如何优雅的设计一个分布式锁

如何设计一个分布式锁?
今天,叶秋老哥又去面试了,只见美女面试官微微一笑,问了我一个问题,听完后,内心一颤,不知道是被她迷人的笑容给迷倒,还是被她的致命问题给问倒。不过还是内心一收,正襟危坐,吧啦吧啦了一堆,如下:
对于如何设计一个分布式锁,我认为我们应该先了解什么是分布式锁?
1、什么是分布式锁
我个人理解的分布式锁,顾名思义就是分布式系统下的锁。在分布式系统中,若数据只有一份,那么在同一时刻,或许会有多个机器访问修改该数据,那么为了保证该数据的一致性和可见性,我们就需要一个锁,当有机器访问该数据时,就把该数据锁住,来提醒别的机器,“我”已经有别的机器获取到了,你们再等会。
2、那么分布式锁,具备什么条件呢?
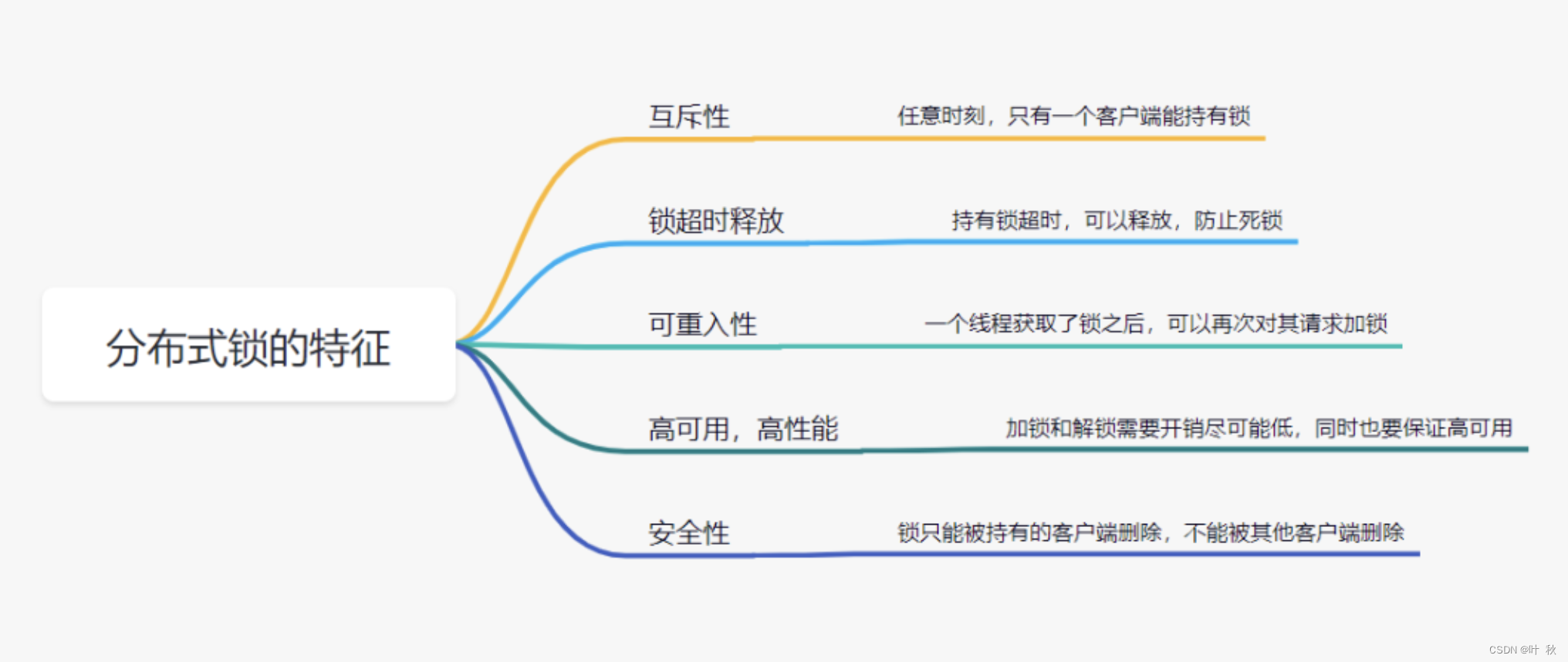
- 四个一:在分布式系统下,同一个方法在同一时间只能被一台机器上的一个线程执行。
- 三个具备:具备可重入锁特性(防止死锁)、具备阻塞锁特性、具备公平锁特性。
- 两个高:高性能、高可用的获取和释放锁,不能死锁。
3、设计分布式锁有哪些方式?
对于如何设计一个分布式锁,我认为有以下几种方式,分别是:
- 利用redis做分布式锁(小样,上次面试把你给漏了,这次先说你)
- 数据库做分布式锁
- 利用zookeeper做分布式锁
3.1 利用redis实现分布式锁原理
在redis中,我们可以利用redis 的 setnx()、expire() 方法做分布式锁。
首先 setnx()方法它有两个参数:setnx(key,value),含义就是,如果key不存在,则设置当前key成功,并返回状态码1。如果key存在,则设置当前key失败,并返回状态码0。并且由于该方法是原子性的,所以可以考虑使用该方法。
并且配合expire()方法,来设置key的过期时间。
整体流程如下:
- setnx(key,value)如果返回0,代表key已存在,设置失败;如果返回1,代表key不存在,设置成功。
- 然后使用
expire(key),对key设置超时时间,避免死锁问题。 - 然后线程访问完毕后,调用delete命令删除该key。代表使用完毕,其他线程可以竞争该锁。
3.2 基于数据库做分布式锁
第二种方法就是基于数据库的排他锁来实现分布式锁。
我们都知道,在数据库的查询语句后面加上 for update后,数据库就会给该条数据加上排他锁,这样,其他线程就无法再访问该条记录了。我们可以以此来认为获得排他锁的线程即获得了分布式锁。然后执行自己的业务逻辑,最后通过 connection.commit()来释放锁。
使用这种方式的优点是:
- 简单,易于理解
- 不需要引入别的技术,成本低
缺点是:
- 对数据库依赖性大
- 操作数据库有一定的性能开销
3.3 基于zookeeper实现分布式锁
再说zookeeper之前,先说下zookeeper的锁原理:
利用临时节点与 watch 机制。每个锁占用一个普通节点 /lock,当需要获取锁时在 /lock 目录下创建一个临时节点,创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁。临时节点好处 在于当进程挂掉后能自动上锁的节点自动删除即取消锁。
缺点:所有取锁失败的进程都监听父节点,很容易发生羊群效应,即当释放锁后所有等待进程一起来创建节点,并发量很大。
说清楚了原理,用代码实现也就不难了,可以引入zookeeper的客户端zkClient。
所以设计一个分布式锁大致有以上几种方法,但具体使用哪一种方式比较合理,就应该根据实际场景来具体分析了。

- 点赞
- 收藏
- 关注作者
评论(0)