【愚公系列】《Python网络爬虫从入门到精通》023-多线程爬虫

| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在信息爆炸的时代,数据的获取和处理变得愈发重要。网络爬虫作为一种强大的数据采集工具,已经在各个领域中发挥着不可或缺的作用。而在爬取大规模数据时,单线程的爬虫往往显得力不从心,效率低下。为了提升数据获取的速度和效率,多线程爬虫应运而生。
本期文章将深入探讨多线程爬虫的原理与应用,带您了解如何利用多线程技术显著提高网络数据的采集效率。我们将从多线程的基本概念入手,逐步剖析其在爬虫开发中的具体实现和最佳实践。
🚀一、多线程爬虫
🔎1.什么是线程
线程(Thread)是操作系统能够进行运算调度的最小单位。它被包含在进程中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。例如,对于视频播放器,显示视频用一个线程,播放音频用另一个线程。只有两个线程同时工作,我们才能正常观看画面和声音同步的视频。
举个生活中的例子来更好地理解进程和线程的关系。一个进程就像一座房子,它是一个容器,有着相应的属性,如占地面积、卧室、厨房和卫生间等。房子本身并没有主动地做任何事情。而线程就是这座房子的居住者,他可以使用房子内每一个房间、做饭、洗澡等。
🔎2.Python线程创建
🦋2.1 线程模块选择
-
thread模块:低级模块,功能有限(不推荐直接使用)。 -
threading模块:高级模块,封装了thread,提供更全面的线程管理接口(推荐使用)。
🦋2.2 创建线程的两种方式
方式1:直接使用threading.Thread类
-
语法:
Thread(group=None, target=None, name=None, args=(), kwargs={})参数说明:
-
group:
-
说明: 该参数保留给将来的版本,当前版本中应始终设置为 None。 -
默认值: None
-
-
target:
-
说明: 表示一个可调用对象(如函数),线程启动时, run()方法将调用此对象。如果不提供该参数,线程将不会执行任何操作。 -
默认值: None
-
-
name:
-
说明: 表示当前线程的名称。如果未指定,将自动生成一个名称,格式为“Thread-N”,其中 N 是一个唯一的数字。 -
默认值: None(自动生成名称)
-
-
args:
-
说明: 表示传递给 target函数的参数,以元组的形式提供。如果target函数不需要参数,可以设置为一个空元组。 -
默认值: ()(空元组)
-
-
kwargs:
-
说明: 表示传递给 target函数的关键字参数,以字典的形式提供。如果target函数不需要关键字参数,可以设置为一个空字典。 -
默认值: {}(空字典)
-
-
-
示例代码(创建4个线程):
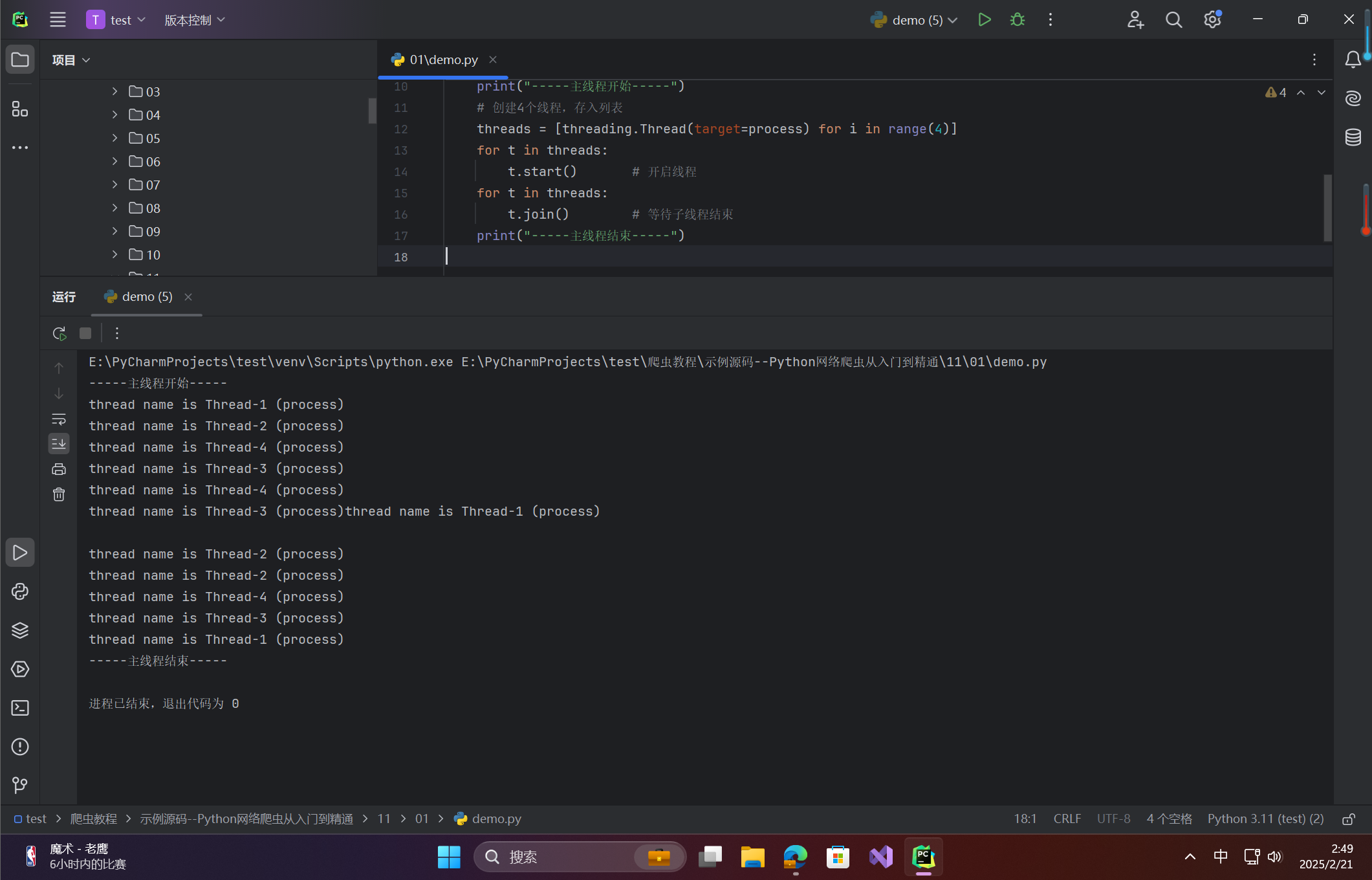
# -*- coding:utf-8 -*- import threading,time def process(): for i in range(3): time.sleep(1) print("thread name is %s" % threading.current_thread().name) if __name__ == '__main__': print("-----主线程开始-----") # 创建4个线程,存入列表 threads = [threading.Thread(target=process) for i in range(4)] for t in threads: t.start() # 开启线程 for t in threads: t.join() # 等待子线程结束 print("-----主线程结束-----")运行结果:

4个子线程并发执行,每个线程输出3次名称。
方式2:继承Thread类自定义子类
-
步骤:
-
定义子类继承 threading.Thread。 -
重写 run()方法(线程逻辑在此实现)。
-
-
示例代码:
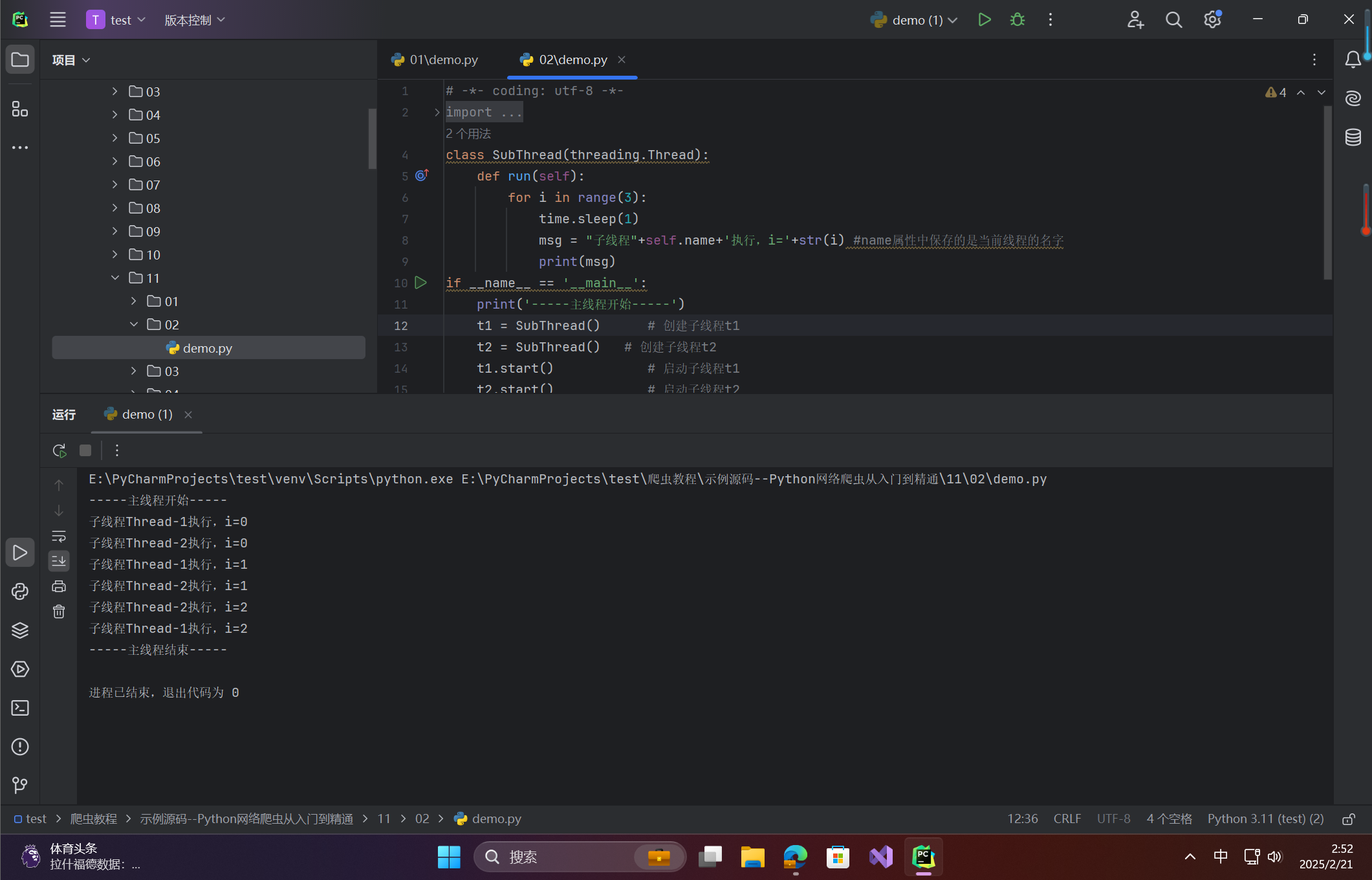
# -*- coding: utf-8 -*- import threading import time class SubThread(threading.Thread): def run(self): for i in range(3): time.sleep(1) msg = "子线程"+self.name+'执行,i='+str(i) #name属性中保存的是当前线程的名字 print(msg) if __name__ == '__main__': print('-----主线程开始-----') t1 = SubThread() # 创建子线程t1 t2 = SubThread() # 创建子线程t2 t1.start() # 启动子线程t1 t2.start() # 启动子线程t2 t1.join() # 等待子线程t1 t2.join() # 等待子线程t2 print('-----主线程结束-----')运行结果:
两个子线程交替输出执行信息。
🔎3.线程间通信
🦋3.1 共享全局变量
-
特性:同一进程内的线程共享全局变量。
-
示例代码(验证共享性):
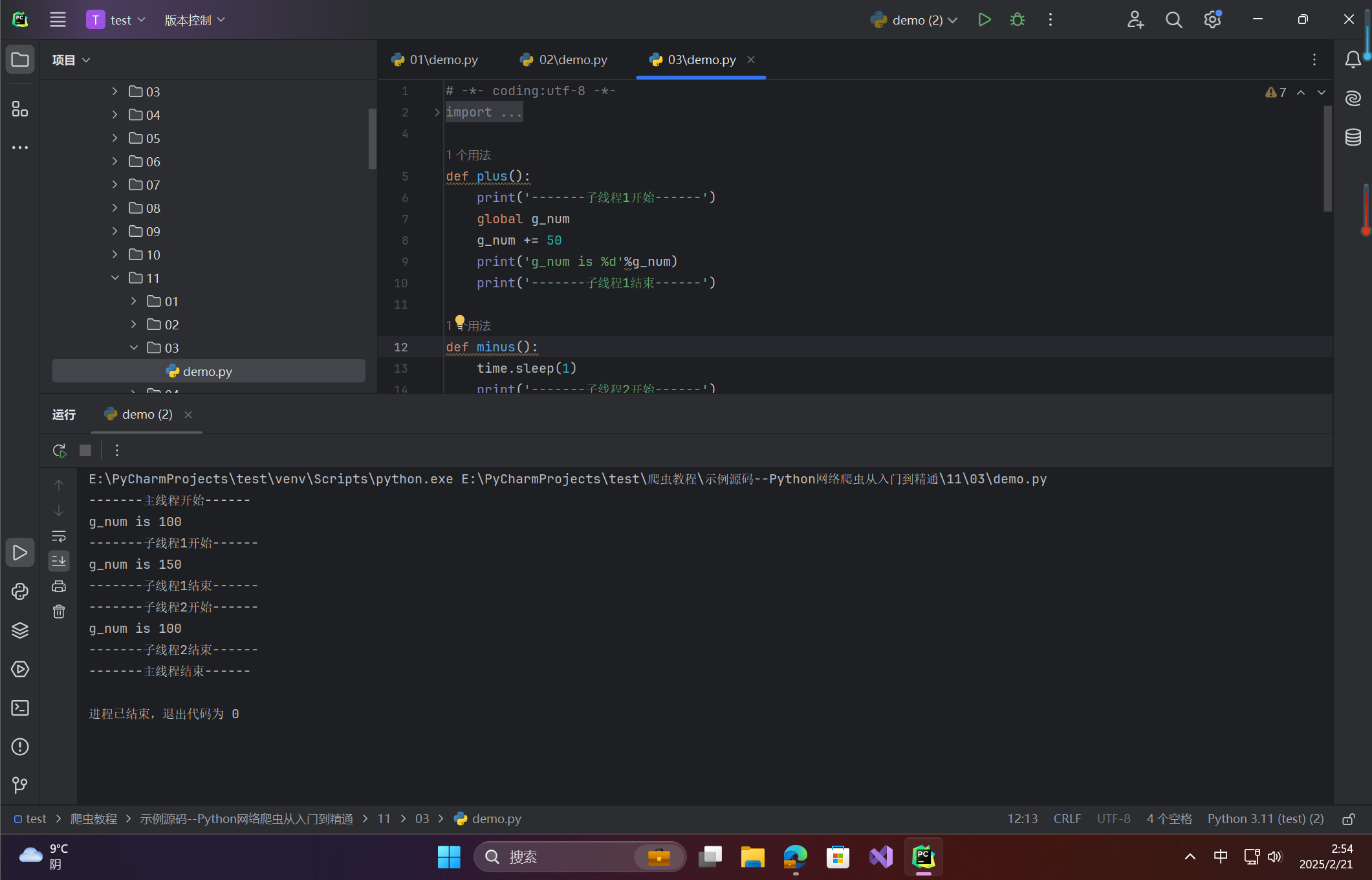
# -*- coding:utf-8 -*- from threading import Thread import time def plus(): print('-------子线程1开始------') global g_num g_num += 50 print('g_num is %d'%g_num) print('-------子线程1结束------') def minus(): time.sleep(1) print('-------子线程2开始------') global g_num g_num -= 50 print('g_num is %d'%g_num) print('-------子线程2结束------') g_num = 100 # 定义一个全局变量 if __name__ == '__main__': print('-------主线程开始------') print('g_num is %d'%g_num) t1 = Thread(target=plus) # 实例化线程p1 t2 = Thread(target=minus) # 实例化线程p2 t1.start() # 开启线程p1 t2.start() # 开启线程p2 t1.join() # 等待p1线程结束 t2.join() # 等待p2线程结束 print('-------主线程结束------')运行结果:
g_num的最终值可能为100(线程交替执行顺序影响结果)。
🦋3.2 互斥锁(Lock)
-
作用:防止多线程同时修改共享资源导致数据混乱。
-
核心方法:
-
acquire():加锁(阻塞或非阻塞)。 -
release():释放锁。
-
-
示例代码(模拟购票):
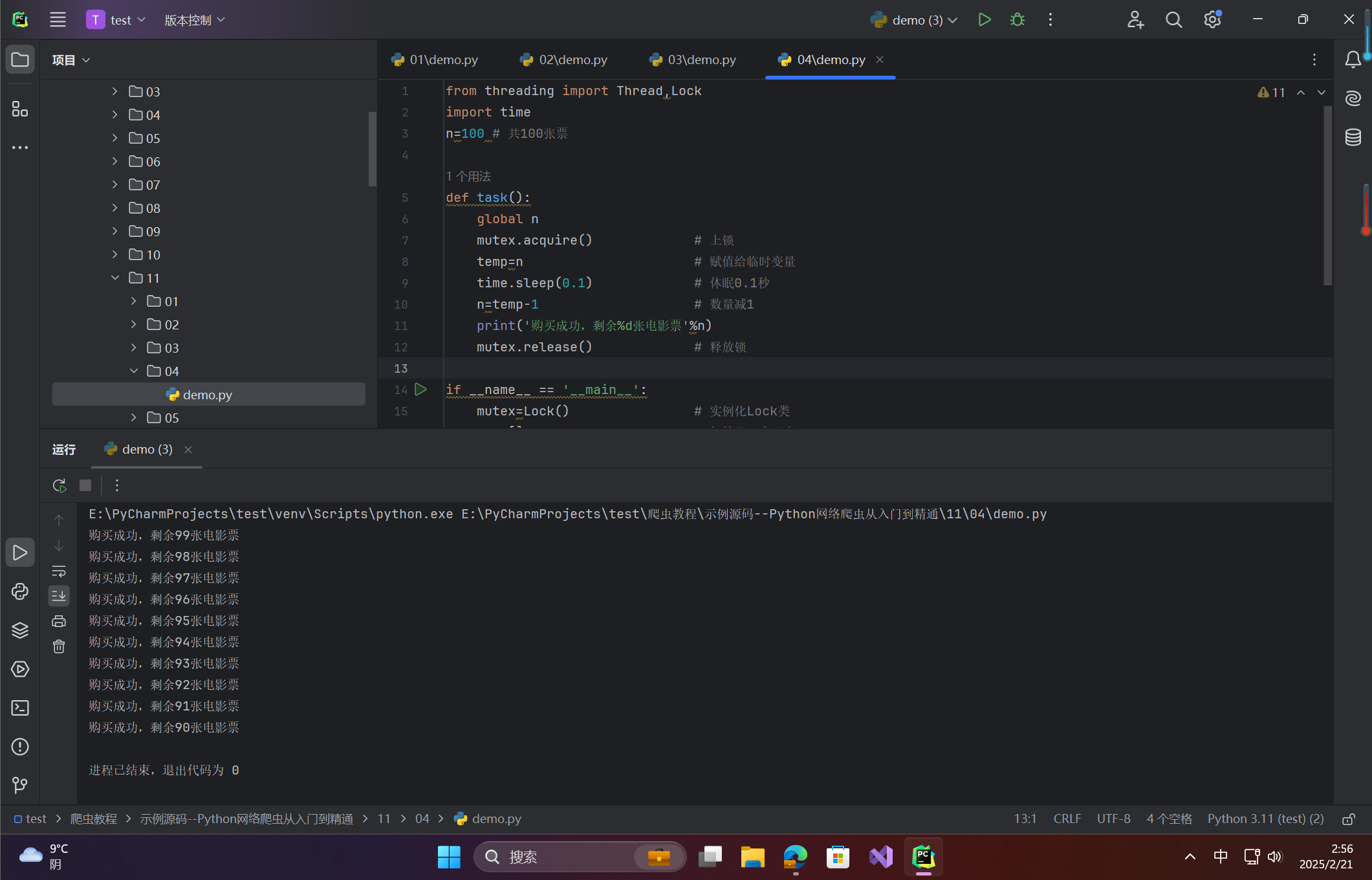
from threading import Thread,Lock import time n=100 # 共100张票 def task(): global n mutex.acquire() # 上锁 temp=n # 赋值给临时变量 time.sleep(0.1) # 休眠0.1秒 n=temp-1 # 数量减1 print('购买成功,剩余%d张电影票'%n) mutex.release() # 释放锁 if __name__ == '__main__': mutex=Lock() # 实例化Lock类 t_l=[] # 初始化一个列表 for i in range(10): t=Thread(target=task) # 实例化线程类 t_l.append(t) # 将线程实例存入列表中 t.start() # 创建线程 for t in t_l: t.join() # 等待子线程结束运行结果:
每次仅一个线程修改票数,最终剩余票数为90。
注意使用互斥锁要避免死锁: 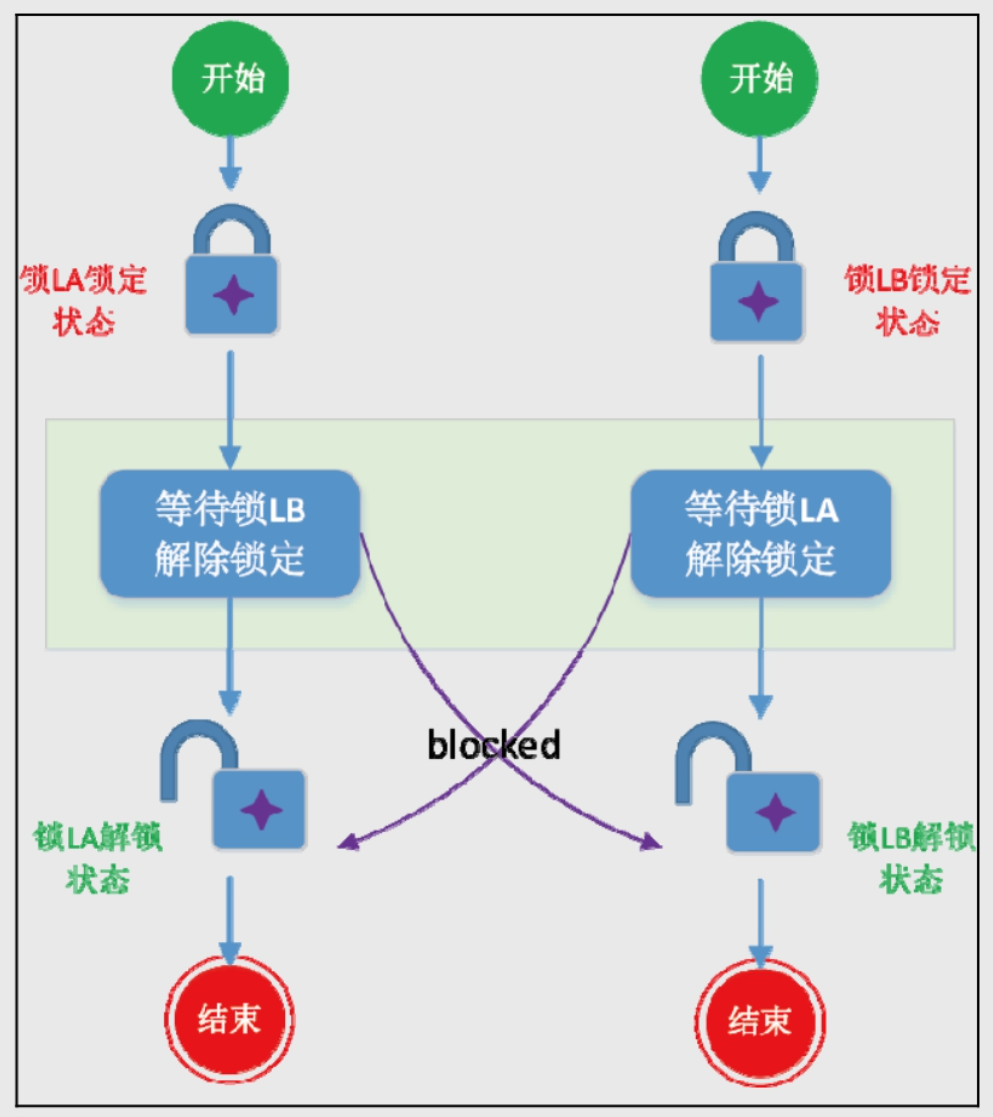
🦋3.3 队列(Queue)
-
特性:线程安全的先进先出(FIFO)数据结构,用于解耦生产者和消费者。
-
示例代码(生产者-消费者模型):
from queue import Queue import random,threading,time # 生产者类 class Producer(threading.Thread): def __init__(self, name,queue): threading.Thread.__init__(self, name=name) self.data=queue def run(self): for i in range(5): print("生产者%s将产品%d加入队列!" % (self.getName(), i)) self.data.put(i) time.sleep(random.random()) print("生产者%s完成!" % self.getName()) # 消费者类 class Consumer(threading.Thread): def __init__(self,name,queue): threading.Thread.__init__(self,name=name) self.data=queue def run(self): for i in range(5): val = self.data.get() print("消费者%s将产品%d从队列中取出!" % (self.getName(),val)) time.sleep(random.random()) print("消费者%s完成!" % self.getName()) if __name__ == '__main__': print('-----主线程开始-----') queue = Queue() # 实例化队列 producer = Producer('Producer',queue) # 实例化线程Producer,并传入队列作为参数 consumer = Consumer('Consumer',queue) # 实例化线程Consumer,并传入队列作为参数 producer.start() # 启动线程Producer consumer.start() # 启动线程Consumer producer.join() # 等待线程Producer结束 consumer.join() # 等待线程Consumer结束 print('-----主线程结束-----')运行结果:
生产者依次将产品加入队列,消费者按顺序取出。
🔎4.关键对比
| 通信方式 | 适用场景 | 特点 |
|---|---|---|
| 全局变量 | 简单数据共享 | 需手动处理竞争(需配合锁) |
| 互斥锁 | 精确控制共享资源访问 | 避免数据混乱,但可能引发死锁 |
| 队列 | 生产者-消费者模型或异步任务处理 | 线程安全,天然解决资源竞争问题 |
🔎5.注意事项
-
死锁:多个线程互相等待对方释放锁时发生。 -
避免方法:按固定顺序加锁,或使用超时机制。
-
-
全局变量:线程间共享方便,但需谨慎处理竞争条件。
通过上述机制,可实现线程间的数据同步与协作。

- 点赞
- 收藏
- 关注作者
评论(0)