【愚公系列】《Python网络爬虫从入门到精通》022-Splash的爬虫应用

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在当今互联网技术飞速发展的时代,网页数据的提取变得愈发复杂。许多网站使用JavaScript来动态生成内容,这使得传统爬虫工具难以有效抓取所需数据。而Splash,一个基于Python的JavaScript渲染服务,提供了一种解决方案,使得我们能够轻松处理这些动态网页。
在本期文章中,我们将深入探讨Splash的爬虫应用。我们将介绍Splash的基本概念、安装与配置,以及如何利用它进行网页抓取。通过实际案例,我们将演示如何使用Splash处理JavaScript生成的内容,提取所需信息,并展示如何将其与其他爬虫框架结合使用,提升数据抓取的效率和准确性。
🚀一、Splash的爬虫应用
Splash 是一个基于 JavaScript 渲染的轻量级 Web 浏览器服务,提供 HTTP API 接口。通过 Python 调用其 API 或 Lua 脚本,可实现动态渲染页面的爬取。
🔎1.搭建 Splash 环境(Windows 10 系统)
依赖工具:Docker(仅支持 Windows 10 专业版/企业版 64 位)
安装步骤
-
安装 Docker
-
访问 ,下载 Docker Desktop Installer.exe。 -
安装时需开启 Hyper-V 功能。
-
-
安装 Splash
-
打开命令提示符,执行以下命令: docker pull scrapinghub/splash
-
-
启动 Splash 服务
docker run -p 8050:8050 scrapinghub/splash-
访问 可进入 Splash 测试页面。
-
 3. 测试 Splash 服务
3. 测试 Splash 服务
-
访问 单击“Render me!”按钮,将显示如图所示的渲染页面。
 在这里插入图片描述
在这里插入图片描述
🔎2.Splash 的 HTTP API
🦋2.1 render.html 接口
功能:获取 JavaScript 渲染后的 HTML
请求地址:
示例:获取百度首页 Logo 链接
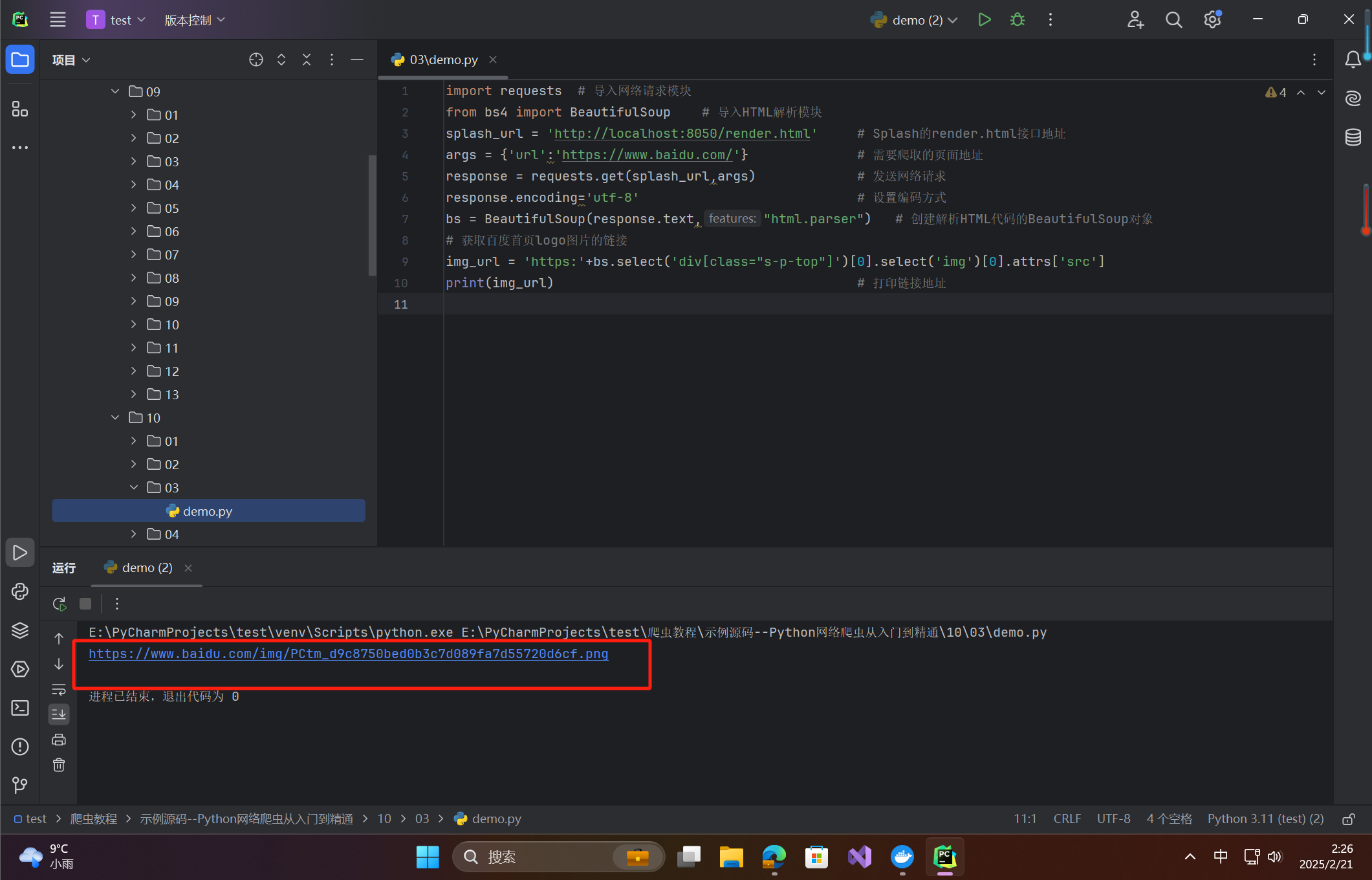
import requests # 导入网络请求模块
from bs4 import BeautifulSoup # 导入HTML解析模块
splash_url = 'http://localhost:8050/render.html' # Splash的render.html接口地址
args = {'url':'https://www.baidu.com/'} # 需要爬取的页面地址
response = requests.get(splash_url,args) # 发送网络请求
response.encoding='utf-8' # 设置编码方式
bs = BeautifulSoup(response.text,"html.parser") # 创建解析HTML代码的BeautifulSoup对象
# 获取百度首页logo图片的链接
img_url = 'https:'+bs.select('div[class="s-p-top"]')[0].select('img')[0].attrs['src']
print(img_url) # 打印链接地址
 在这里插入图片描述
在这里插入图片描述
除了url下面是render.html 接口常用的参数: 
🦋2.2 render.png 接口
功能:获取网页截图
请求地址:
示例:保存百度首页截图
import requests # 导入网络请求模块
splash_url = 'http://localhost:8050/render.png' # Splash的render.png接口地址
args = {'url':'https://www.baidu.com/','width':1280,'height':800} # 需要爬取的页面地址
response = requests.get(splash_url,args) # 发送网络请求
with open('baidu.png','wb') as f: # 调用open函数
f.write(response.content) # 将返回的二进制数据保存成图片
🦋3.3 render.json 接口
功能:获取页面元数据(URL、标题、尺寸等)
请求地址:
示例:获取页面 JSON 信息
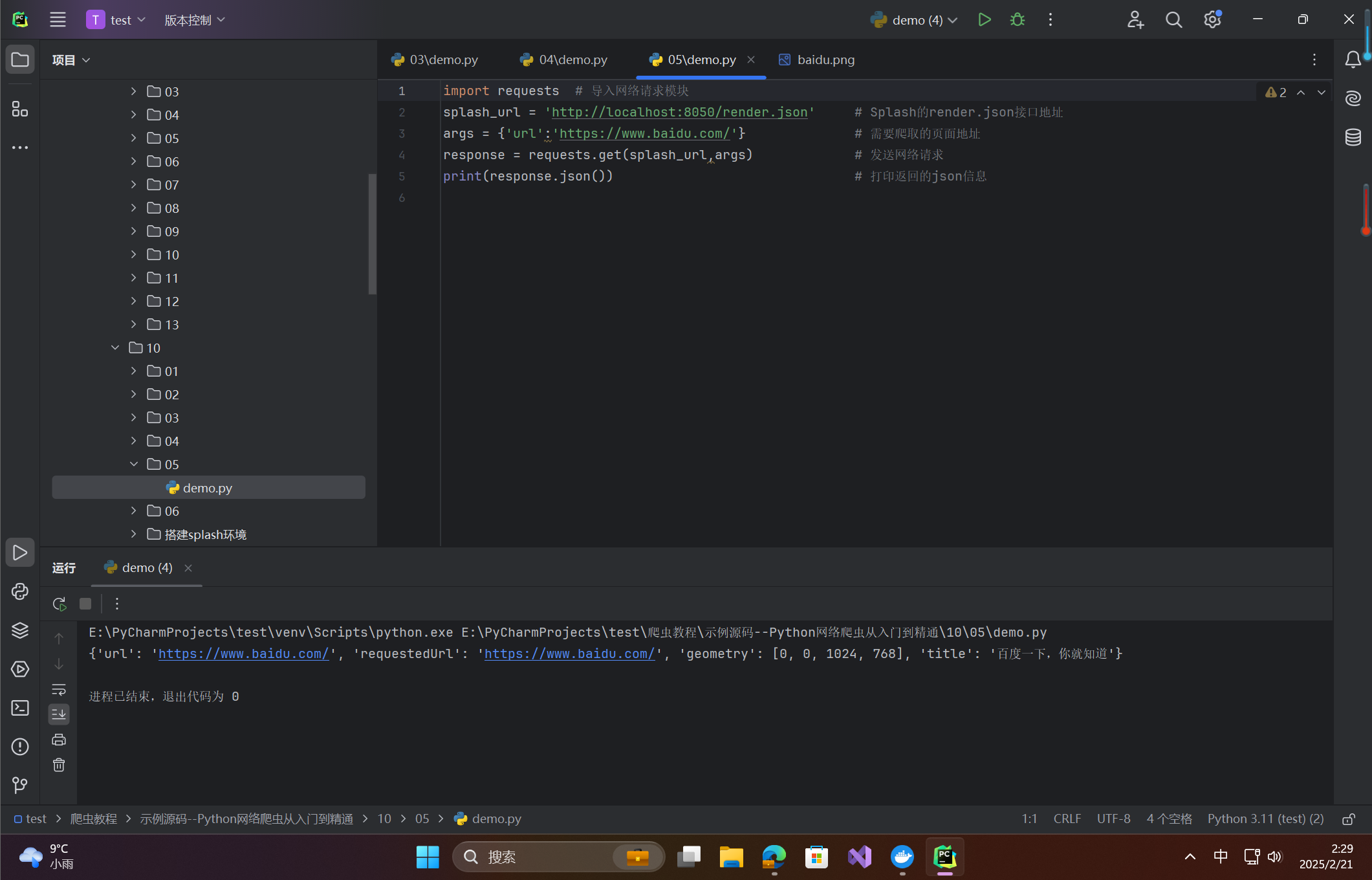
import requests # 导入网络请求模块
splash_url = 'http://localhost:8050/render.json' # Splash的render.json接口地址
args = {'url':'https://www.baidu.com/'} # 需要爬取的页面地址
response = requests.get(splash_url,args) # 发送网络请求
print(response.json()) # 打印返回的json信息
 在这里插入图片描述
在这里插入图片描述
🔎3.执行 Lua 自定义脚本
接口:execute
功能:通过 Lua 脚本控制渲染逻辑
示例:获取百度首页渲染后的 HTML
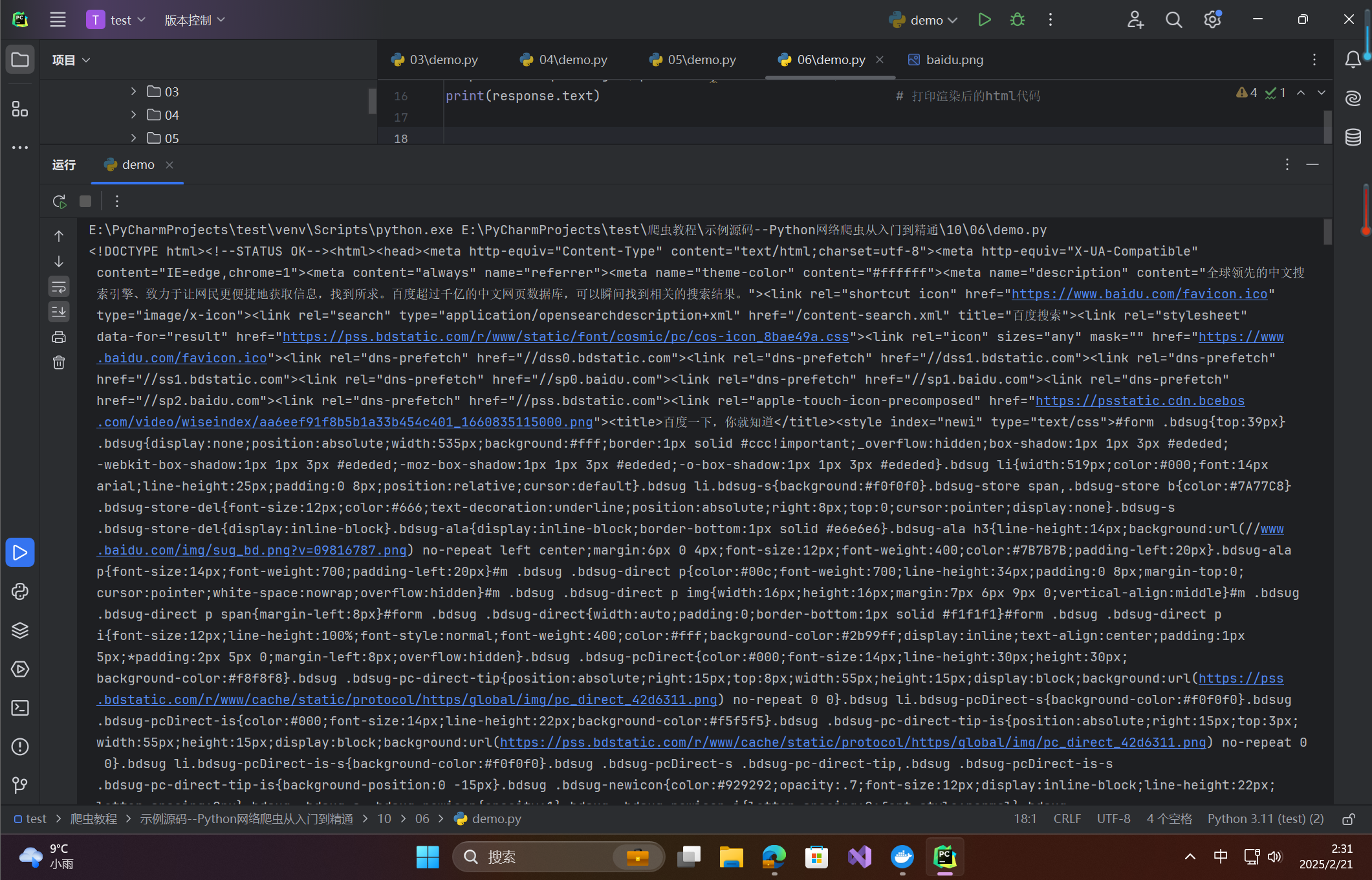
import requests # 导入网络请求模块
from urllib.parse import quote # 导入quote方法
# 自定义的lua脚本
lua_script = '''
function main(splash)
splash:go("https://www.baidu.com/")
splash:wait(0.5)
return splash:html()
end
'''
splash_url = 'http://localhost:8050/execute?lua_source='+ quote(lua_script) # Splash的execute接口地址
# 定义headers信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
response = requests.get(splash_url,headers=headers) # 发送网络请求
print(response.text) # 打印渲染后的html代码
 在这里插入图片描述
在这里插入图片描述
Lua 脚本常用方法: 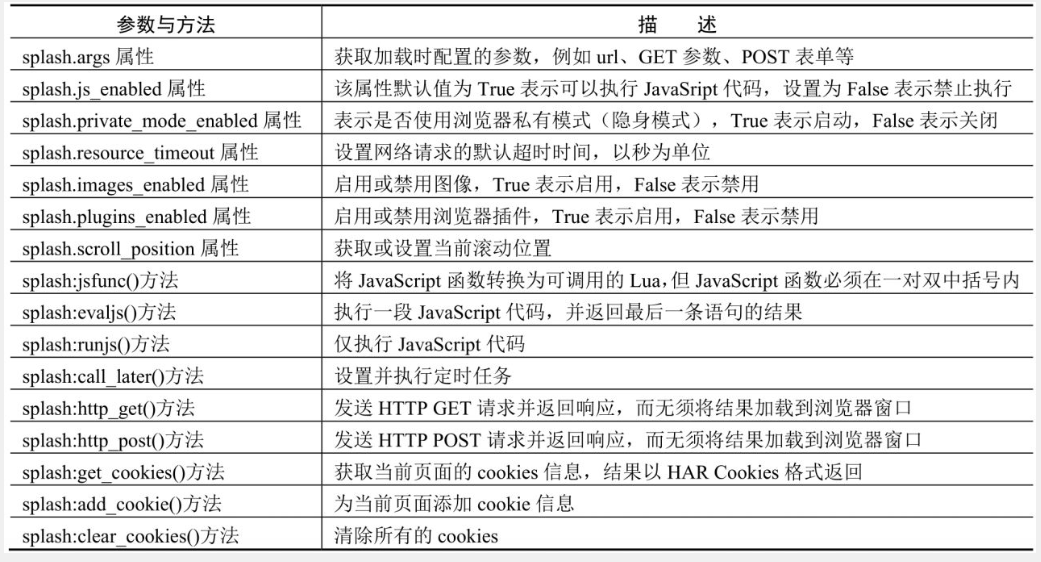
注意事项
-
每次重启后需重新运行 docker run命令启动 Splash。 -
完整 API 文档:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)