【愚公系列】《Python网络爬虫从入门到精通》018-使用 BeautifulSoup 方法获取内容

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据分析和网络爬虫的领域,提取网页信息是一个至关重要的技能。随着Python的广泛应用,BeautifulSoup作为一个功能强大且易于使用的库,成为了开发者和数据科学家们的首选工具之一。它能够帮助我们快速解析HTML和XML文档,并轻松获取我们需要的网页内容。
在本期文章中,我们将深入探讨使用BeautifulSoup的方法,重点指导大家如何高效获取网页中的各种内容。我们将介绍BeautifulSoup的基本用法,包括如何加载网页、查找节点、提取文本和属性等具体操作。通过实际的示例,读者将能够直观地了解如何应用这些方法,从而在自己的项目中实现数据提取的目标。
🚀一、使用 BeautifulSoup 方法获取内容
🔎1.find_all() 方法
用于获取 所有符合条件 的节点内容,返回 bs4.element.ResultSet 对象(类似列表)。
语法格式
find_all(name=None, attrs={}, recursive=True, text=None, limit=None, kwargs)
🦋1.1 name 参数
通过 标签名称 匹配节点。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
<body>
<p class="p-1" value = "1"><a href="https://item.jd.com/12353915.html">零基础学Python</a></p>
<p class="p-2" value = "2"><a href="https://item.jd.com/12451724.html">Python从入门到项目实践</a></p>
<p class="p-3" value = "3"><a href="https://item.jd.com/12512461.html">Python项目开发案例集锦</a></p>
<div class="div-2" value = "4"><a href="https://item.jd.com/12550531.html">Python编程锦囊</a></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
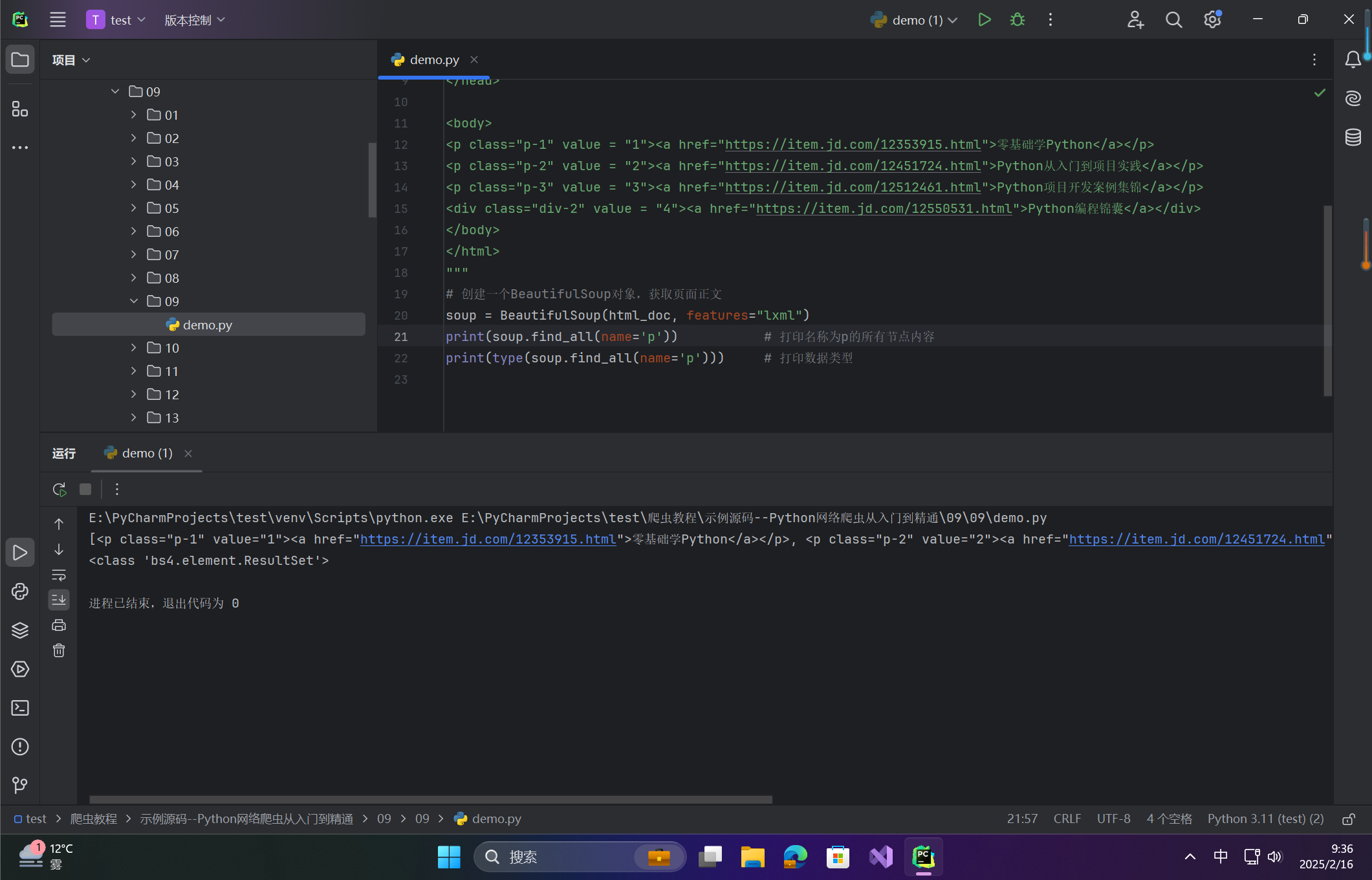
print(soup.find_all(name='p')) # 打印名称为p的所有节点内容
print(type(soup.find_all(name='p'))) # 打印数据类型
 在这里插入图片描述
在这里插入图片描述
嵌套查找:
first_p = p_tags[0] # 获取第一个 <p> 标签
a_tag = first_p.find_all(name='a') # 在第一个 <p> 中查找 <a> 标签
🦋1.2 attrs 参数
通过 属性 匹配节点,支持字典或直接赋值。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
<body>
<p class="p-1" value = "1"><a href="https://item.jd.com/12353915.html">零基础学Python</a></p>
<p class="p-1" value = "2"><a href="https://item.jd.com/12451724.html">Python从入门到项目实践</a></p>
<p class="p-3" value = "3"><a href="https://item.jd.com/12512461.html">Python项目开发案例集锦</a></p>
<div class="div-2" value = "4"><a href="https://item.jd.com/12550531.html">Python编程锦囊</a></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
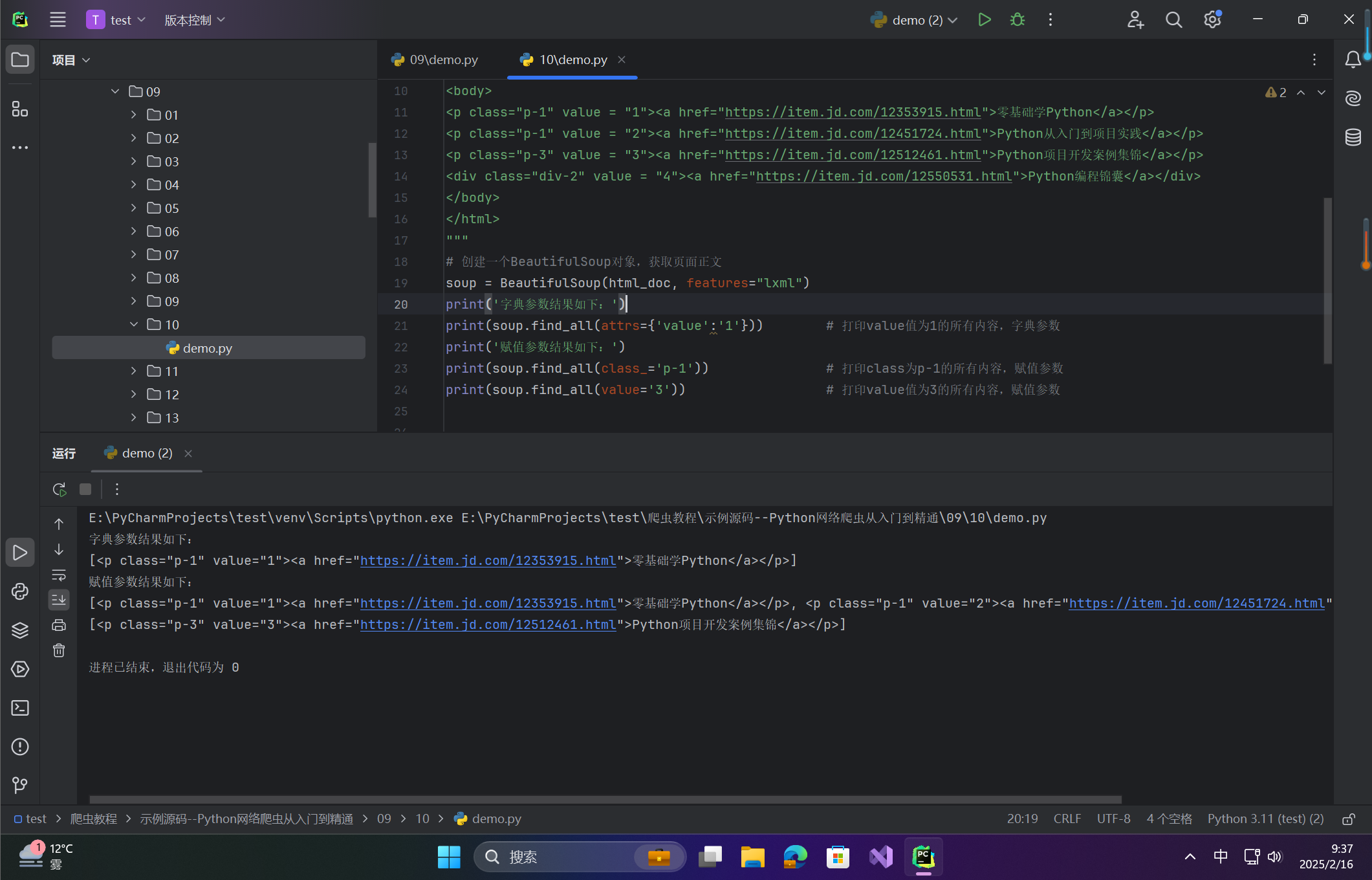
print('字典参数结果如下:')
print(soup.find_all(attrs={'value':'1'})) # 打印value值为1的所有内容,字典参数
print('赋值参数结果如下:')
print(soup.find_all(class_='p-1')) # 打印class为p-1的所有内容,赋值参数
print(soup.find_all(value='3')) # 打印value值为3的所有内容,赋值参数
 在这里插入图片描述
在这里插入图片描述
注意:
-
class需写成class_(避免与Python关键字冲突)。
🦋1.3 text 参数
通过 文本内容 匹配节点,支持字符串或正则表达式。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
import re # 导入正则表达式模块
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
<body>
<p class="p-1" value = "1"><a href="https://item.jd.com/12353915.html">零基础学Python</a></p>
<p class="p-1" value = "2"><a href="https://item.jd.com/12451724.html">Python从入门到项目实践</a></p>
<p class="p-3" value = "3"><a href="https://item.jd.com/12512461.html">Python项目开发案例集锦</a></p>
<div class="div-2" value = "4"><a href="https://item.jd.com/12550531.html">Python编程锦囊</a></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
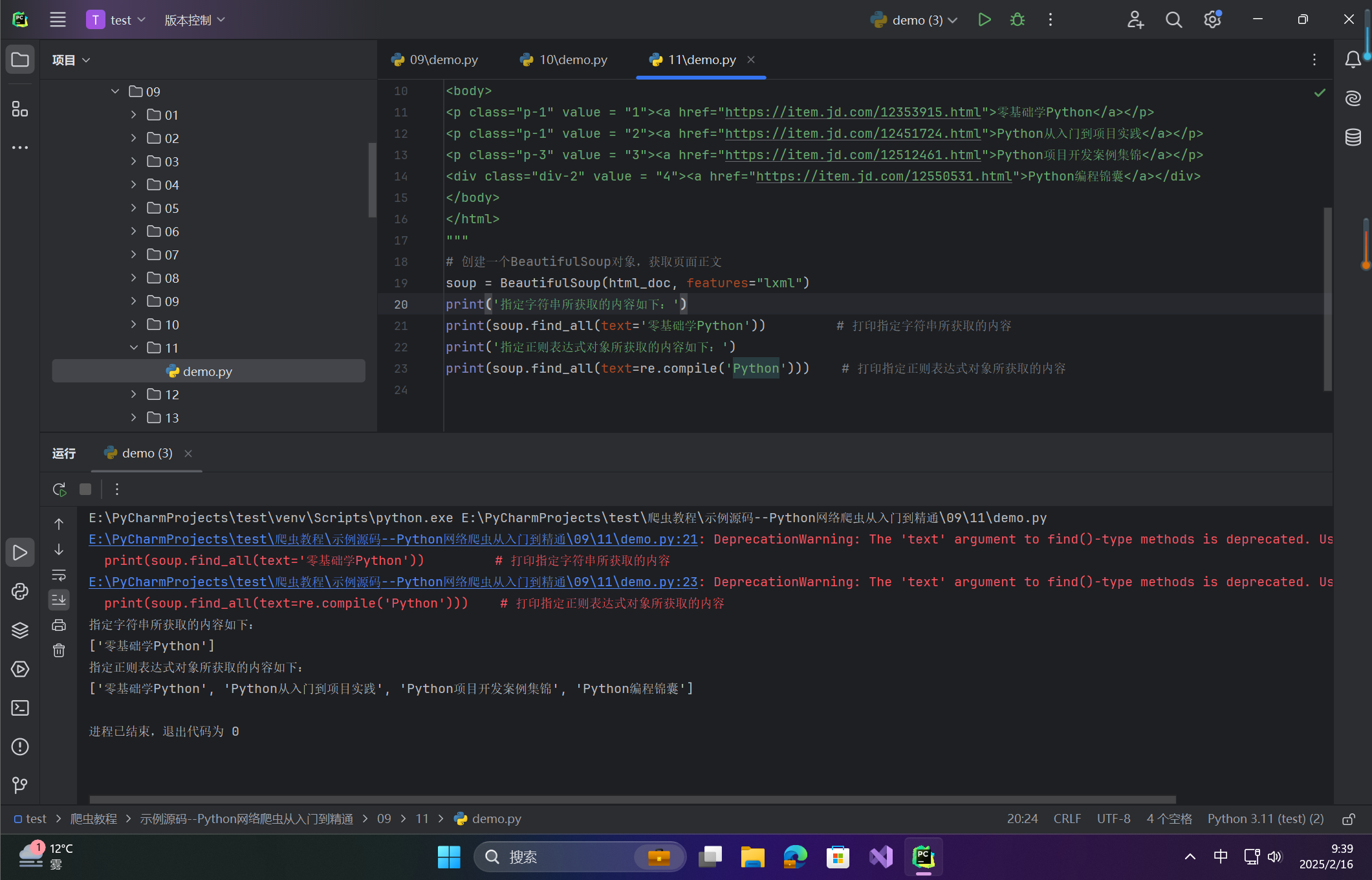
print('指定字符串所获取的内容如下:')
print(soup.find_all(text='零基础学Python')) # 打印指定字符串所获取的内容
print('指定正则表达式对象所获取的内容如下:')
print(soup.find_all(text=re.compile('Python'))) # 打印指定正则表达式对象所获取的内容
 在这里插入图片描述
在这里插入图片描述
🔎2.find() 方法
用于获取 第一个匹配 的节点内容,返回 bs4.element.Tag 对象。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
import re # 导入正则表达式模块
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
<body>
<p class="p-1" value = "1"><a href="https://item.jd.com/12353915.html">零基础学Python</a></p>
<p class="p-1" value = "2"><a href="https://item.jd.com/12451724.html">Python从入门到项目实践</a></p>
<p class="p-3" value = "3"><a href="https://item.jd.com/12512461.html">Python项目开发案例集锦</a></p>
<div class="div-2" value = "4"><a href="https://item.jd.com/12550531.html">Python编程锦囊</a></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
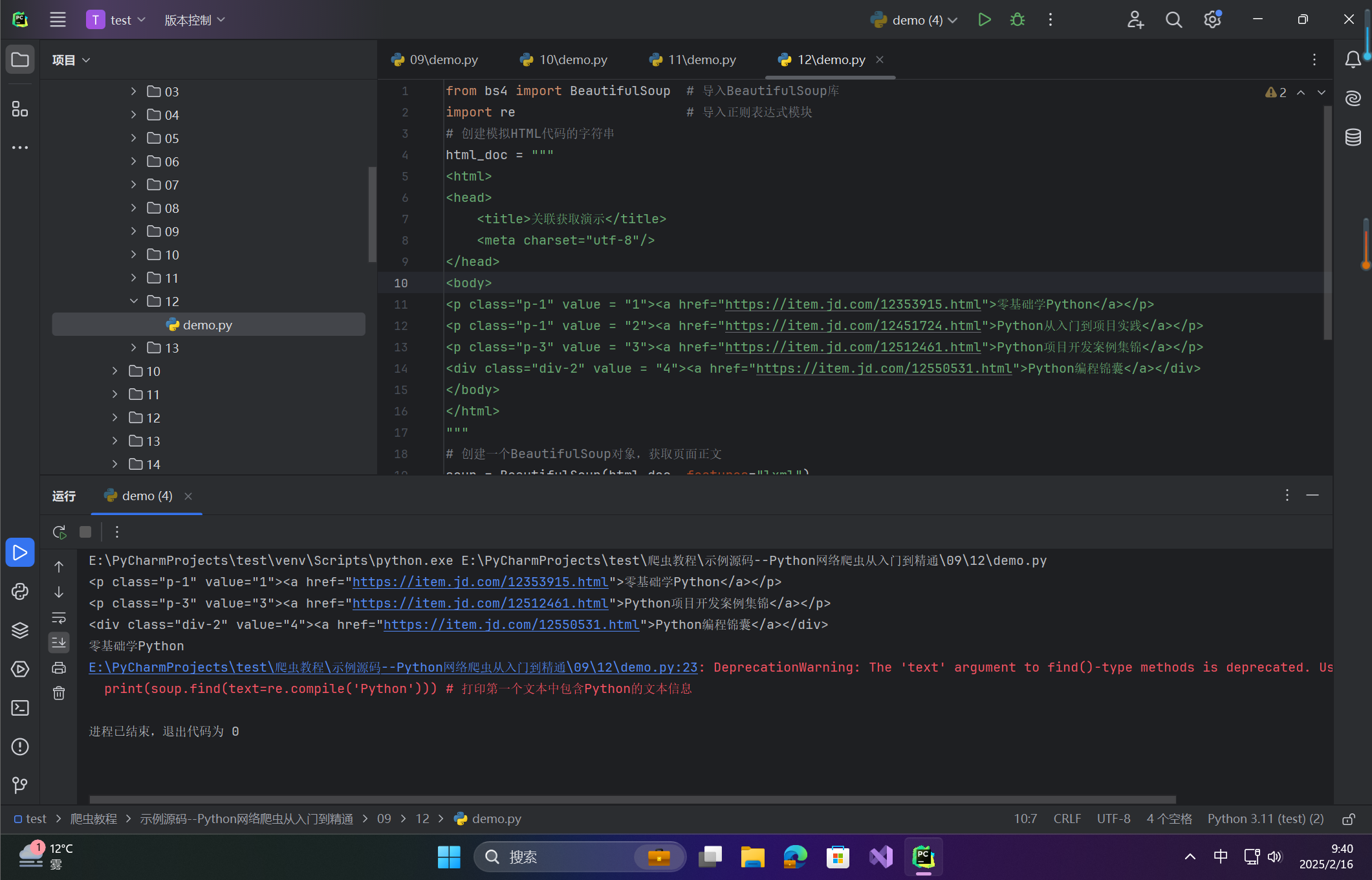
print(soup.find(name='p')) # 打印第一个name为p的节点内容
print(soup.find(class_='p-3')) # 打印第一个class为p-3的节点内容
print(soup.find(attrs={'value':'4'})) # 打印第一个value为4的节点内容
print(soup.find(text=re.compile('Python'))) # 打印第一个文本中包含Python的文本信息
 在这里插入图片描述
在这里插入图片描述
🔎3.其他方法
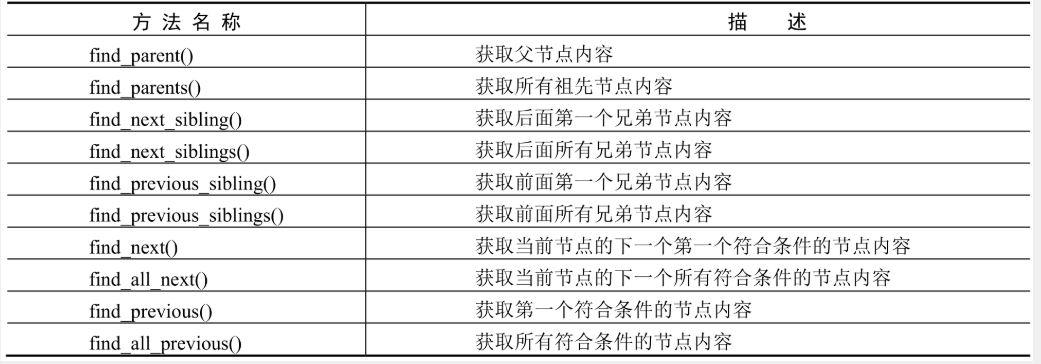 在这里插入图片描述
在这里插入图片描述
🔎4.关键区别
| 方法 | 返回结果类型 | 特点 |
|---|---|---|
find_all |
bs4.element.ResultSet |
返回所有匹配的节点 |
find |
bs4.element.Tag |
返回第一个匹配节点 |
🔎5.注意事项
-
参数优先级: name和attrs可组合使用。 -
正则表达式:通过 re.compile()实现模糊匹配。 -
性能优化:使用 limit参数限制返回结果数量。 -
动态内容:无法处理JavaScript动态生成的内容,需结合Selenium等工具。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)