【愚公系列】《Python网络爬虫从入门到精通》014-XPath解析

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在现代网页开发和数据抓取中,获取和处理网页中的信息是非常关键的一环。而在众多的数据提取技术中,XPath(XML Path Language)以其强大的选择能力和灵活性,成为了网页解析的重要工具。无论是提取特定元素的文本内容,还是获取复杂结构中的数据,掌握XPath的使用都能大幅提高我们的数据处理效率。
在本期文章中,我们将深入探讨XPath解析的基本概念和应用技巧。我们将介绍XPath的语法、常用函数及其在Python中的实现方法,帮助你快速上手并应对各种数据提取的需求。通过具体的实例演示,我们将展示如何利用XPath解析网页,提取所需的信息,并为后续的数据分析和处理做好准备。
🚀一、XPath解析
🔎1.XPath 概述
🦋1.1 XPath 是什么?
-
全称:XML Path Language -
功能:在 XML/HTML 中通过路径表达式定位节点 -
特性: -
支持 100+ 内建函数(字符串、数值、逻辑处理等) -
W3C 标准(1999年发布) -
路径表达式简洁高效
-
🦋1.2 常用路径表达式
| 表达式 | 描述 |
|---|---|
nodename |
选取当前节点的所有子节点 |
/ |
从根节点开始直接子节点 |
// |
从当前节点选取所有子孙节点 |
. |
当前节点 |
.. |
父节点 |
@ |
选取属性 |
* |
通配符(匹配所有节点) |
🔎2.XPath 解析操作
🦋2.1 解析 HTML
☀️2.1.1 parse() 方法
-
功能:解析本地 HTML 文件 -
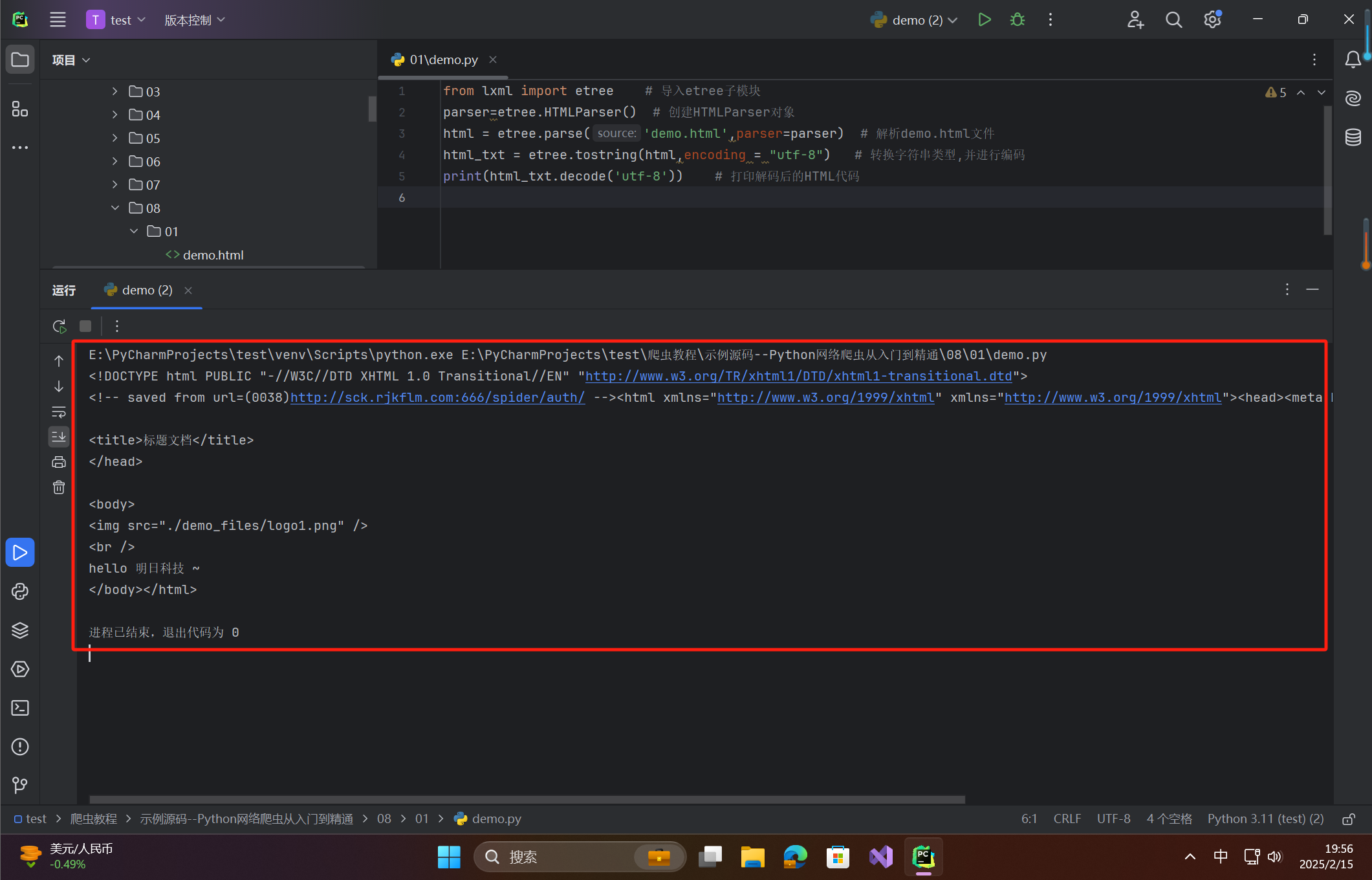
示例: from lxml import etree parser = etree.HTMLParser() html = etree.parse('demo.html', parser=parser) html_str = etree.tostring(html, encoding="utf-8").decode('utf-8') print(html_str) 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述☀️2.1.2 HTML() 方法
-
功能:解析字符串或网络返回的 HTML
-
示例:
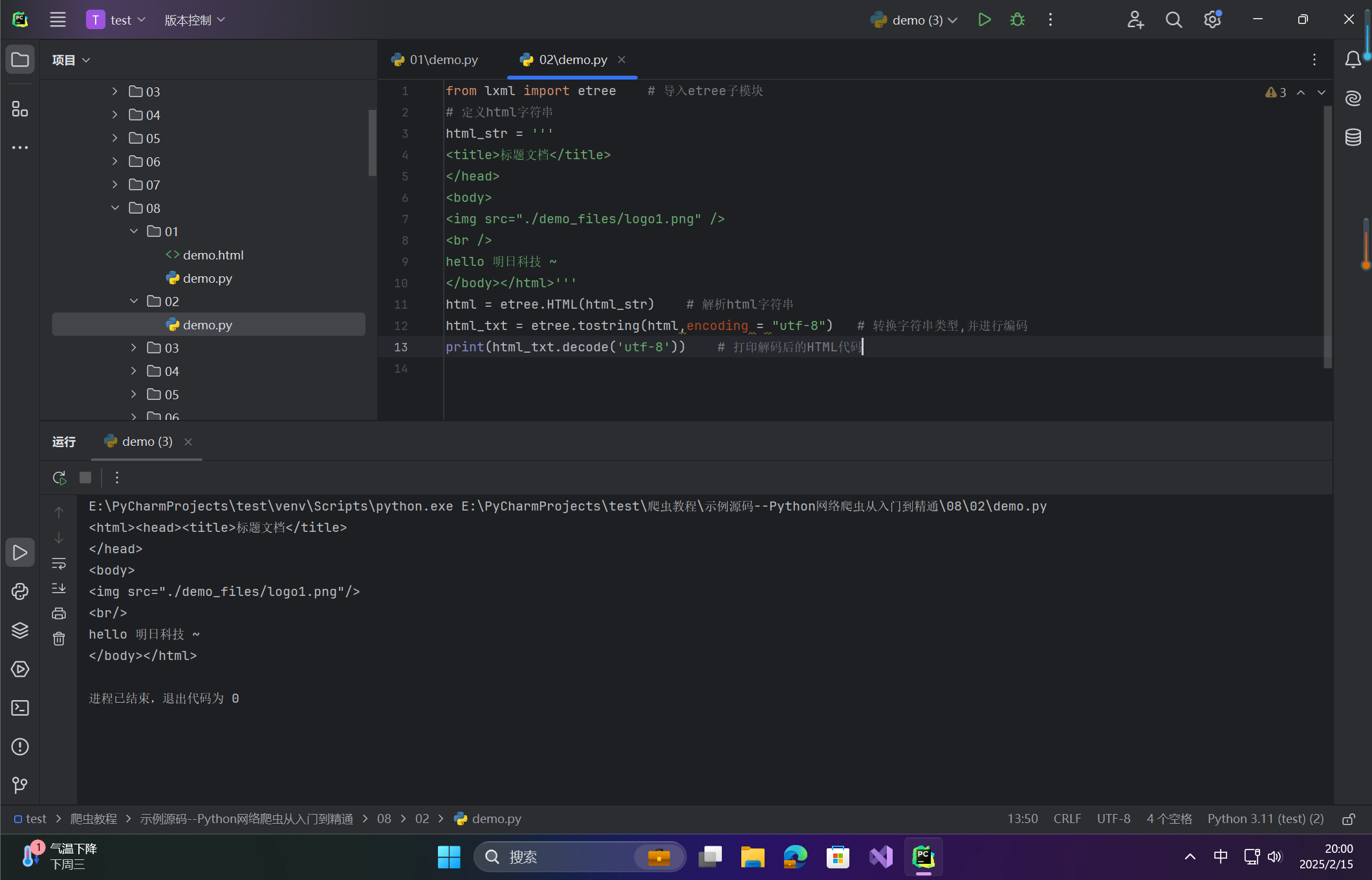
from lxml import etree # 导入etree子模块 # 定义html字符串 html_str = ''' <title>标题文档</title> </head> <body> <img src="./demo_files/logo1.png" /> <br /> hello 明日科技 ~ </body></html>''' html = etree.HTML(html_str) # 解析html字符串 html_txt = etree.tostring(html,encoding = "utf-8") # 转换字符串类型,并进行编码 print(html_txt.decode('utf-8')) # 打印解码后的HTML代码在这里插入图片描述 -
功能:解析服务器返回的 HTML
-
示例:
from lxml import etree # 导入etree子模块 import requests # 导入requests模块 from requests.auth import HTTPBasicAuth # 导入HTTPBasicAuth类 # 定义请求地址 url = 'http://sck.rjkflm.com:666/spider/auth/' ah = HTTPBasicAuth('admin','admin') # 创建HTTPBasicAuth对象,参数为用户名与密码 response = requests.get(url=url,auth=ah) # 发送网络请求 if response.status_code==200: # 如果请求成功 html = etree.HTML(response.text) # 解析html字符串 html_txt = etree.tostring(html,encoding = "utf-8") # 转换字符串类型,并进行编码 print(html_txt.decode('utf-8')) # 打印解码后的HTML代码在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述🦋2.2 获取节点
☀️2.2.1 所有节点
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li> <a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
node_all = html.xpath('//*') # 获取所有节点
print('数据类型:',type(node_all)) # 打印数据类型
print('数据长度:',len(node_all)) # 打印数据长度
print('数据内容:',node_all) # 打印数据内容
# 通过推导式打印所有节点名称,通过节点对象.tag获取节点名称
print('节点名称:',[i.tag for i in node_all])
☀️2.2.2 指定节点
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li> <a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</ul>
</div>
'''
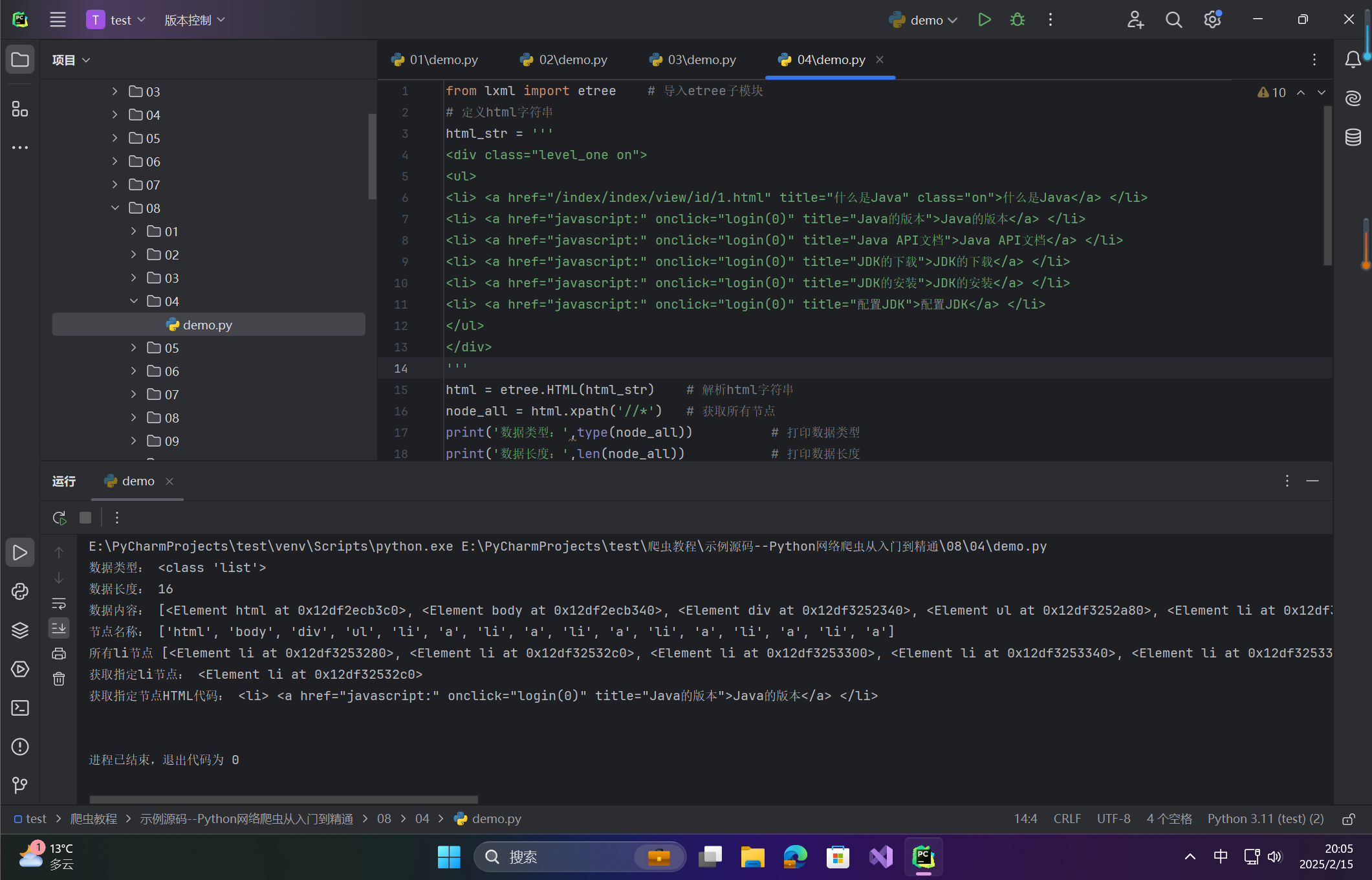
html = etree.HTML(html_str) # 解析html字符串,html字符串为上一示例的html字符串
li_all = html.xpath('//li') # 获取所有li节点
print('所有li节点',li_all) # 打印所有li节点
print('获取指定li节点:',li_all[1]) # 打印指定li节点
li_txt = etree.tostring(li_all[1],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',li_txt.decode('utf-8'))
 在这里插入图片描述
在这里插入图片描述
🦋2.3 节点关系
☀️2.3.1 子节点
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li>
<a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a>
<a>Java</a>
</li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
</ul>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
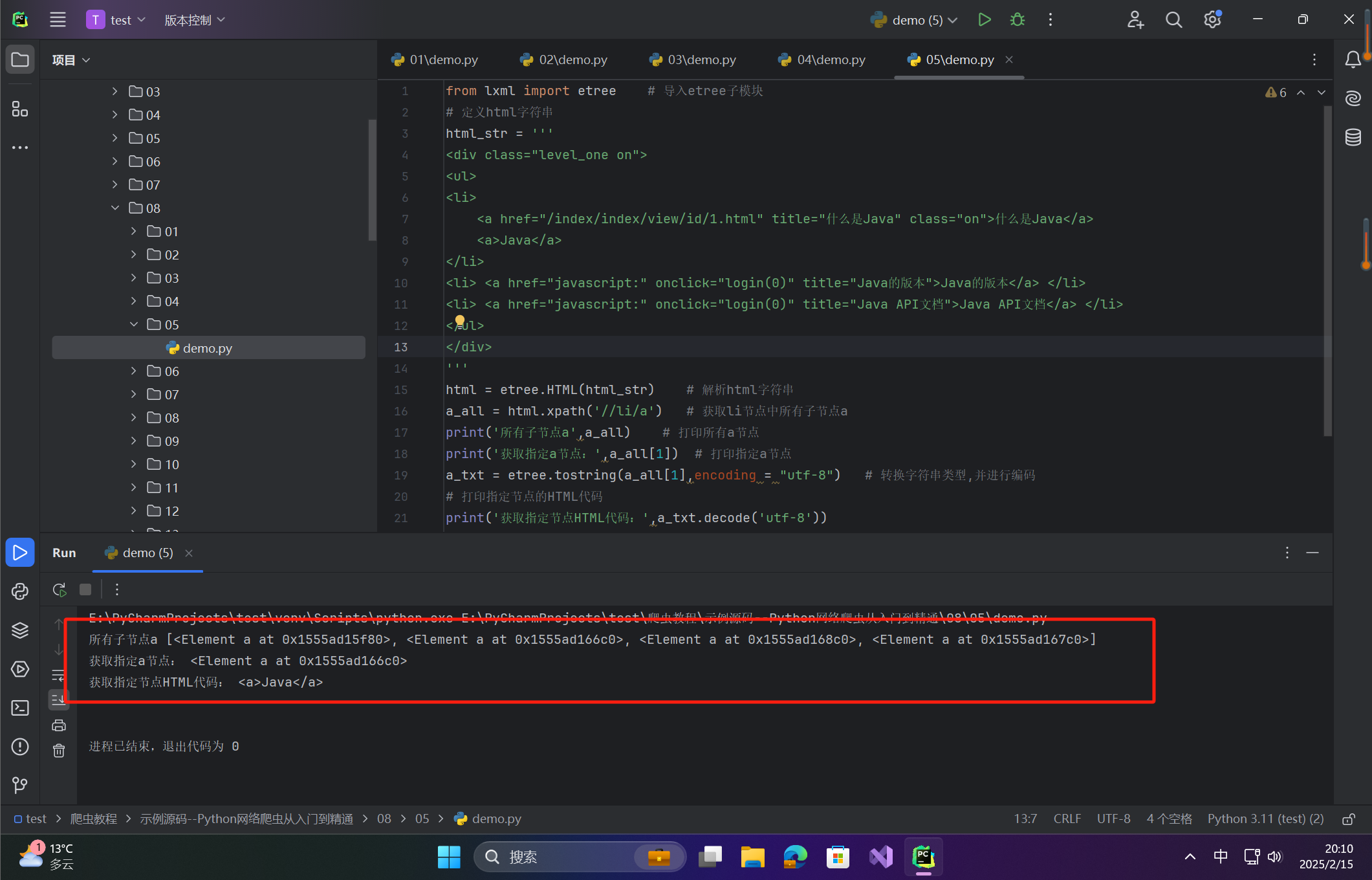
a_all = html.xpath('//li/a') # 获取li节点中所有子节点a
print('所有子节点a',a_all) # 打印所有a节点
print('获取指定a节点:',a_all[1]) # 打印指定a节点
a_txt = etree.tostring(a_all[1],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',a_txt.decode('utf-8'))
 在这里插入图片描述
在这里插入图片描述
☀️2.3.2 子孙节点
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li>
<a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a>
<a>Java</a>
</li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
<li>
<a href="javascript:" onclick="login(0)" title="Java API文档">
<a>a节点中的a节点</a>
</a>
</li>
</ul>
</div>
'''
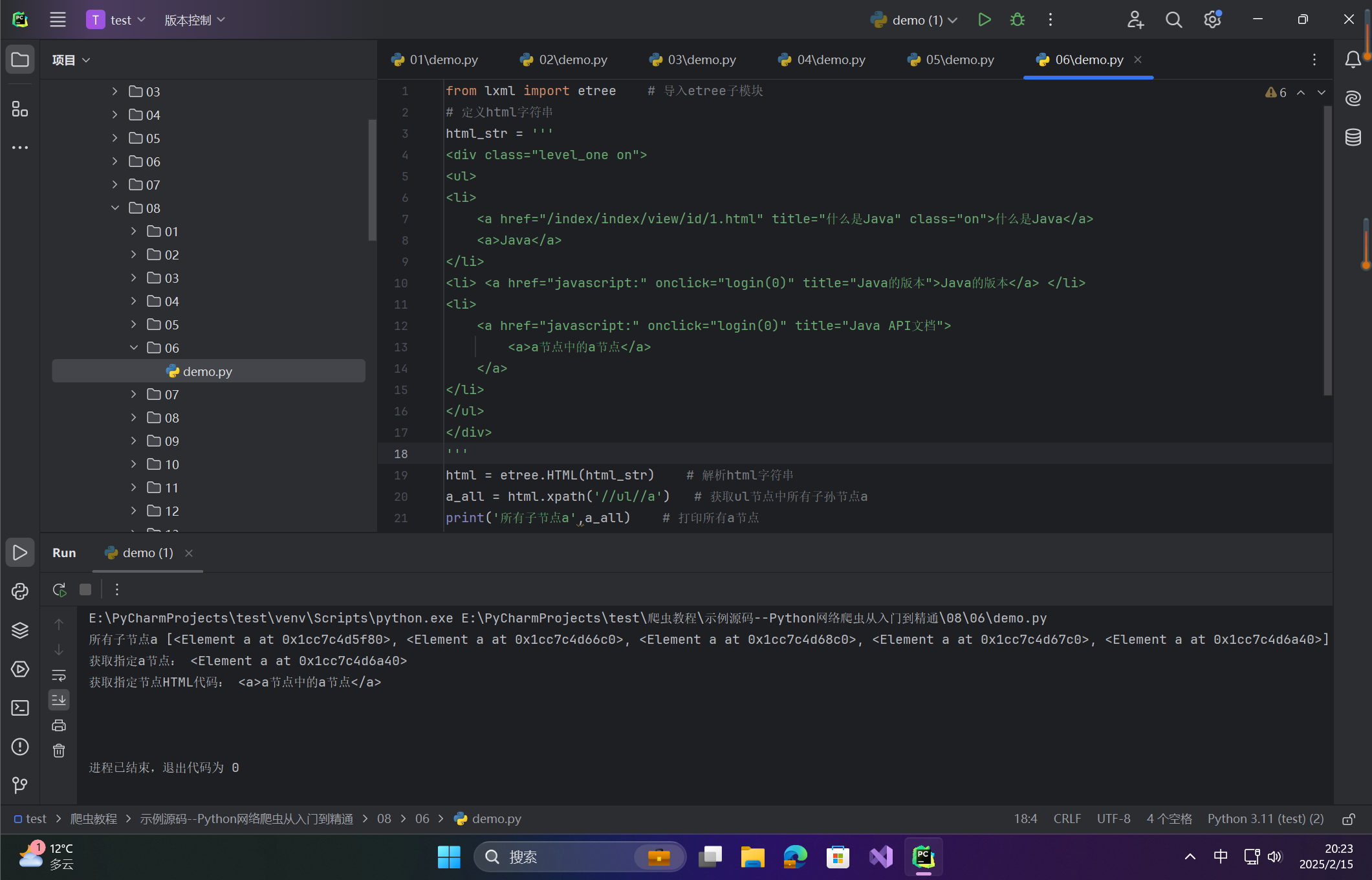
html = etree.HTML(html_str) # 解析html字符串
a_all = html.xpath('//ul//a') # 获取ul节点中所有子孙节点a
print('所有子节点a',a_all) # 打印所有a节点
print('获取指定a节点:',a_all[4]) # 打印指定a节点
a_txt = etree.tostring(a_all[4],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:',a_txt.decode('utf-8'))
 在这里插入图片描述
在这里插入图片描述
☀️2.3.3 父节点
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li><a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a></li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
</ul>
</div>
'''
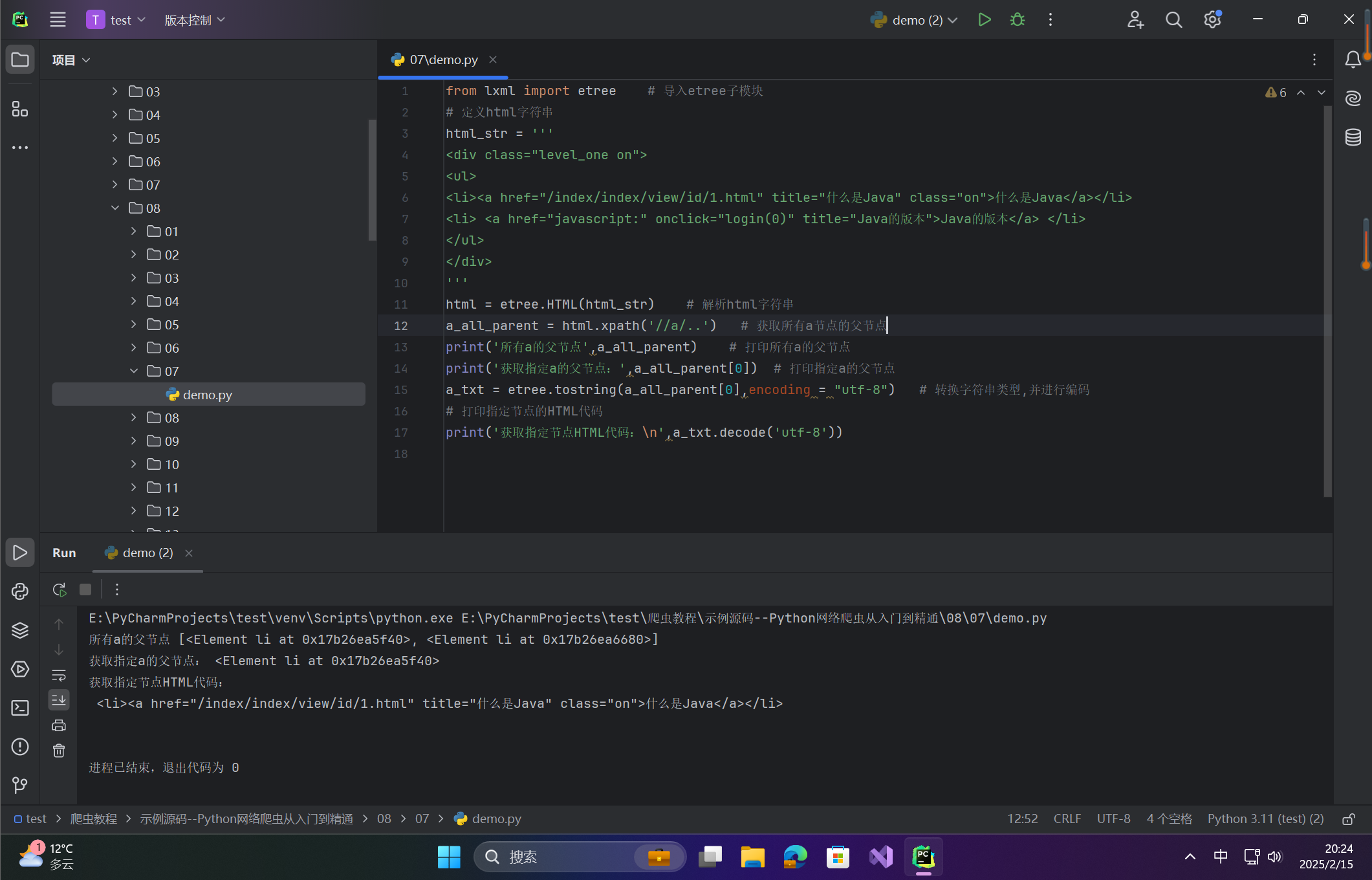
html = etree.HTML(html_str) # 解析html字符串
a_all_parent = html.xpath('//a/..') # 获取所有a节点的父节点
print('所有a的父节点',a_all_parent) # 打印所有a的父节点
print('获取指定a的父节点:',a_all_parent[0]) # 打印指定a的父节点
a_txt = etree.tostring(a_all_parent[0],encoding = "utf-8") # 转换字符串类型,并进行编码
# 打印指定节点的HTML代码
print('获取指定节点HTML代码:\n',a_txt.decode('utf-8'))
 在这里插入图片描述
在这里插入图片描述
🦋2.4 文本与属性
☀️2.4.1 获取文本
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="level_one on">
<ul>
<li><a href="/index/index/view/id/1.html" title="什么是Java" class="on">什么是Java</a></li>
<li> <a href="javascript:" onclick="login(0)" title="Java的版本">Java的版本</a> </li>
</ul>
</div>
'''
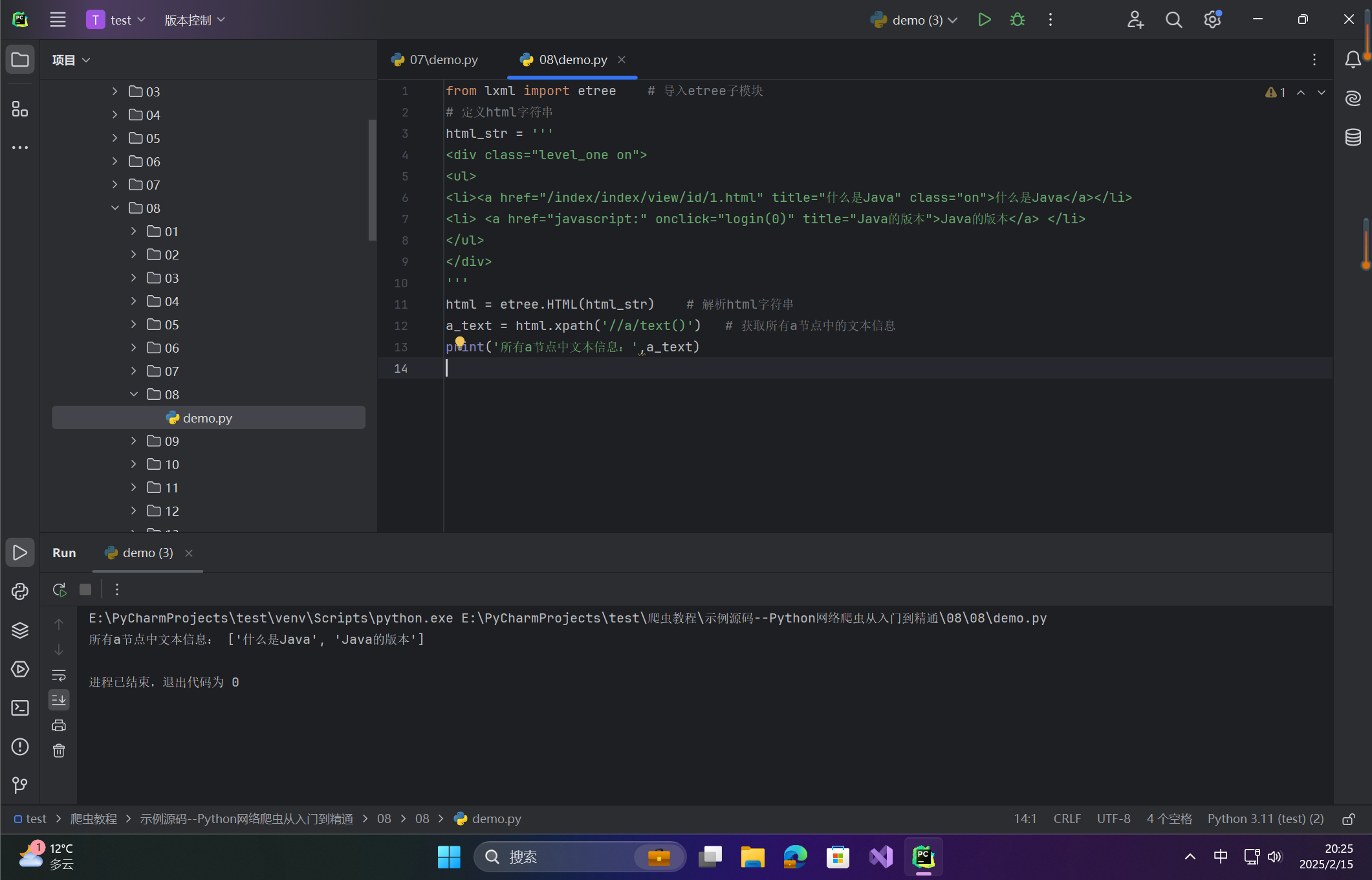
html = etree.HTML(html_str) # 解析html字符串
a_text = html.xpath('//a/text()') # 获取所有a节点中的文本信息
print('所有a节点中文本信息:',a_text)
 在这里插入图片描述
在这里插入图片描述
☀️2.4.2 获取属性
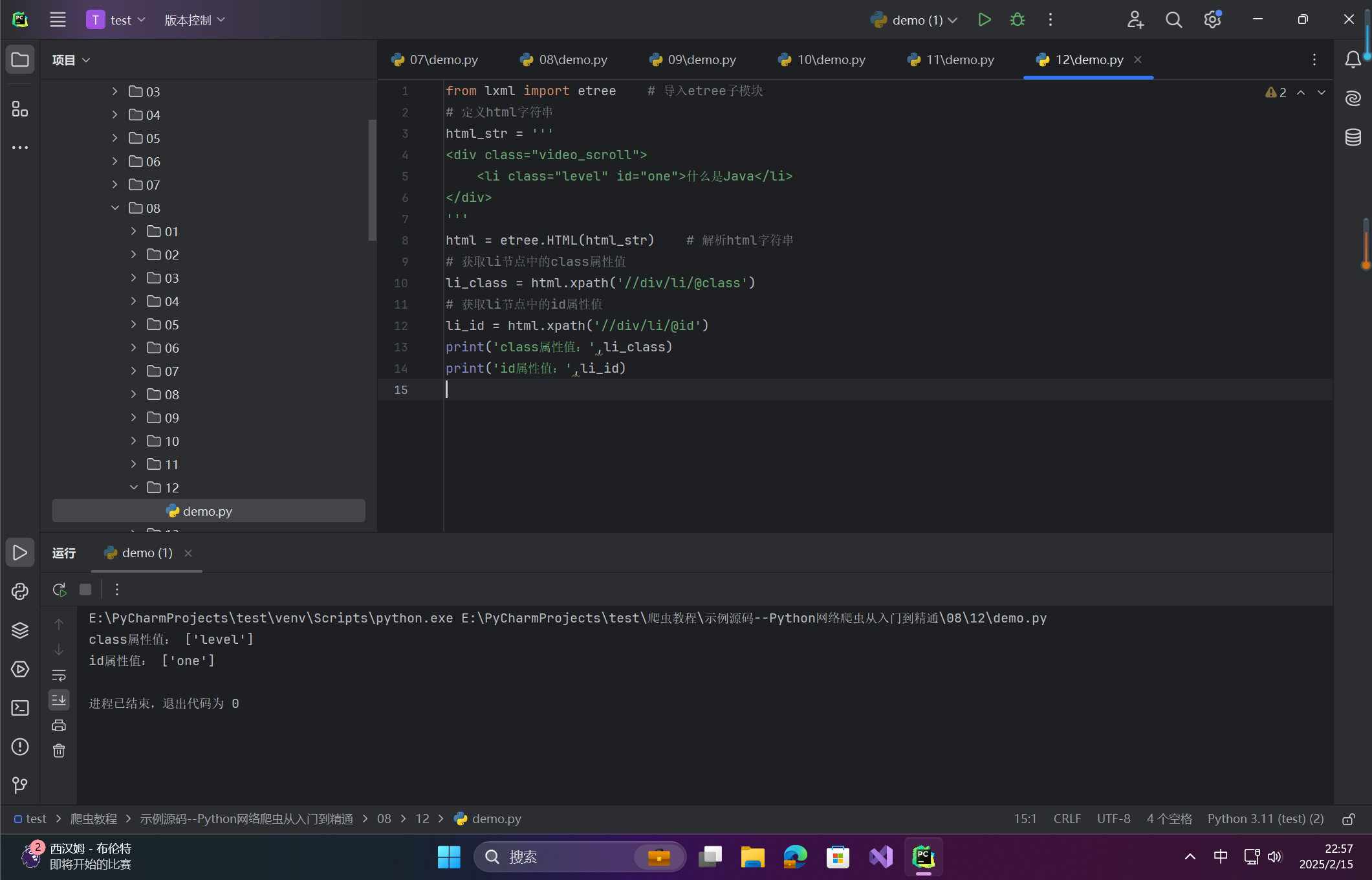
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li class="level" id="one">什么是Java</li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取li节点中的class属性值
li_class = html.xpath('//div/li/@class')
# 获取li节点中的id属性值
li_id = html.xpath('//div/li/@id')
print('class属性值:',li_class)
print('id属性值:',li_id)
 在这里插入图片描述
在这里插入图片描述
☀️2.4.3 属性匹配
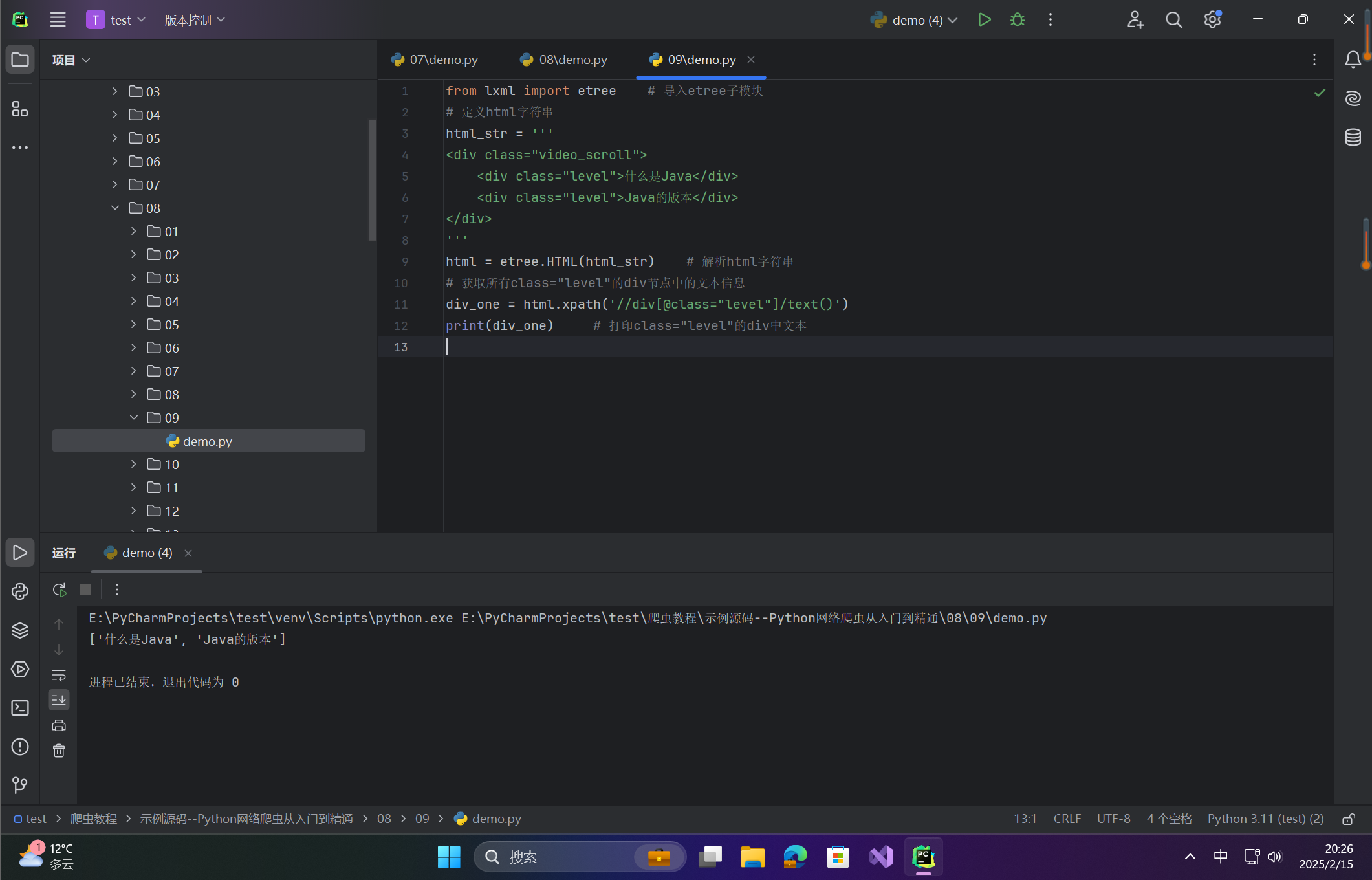
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level"的div节点中的文本信息
div_one = html.xpath('//div[@class="level"]/text()')
print(div_one) # 打印class="level"的div中文本
 在这里插入图片描述
在这里插入图片描述
☀️2.4.4 属性多值匹配
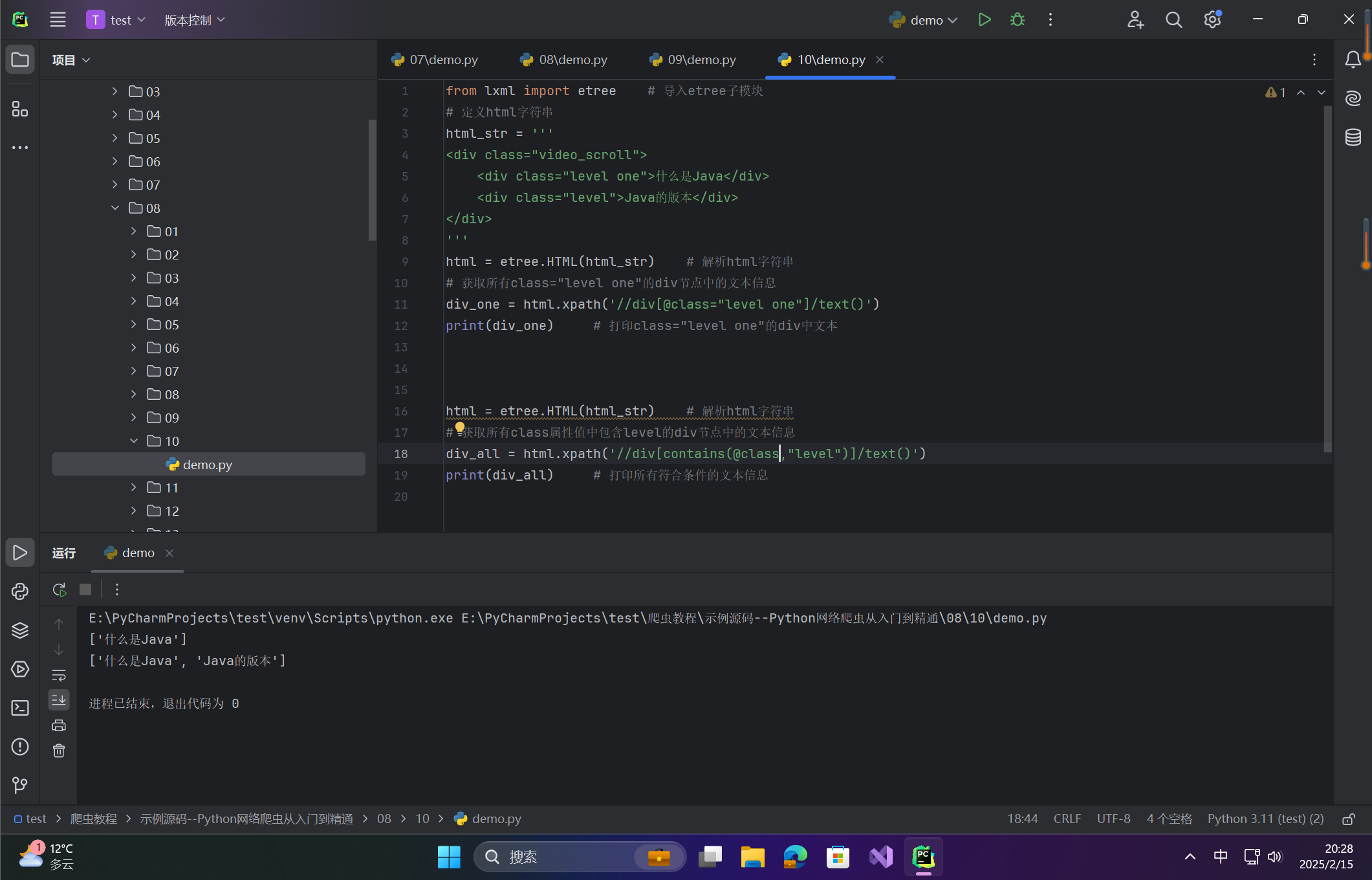
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level one">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class="level one"的div节点中的文本信息
div_one = html.xpath('//div[@class="level one"]/text()')
print(div_one) # 打印class="level one"的div中文本
html = etree.HTML(html_str) # 解析html字符串
# 获取所有class属性值中包含level的div节点中的文本信息
div_all = html.xpath('//div[contains(@class,"level")]/text()')
print(div_all) # 打印所有符合条件的文本信息
 在这里插入图片描述
在这里插入图片描述
☀️2.4.5 多属性匹配
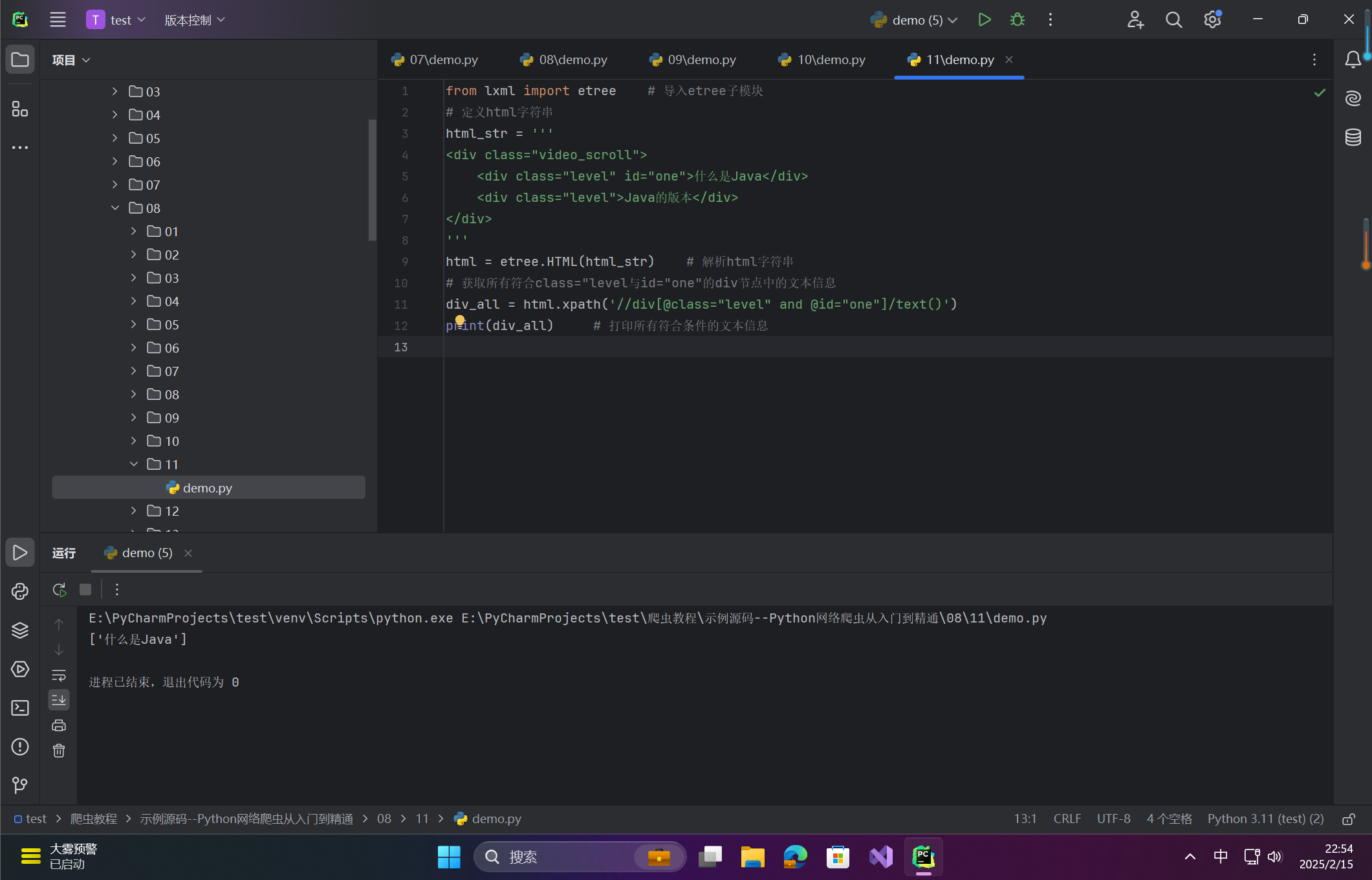
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<div class="level" id="one">什么是Java</div>
<div class="level">Java的版本</div>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
# 获取所有符合class="level与id="one"的div节点中的文本信息
div_all = html.xpath('//div[@class="level" and @id="one"]/text()')
print(div_all) # 打印所有符合条件的文本信息
🦋2.5 高级操作
☀️2.5.1 按序获取
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li> <a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
<li> <a href="javascript:" onclick="login(0)" title="配置JDK">配置JDK</a> </li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
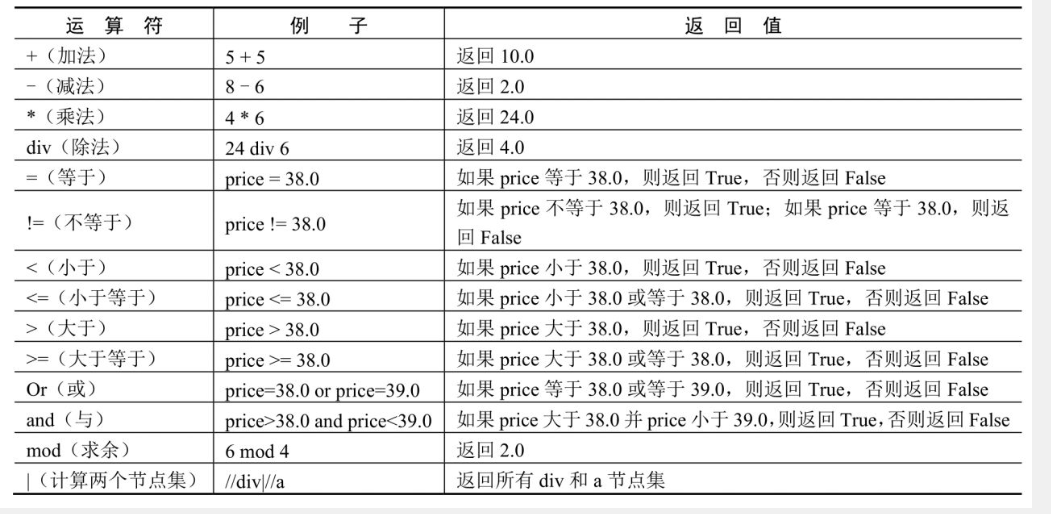
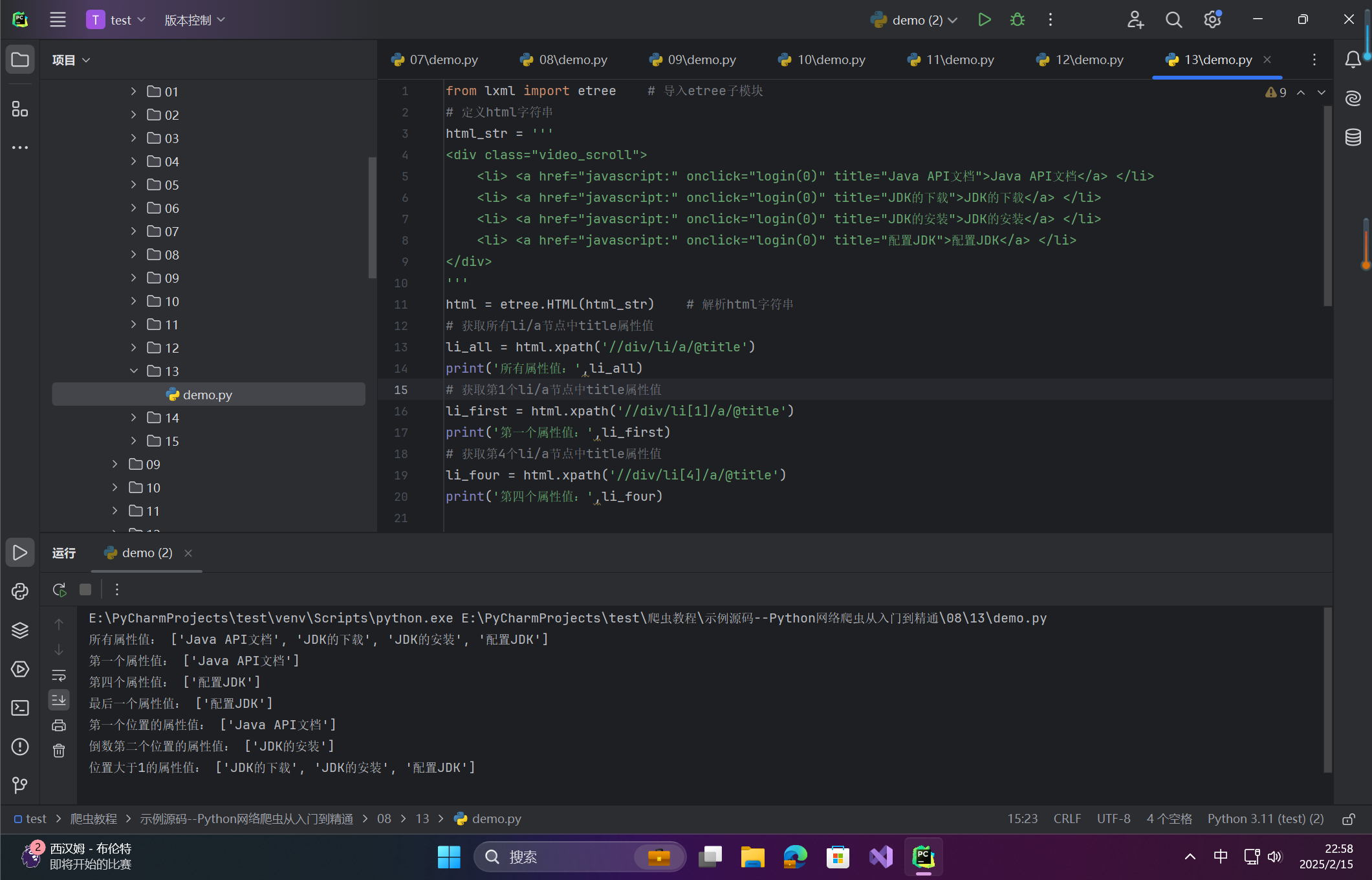
# 获取所有li/a节点中title属性值
li_all = html.xpath('//div/li/a/@title')
print('所有属性值:',li_all)
# 获取第1个li/a节点中title属性值
li_first = html.xpath('//div/li[1]/a/@title')
print('第一个属性值:',li_first)
# 获取第4个li/a节点中title属性值
li_four = html.xpath('//div/li[4]/a/@title')
print('第四个属性值:',li_four)
html = etree.HTML(html_str) # 解析html字符串
# 获取最后一个li/a节点中title属性值
li_last = html.xpath('//div/li[last()]/a/@title')
print('最后一个属性值:',li_last)
# 获取第1个li/a节点中title属性值
li = html.xpath('//div/li[position()=1]/a/@title')
print('第一个位置的属性值:',li)
# 获取倒数第二个li/a节点中title属性值
li = html.xpath('//div/li[last()-1]/a/@title')
print('倒数第二个位置的属性值:',li)
# 获取位置大于1的li/a节点中title属性值
li = html.xpath('//div/li[position()>1]/a/@title')
print('位置大于1的属性值:',li)
 在这里插入图片描述
在这里插入图片描述
☀️2.5.2 节点轴
from lxml import etree # 导入etree子模块
# 定义html字符串
html_str = '''
<div class="video_scroll">
<li><a href="javascript:" onclick="login(0)" title="Java API文档">Java API文档</a></li>
<li><a href="javascript:" onclick="login(0)" title="JDK的下载">JDK的下载</a></li>
<li> <a href="javascript:" onclick="login(0)" title="JDK的安装">JDK的安装</a> </li>
</div>
'''
html = etree.HTML(html_str) # 解析html字符串
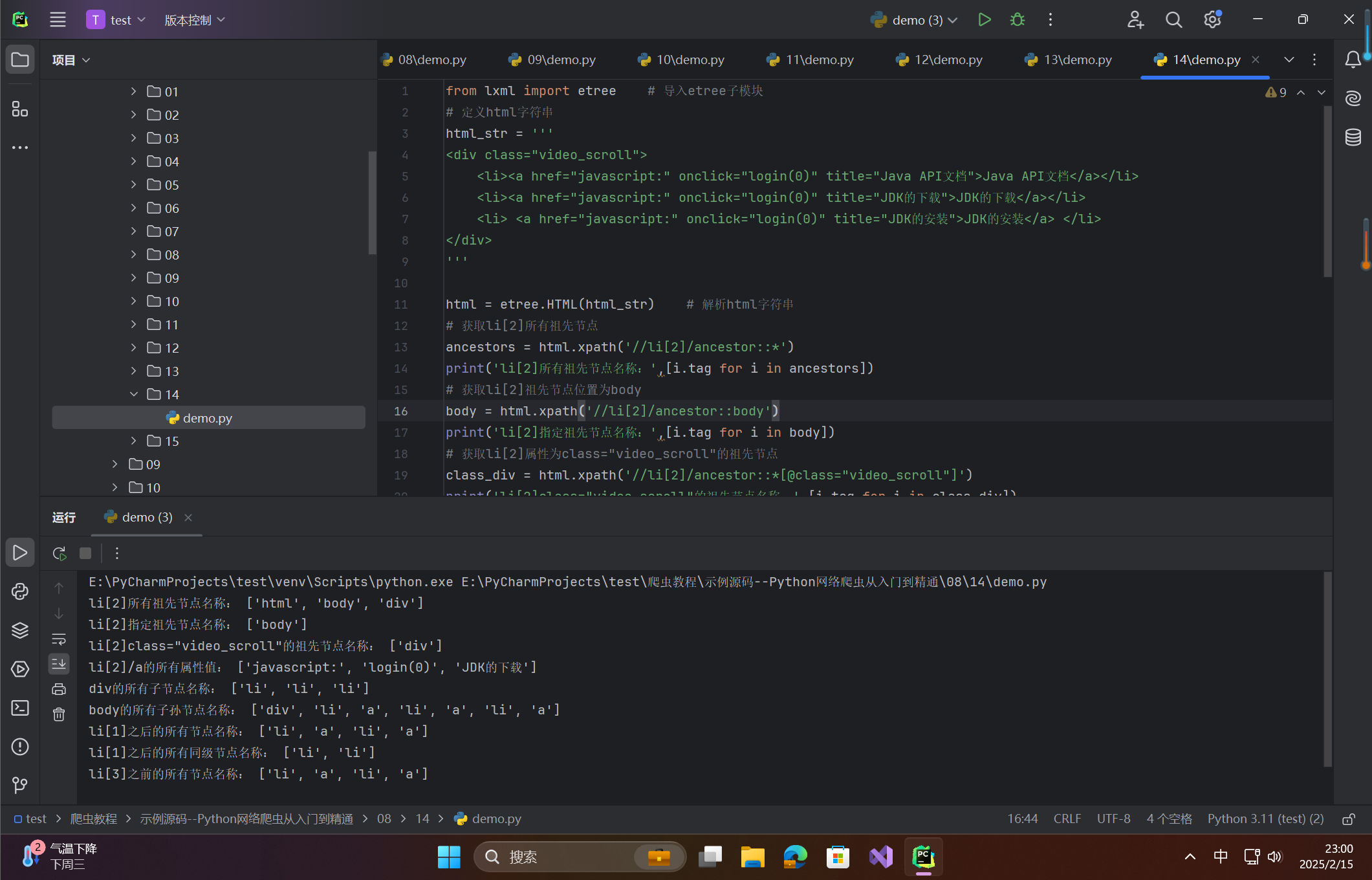
# 获取li[2]所有祖先节点
ancestors = html.xpath('//li[2]/ancestor::*')
print('li[2]所有祖先节点名称:',[i.tag for i in ancestors])
# 获取li[2]祖先节点位置为body
body = html.xpath('//li[2]/ancestor::body')
print('li[2]指定祖先节点名称:',[i.tag for i in body])
# 获取li[2]属性为class="video_scroll"的祖先节点
class_div = html.xpath('//li[2]/ancestor::*[@class="video_scroll"]')
print('li[2]class="video_scroll"的祖先节点名称:',[i.tag for i in class_div])
# 获取li[2]/a所有属性值
attributes = html.xpath('//li[2]/a/attribute::*')
print('li[2]/a的所有属性值:',attributes)
# 获取div所有子节点
div_child = html.xpath('//div/child::*')
print('div的所有子节点名称:',[i.tag for i in div_child])
# 获取body所有子孙节点
body_descendant = html.xpath('//body/descendant::*')
print('body的所有子孙节点名称:',[i.tag for i in body_descendant])
# 获取li[1]节点后的所有节点
li_following = html.xpath('//li[1]/following::*')
print('li[1]之后的所有节点名称:',[i.tag for i in li_following])
# 获取li[1]节点后的所有同级节点
li_sibling = html.xpath('//li[1]/following-sibling::*')
print('li[1]之后的所有同级节点名称:',[i.tag for i in li_sibling])
# 获取li[3]节点前的所有节点
li_preceding = html.xpath('//li[3]/preceding::*')
print('li[3]之前的所有节点名称:',[i.tag for i in li_preceding])
 在这里插入图片描述
在这里插入图片描述
🔎3.关键总结
-
路径表达式:
-
/直接子节点,//所有子孙节点,@属性操作。 -
索引从 1开始(非 Python 的0)。
-
-
常用方法:
-
text()获取文本,@attr获取属性。 -
contains()模糊匹配,逻辑运算符(and/or)。
-
-
性能优化:
-
使用 lxml(C 底层)解析效率高。 -
优先精确路径(如 //div//a比//a更快)。
-
-
注意点:
-
网络请求需添加 User-Agent反爬。 -
动态加载内容需结合其他工具(如 Selenium)。
-

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)