【愚公系列】《Python网络爬虫从入门到精通》010-使用search()进行匹配

【摘要】 标题详情作者简介愚公搬代码头衔华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。近期荣誉2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳...
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据处理和文本分析中,字符串匹配是不可或缺的一部分。而Python的正则表达式库为我们提供了强大的工具,其中search()函数以其灵活性和高效性,成为在文本中查找模式的理想选择。与其他匹配方法相比,search()能够在整个字符串中寻找符合条件的第一个匹配项,极大地方便了我们对数据的处理与分析。
在本期文章中,我们将深入探讨search()函数的用法及其应用场景。我们将介绍search()的基本语法、常用参数,以及与其他匹配方法(如match()和findall())的差异。通过生动的实例演示,我们将帮助你理解如何利用search()函数在复杂的文本中快速定位目标信息,提升你的数据处理能力。
🚀一、使用search()进行匹配
方法作用 :
re.search() 在整个字符串中搜索第一个匹配项,返回Match对象(匹配成功)或None(无匹配)。
语法格式
re.search(pattern, string, flags=0)
参数说明
-
pattern: 正则表达式(字符串形式) -
string: 待匹配字符串 -
flags: 修饰符(可选,如re.I忽略大小写)
🔎1.获取第一匹配值
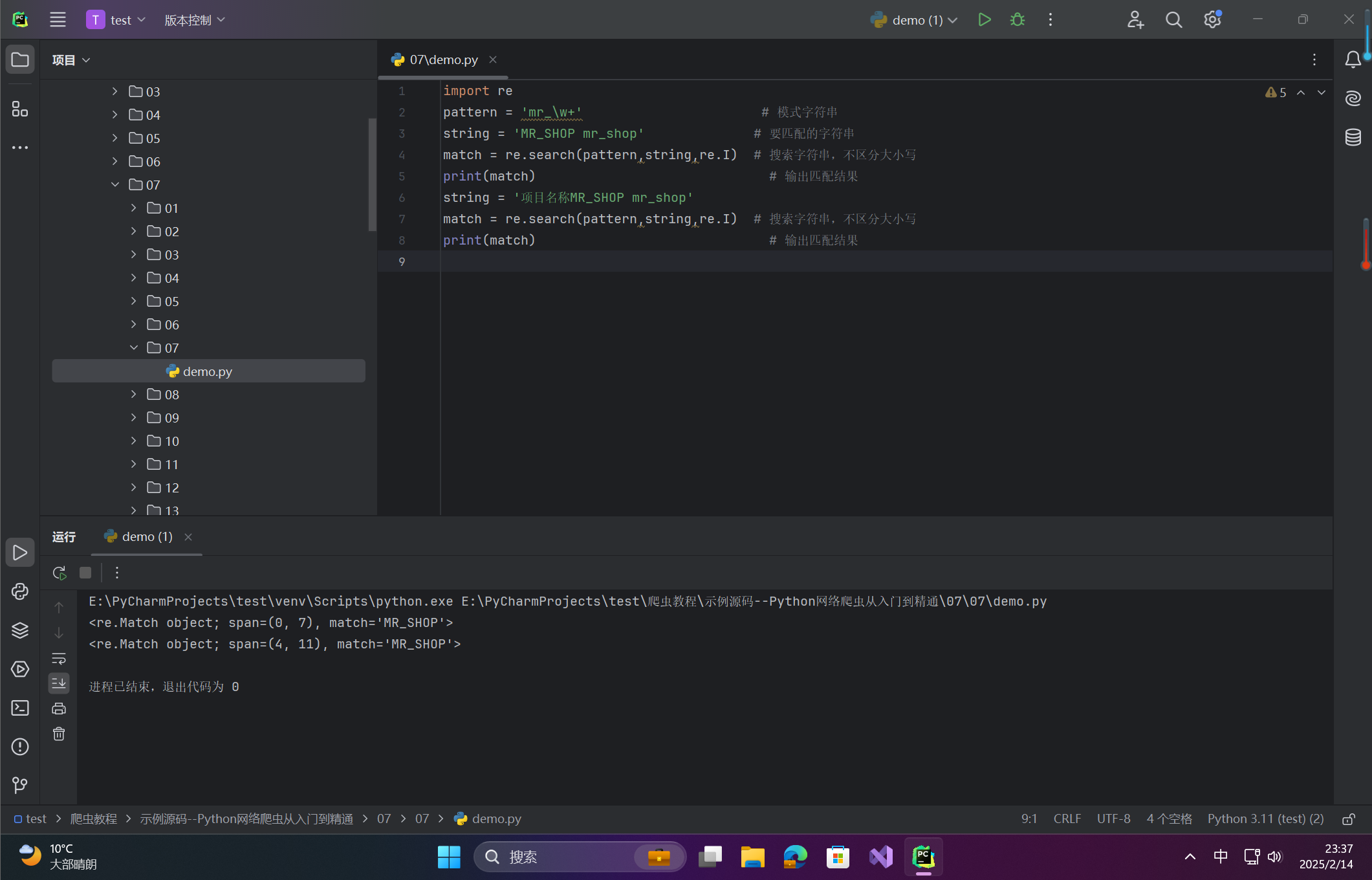
import re
pattern = 'mr_\w+' # 模式字符串
string = 'MR_SHOP mr_shop' # 要匹配的字符串
match = re.search(pattern,string,re.I) # 搜索字符串,不区分大小写
print(match) # 输出匹配结果
string = '项目名称MR_SHOP mr_shop'
match = re.search(pattern,string,re.I) # 搜索字符串,不区分大小写
print(match)
说明
-
search()不限定从字符串起始位置匹配,返回第一个有效匹配。 -
re.I修饰符使匹配不区分大小写。
 在这里插入图片描述
在这里插入图片描述
🔎2.可选匹配(使用?实现可选部分)
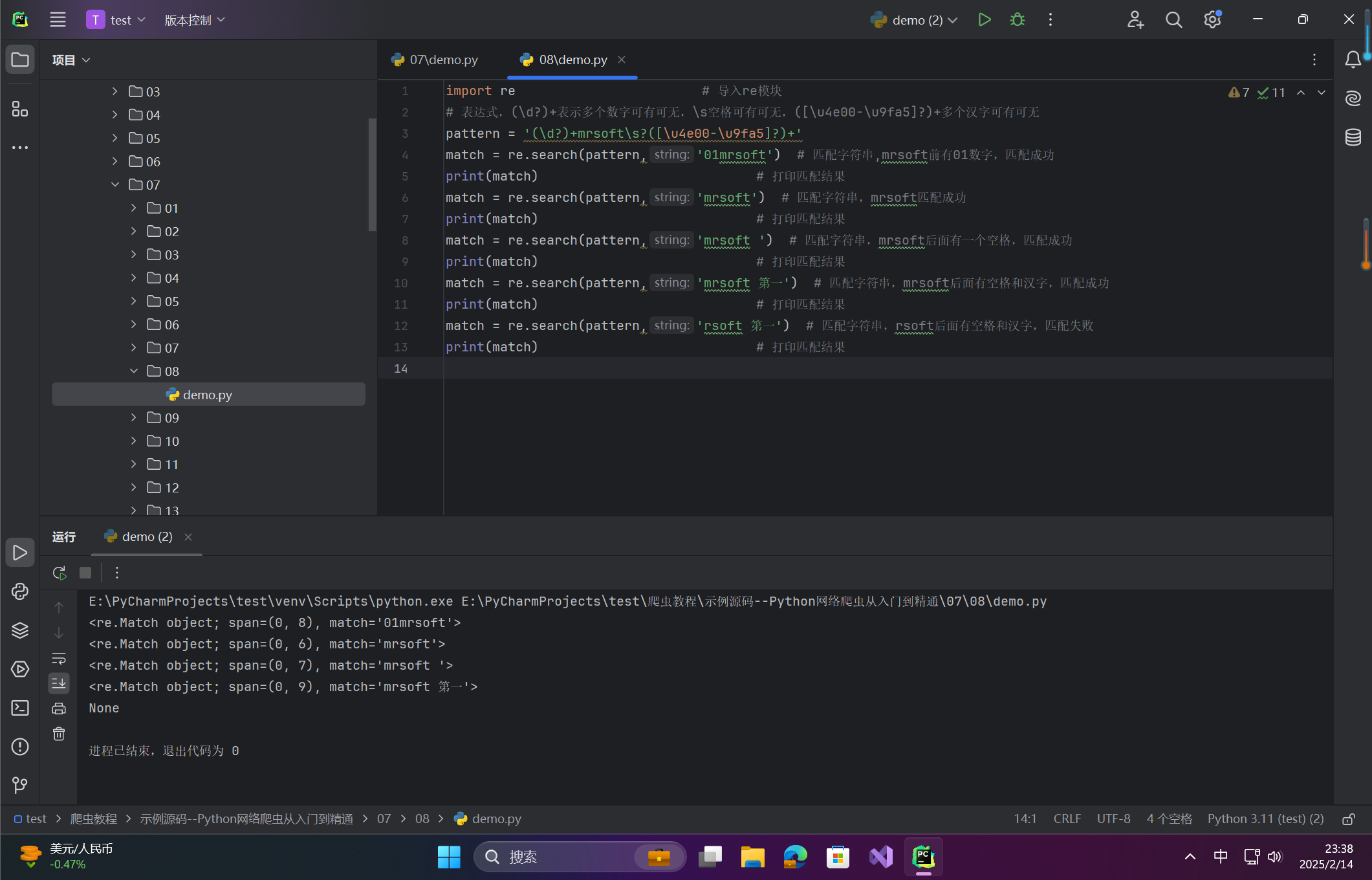
import re # 导入re模块
# 表达式,(\d?)+表示多个数字可有可无,\s空格可有可无,([\u4e00-\u9fa5]?)+多个汉字可有可无
pattern = '(\d?)+mrsoft\s?([\u4e00-\u9fa5]?)+'
match = re.search(pattern,'01mrsoft') # 匹配字符串,mrsoft前有01数字,匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,'mrsoft') # 匹配字符串,mrsoft匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,'mrsoft ') # 匹配字符串,mrsoft后面有一个空格,匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,'mrsoft 第一') # 匹配字符串,mrsoft后面有空格和汉字,匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,'rsoft 第一') # 匹配字符串,rsoft后面有空格和汉字,匹配失败
print(match) # 打印匹配结果
关键点
-
?表示其前字符/组可省略(0或1次出现)。 -
rsoft第一匹配失败,因缺少完整的mrsoft。
 在这里插入图片描述
在这里插入图片描述
🔎3.匹配字符串边界(使用\b)
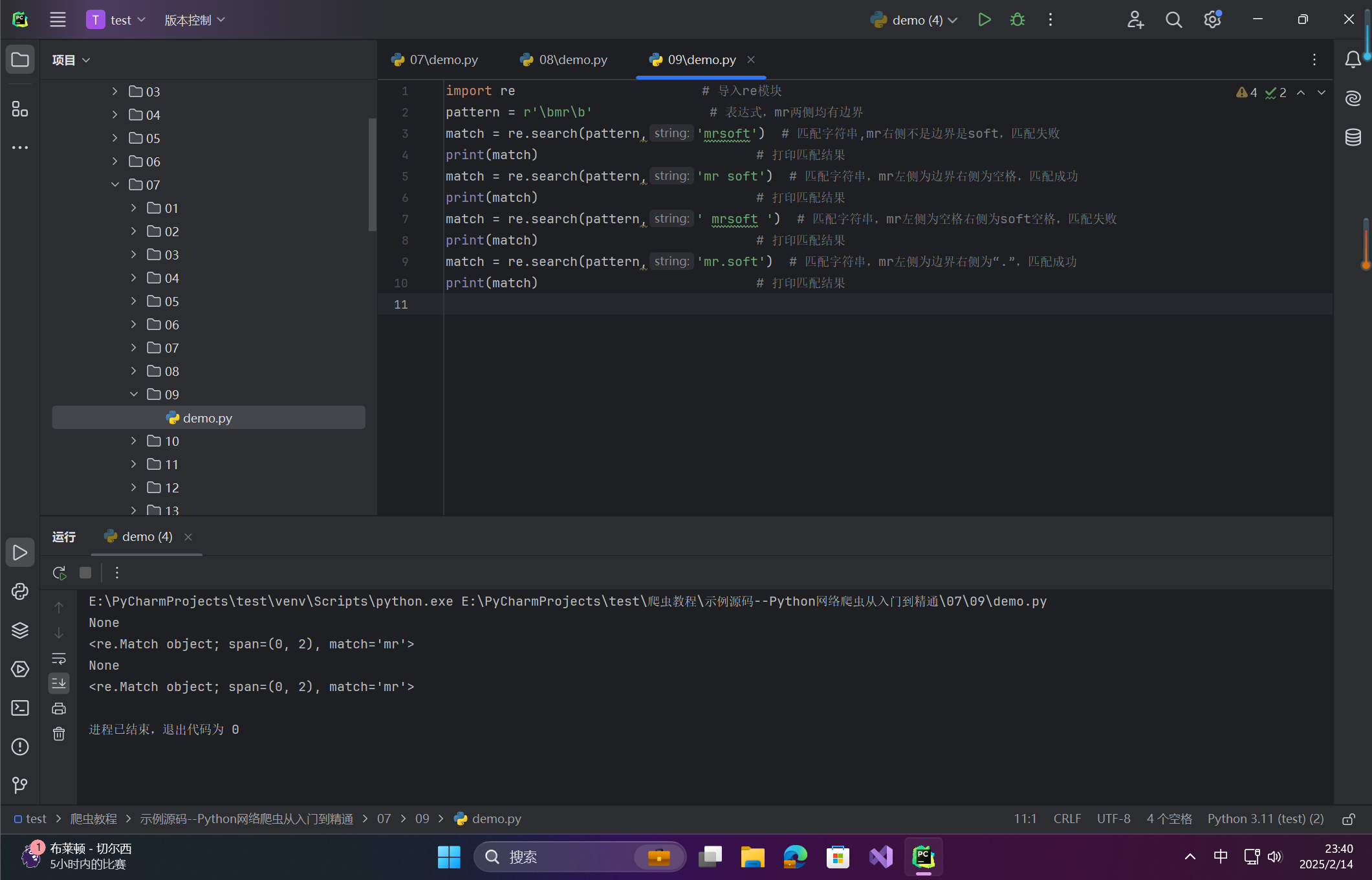
import re # 导入re模块
pattern = r'\bmr\b' # 表达式,mr两侧均有边界
match = re.search(pattern,'mrsoft') # 匹配字符串,mr右侧不是边界是soft,匹配失败
print(match) # 打印匹配结果
match = re.search(pattern,'mr soft') # 匹配字符串,mr左侧为边界右侧为空格,匹配成功
print(match) # 打印匹配结果
match = re.search(pattern,' mrsoft ') # 匹配字符串,mr左侧为空格右侧为soft空格,匹配失败
print(match) # 打印匹配结果
match = re.search(pattern,'mr.soft') # 匹配字符串,mr左侧为边界右侧为“.”,匹配成功
print(match) # 打印匹配结果
关键点
-
\b匹配单词边界(如空格、标点、字符串首尾)。 -
原始模式需用 r''避免转义错误。
 在这里插入图片描述
在这里插入图片描述
🔎4.注意事项
-
正则表达式语法 -
Unicode字符范围需正确书写(如 \u4e00-\u9fa5匹配汉字)。 -
使用原始字符串( r'')避免转义问题。
-
-
方法对比 -
re.match()仅从字符串起始位置匹配。 -
re.search()搜索整个字符串。
-
-
修饰符 -
常用修饰符: re.I(忽略大小写)、re.M(多行模式)。
-
通过修正后的代码和解析,可更清晰地理解re.search()的应用场景及正则语法细节。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)