【愚公系列】《Python网络爬虫从入门到精通》015-案例:爬取豆瓣电影Top 250

| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在信息丰富的互联网时代,网络爬虫技术为我们提供了获取和分析数据的强大工具。作为一个涵盖了大量影视信息的平台,豆瓣电影以其丰富的用户评分和评论,成为了电影爱好者和研究者的重要资源。而在众多的数据抓取项目中,爬取豆瓣电影Top 250无疑是一个经典且颇具挑战性的案例。
在本期文章中,我们将详细解析如何利用Python编写网络爬虫,专门针对豆瓣电影Top 250进行数据抓取。我们将一步步介绍从分析网页结构、构建请求、处理响应,到提取电影信息(如标题、评分、评论等)的整个流程。同时,我们还将分享一些实用的技巧与注意事项,帮助你更顺利地完成爬取任务。
🚀一、案例:爬取豆瓣电影Top 250
本节将使用requests模块与lxml模块中的XPath,爬取豆瓣电影Top 250中的电影信息,如图所示。
🔎1.分析请求地址
在豆瓣电影Top 250首页的底部可以确定电影信息一共有10页内容,每页有25个电影信息,如图所示。 
切换页面,发现每页的url地址的规律,如图所示。 
🔎2.分析信息位置
打开浏览器“开发者工具”,在顶部选项卡中单击Elements选项,然后单击图标,接着选中网页中的电影名称,查看电影名称所在HTML代码的位置,如图所示。  按照图8.7中的操作步骤,查看“导演、主演”HTML代码位置。“电影评分" “评价人数” “电影总结”信息所对应的。
按照图8.7中的操作步骤,查看“导演、主演”HTML代码位置。“电影评分" “评价人数” “电影总结”信息所对应的。
🔎3.爬虫代码的实现(豆瓣电影 Top 250 爬取)
🦋3.1 完整代码实现
import requests
from lxml import etree
import time
import random
# ------------------------------
# 1. 定义请求头与工具函数
# ------------------------------
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
def clean_text(text_list):
"""清洗文本中的空白符并拼接字符串"""
return ''.join([text.strip() for text in text_list])
# ------------------------------
# 2. 核心爬取函数
# ------------------------------
def get_movie_info(url):
"""获取单页电影信息"""
try:
# 发送请求
response = requests.get(url, headers=HEADERS)
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
return
# 解析 HTML
html = etree.HTML(response.text)
movies = html.xpath('//div[@class="info"]')
for movie in movies:
# 提取电影名称
name = movie.xpath('.//span[@class="title"]/text()')
name = clean_text(name) if name else "未知"
# 提取导演与演员
info = movie.xpath('.//div[@class="bd"]/p[1]/text()')
info = clean_text(info).replace("\xa0", " ") # 处理特殊空格
# 提取评分
score = movie.xpath('.//span[@class="rating_num"]/text()')
score = score[0] if score else "无评分"
# 提取评价人数
evaluation = movie.xpath('.//div[@class="star"]/span[last()]/text()')
evaluation = evaluation[0].replace("人评价", "") if evaluation else "0"
# 提取短评
summary = movie.xpath('.//span[@class="inq"]/text()')
summary = summary[0] if summary else "无短评"
# 打印结果
print(f"电影名称: {name}")
print(f"导演与演员: {info}")
print(f"评分: {score}")
print(f"评价人数: {evaluation}")
print(f"短评: {summary}")
print("-" * 40)
except Exception as e:
print(f"发生异常: {e}")
# ------------------------------
# 3. 主程序入口
# ------------------------------
if __name__ == '__main__':
for page in range(0, 250, 25): # 豆瓣每页25条,共10页
url = f"https://movie.douban.com/top250?start={page}"
print(f"正在爬取第 {page//25 + 1} 页: {url}")
get_movie_info(url)
time.sleep(random.uniform(1, 3)) # 随机延时防封禁
🦋3.2 代码解析
☀️3.2.1 请求头与工具函数
-
HEADERS:模拟浏览器访问,避免被反爬。 -
clean_text():清洗文本中的空白符和换行,使用列表推导高效拼接字符串。
☀️3.2.2 核心爬取函数 get_movie_info()
-
请求与解析: -
使用 requests.get()发送请求,检查状态码确保成功。 -
通过 etree.HTML()解析 HTML 内容。
-
-
XPath 提取数据: -
电影名称:匹配 <span class="title">标签。 -
导演与演员:提取第一个 <p>标签内容,处理特殊空格\xa0。 -
评分与评价人数:定位评分标签和评价人数标签,处理无数据情况。 -
短评:提取 <span class="inq">内容,若无则显示占位符。
-
-
异常处理:捕获网络请求和解析中的异常,增强代码健壮性。
☀️3.2.3 主程序入口
-
分页爬取:通过 range(0, 250, 25)生成 10 页的 URL。 -
随机延时: time.sleep(random.uniform(1, 3))模拟人类操作,降低封禁风险。
🦋3.3 关键改进点
-
修复原代码问题:
-
原代码 header格式错误(应使用字典,而非字符串)。 -
原 processing()函数效率低,改用join+ 列表推导优化。 -
修复 XPath 路径错误(如评分和评价人数的定位)。
-
-
增强功能:
-
异常处理:添加 try...except捕获网络和解析错误。 -
防反爬策略:随机延时 + 模拟浏览器 User-Agent。 -
数据清洗:处理特殊字符 \xa0,优化输出格式。
-
-
代码可维护性:
-
将请求头定义为常量 HEADERS。 -
使用格式化字符串 ( f-string) 提升可读性。
-
🦋3.4 运行结果示例
 在这里插入图片描述
在这里插入图片描述
🦋3.5 注意事项
-
反爬机制:
-
豆瓣可能限制频繁访问,建议添加代理 IP 池或降低请求频率。 -
若返回 403 错误,需更换 User-Agent 或增加请求头参数(如 Referer)。
-
-
数据存储:
-
可将结果保存至 CSV/Excel: import pandas as pd data = [] # 在循环中收集数据 data.append({"名称": name, "评分": score, ...}) pd.DataFrame(data).to_csv("douban_top250.csv", index=False)
-
-
扩展性:
-
添加多线程/异步加速爬取(需注意遵守网站 robots.txt)。 -
使用 BeautifulSoup或Scrapy框架提升解析效率。
-
🚀前言
在信息丰富的互联网时代,网络爬虫技术为我们提供了获取和分析数据的强大工具。作为一个涵盖了大量影视信息的平台,豆瓣电影以其丰富的用户评分和评论,成为了电影爱好者和研究者的重要资源。而在众多的数据抓取项目中,爬取豆瓣电影Top 250无疑是一个经典且颇具挑战性的案例。
在本期文章中,我们将详细解析如何利用Python编写网络爬虫,专门针对豆瓣电影Top 250进行数据抓取。我们将一步步介绍从分析网页结构、构建请求、处理响应,到提取电影信息(如标题、评分、评论等)的整个流程。同时,我们还将分享一些实用的技巧与注意事项,帮助你更顺利地完成爬取任务。
🚀一、案例:爬取豆瓣电影Top 250
本节将使用requests模块与lxml模块中的XPath,爬取豆瓣电影Top 250中的电影信息,如图所示。
🔎1.分析请求地址
在豆瓣电影Top 250首页的底部可以确定电影信息一共有10页内容,每页有25个电影信息,如图所示。 
切换页面,发现每页的url地址的规律,如图所示。 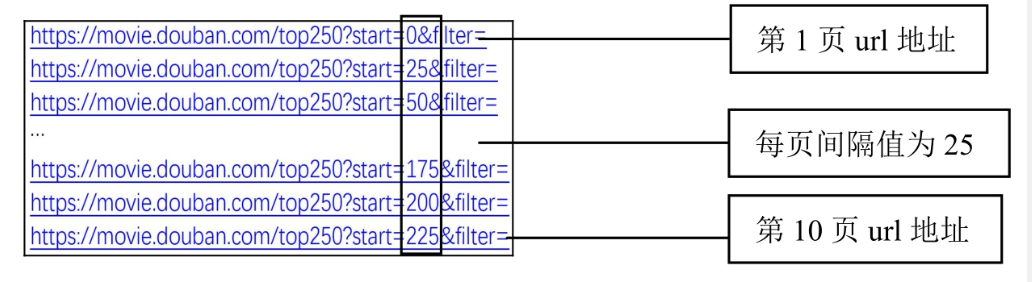
🔎2.分析信息位置
打开浏览器“开发者工具”,在顶部选项卡中单击Elements选项,然后单击图标,接着选中网页中的电影名称,查看电影名称所在HTML代码的位置,如图所示。 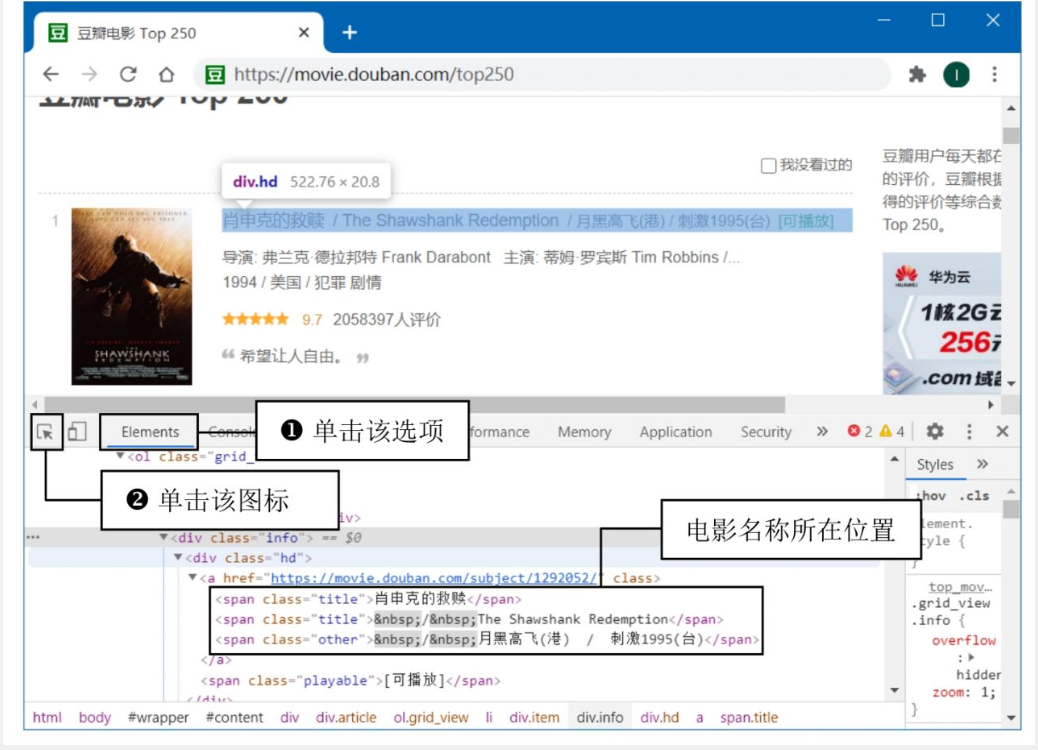 按照图8.7中的操作步骤,查看“导演、主演”HTML代码位置。“电影评分" “评价人数” “电影总结”信息所对应的。
按照图8.7中的操作步骤,查看“导演、主演”HTML代码位置。“电影评分" “评价人数” “电影总结”信息所对应的。
🔎3.爬虫代码的实现(豆瓣电影 Top 250 爬取)
🦋3.1 完整代码实现
import requests
from lxml import etree
import time
import random
# ------------------------------
# 1. 定义请求头与工具函数
# ------------------------------
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
def clean_text(text_list):
"""清洗文本中的空白符并拼接字符串"""
return ''.join([text.strip() for text in text_list])
# ------------------------------
# 2. 核心爬取函数
# ------------------------------
def get_movie_info(url):
"""获取单页电影信息"""
try:
# 发送请求
response = requests.get(url, headers=HEADERS)
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
return
# 解析 HTML
html = etree.HTML(response.text)
movies = html.xpath('//div[@class="info"]')
for movie in movies:
# 提取电影名称
name = movie.xpath('.//span[@class="title"]/text()')
name = clean_text(name) if name else "未知"
# 提取导演与演员
info = movie.xpath('.//div[@class="bd"]/p[1]/text()')
info = clean_text(info).replace("\xa0", " ") # 处理特殊空格
# 提取评分
score = movie.xpath('.//span[@class="rating_num"]/text()')
score = score[0] if score else "无评分"
# 提取评价人数
evaluation = movie.xpath('.//div[@class="star"]/span[last()]/text()')
evaluation = evaluation[0].replace("人评价", "") if evaluation else "0"
# 提取短评
summary = movie.xpath('.//span[@class="inq"]/text()')
summary = summary[0] if summary else "无短评"
# 打印结果
print(f"电影名称: {name}")
print(f"导演与演员: {info}")
print(f"评分: {score}")
print(f"评价人数: {evaluation}")
print(f"短评: {summary}")
print("-" * 40)
except Exception as e:
print(f"发生异常: {e}")
# ------------------------------
# 3. 主程序入口
# ------------------------------
if __name__ == '__main__':
for page in range(0, 250, 25): # 豆瓣每页25条,共10页
url = f"https://movie.douban.com/top250?start={page}"
print(f"正在爬取第 {page//25 + 1} 页: {url}")
get_movie_info(url)
time.sleep(random.uniform(1, 3)) # 随机延时防封禁
🦋3.2 代码解析
☀️3.2.1 请求头与工具函数
-
HEADERS:模拟浏览器访问,避免被反爬。 -
clean_text():清洗文本中的空白符和换行,使用列表推导高效拼接字符串。
☀️3.2.2 核心爬取函数 get_movie_info()
-
请求与解析: -
使用 requests.get()发送请求,检查状态码确保成功。 -
通过 etree.HTML()解析 HTML 内容。
-
-
XPath 提取数据: -
电影名称:匹配 <span class="title">标签。 -
导演与演员:提取第一个 <p>标签内容,处理特殊空格\xa0。 -
评分与评价人数:定位评分标签和评价人数标签,处理无数据情况。 -
短评:提取 <span class="inq">内容,若无则显示占位符。
-
-
异常处理:捕获网络请求和解析中的异常,增强代码健壮性。
☀️3.2.3 主程序入口
-
分页爬取:通过 range(0, 250, 25)生成 10 页的 URL。 -
随机延时: time.sleep(random.uniform(1, 3))模拟人类操作,降低封禁风险。
🦋3.3 关键改进点
-
修复原代码问题:
-
原代码 header格式错误(应使用字典,而非字符串)。 -
原 processing()函数效率低,改用join+ 列表推导优化。 -
修复 XPath 路径错误(如评分和评价人数的定位)。
-
-
增强功能:
-
异常处理:添加 try...except捕获网络和解析错误。 -
防反爬策略:随机延时 + 模拟浏览器 User-Agent。 -
数据清洗:处理特殊字符 \xa0,优化输出格式。
-
-
代码可维护性:
-
将请求头定义为常量 HEADERS。 -
使用格式化字符串 ( f-string) 提升可读性。
-
🦋3.4 运行结果示例
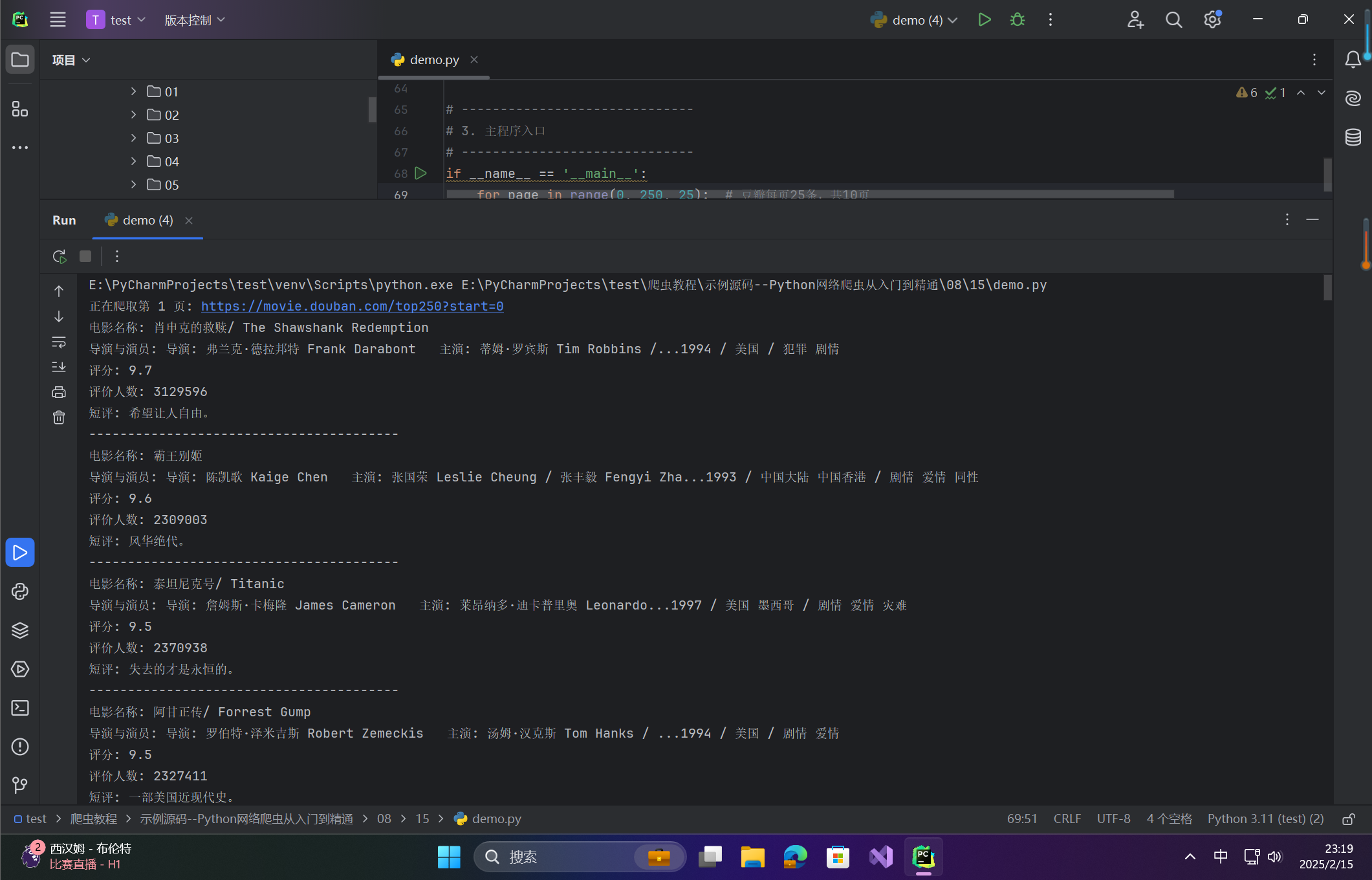 在这里插入图片描述
在这里插入图片描述
🦋3.5 注意事项
-
反爬机制:
-
豆瓣可能限制频繁访问,建议添加代理 IP 池或降低请求频率。 -
若返回 403 错误,需更换 User-Agent 或增加请求头参数(如 Referer)。
-
-
数据存储:
-
可将结果保存至 CSV/Excel: import pandas as pd data = [] # 在循环中收集数据 data.append({"名称": name, "评分": score, ...}) pd.DataFrame(data).to_csv("douban_top250.csv", index=False)
-
-
扩展性:
-
添加多线程/异步加速爬取(需注意遵守网站 robots.txt)。 -
使用 BeautifulSoup或Scrapy框架提升解析效率。
-

- 点赞
- 收藏
- 关注作者
评论(0)