【愚公系列】《Python网络爬虫从入门到精通》020-爬取动态渲染信息(Ajax数据的爬取)

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在当今的互联网时代,动态网页已经成为了常态,许多网站使用Ajax技术来异步加载数据,这使得我们在进行数据爬取时面临着新的挑战。与传统的静态网页不同,Ajax请求通常不会直接在HTML源代码中显示出所需的数据,这就要求我们采取更灵活的方法来获取这些信息。
本期文章将带你深入了解Ajax数据的爬取技巧。我们将探讨Ajax原理和工作方式,以及如何使用Python等工具有效地抓取由Ajax动态加载的数据。通过具体的案例,我们将演示如何分析网络请求、构造请求参数,并提取我们所需的内容,以帮助你在面对动态网页时游刃有余。
🚀一、Ajax数据的爬取
🔎1.Ajax技术简介
-
定义:Ajax(Asynchronous JavaScript and XML)是一种异步数据交互技术,无需刷新页面即可从服务器获取数据并更新网页内容。 -
特点:动态加载数据,页面URL不变,数据通常以JSON格式传输。 -
爬取难点:数据通过JavaScript动态生成,需直接分析网络请求获取数据接口。
🔎2.分析Ajax请求地址
 在这里插入图片描述
在这里插入图片描述
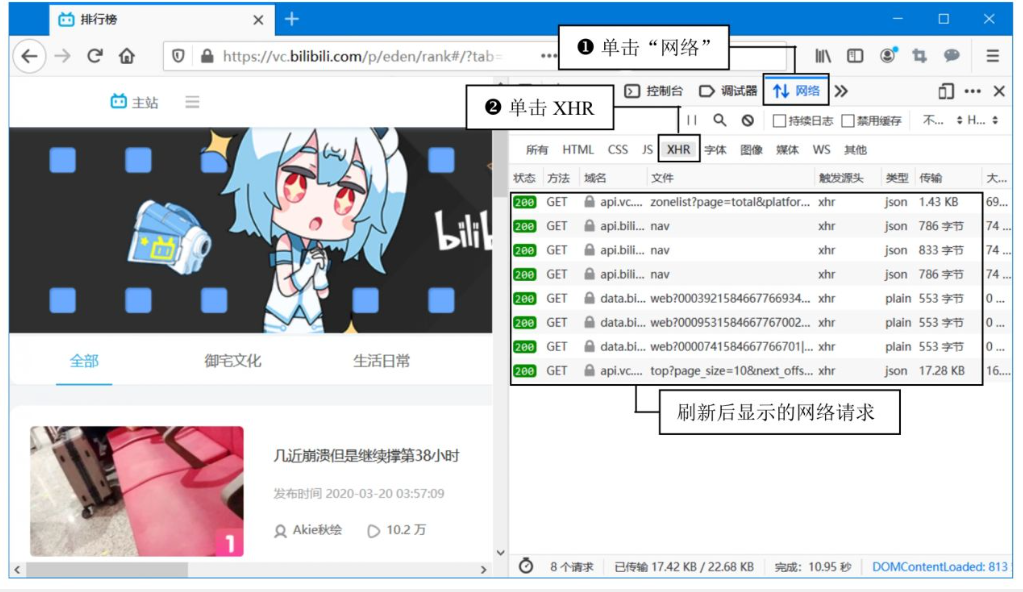
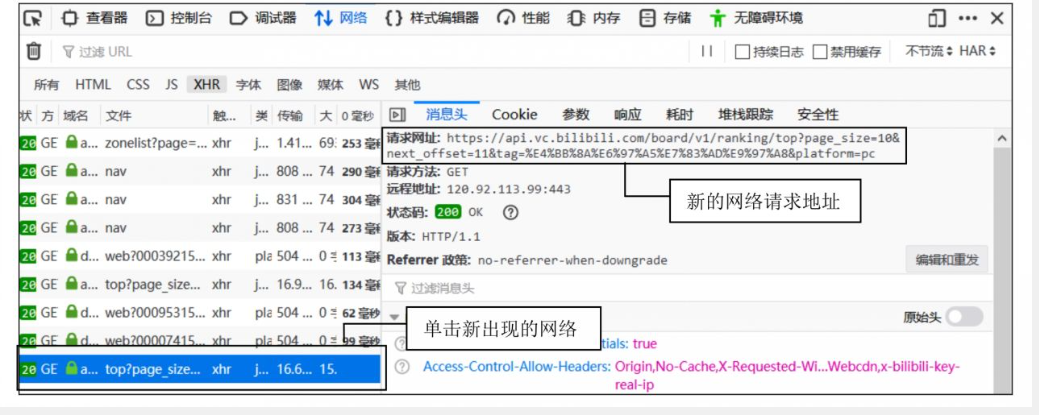
步骤1:定位动态请求
-
打开开发者工具:浏览器中按 F12,切换到 Network(网络监视器)。 -
筛选XHR请求:在请求类型中选择 XHR(Ajax请求通常在此分类)。 -
刷新页面:按 F5重新加载页面,观察新增的网络请求。 -
查找数据接口: -
逐个点击请求,查看 Response(响应数据)中是否包含页面显示的内容(如视频标题、发布时间)。 -
确认目标接口: anking/top。
-
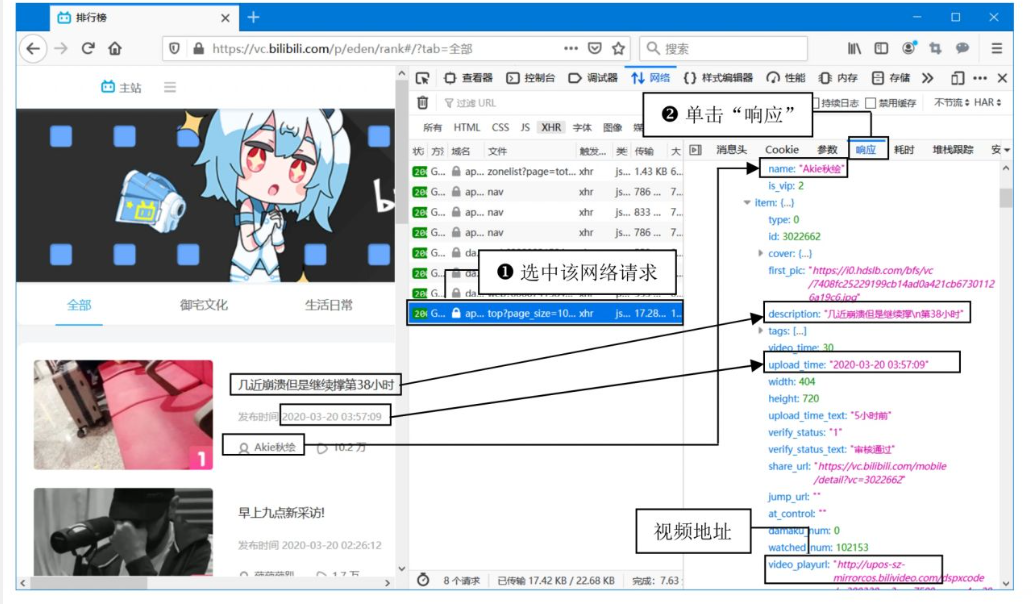
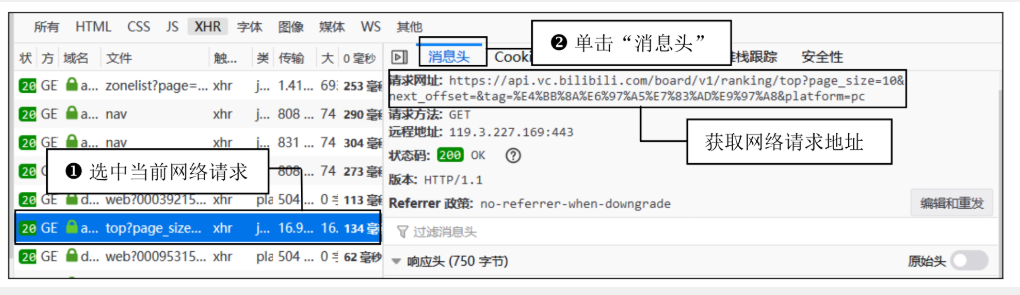
步骤2:分析分页规律
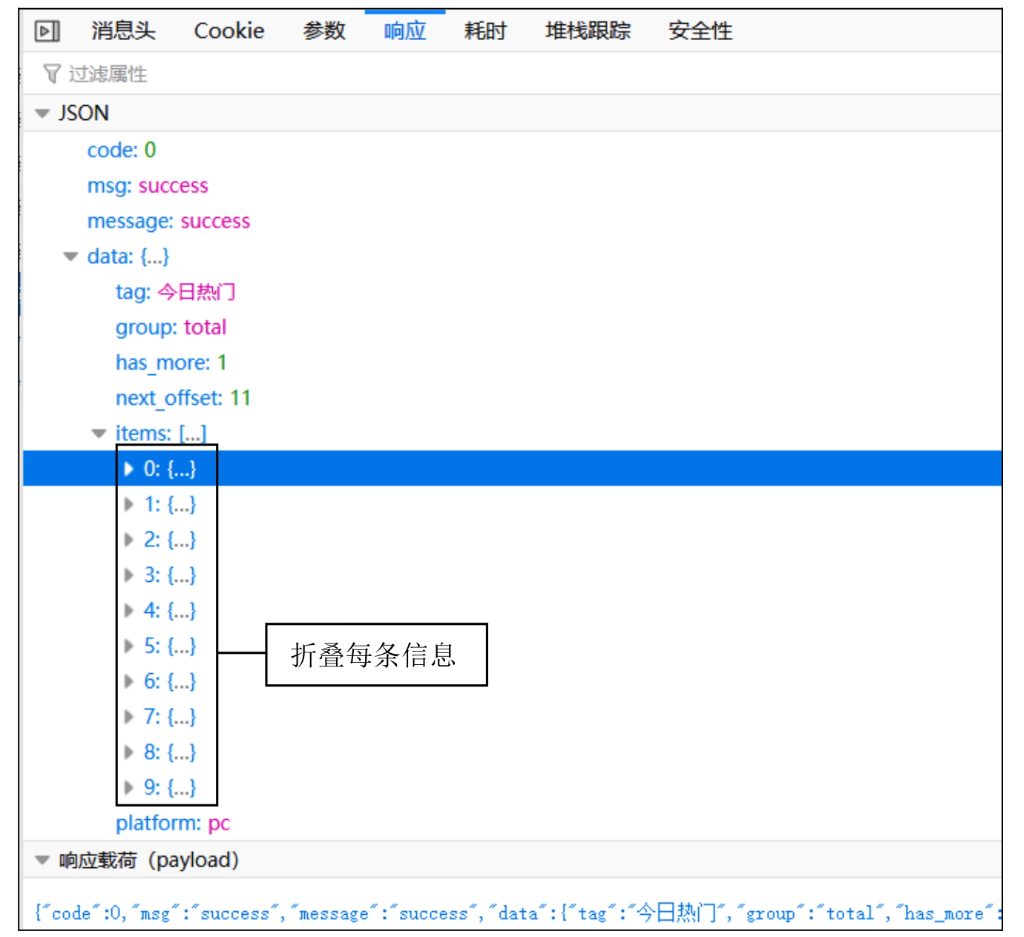
-
请求参数: page_size=10 # 每页返回10条数据 next_offset=0 # 起始偏移量(第一页无参数或为0) next_offset=11 # 第二页偏移量(上一页最后一条数据的偏移量+1) next_offset=21 # 第三页偏移量(依此类推) -
规律:每页请求的 next_offset递增page_size(即第n页的偏移量为10*(n-1))。
🔎3.编写爬虫程序
import requests # 网络请求模块
import time # 时间模块
import random # 随机模块
import os # 操作系统模块
import re # 正则表达式
# 哔哩哔哩小视频json地址
json_url = 'http://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset={page}1&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc'
class Crawl():
def __init__(self):
# 创建头部信息
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'}
def get_json(self, json_url):
response = requests.get(json_url, headers=self.headers)
# 判断请求是否成功
if response.status_code == 200:
return response.json() # 返回json信息
else:
print('获取json信息的请求没有成功!')
#下载视频
def download_video(self,video_url,titlename):
# 下载视频的网络请求
response = requests.get(video_url, headers=self.headers, stream=True)
if not os.path.exists('video'): # 如果video目录不存在时
os.mkdir('video') # 创建该目录
if response.status_code == 200: # 判断请求是否成功
if os.path.exists('video'):
with open('video/'+titlename+'.mp4', 'wb')as f: # 将视频写入指定位置
for data in response.iter_content(chunk_size=1024): # 循环写入,实现一段一段的写
f.write(data) # 写入视频文件
f.flush() # 刷新缓存
print('下载完成!')
else:
print('视频下载失败!')
if __name__ == '__main__':
c = Crawl() # 创建爬虫类对象
for page in range(0,10): # 循环请求10页每页10组数据
json = c.get_json(json_url.format(page=page)) # 获取返回的json数据
infos = json['data']['items'] # 信息集
for info in infos: # 遍历信息
title = info['item']['description'] # 视频标题
# 只保留标题中英文、数字与汉字,其它符号会影响写入文件
comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
title = comp.sub('', title) # 将不符合条件的符号替换为空
video_url = info['item']['video_playurl'] # 视频地址
print(title,video_url) # 打印提取的视频标题与视频地址
c.download_video(video_url, title) # 下载视频,视频标题作为视频的名字
time.sleep(random.randint(3, 6)) # 随机产生获取json请求的间隔时间
🔎4.关键代码解析
-
请求头模拟:
-
添加 User-Agent伪装浏览器,绕过基础反爬机制。
-
-
分页参数处理:
-
通过 next_offset动态生成每页的请求地址,实现循环翻页。
-
-
视频下载优化:
-
使用 stream=True分块下载大文件,避免内存溢出。 -
正则表达式清理标题中的非法字符(如 /,:),确保文件可保存。
-
-
反爬策略:
-
随机延时( time.sleep(random.uniform(1, 3)))降低请求频率。 -
错误处理:检查HTTP状态码,避免程序崩溃。
-
🔎5.注意事项
-
反爬机制:
-
B站可能限制高频请求,需增加代理IP或降低爬取速度。 -
若返回 403 Forbidden,检查请求头是否完整(如添加Referer)。
-
-
接口变动:
-
Ajax接口可能随网站改版更新,需定期检查接口地址和参数。
-
-
数据合法性:
-
遵守网站Robots协议,仅爬取公开数据,避免侵犯版权。
-
🔎6.扩展功能
-
多线程下载:
-
使用 threading或concurrent.futures加速视频下载。
-
-
元数据存储:
-
将视频标题、发布时间、播放量等存入数据库(如SQLite、MySQL)。
-
-
断点续传:
-
记录已下载的视频标题,避免重复爬取。
-

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)