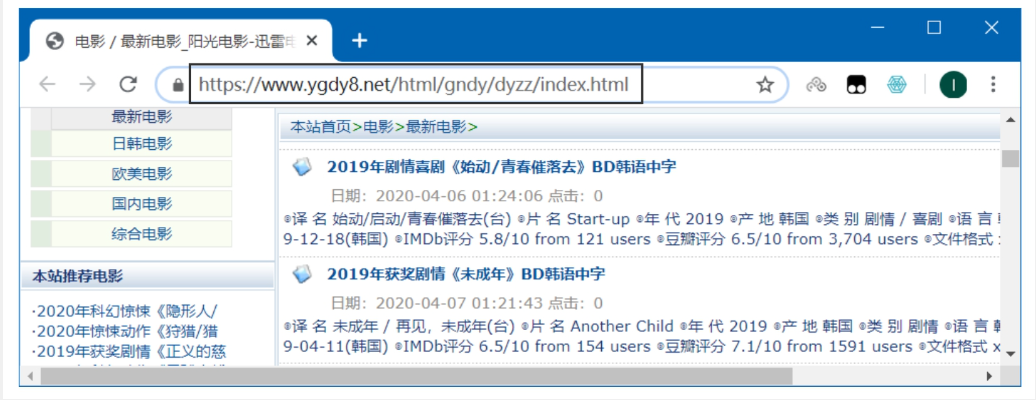
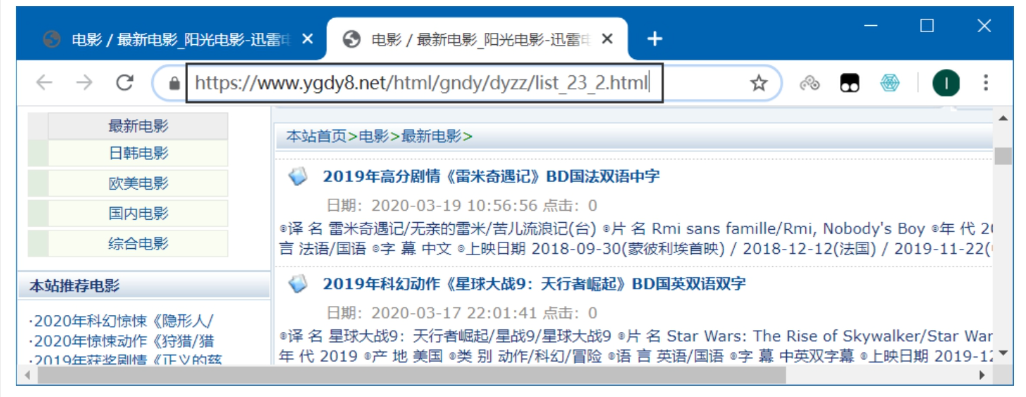
主页翻页规律: -
主页地址格式: https://www.ygdy8.net/html/gndy/dyzz/list_23_{页码}.html -
示例: -
第1页: list_23_1.html -
第2页: list_23_2.html -
第3页: list_23_3.html
-
-
-
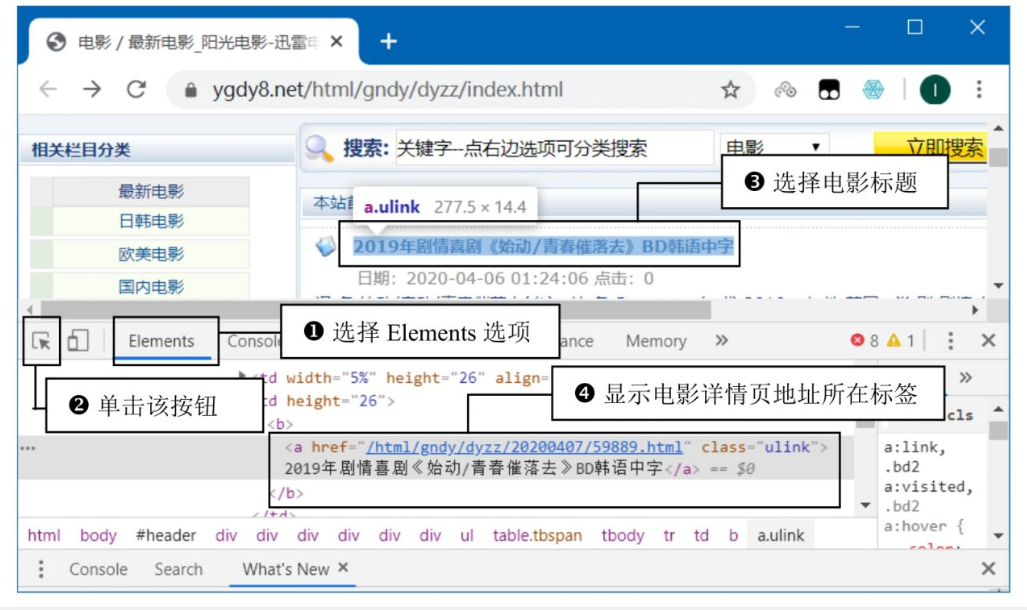
详情页地址提取: -
使用浏览器开发者工具定位电影标题的HTML标签,获取详情页的相对路径(如 /html/.../12345.html)。
-
🔎2.爬取电影详情页地址
🦋2.1 代码框架
import requests
from fake_useragent import UserAgent
from multiprocessing import Pool
import re
from bs4 import BeautifulSoup
import time
import pandas as pd
class Spider:
def __init__(self):
self.info_urls = [] # 存储详情页URL
self.df = pd.DataFrame(columns=('name', 'date', 'imdb', 'douban', 'length', 'download_url'))
def get_home(self, home_url):
headers = {'User-Agent': UserAgent().random}
response = requests.get(home_url, headers=headers)
if response.status_code == 200:
response.encoding = 'gb2312'
html = response.text
# 提取详情页URL(正则匹配)
details_urls = re.findall(r'', html)
self.info_urls.extend(details_urls)
if __name__ == '__main__':
# 生成前10页的主页URL
home_urls = [f'https://www.ygdy8.net/html/gndy/dyzz/list_23_{i}.html' for i in range(1, 11)]
# 串行爬取(对比耗时)
s_serial = Spider()
start = time.time()
for url in home_urls:
s_serial.get_home(url)
print(f"串行耗时: {time.time() - start:.2f}秒")
# 多进程爬取(4进程)
s_parallel = Spider()
start = time.time()
with Pool(4) as pool:
pool.map(s_parallel.get_home, home_urls)
print(f"4进程耗时: {time.time() - start:.2f}秒")
运行结果
串行耗时: 12.16秒
4进程耗时: 4.92秒
🔎3.爬取电影信息与下载地址
🦋3.1 提取电影信息
通过开发者工具定位关键信息标签:
-
电影名称:`` -
上映时间/IMDB/豆瓣评分:``中的文本内容。 -
下载地址:页面底部的迅雷下载链接。
🦋3.2 实现代码
import requests # 导入网络请求模块
from fake_useragent import UserAgent # 导入请求头模块
from multiprocessing import Pool # 导入进程池
import re # 导入正则表达式
from bs4 import BeautifulSoup # 导入解析html代码
import time # 导入时间模块
import pandas as pd # 导入pandas模块
class Spider():
def __init__(self):
self.info_urls = [] # 所有电影详情页的请求地址
# 创建DataFrame临时表格
self.df = pd.DataFrame(columns=('name', 'date', 'imdb', 'douban', 'length', 'download_url'))
# 获取首页信息
def get_home(self,home_url):
header = UserAgent().random # 创建随机请求头
home_response = requests.get(home_url,header) # 发送首页网络请求
if home_response.status_code ==200: # 判断请求是否成功
home_response.encoding='gb2312' # 设置编码方式
html = home_response.text # 获取返回的html代码
details_urls = re.findall('<a href="(.*?)" class="ulink">',html) # 获取所有电影详情页地址
self.info_urls.extend(details_urls) # 添加请求地址列表
def get_info(self,url):
header = UserAgent().random # 创建随机请求头
info_response = requests.get(url,header) # 发送获取每条电影信息的网络请求
if info_response.status_code ==200: # 判断请求是否成功
info_response.encoding = 'gb2312'
html = BeautifulSoup(info_response.text,"html.parser") # 获取返回的html代码
try:
# 获取迅雷下载地址
download_url = re.findall('<a href=".*?">(.*?)</a></td>',
info_response.text)[0]
except:
# 出现异常不再爬取,直接爬起下一个电影的信息
return
name = html.select('div[class="title_all"]')[0].text # 获取电影名称
# 将电影的详细信息进行处理,先去除所有html中的空格(\u3000),然后用◎将数据进行分割
info_all = (html.select('div[id="Zoom"]')[0]).p.text.replace('\u3000','').split('◎')
date = info_all[8] # 获取上映时间
imdb = info_all[9] # 获取IMDb评分
douban = info_all[10] # 获取豆瓣评分
length = info_all[14] # 获取片长
# 将数据信息添加至DataFrame临时表格中
self.df.loc[len(self.df)+1] = {'name': name, 'date': date, 'imdb': imdb,
'douban': douban, 'length': length,'download_url': download_url}
if __name__ == '__main__': # 创建程序入口
# 创建主页请求地址的列表
home_url = ['https://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html'
.format(str(i))for i in range(1,11)]
s = Spider() # 创建自定义爬虫类对象
start_time = time.time() # 记录串行爬取电影详情页地址的起始时间
for i in home_url: # 循环遍历主页请求地址
s.get_home(i) # 发送网络请求,获取每个电影详情页地址
end_time = time.time() # 记录串行爬取电影详情页地址结束时间
print('串行爬取电影详情页地址耗时:',end_time-start_time)
start_time_4 = time.time() # 记录四进程爬取电影详情页地址起始时间
pool = Pool(processes=4) # 创建4进程对象
pool.map(s.get_home,home_url) # 通过进程获取每个电影详情页地址
end_time_4 = time.time() # 记录四进程爬取电影详情页地址结束时间
print('4进程爬取电影详情页地址耗时:', end_time_4 - start_time_4)
# 以下用于爬取电影详情信息,并保存
info_urls = ['http://www.ygdy8.net' + i for i in s.info_urls] # 组合每个电影详情页的请求地址
info_start_time = time.time() # 记录爬取电影详情信息的起始时间
for i in info_urls: # 循环遍历电影详情页请求地址
s.get_info(i) # 发送网络请求,获取每个电影详情信息
info_end_time = time.time() # 记录串行结束时间
print('串行爬取电影详情信息耗时:', info_end_time - info_start_time)
s.df.to_excel('movie_information.xlsx') # 将爬取电影的详细信息保存至excel文件中
info_start_time_4 = time.time() # 记录四进程爬取电影详情信息起始时间
pool = Pool(processes=4) # 创建4进程对象
pool.map(s.get_info, info_urls) # 通过进程获取每个电影详情信息
info_end_time_4 = time.time() # 记录四进程爬取电影详情信息结束时间
print('4进程爬取电影详情信息耗时:', info_end_time_4 - info_start_time_4)
s.df.to_excel('movie_information_4pool.xlsx') # 将爬取电影的详细信息保存至excel文件中
运行结果 
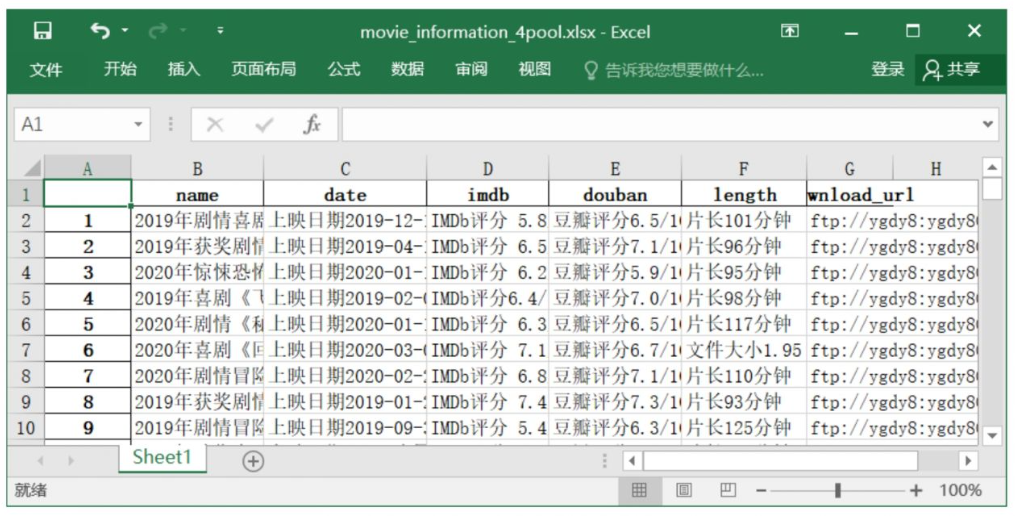
🔎4.结果输出
-
Excel文件内容:
 在这里插入图片描述
在这里插入图片描述
🔎5.关键点总结
-
多进程优势:
-
并行处理I/O密集型任务(如网络请求),显著减少总耗时。 -
需注意进程间数据隔离,使用独立实例或共享内存(如 multiprocessing.Manager)。
-
-
反爬策略:
-
使用随机User-Agent( fake_useragent库)。 -
合理设置请求间隔,避免触发反爬机制。
-
-
异常处理:
-
网络请求需校验 status_code。 -
数据提取时需处理可能的标签缺失或格式变化。
-
通过多进程爬虫,可充分利用CPU资源,提升爬虫效率。但需注意目标网站的Robots协议及法律合规性。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)