【愚公系列】《Python网络爬虫从入门到精通》013-案例:爬取编程e学网视频

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在当今信息爆炸的时代,网络爬虫作为一种强大的数据获取工具,正被越来越多的人所关注和应用。无论是为了收集学习资料,还是为了进行市场分析,爬虫技术都能帮助我们从繁杂的网页中提取出有价值的信息。在众多的学习资源中,视频教程因其生动直观的特点,受到广大编程学习者的青睐。而今天,我们将通过一个实际案例,带领大家一起爬取编程e学网的视频资源。
在本期文章中,我们将详细介绍如何使用Python编写网络爬虫,针对编程e学网的视频进行数据抓取。我们将一步一步解析爬虫的基本步骤,包括如何分析网页结构、构建请求、处理响应、提取视频链接等。通过这个案例,你不仅能掌握网络爬虫的基本技巧,还能深入理解数据抓取的实际应用。
🚀一、案例:爬取编程e学网视频
🔎1.查找视频页面
-
访问目标网站 -
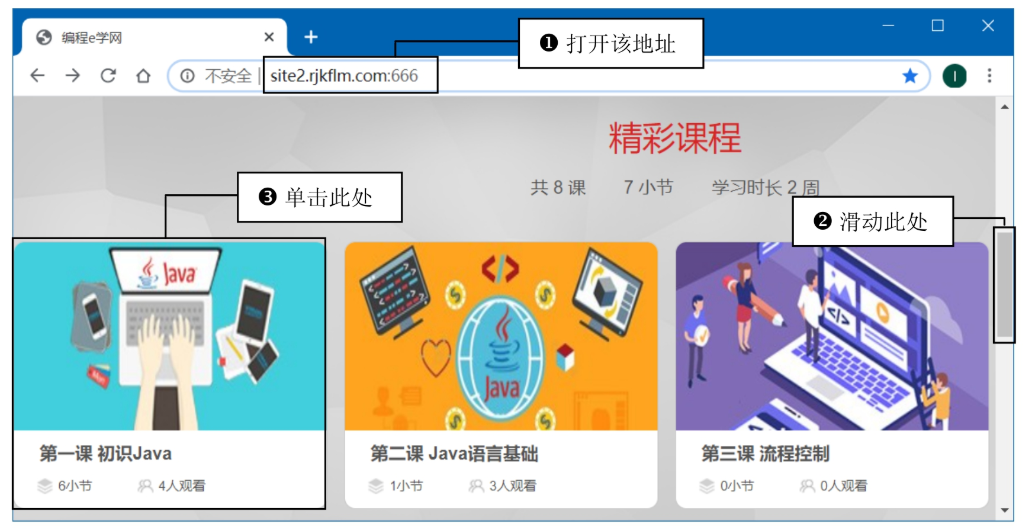
打开浏览器,访问编程e学网: http://site2.rjkflm.com:666/(注意域名可能已变更,需确认可用性)。 -
在页面“精彩课程”区域,点击“第一课 初识Java”进入课程列表。
-
 在这里插入图片描述
在这里插入图片描述
-
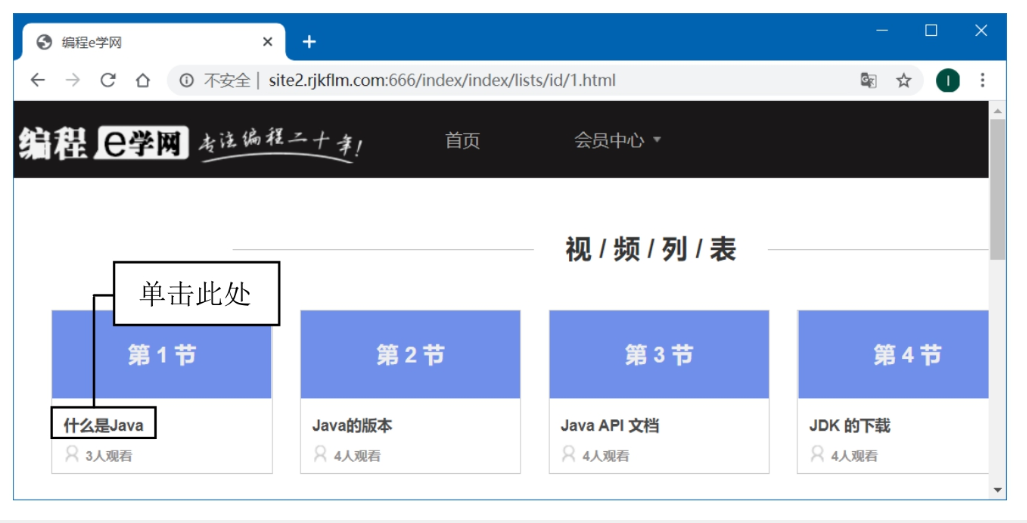
定位目标视频 -
在视频列表中找到“第1节 什么是Java”,点击进入视频播放页面。
-
 在这里插入图片描述
在这里插入图片描述
-
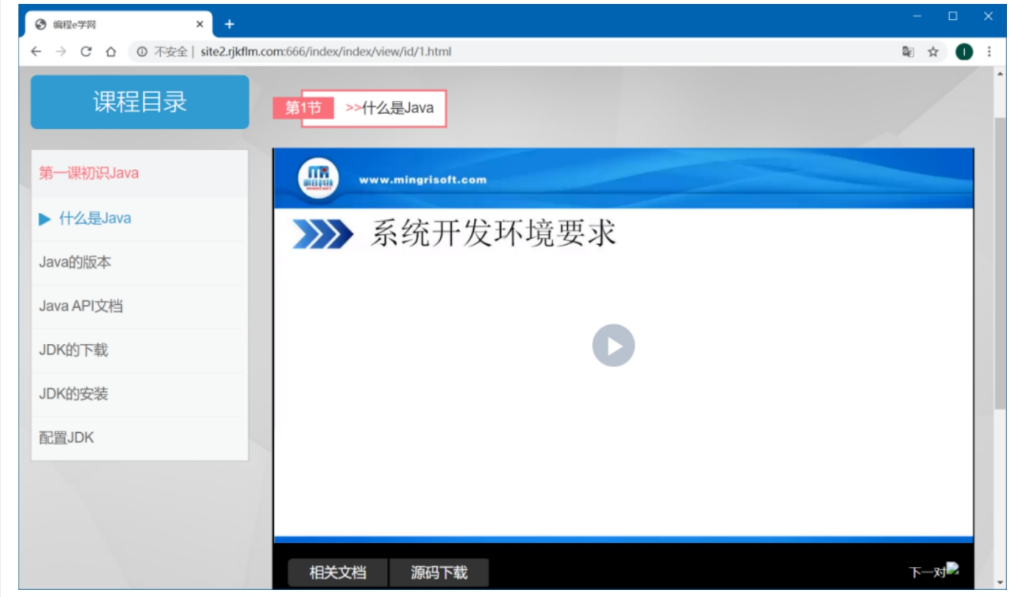
获取视频页面地址 -
记录当前页面URL(示例地址): http://site2.rjkflm.com:666/index/index/view/id/1.html
-
 在这里插入图片描述
在这里插入图片描述
🔎2.分析视频地址
-
使用开发者工具分析页面
-
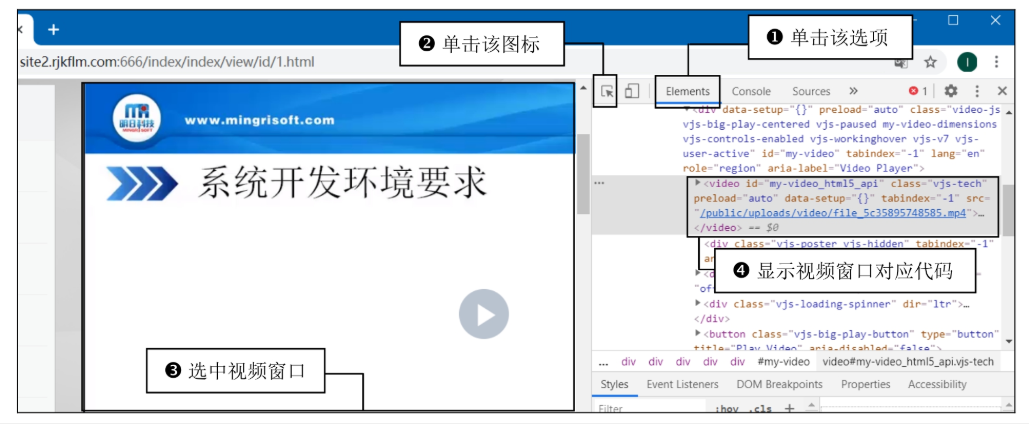
按 F12 打开浏览器开发者工具(以Chrome为例)。 -
切换到 Elements 标签,点击元素选择工具(![图标]),选中视频播放窗口。 -
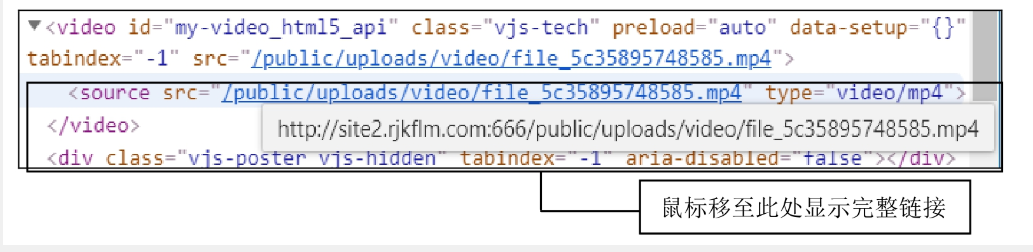
在HTML代码中找到视频标签 <source>,提取.mp4结尾的URL(可能为相对路径)。
-
-
拼接完整视频地址
-
示例代码片段中的视频地址可能为: /uploads/video/lesson1.mp4。 -
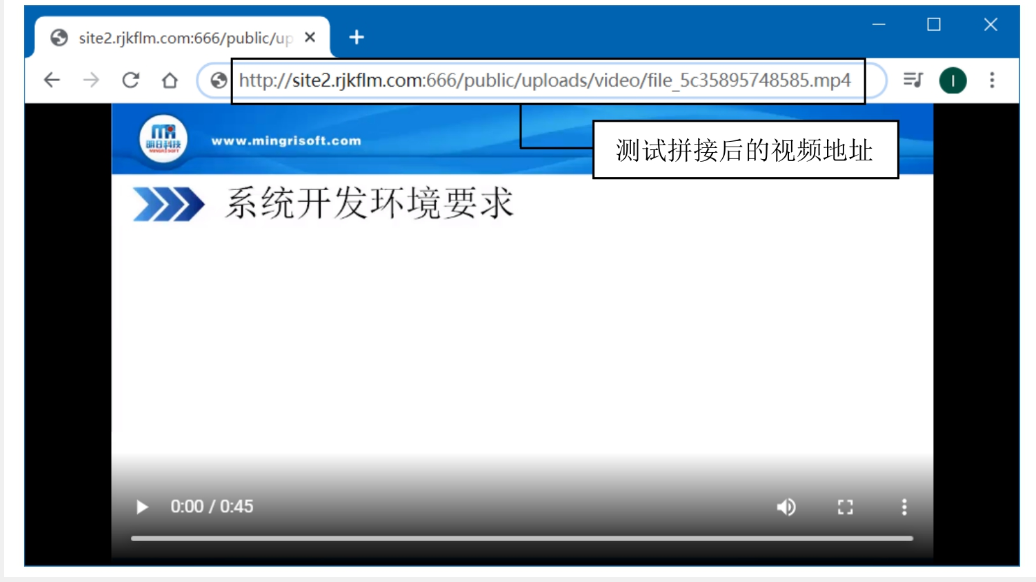
拼接网站根域名得到完整URL: http://site2.rjkflm.com:666/uploads/video/lesson1.mp4
-
-
验证地址有效性
-
将完整URL粘贴到浏览器地址栏,确认视频可播放。
-
 在这里插入图片描述
在这里插入图片描述
🔎3.实现视频下载
完整代码示例
import requests
import re
# 定义视频播放页面的URL(需确认当前有效)
url = 'http://site2.rjkflm.com:666/index/index/view/id/1.html'
# 设置请求头(模拟浏览器访问)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 发送请求获取页面内容
response = requests.get(url=url, headers=headers)
if response.status_code != 200:
print("请求失败,状态码:", response.status_code)
exit()
# 正则表达式匹配视频地址
pattern = r'<source src="(.*?)" type="video/mp4">'
match = re.findall(pattern, response.text)
if not match:
print("未找到视频地址!")
exit()
# 拼接完整视频URL
base_url = 'http://site2.rjkflm.com:666'
video_url = base_url + match[0]
# 下载视频
video_response = requests.get(video_url, headers=headers, stream=True)
if video_response.status_code == 200:
# 使用with语句安全写入文件
with open('java视频.mp4', 'wb') as f:
for chunk in video_response.iter_content(chunk_size=1024*1024): # 分块下载(避免大文件内存溢出)
if chunk:
f.write(chunk)
print("视频下载完成!")
else:
print("视频下载失败,状态码:", video_response.status_code)
 在这里插入图片描述
在这里插入图片描述
🔎4.关键步骤说明
-
请求头设置
-
使用 User-Agent模拟浏览器访问,避免被反爬虫拦截。
-
-
正则表达式匹配
-
模式 r'<source src="(.*?)" type="video/mp4">'提取视频地址的非贪婪匹配。 -
若页面结构变化,需调整正则表达式或改用其他解析方式(如 BeautifulSoup)。
-
-
分块下载视频
-
通过 stream=True和iter_content()分块写入文件,避免大文件占用内存。
-
🔎5.注意事项
-
合法性验证
-
确保目标网站允许爬取,遵守 robots.txt协议。 -
仅用于学习用途,禁止商业用途或侵犯版权。
-
-
代码健壮性
-
添加异常处理(如 try...except)应对网络错误或页面结构变更。 -
检查正则匹配结果是否存在(避免 IndexError)。
-
-
域名有效性
-
示例域名可能已失效,需替换为实际可访问的地址。
-
🔎6.运行结果
-
成功下载后,当前目录生成 java视频.mp4文件。 -
若失败,控制台输出错误原因(如状态码、未匹配到地址等)。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)