【愚公系列】《Python网络爬虫从入门到精通》017-使用 BeautifulSoup 获取节点内容

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在网络爬虫和数据分析的过程中,从网页中提取信息是我们最核心的任务之一。而当提到网页解析,BeautifulSoup无疑是Python中最受欢迎的库之一。它以其简单直观的接口,帮助开发者轻松地从复杂的HTML和XML文档中获取所需的节点内容。
在本期文章中,我们将专注于使用BeautifulSoup获取节点内容的技巧与方法。我们将详细介绍如何通过BeautifulSoup解析网页,定位特定的节点,并提取其中的文本、属性等信息。通过实际的示例,我们将展示如何在真实的项目中应用这些技巧,帮助你快速上手并掌握数据提取的关键技能。
🚀一、使用 BeautifulSoup 获取节点内容
🔎1.获取节点对应的代码
方法:直接调用节点名称
特性:若有多个同名节点,默认返回第一个。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>第一个 HTML 页面</title>
</head>
<body>
<p>body 元素的内容会显示在浏览器中。</p>
<p>title 元素的内容会显示在浏览器的标题栏中。</p>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('head节点内容为:\n',soup.head) # 打印head节点
print('body节点内容为:\n',soup.body) # 打印body节点
print('title节点内容为:\n',soup.title) # 打印title节点
print('p节点内容为:\n',soup.p) # 打印p节点
运行结果: 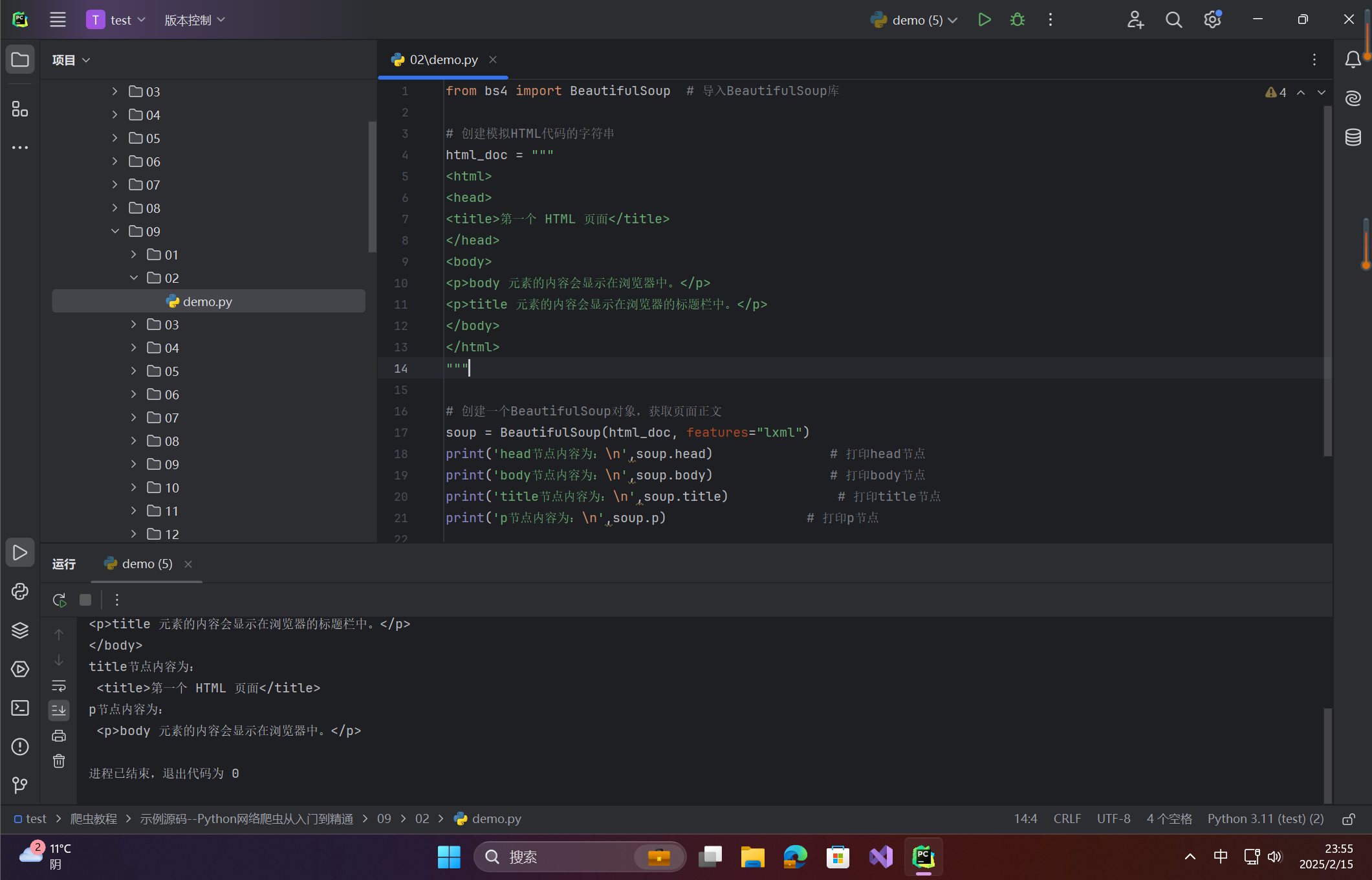
🔎2.获取节点属性
方法:通过 attrs 属性或直接使用 节点['属性名']。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>横排响应式登录</title>
<meta http-equiv="Content-Type" content="text/html" charset="utf-8"/>
<meta name="viewport" content="width=device-width"/>
<link href="font/css/bootstrap.min.css" type="text/css" rel="stylesheet">
<link href="css/style.css" type="text/css" rel="stylesheet">
</head>
<body>
<h3>登录</h3>
<div class="glyphicon glyphicon-envelope"><input type="text" placeholder="请输入邮箱"></div>
<div class="glyphicon glyphicon-lock"><input type="password" placeholder="请输入密码"></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('meta节点中属性如下:\n',soup.meta.attrs)
print('link节点中属性如下:\n',soup.link.attrs)
print('div节点中属性如下:\n',soup.div.attrs)
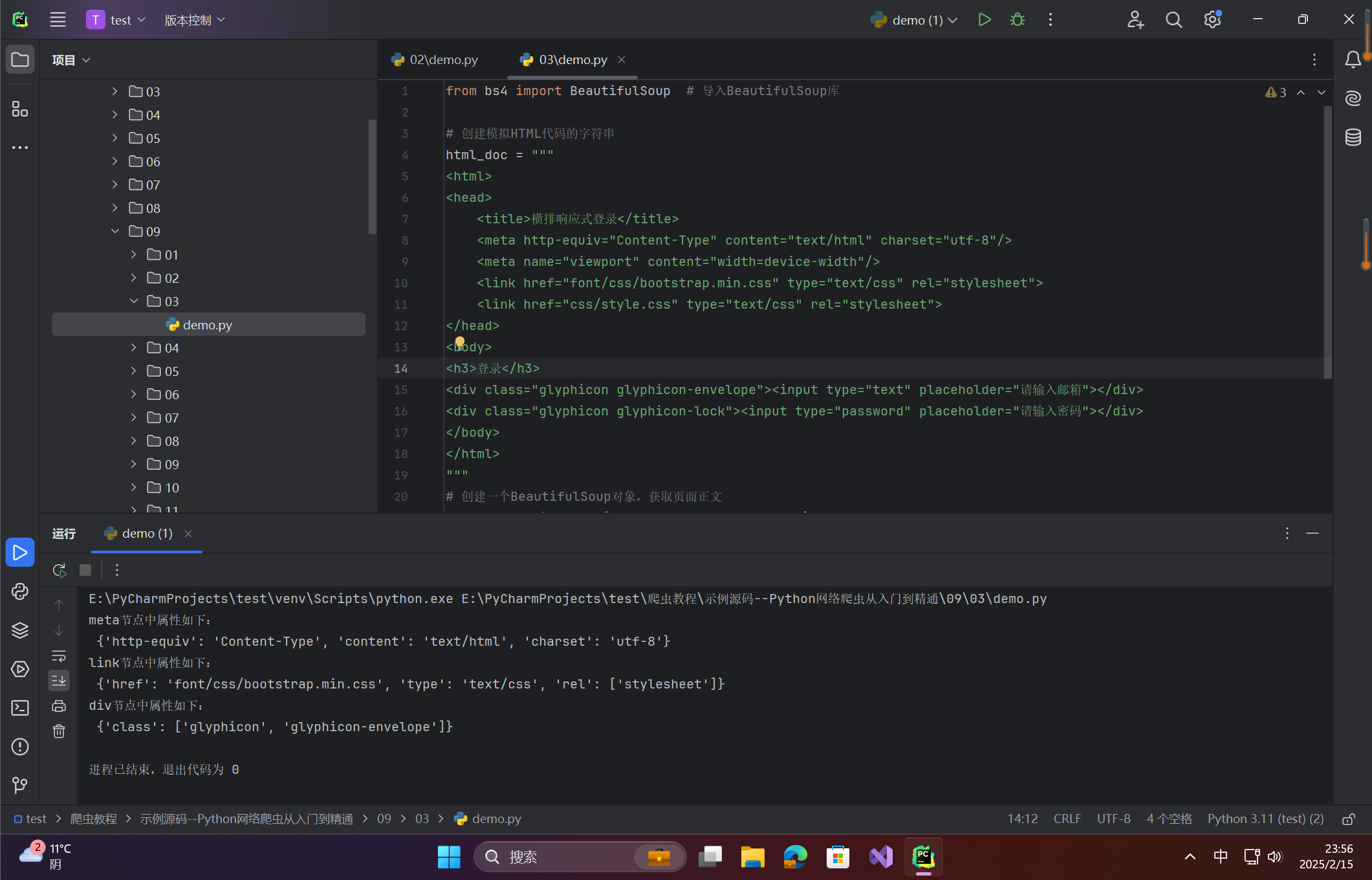 在这里插入图片描述
在这里插入图片描述
🔎3.获取节点文本内容
方法:通过 string 属性。
示例代码:
html_doc = """
<html>
<head>
<title>横排响应式登录</title>
</head>
<body>
<h3>登录</h3>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, "lxml")
print(soup.title.string) # 输出: 横排响应式登录
print(soup.h3.string) # 输出: 登录
🔎4.嵌套获取节点内容
特性:节点可嵌套获取子节点内容,所有节点均为 Tag 类型。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>横排响应式登录</title>
<meta http-equiv="Content-Type" content="text/html" charset="utf-8"/>
<meta name="viewport" content="width=device-width"/>
<link href="font/css/bootstrap.min.css" type="text/css" rel="stylesheet">
<link href="css/style.css" type="text/css" rel="stylesheet">
</head>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print('head节点内容如下:\n',soup.head)
print('head节点数据类型为:',type(soup.head))
print('head节点中title节点内容如下:\n',soup.head.title)
print('head节点中title节点数据类型为:',type(soup.head.title))
print('head节点中title节点中的文本内容为:',soup.head.title.string)
print('head节点中title节点中文本内容的数据类型为:',type(soup.head.title.string))
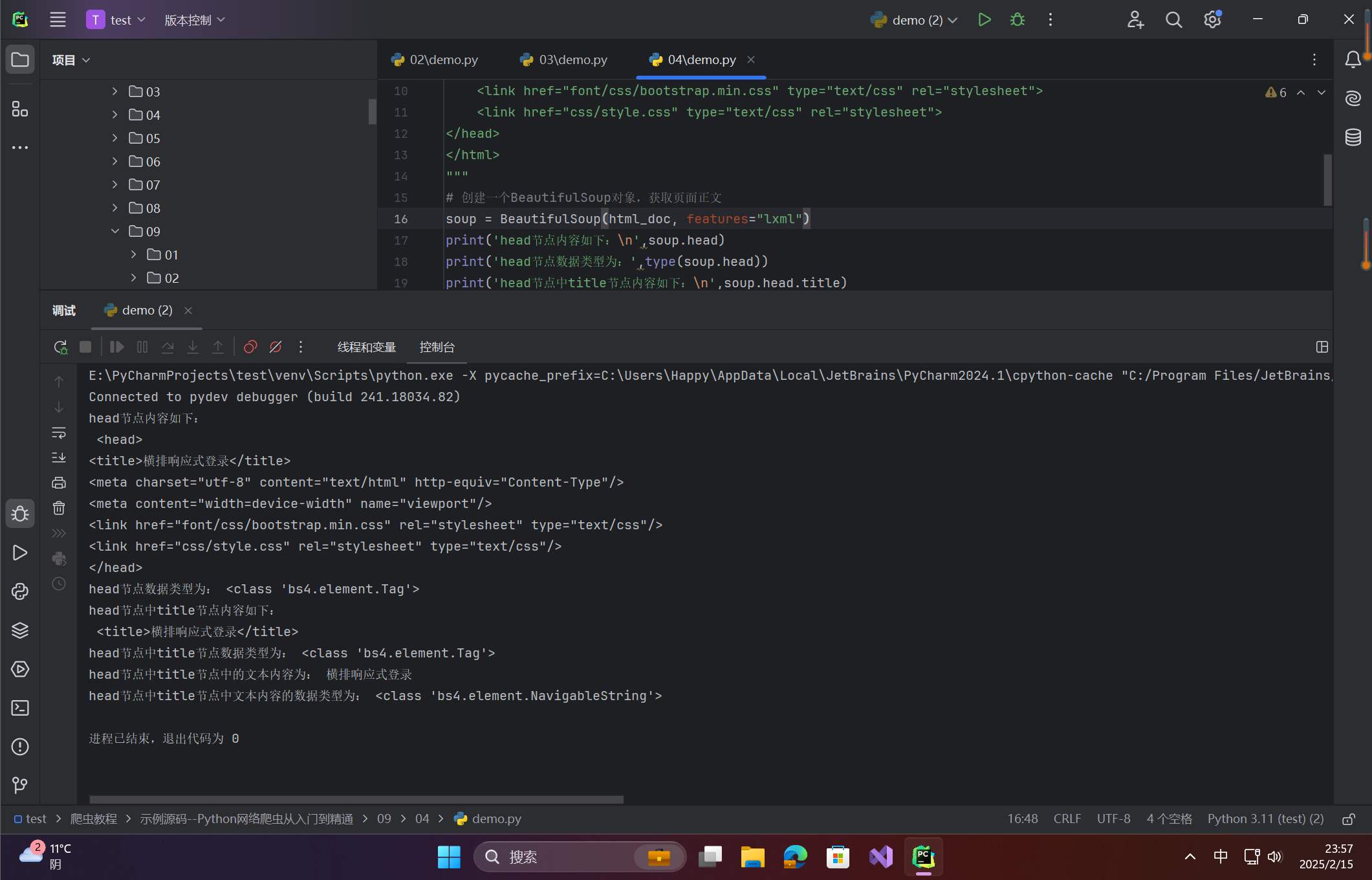 在这里插入图片描述
在这里插入图片描述
🔎5.关联获取
🦋5.1 获取子节点
方法:
-
contents: 返回子节点列表(含换行符等文本节点)。 -
children: 返回子节点生成器(需遍历)。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
print(soup.head.contents) # 列表形式打印head下所有子节点
print(soup.head.children) # 可迭代对象形式打印head下所有子节点
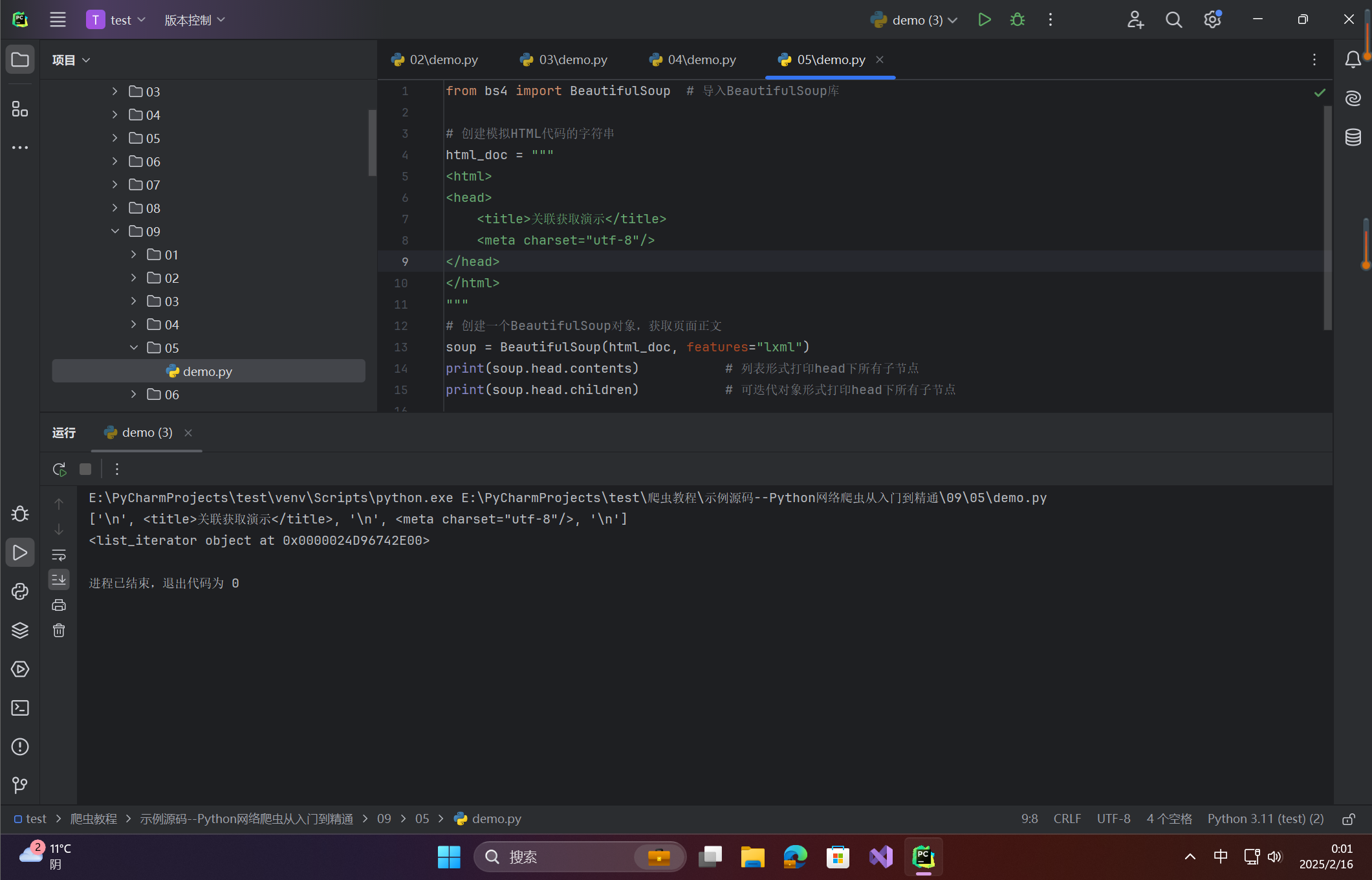 在这里插入图片描述
在这里插入图片描述
🦋5.2 获取孙节点
方法:descendants
特性:递归遍历所有子孙节点(包括嵌套的节点)。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
…此处省略…
<body>
<div id="test1">
<div id="test2">
<ul>
<li class="test3" value = "user1234">
此处为演示信息
</li>
</ul>
</div>
</div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
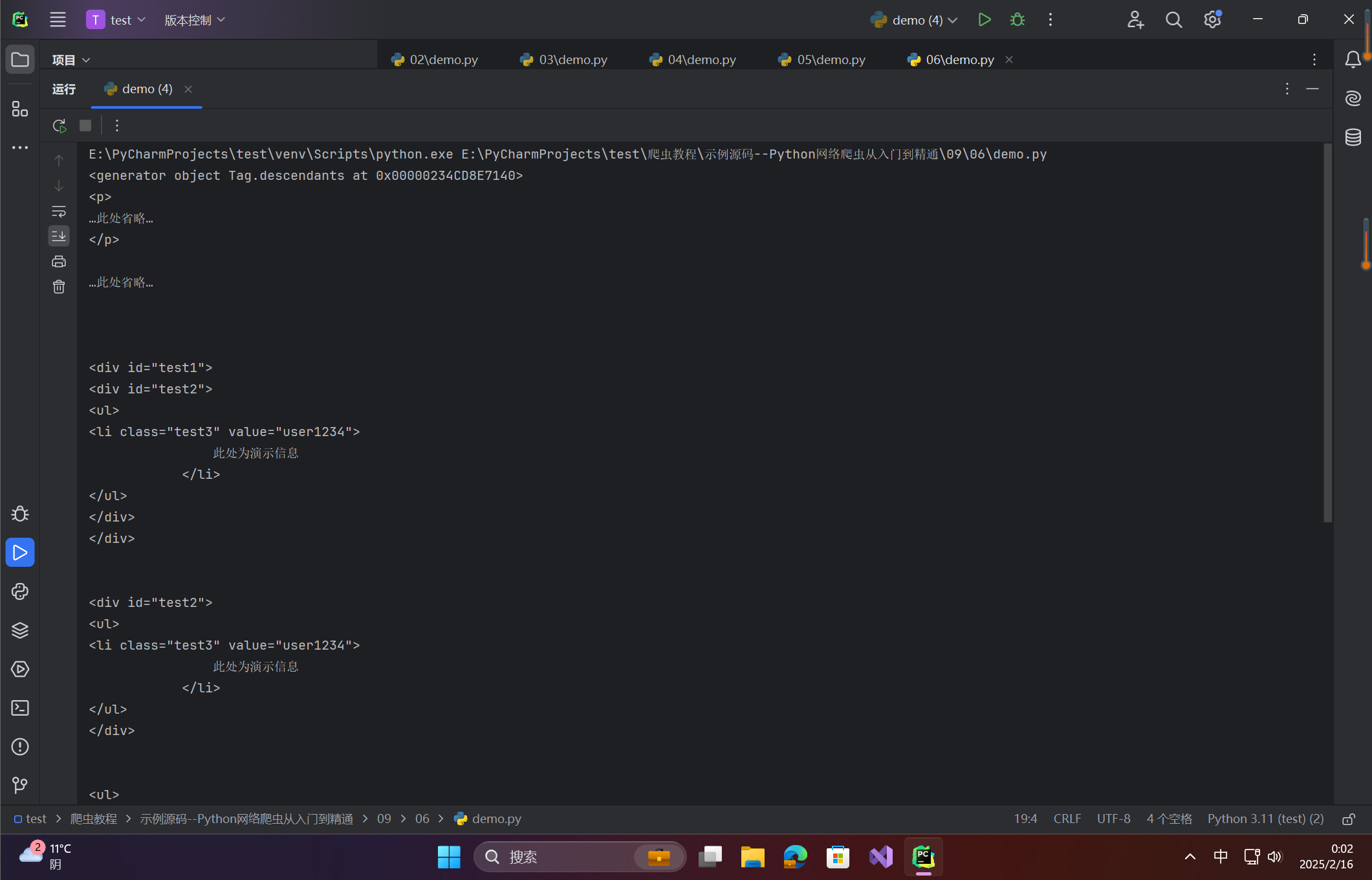
print(soup.body.descendants) # 打印body节点下所有子孙节点内容的generator对象
for i in soup.body.descendants: # 循环遍历generator对象中的所有子孙节点
print(i) # 打印子孙节点内容
 在这里插入图片描述
在这里插入图片描述
🦋5.3 获取父节点
方法:
-
parent: 直接父节点。 -
parents: 所有祖先节点(生成器)。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
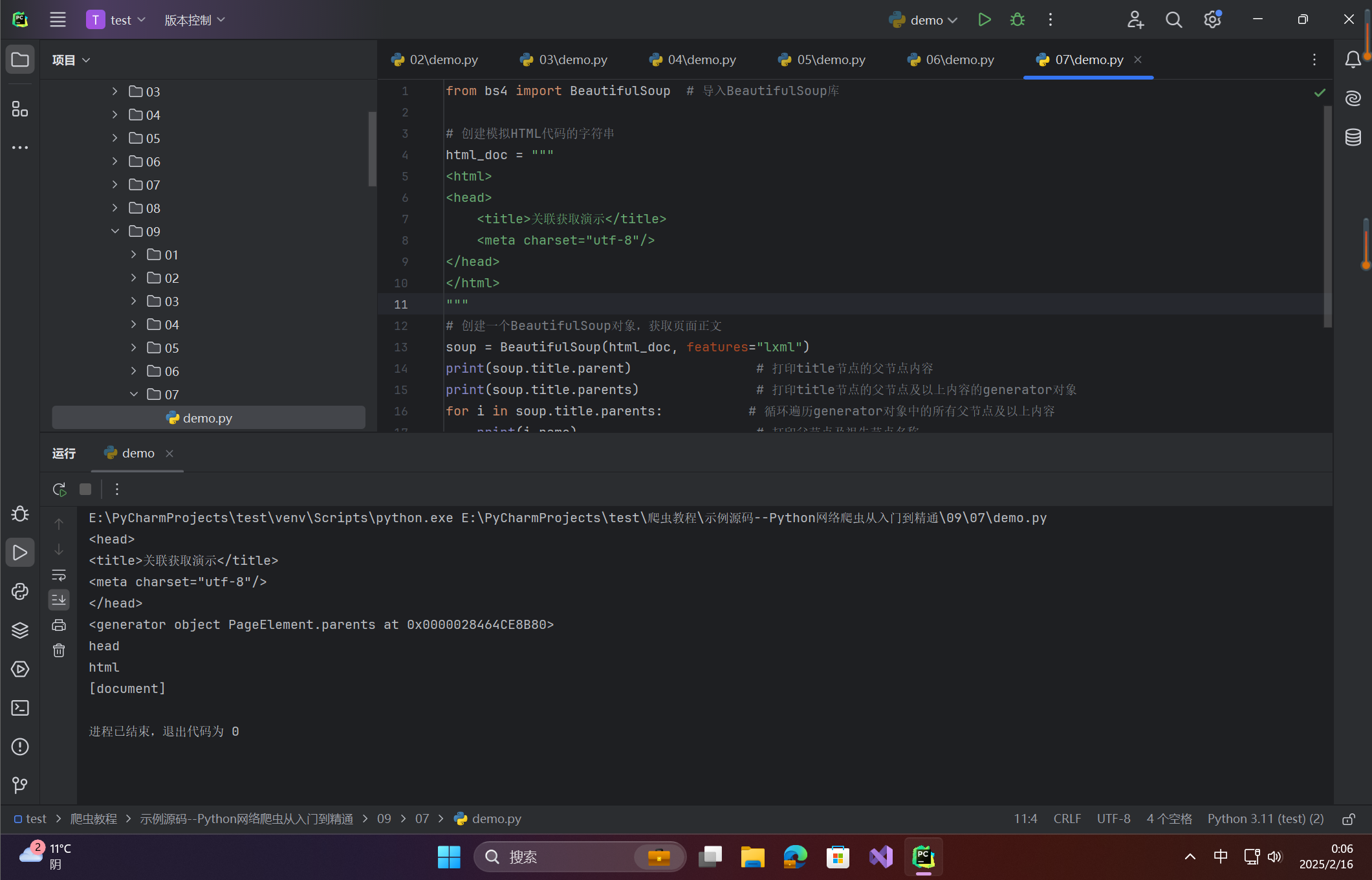
print(soup.title.parent) # 打印title节点的父节点内容
print(soup.title.parents) # 打印title节点的父节点及以上内容的generator对象
for i in soup.title.parents: # 循环遍历generator对象中的所有父节点及以上内容
print(i.name) # 打印父节点及祖先节点名称
 在这里插入图片描述
在这里插入图片描述
🦋5.4 获取兄弟节点
方法:
-
next_sibling/previous_sibling: 相邻兄弟节点。 -
next_siblings/previous_siblings: 所有兄弟节点(生成器)。
示例代码:
from bs4 import BeautifulSoup # 导入BeautifulSoup库
# 创建模拟HTML代码的字符串
html_doc = """
<html>
<head>
<title>关联获取演示</title>
<meta charset="utf-8"/>
</head>
<body>
<p class="p-1" value = "1"><a href="https://item.jd.com/12353915.html">零基础学Python</a></p>
第一个p节点下文本
<div class="div-1" value = "2"><a href="https://item.jd.com/12451724.html">Python从入门到项目实践</a></div>
<p class="p-3" value = "3"><a href="https://item.jd.com/12512461.html">Python项目开发案例集锦</a></p>
<div class="div-2" value = "4"><a href="https://item.jd.com/12550531.html">Python编程锦囊</a></div>
</body>
</html>
"""
# 创建一个BeautifulSoup对象,获取页面正文
soup = BeautifulSoup(html_doc, features="lxml")
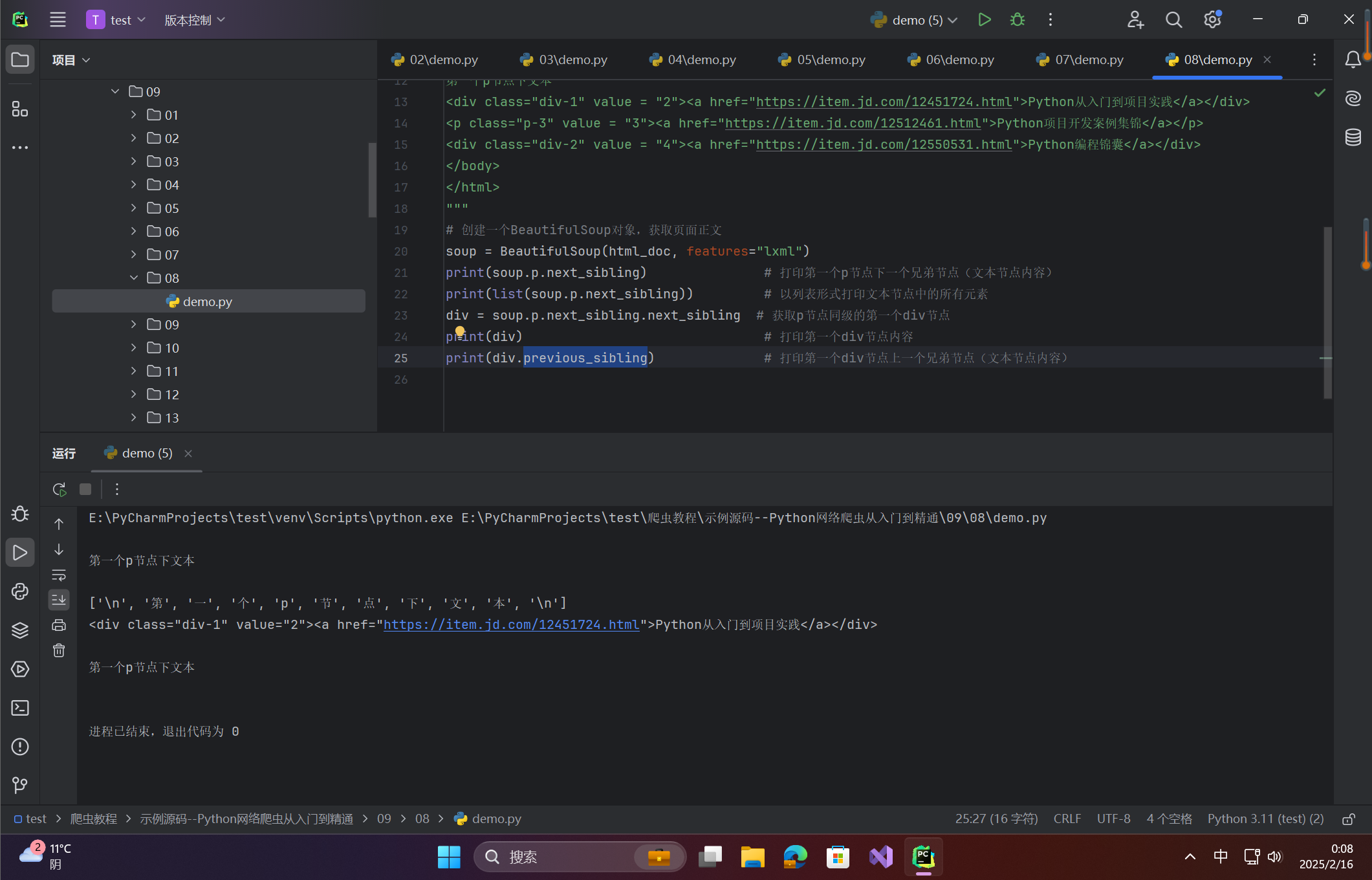
print(soup.p.next_sibling) # 打印第一个p节点下一个兄弟节点(文本节点内容)
print(list(soup.p.next_sibling)) # 以列表形式打印文本节点中的所有元素
div = soup.p.next_sibling.next_sibling # 获取p节点同级的第一个div节点
print(div) # 打印第一个div节点内容
print(div.previous_sibling) # 打印第一个div节点上一个兄弟节点(文本节点内容)
 在这里插入图片描述
在这里插入图片描述
🔎6.关键总结
-
直接获取节点: soup.tag_name,仅返回第一个匹配节点。 -
属性操作: attrs返回字典,或直接通过tag['attr']获取。 -
文本内容: tag.string获取纯文本(不含子节点)。 -
嵌套结构:通过 Tag对象逐层访问子节点。 -
关联遍历: -
contents和children用于子节点。 -
descendants用于所有子孙节点。 -
parent和parents用于父节点/祖先节点。 -
next_sibling和previous_sibling用于兄弟节点。
-
通过灵活组合这些方法,可高效提取复杂 HTML 结构中的数据。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)