【愚公系列】《Python网络爬虫从入门到精通》005-请求模块requests

| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在Python的丰富生态中,网络请求是我们进行数据交互和服务集成的重要环节。而在众多网络请求库中,requests模块凭借其简洁易用的接口和强大的功能,成为了开发者的首选。无论是发送GET、POST请求,还是处理响应数据,requests都能轻松应对,极大地简化了我们的编码工作。
在这篇文章中,我们将深入探索requests模块的基本用法和一些高级特性,帮助你更好地理解如何使用它进行高效的网络请求。同时,我们还会介绍一些常见的用例,如API调用、数据抓取和错误处理等,确保你能够在实际项目中灵活运用。
🚀一、请求模块requests
🔎1. 安装与简介
-
安装: pip install requests -
核心特性: -
支持 Keep-Alive 和连接池 -
国际化域名与 URL -
持久化 Cookie 会话 -
自动内容解码(JSON、文本、二进制) -
SSL 认证、代理支持、文件分块上传 -
超时控制、异常处理
-
🔎2. 基础请求方式
🦋2.1 GET 请求
示例:不带参数的 GET 请求
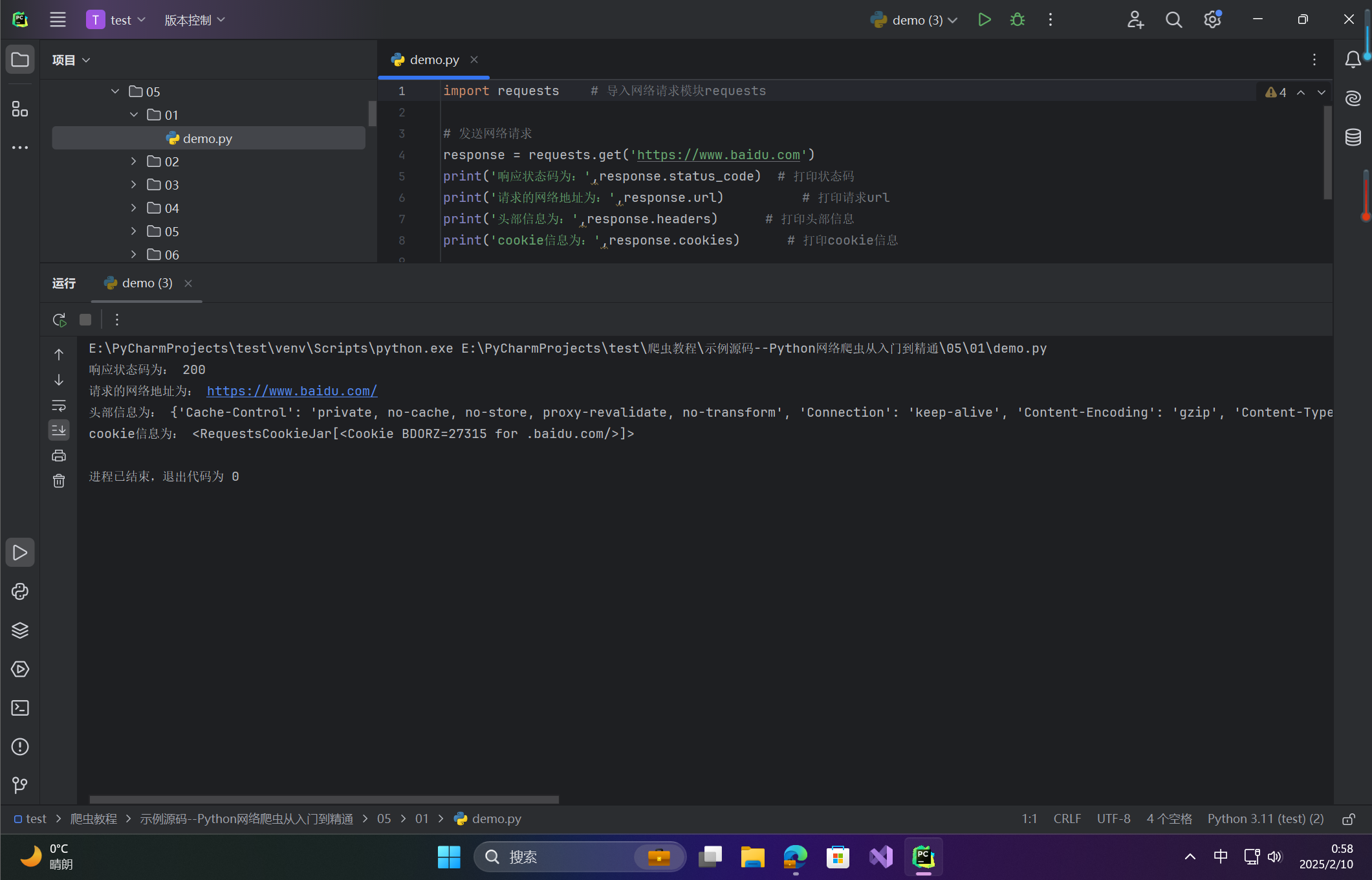
import requests # 导入网络请求模块requests
# 发送网络请求
response = requests.get('https://www.baidu.com')
print('响应状态码为:',response.status_code) # 打印状态码
print('请求的网络地址为:',response.url) # 打印请求url
print('头部信息为:',response.headers) # 打印头部信息
print('cookie信息为:',response.cookies) # 打印cookie信息
 在这里插入图片描述
在这里插入图片描述
示例:处理响应编码(UTF-8)
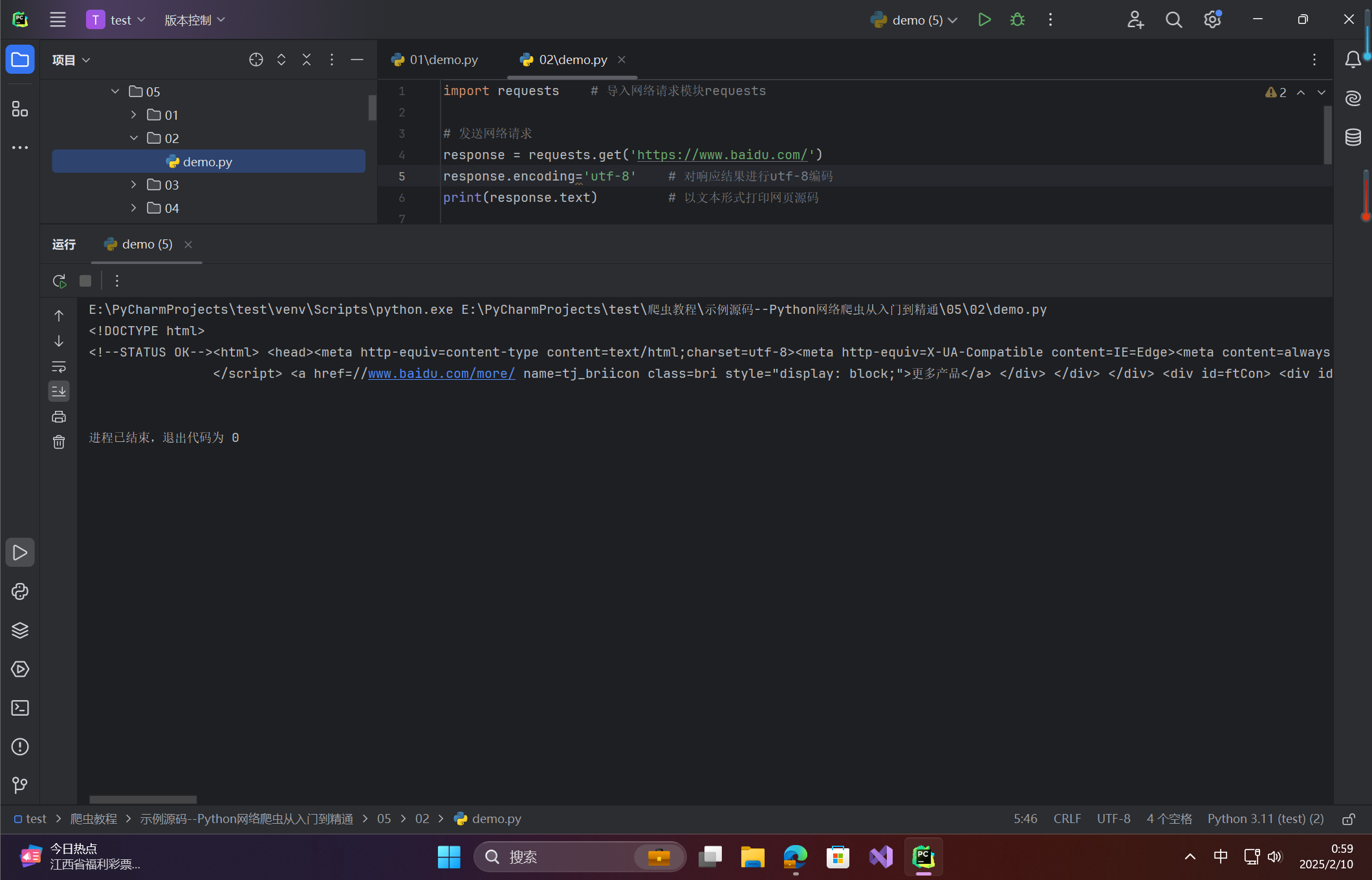
import requests # 导入网络请求模块requests
# 发送网络请求
response = requests.get('https://www.baidu.com/')
response.encoding='utf-8' # 对响应结果进行utf-8编码
print(response.text) # 以文本形式打印网页源码
 在这里插入图片描述
在这里插入图片描述
示例:下载二进制文件(如图片)
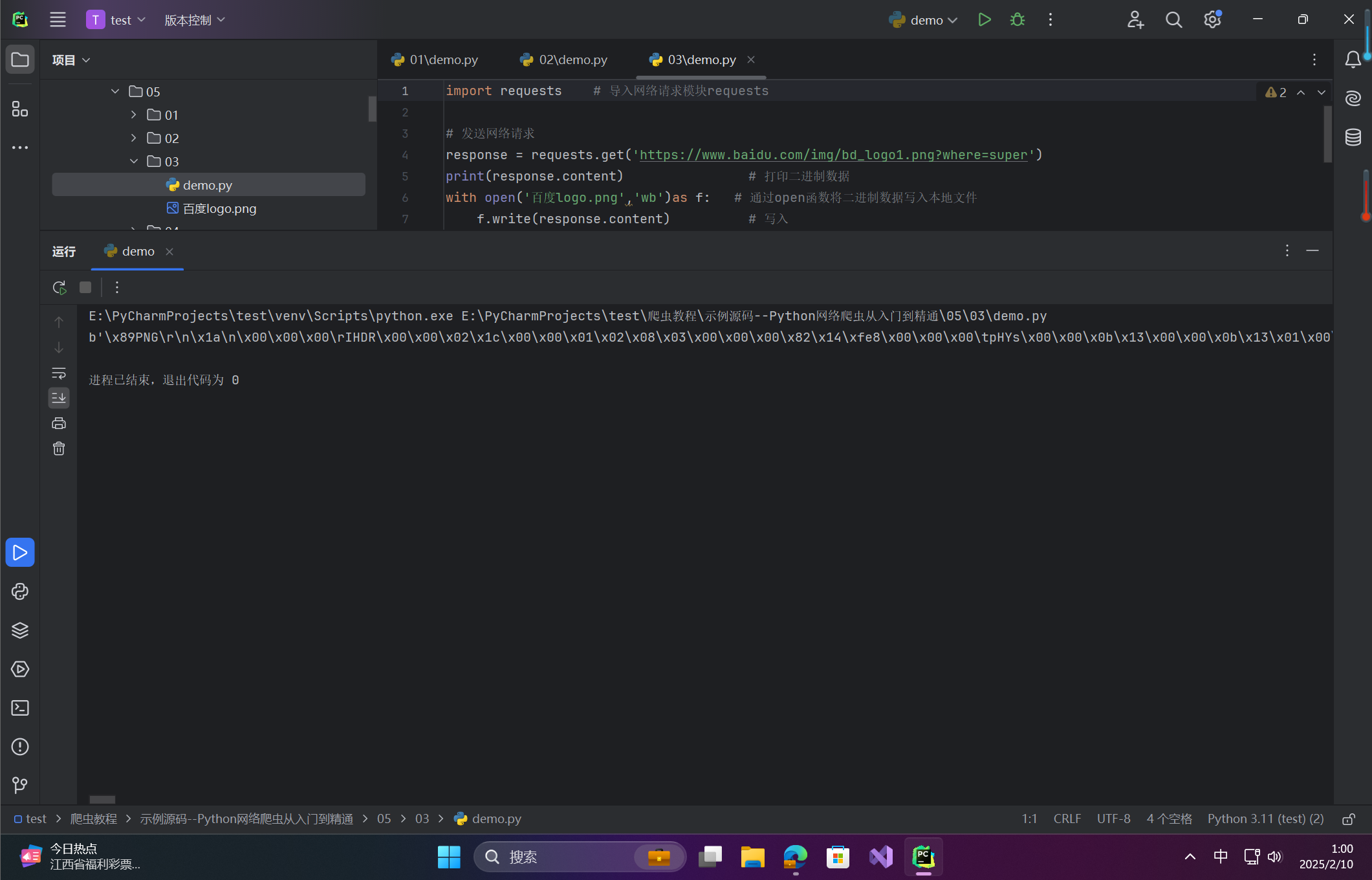
import requests # 导入网络请求模块requests
# 发送网络请求
response = requests.get('https://www.baidu.com/img/bd_logo1.png?where=super')
print(response.content) # 打印二进制数据
with open('百度logo.png','wb')as f: # 通过open函数将二进制数据写入本地文件
f.write(response.content) # 写入

示例:带参数的 GET 请求
# 直接在 URL 中拼接参数
response = requests.get('http://httpbin.org/get?name=Jack&age=30')
# 使用 params 参数传递字典
data = {'name': 'Michael', 'age': '36'}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text) # 显示参数在 args 字段中
🦋2.2 POST 请求
示例:发送表单数据
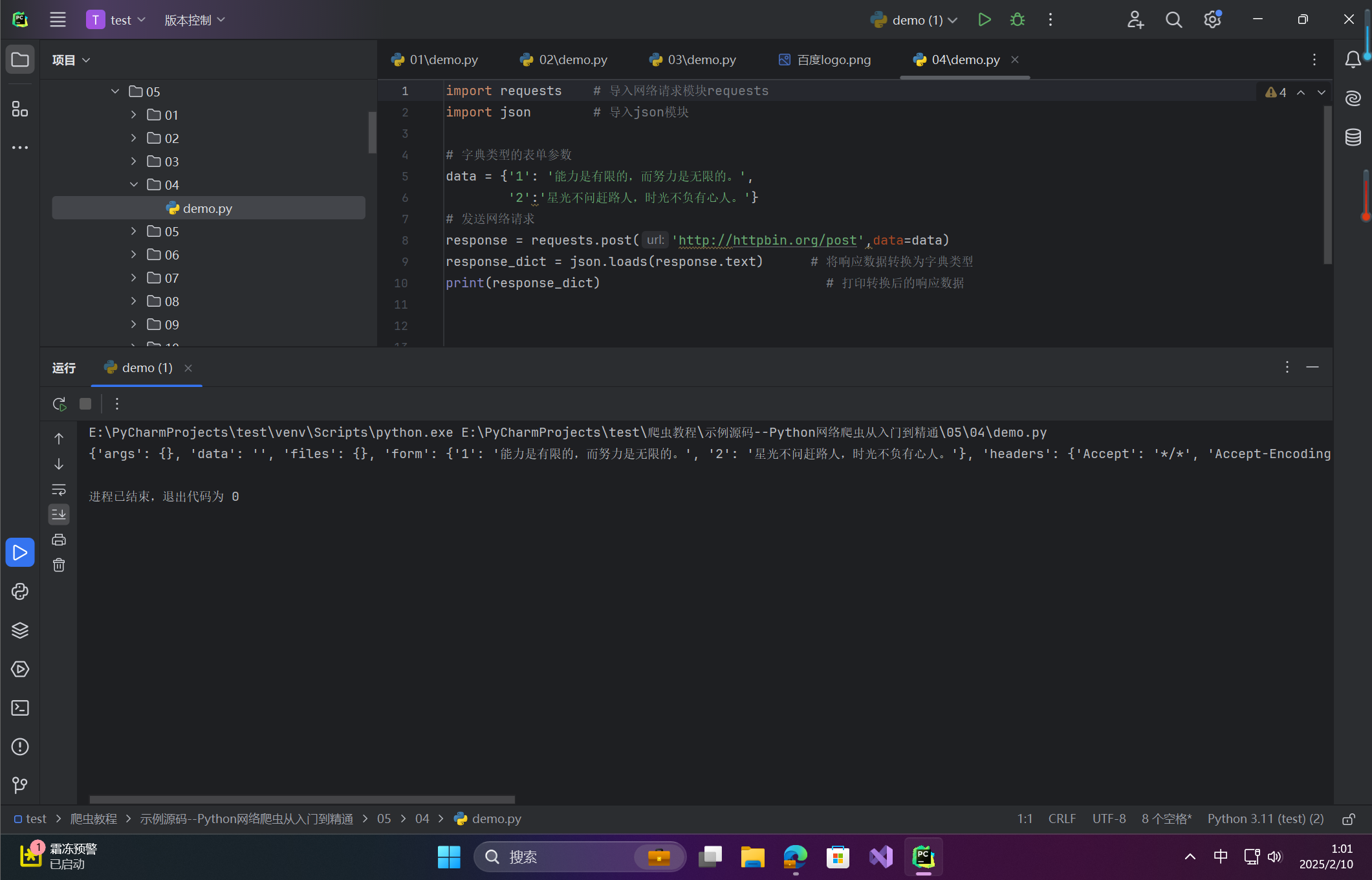
import requests # 导入网络请求模块requests
import json # 导入json模块
# 字典类型的表单参数
data = {'1': '能力是有限的,而努力是无限的。',
'2':'星光不问赶路人,时光不负有心人。'}
# 发送网络请求
response = requests.post('http://httpbin.org/post',data=data)
response_dict = json.loads(response.text) # 将响应数据转换为字典类型
print(response_dict) # 打印转换后的响应数据
 在这里插入图片描述
在这里插入图片描述
🔎3. 复杂请求处理
🦋3.1 添加请求头
示例:模拟浏览器请求头
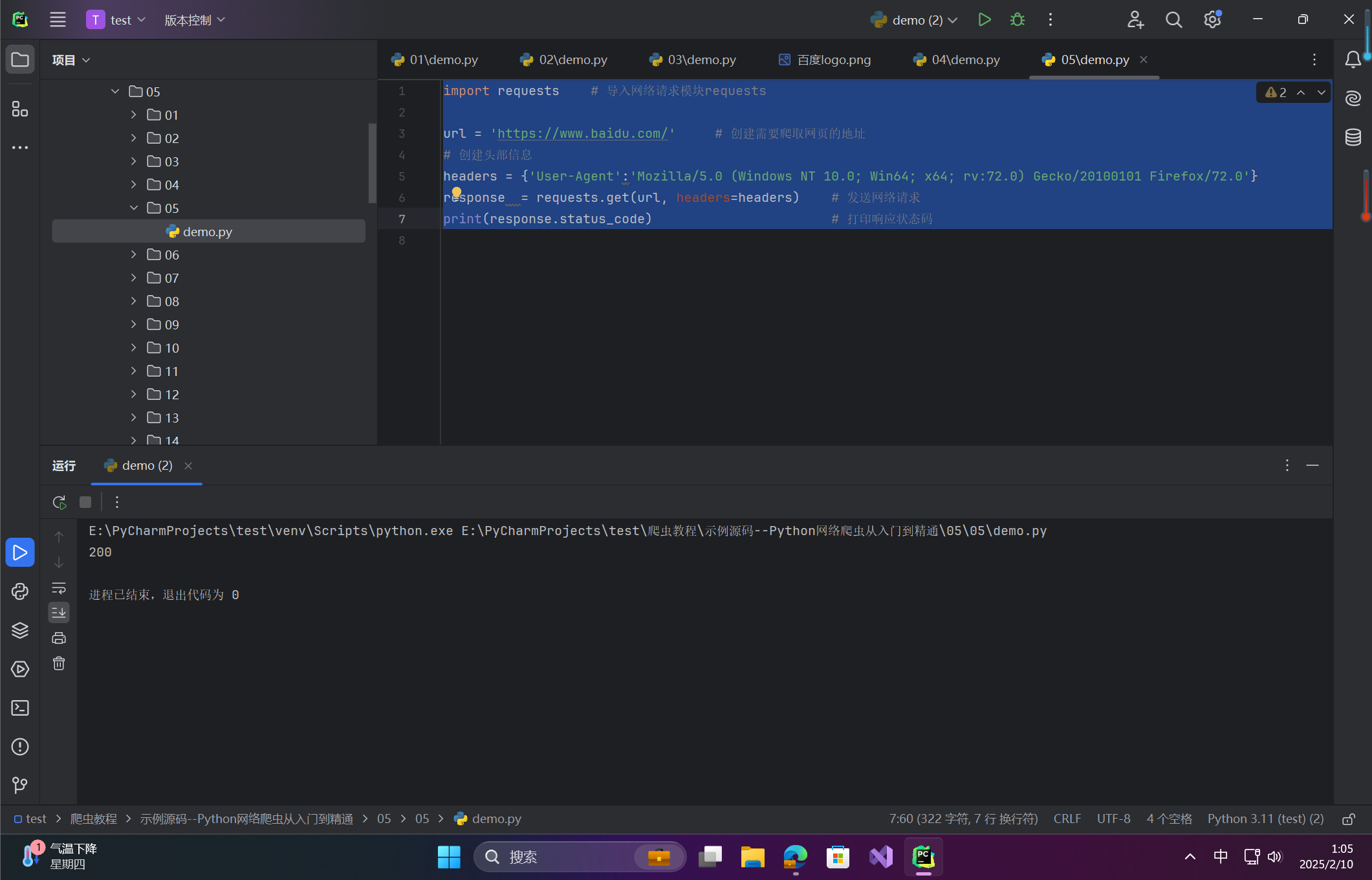
import requests # 导入网络请求模块requests
url = 'https://www.baidu.com/' # 创建需要爬取网页的地址
# 创建头部信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0'}
response = requests.get(url, headers=headers) # 发送网络请求
print(response.status_code) # 打印响应状态码
 在这里插入图片描述
在这里插入图片描述
🦋3.2 处理 Cookies
在爬取某些数据时,需要进行网页的登录,才可以进行数据的抓取工作。Cookies登录就像很多网页中的自动登录功能一样,可以让用户在第二次登录时,在不需要验证账号和密码的情况下进行登录。在使用requests模块实现Cookies登录时,首先需要在浏览器的开发者工具页面中找到可以实现登录的Cookies信息,然后将Cookies信息处理并添加至RequestsCookieJar的对象中,最后将RequestsCookieJar对象作为网络请求的Cookies参数,发送网络请求即可。以获取豆网页登录后的用户名为例,具体步骤如下。
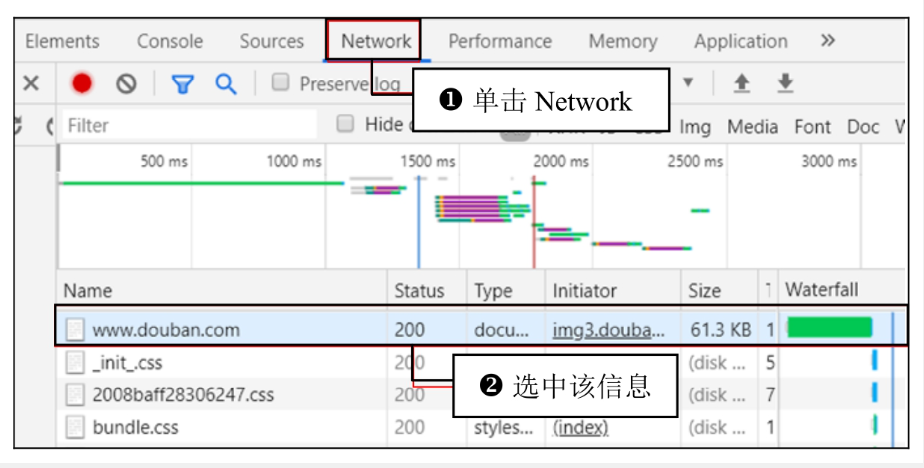
(1)在谷歌浏览器中打开豆瓣网页地址(https://www.douban.com/),然后按F12键打开网络监视器,选择“密码登录”输入“手机号/邮箱”与“密码”,然后单击“登录豆瓣”,网络监视器将显示如图所示的数据变化。
 (2)在Headers选项中选中Request Headers选项,获取登录后的Cookie信息,如图所示。
(2)在Headers选项中选中Request Headers选项,获取登录后的Cookie信息,如图所示。 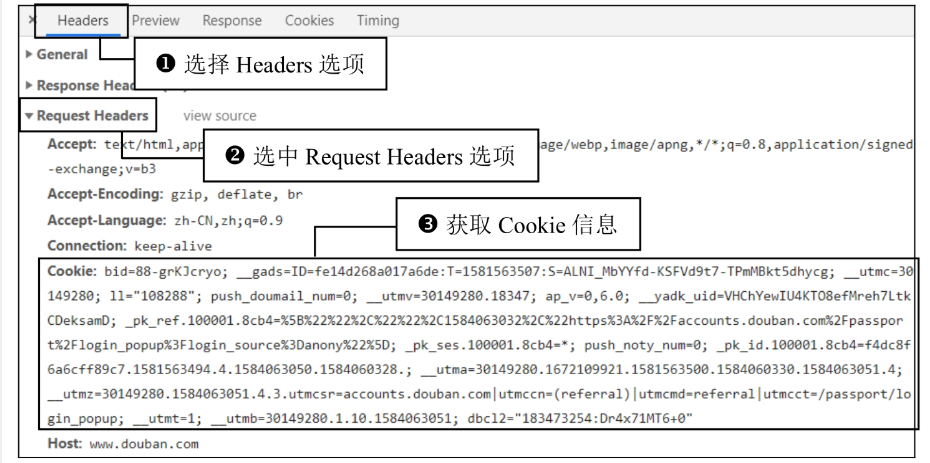 (3)导入相应的模块,将“找到登录后网页中的Cookie信息”以字符串形式保存,然后创建RequestsCookieJar()对象并对Cookie信息进行处理,最后将处理后的RequestsCookieJar()对象作为网络请求参数,实现网页的登录请求。代码如下:
(3)导入相应的模块,将“找到登录后网页中的Cookie信息”以字符串形式保存,然后创建RequestsCookieJar()对象并对Cookie信息进行处理,最后将处理后的RequestsCookieJar()对象作为网络请求参数,实现网页的登录请求。代码如下:
import requests # 导入网络请求模块
from lxml import etree # 导入lxml模块
cookies = '此处填写登录后网页中的cookie信息'
headers = {'Host': 'www.douban.com',
'Referer': 'https://www.hao123.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'}
# 创建RequestsCookieJar对象,用于设置cookies信息
cookies_jar = requests.cookies.RequestsCookieJar()
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
cookies_jar.set(key, value) # 将cookies保存RequestsCookieJar当中
# 发送网络请求
response = requests.get('https://www.douban.com/',
headers=headers, cookies=cookies_jar)
if response.status_code == 200: # 请求成功时
html = etree.HTML(response.text) # 解析html代码
# 获取用户名
name = html.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]/text()')
print(name[0]) # 打印用户名
🦋3.3 会话管理
示例:使用 Session 保持登录状态
import requests # 导入requests模块
s = requests.Session() # 创建会话对象
data={'username': 'mrsoft', 'password': 'mrsoft'} # 创建用户名、密码的表单数据
# 发送登录请求
response =s.post('http://site2.rjkflm.com:666/index/index/chklogin.html',data=data)
response2=s.get('http://site2.rjkflm.com:666') # 发送登录后页面请求
print('登录信息:',response.text) # 打印登录信息
print('登录后页面信息如下:\n',response2.text) # 打印登录后的页面信息
🦋3.4 身份验证
 在这里插入图片描述
在这里插入图片描述
示例:HTTP 基础认证
import requests # 导入requests模块
from requests.auth import HTTPBasicAuth # 导入HTTPBasicAuth类
# 定义请求地址
url = 'http://sck.rjkflm.com:666/spider/auth/'
ah = HTTPBasicAuth('admin','admin') # 创建HTTPBasicAuth对象,参数为用户名与密码
response = requests.get(url=url,auth=ah) # 发送网络请求
if response.status_code==200: # 如果请求成功
print(response.text) # 打印验证后的HTML代码
🦋3.5 处理超时与异常
示例:设置超时并捕获异常
import requests # 导入网络请求模块
# 循环发送请求50次
for a in range(0, 50):
try: # 捕获异常
# 设置超时为0.5秒
response = requests.get('https://www.baidu.com/', timeout=0.1)
print(response.status_code) # 打印状态码
except Exception as e: # 捕获异常
print('异常'+str(e)) # 打印异常信息
示例:网络异常分类
import requests # 导入网络请求模块
# 导入requests.exceptions模块中的三种异常类
from requests.exceptions import ReadTimeout,HTTPError,RequestException
# 循环发送请求50次
for a in range(0, 50):
try: # 捕获异常
# 设置超时为0.5秒
response = requests.get('https://www.baidu.com/', timeout=0.1)
print(response.status_code) # 打印状态码
except ReadTimeout: # 超时异常
print('timeout')
except HTTPError: # HTTP异常
print('httperror')
except RequestException: # 请求异常
print('reqerror')
🦋3.6 上传文件
示例:上传图片文件
import requests # 导入网络请求模块
bd = open('百度logo.png','rb') # 读取指定文件
file = {'file':bd} # 定义需要上传的图片文件
# 发送上传文件的网络请求
response = requests.post('http://httpbin.org/post',files = file)
print(response.text) # 打印响应结果
 在这里插入图片描述
在这里插入图片描述
🔎4. 代理服务
🦋4.1 使用代理发送请求
示例:设置代理 IP
import requests # 导入网络请求模块
# 头部信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'}
proxy = {'http': 'http://117.88.176.38:3000',
'https': 'https://117.88.176.38:3000'} # 设置代理ip与对应的端口号
try:
# 对需要爬取的网页发送请求,verify=False不验证服务器的SSL证书
response = requests.get('http://2020.ip138.com', headers= headers,proxies=proxy,verify=False,timeout=3)
print(response.status_code) # 打印响应状态码
except Exception as e:
print('错误异常信息为:',e) # 打印异常信息
🦋4.2 获取与检测代理 IP
示例:爬取免费代理 IP
import requests # 导入网络请求模块
from lxml import etree # 导入HTML解析模块
import pandas as pd # 导入pandas模块
# 头部信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'}
# 发送网络请求
response = requests.get('https://www.xicidaili.com/nn/', headers=headers)
response.encoding = 'utf-8' # 设置编码方式
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析HTML
table = html.xpath('//table[@id="ip_list"]')[0] # 获取table标签内容
trs = table.xpath('//tr')[1:] # 获取所有tr标签,排除第一条
ip_table = pd.DataFrame(columns=['ip']) # 创建临时表格数据
ip_list = [] # 创建保存ip地址的列表
# 循环遍历标签内容
for t in trs:
ip = t.xpath('td/text()')[0] # 获取代理ip
port = t.xpath('td/text()')[1] # 获取端口
ip_list.append(ip+':'+port) # 将ip与端口组合并添加至列表当中
print('代理ip为:', ip, '对应端口为:', port)
ip_table['ip']=ip_list # 将提取的ip保存至excel文件中的ip列
# 生成xlsx文件
ip_table.to_excel('ip.xlsx', sheet_name='data')
示例:检测代理 IP 有效性
import requests # 导入网络请求模块
import pandas # 导入pandas模块
from lxml import etree # 导入HTML解析模块
ip_table = pandas.read_excel('ip.xlsx') # 读取代理IP文件内容
ip = ip_table['ip'] # 获取代理ip列信息
# 头部信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'}
# 循环遍历代理IP并通过代理发送网络请求
for i in ip:
proxies = {'http': 'http://{ip}'.format(ip=i),
'https': 'https://{ip}'.format(ip=i)}
try:
# verify=False不验证服务器的SSL证书
response = requests.get('http://2020.ip138.com/',
headers=headers,proxies=proxies,verify=False,timeout=2)
if response.status_code==200: # 判断请求是否成功,请求成功说明代理IP可用
response.encoding='utf-8' # 进行编码
html = etree.HTML(response.text) # 解析HTML
info = html.xpath('/html/body/p[1]/text()')
print(info[0].strip()) # 输出当前ip匿名信息
except Exception as e:
pass
# print('错误异常信息为:',e) # 打印异常信息

- 点赞
- 收藏
- 关注作者
评论(0)