【愚公系列】《Python网络爬虫从入门到精通》008-正则表达式基础

| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在数据处理和文本分析的领域,正则表达式(Regex)无疑是一项强大的工具。它以其灵活性和高效性,帮助我们从杂乱无章的文本中提取出所需的信息,进行模式匹配和数据验证。无论是在编程、数据清洗,还是在Web开发中,正则表达式都扮演着不可或缺的角色。
在本期文章中,我们将深入探索正则表达式的基础知识。我们将介绍正则表达式的基本构成、常用符号及其功能,帮助你掌握这一强大工具的使用技巧。从简单的匹配到复杂的模式识别,我们将通过实例演示,让你轻松理解正则表达式的应用场景及其背后的逻辑。
🚀一、正则表达式基础
正则表达式用于在字符串中进行模式匹配、排除、分组等操作。在Web开发中,获取的HTML代码通常以字符串形式返回,正则表达式可以高效地对这些字符串进行处理。
🔎1.行定位符
-
^:表示行的开始位置。 -
$:表示行的结尾位置。示例:
-
^tm:匹配以tm开头的行。 -
tm$:匹配以tm结尾的行。 -
tm:匹配tm出现在字符串的任何部分。
-
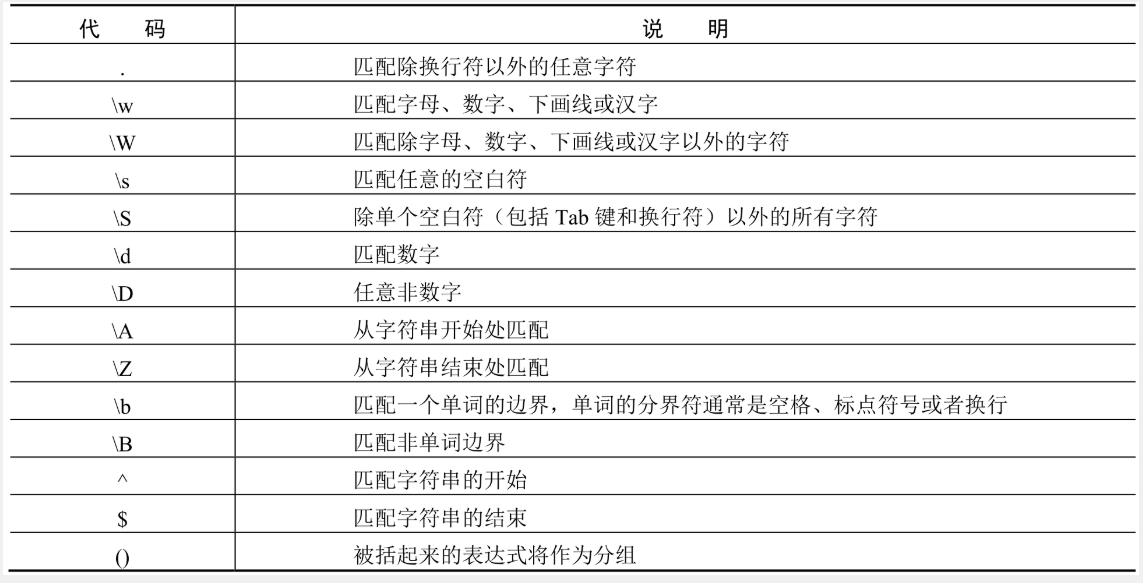
🔎2.元字符
正则表达式中有许多元字符(用于定义匹配规则),如:
-
.:匹配任意字符(除了换行符)。 -
\w:匹配字母、数字或下划线。 -
\d:匹配数字。 -
\s:匹配空白符(包括空格、Tab键、换行符等)。示例:
-
\b:匹配单词边界。 -
\W:匹配非字母数字字符。
-
 在这里插入图片描述
在这里插入图片描述
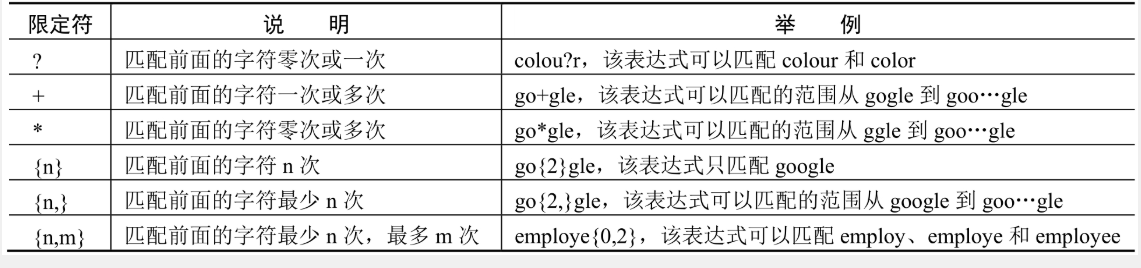
🔎3.限定符
限定符用于指定字符出现的次数:
-
*:零次或多次。 -
+:一次或多次。 -
?:零次或一次。 -
{n}:恰好n次。 -
{n,}:至少n次。 -
{n,m}:至少n次,但不超过m次。示例:
-
\d{8}:匹配恰好8位数字。
-
 在这里插入图片描述
在这里插入图片描述
🔎4.字符类
字符类用于定义一个字符集合,方括号内列出允许匹配的字符:
-
[aeiou]:匹配任意一个元音字母。 -
[0-9]:匹配数字。 -
[a-zA-Z]:匹配字母。示例:
-
[\u4e00-\u9fa5]:匹配任意汉字。
-
🔎5.排除字符
使用 ^ 在方括号内表示排除指定的字符:
-
[^a-zA-Z]:匹配非字母字符。
🔎6.选择字符
选择字符(|)用于匹配多个模式中的一个:
-
a|b:匹配a或b。示例:
-
身份证号码: (\d{18}$)|(\d{17}(\d|X|x))。
-
🔎7.转义字符
在正则表达式中,某些字符(如 .、*、?)是元字符,如果要匹配它们本身,需要使用反斜杠 \ 进行转义。
示例:
-
IP地址: [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}。
🔎8.分组
通过小括号 () 将表达式分组,方便应用限定符或进行捕获。
-
(abc){2}:匹配abc重复2次。示例:
-
(\d{3})-(\d{3}):匹配如123-456的格式。
-
🔎9.在Python中使用正则表达式
-
正则表达式在Python中通常以原生字符串的形式表示(在字符串前加
r或R),这样可以避免反斜杠被错误转义。示例:
import re pattern = r'\d{8}' match = re.match(pattern, '12345678')

- 点赞
- 收藏
- 关注作者
评论(0)