Java流操作解析:深度剖析中间操作、终端操作与并行处理机制


文章目录
对于如何来到filter过滤操作的源码位置,读者可以参考我的上一篇博客哈,具体的步骤都已经详细给出。

主要作用:创建一个新的无状态操作,用于对流中的元素进行过滤。在处理流元素时,会根据传入的predicate条件进行过滤,并将满足条件的元素传递给下游。

map的作用:对流中的每个元素应用指定的映射函数,然后将映射后的结果组成一个新的流返回。
源码解析流程:
主要作用:创建一个新的无状态操作,用于对流中的元素应用指定的映射函数,并将映射后的结果传递给下游的Sink对象。
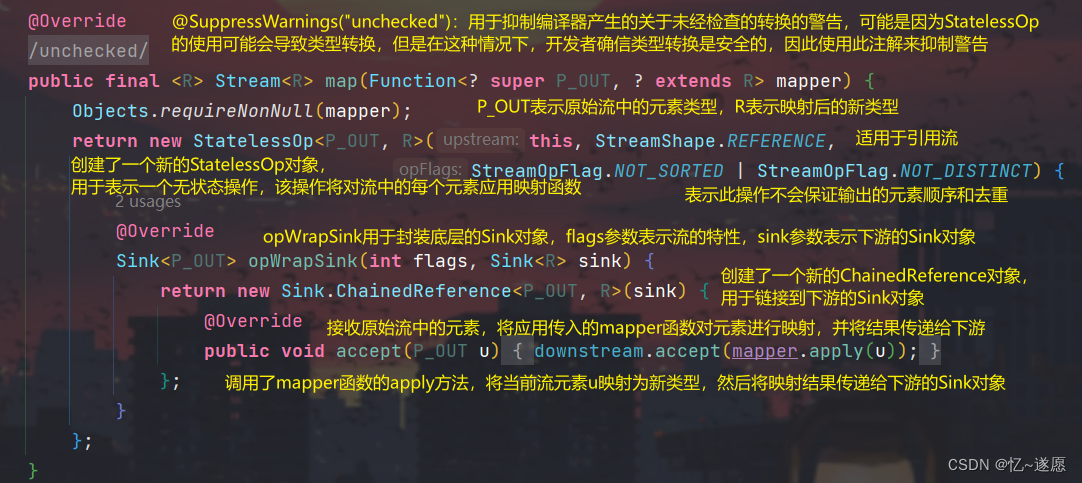
sorted的作用:对流中的元素进行排序,排序方式由传入的比较器(Comparator)决定,排序后返回一个新的排序后的流。
源码解析流程:







distinct的作用:去重操作会移除流中的重复元素,只保留其中的一个。
源码解析流程:

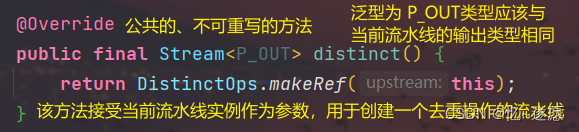
由于代码过长,截图不方便,采用代码加注释的形式.实现 makeRef 方法,该方法创建了一个去重操作的流水线,使用了并行处理来实现去重,并且在处理过程中保持了有序性 。
static <T> ReferencePipeline<T, T> makeRef(AbstractPipeline<?, T, ?> upstream) {
// 创建一个新的 StatefulOp 实例,表示去重操作的流水线,使用 REFERENCE 类型的流形状
return new ReferencePipeline.StatefulOp<T, T>(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_DISTINCT | StreamOpFlag.NOT_SIZED) {
// reduce 方法用于将并行处理的元素归约为单个结果
<P_IN> Node<T> reduce(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
// 如果流是有序的,则保持排序顺序
TerminalOp<T, LinkedHashSet<T>> reduceOp
= ReduceOps.<T, LinkedHashSet<T>>makeRef(LinkedHashSet::new, LinkedHashSet::add,
LinkedHashSet::addAll);
// 使用 reduceOp 对元素进行归约操作,并将结果封装为 Node
return Nodes.node(reduceOp.evaluateParallel(helper, spliterator));
}
// opEvaluateParallel 方法用于并行评估操作
@Override
<P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
// 如果流中已经包含了 DISTINCT 标志,表示已经进行了去重操作,则直接返回
if (StreamOpFlag.DISTINCT.isKnown(helper.getStreamAndOpFlags())) {
// 不进行任何操作,直接返回流的结果
return helper.evaluate(spliterator, false, generator);
}
// 如果流中已经包含了 ORDERED 标志,表示流是有序的
else if (StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {
// 调用 reduce 方法进行归约操作
return reduce(helper, spliterator);
}
// 如果流不是有序的
else {
// 用于标记是否有 null 值出现的原子布尔值
AtomicBoolean seenNull = new AtomicBoolean(false);
// 使用 ConcurrentHashMap 存储元素,保证线程安全
ConcurrentHashMap<T, Boolean> map = new ConcurrentHashMap<>();
// 使用 ForEachOps 进行并行遍历并添加元素到 ConcurrentHashMap
TerminalOp<T, Void> forEachOp = ForEachOps.makeRef(t -> {
if (t == null)
seenNull.set(true); // 如果元素为 null,则设置标志为 true
else
map.putIfAbsent(t, Boolean.TRUE); // 如果元素不为 null,则添加到 ConcurrentHashMap 中
}, false);
forEachOp.evaluateParallel(helper, spliterator);
// 如果出现 null 元素,则将其加入到结果中
Set<T> keys = map.keySet();
if (seenNull.get()) {
// 如果有 null 元素,则创建一个支持 null 元素的 HashSet 并添加到结果中
keys = new HashSet<>(keys);
keys.add(null);
}
// 返回包含去重结果的 Node
return Nodes.node(keys);
}
}
};
}
**ps:**本篇仅仅展示部分使用较多的中间操作,读者可自行去解读其它中间操作。
collect方法行为:使用supplier创建结果容器,使用accumulator将流中的元素逐个添加到结果容器中,最后使用combiner将不同分区的结果容器合并成一个整体结果容器。


在collect方法的实现中,可能会涉及到工厂模式、建造者模式等,具体取决于你使用的收集器(Collector)。
Demo:当使用Collectors.toList()方法,会返回一个Collector,这里使用了工厂模式,Collectors.toList()方法返回了一个Collector的实例,这个实例使用了CollectorImpl类。
实现类似如下:
/**
* ArrayList::new作为一个Supplier,以及List::add作为一个累加器函数,可以说是使用了工厂模式和策略模式
*/
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
作用:流中调用 count() 方法将返回流中元素的总数。

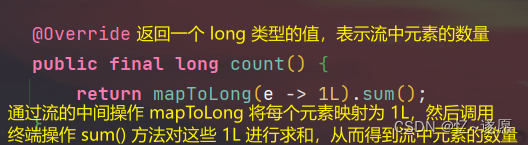

可能涉及到设计模式思想:
public long count() {
return mapToLong(e -> 1L).sum();
}
- 装饰者模式:在
count()方法的实现中,可以看到通过mapToLong()方法对流进行了装饰,将流中的每个元素映射为1L,然后再调用sum()方法。这种装饰操作符合装饰者模式的思想,通过添加额外的功能来扩展原有对象的行为。 - 工厂模式:在流式编程中,流对象的创建通常是通过工厂方法来实现的。例如,
Stream接口中的mapToLong()方法就是一个工厂方法,用于创建一个新的LongStream对象。 - 策略模式:
mapToLong()方法接受一个函数式接口ToLongFunction作为参数,这个函数式接口的具体实现是根据传入的 lambda 表达式来确定的,从而实现了策略模式的思想,即根据不同的需求传入不同的策略。
作用: 用于判断流中是否存在至少一个元素满足给定的条件。



内部实现中可能会涉及到的设计模式思想:
- 迭代器模式:在流的内部实现中很可能会使用迭代器来遍历流中的元素,并在遍历过程中进行条件判断,以确定是否存在满足条件的元素。
- 策略模式:
anyMatch()方法接受一个Predicate参数,这个参数是一个函数式接口,根据传入的 lambda 表达式或者方法引用来确定具体的判断条件,这符合策略模式的思想。 - 模板方法模式:流的内部可能会使用模板方法模式来定义流的处理流程,例如迭代、条件判断等,而具体的操作则由子类或者传入的参数决定。
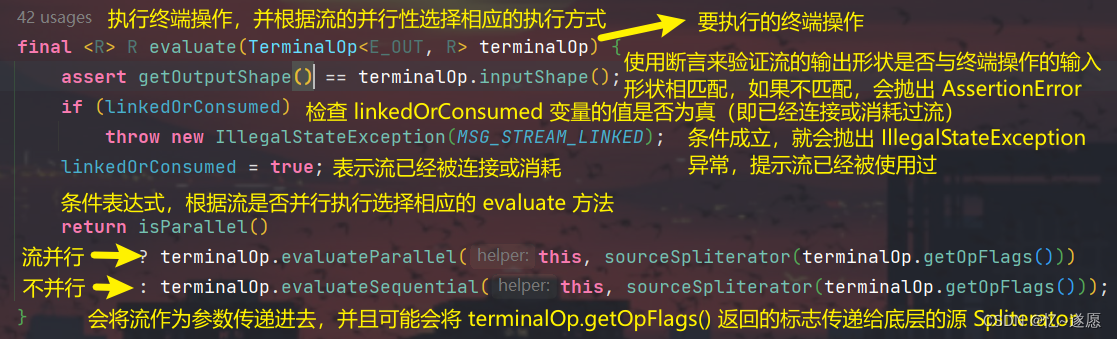
流的并行处理机制是 Java 中处理数据流的一种方式,它可以利用多核处理器和并行计算资源来加速数据处理过程。流的并行处理通过将数据流分成多个子流,并行处理每个子流来实现。
结合源码来解析一下流的并行处理机制:
- 在流的并行处理中,流的元素会被分成多个子流,每个子流会被分配给不同的线程进行处理。这个过程由
sourceSpliterator(terminalOp.getOpFlags())方法完成,它返回一个适当的分隔器,用于将流的元素分割成多个子流。 - 根据流的并行性,调用不同的评估方法来处理子流:
- 如果流是并行的(即
isParallel()返回true),则调用terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))方法来并行评估子流。这个方法会利用并行计算资源来同时处理多个子流,加速数据处理过程。 - 如果流是顺序的(即
isParallel()返回false),则调用terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()))方法来顺序评估子流。这个方法会按顺序处理每个子流的元素,没有并行化处理。
- 如果流是并行的(即
- 在评估方法中,会根据
TerminalOp的实现对子流的元素进行相应的操作,并最终返回结果。
多线程执行流操作的内部工作原理可以通过分析 Java 流框架的实现来理解。流框架在处理流操作时,会根据流的并行性将任务分配给多个线程执行,并利用并发编程的技术来实现高效的多线程执行。
结合源码来解析一下多线程执行流操作的内部工作原理:
- 分割流的元素:在流的并行处理中,流的元素会被分成多个子流,每个子流会被分配给不同的线程进行处理。这个过程由
sourceSpliterator(terminalOp.getOpFlags())方法完成,它返回一个适当的分隔器,用于将流的元素分割成多个子流。 - 并行执行任务:根据流的并行性,Java 流框架会将任务分配给线程池中的多个线程执行,并行处理每个子流。在源码中,调用了
terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))方法来并行评估子流。这个方法会利用并行计算资源来同时处理多个子流,加速数据处理过程。 - 任务的合并与结果返回:在并行执行过程中,各个线程会独立执行任务,并产生各自的部分结果。在评估方法的内部,Java 流框架会负责合并各个线程的结果,并最终返回整体的结果。这样,多线程执行的结果会被正确地合并到最终的结果中。
- 线程管理与调度:Java 流框架会利用线程池来管理并发执行的线程,确保资源的有效利用和任务的合理调度。线程池会根据需要动态地管理线程的数量,并根据系统资源和任务负载来调度线程的执行。
如今我努力奔跑,不过是为了追上那个曾经被你寄予厚望的我

- 点赞
- 收藏
- 关注作者
评论(0)