【愚公系列】《Python网络爬虫从入门到精通》021-爬取动态渲染信息(Selenium数据的爬取)

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在现代网络数据采集中,许多网站采用了复杂的JavaScript脚本和动态加载技术,使得传统的爬虫工具难以有效提取数据。这时,Selenium这个强大的自动化测试工具便成为了数据爬取的理想选择。它不仅可以模拟用户在浏览器中的操作,还能够处理动态网页,轻松抓取那些通过Ajax或JavaScript生成的数据。
在本期文章中,我们将深入探讨如何使用Selenium进行数据的爬取。我们将介绍Selenium的基本使用方法,包括如何设置环境、启动浏览器、定位元素以及提取所需的信息等。通过生动的实例,我们将展示如何利用Selenium处理复杂的网页,帮助你快速上手并掌握数据提取的技巧。
🚀一、Selenium数据的爬取
🔎1.Selenium 简介
-
作用:浏览器自动化测试框架,可模拟用户操作(点击、滚动、输入等),获取动态渲染的页面内容。 -
适用场景:爬取通过 JavaScript 动态加载的网页(如无限滚动、点击加载更多)。 -
支持浏览器:Chrome、Firefox、Edge 等。 -
核心功能: -
控制浏览器行为(打开页面、点击按钮、输入文本)。 -
获取页面源代码(包含动态生成的内容)。 -
定位并提取网页元素。
-
🔎2.环境配置
🦋2.1 安装 Selenium 模块
pip install selenium
🦋2.2 下载浏览器驱动
-
Chrome 驱动: -
访问,下载与本地浏览器版本匹配的驱动。 -
解压 chromedriver.exe并保存到 Python 安装目录(如C:\Python\Scripts\)。
-
🔎3.基础使用示例
示例:获取京东商品信息
from selenium import webdriver # 导入浏览器驱动模块
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
from selenium.webdriver.common.by import By # 节点定位
try:
# 创建谷歌浏览器驱动参数对象
chrome_options = webdriver.ChromeOptions()
# 不加载图片
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# # 使用headless无界面浏览器模式
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# 加载谷歌浏览器驱动
driver = webdriver.Chrome(options=chrome_options)
# 请求地址
driver.get('https://item.jd.com/12353915.html')
wait = WebDriverWait(driver,10) # 等待10秒
# 等待页面加载class名称为m-item-inner的节点,该节点中包含商品信息
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"m-item-inner")))
# 获取name节点中所有div节点
name_div = driver.find_element_by_css_selector('#name').find_elements_by_tag_name('div')
summary_price = driver.find_element_by_id('summary-price')
print('提取的商品标题如下:')
print(name_div[0].text) # 打印商品标题
print('提取的商品宣传语如下:')
print(name_div[1].text) # 打印宣传语
print('提取的编著信息如下:')
print(name_div[4].text) # 打印编著信息
print('提取的价格信息如下:')
print(summary_price.text) # 打印价格信息
driver.quit() # 退出浏览器驱动
except Exception as e:
print('显示异常信息!', e)
 注意:现在京东会自动检测是否为Selenium,跳到403页面,需要自己改版。
注意:现在京东会自动检测是否为Selenium,跳到403页面,需要自己改版。
🔎4.Selenium 常用方法
🦋4.1 元素定位方法
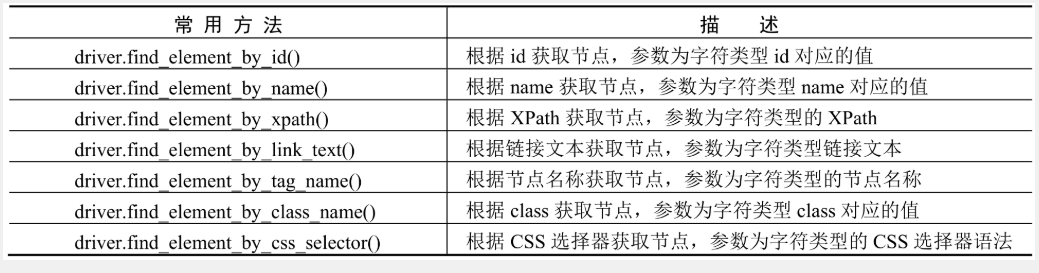 上面都是单节点获取方法,需要多节点加个s就行,也可以采用下面方法:
上面都是单节点获取方法,需要多节点加个s就行,也可以采用下面方法:
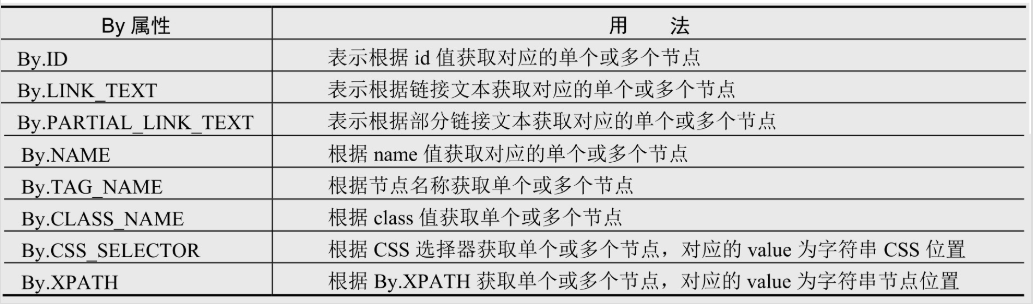 在这里插入图片描述
在这里插入图片描述
🦋4.2 显式等待与隐式等待
-
显式等待:指定条件,等待直到满足条件或超时。 from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # 等待元素可见 element = WebDriverWait(driver, 10).until( EC.visibility_of_element_located((By.ID, 'target-id')) ) -
隐式等待:全局等待时间,适用于所有元素查找。 driver.implicitly_wait(10) # 单位:秒
🦋4.3 操作浏览器
driver.get('https://example.com') # 打开网页
driver.refresh() # 刷新页面
driver.back() # 返回上一页
driver.forward() # 前进下一页
driver.save_screenshot('page.png') # 截图
🦋4.4 元素交互
element.click() # 点击元素
element.send_keys('text')# 输入文本
element.clear() # 清空输入框
element.submit() # 提交表单
🦋4.5 获取元素属性
href = element.get_attribute('href') # 获取属性值
text = element.text # 获取元素文本
tag = element.tag_name # 获取标签名
🔎5.高级配置
🦋5.1 无头模式 (Headless)
chrome_options.add_argument('--headless') # 不显示浏览器窗口
chrome_options.add_argument('--disable-gpu') # 禁用 GPU
🦋5.2 绕过反爬检测
# 禁用自动化测试标识(避免被网站识别为爬虫)
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
🦋5.3 代理设置
chrome_options.add_argument('--proxy-server=http://127.0.0.1:8080')
🔎6.注意事项
-
驱动版本匹配:确保 ChromeDriver 与浏览器版本一致。 -
资源释放:使用 driver.quit()关闭浏览器,避免内存泄漏。 -
反爬策略:合理设置等待时间,避免高频请求触发反爬。 -
动态内容加载:使用显式等待确保元素加载完成。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)