Daily_and_Sports_Activities数据集的详细介绍及训练

一、Daily_and_Sports_Activities数据集
1.数据集介绍
该数据集包括19项日常和体育活动的运动传感器数据,每项活动由8名受试者以自己的风格进行5分钟。躯干、手臂和腿部使用五个Xsens-MTx单位。19 项活动中的每一项都由 8 名受试者(4 名女性,4 名男性,年龄在 20 至 30 岁之间)进行,每次 5 分钟。 每个受试者的每项活动的总信号持续时间为 5 分钟。 受试者被要求以自己的风格进行活动,并且不受活动方式的限制。出于这个原因,某些活动的速度和幅度存在主体间差异。 这些活动在比尔肯特大学体育馆的电气和电子工程大楼进行, 在校园内平坦的户外区域。传感器单元经过校准,可在 25 Hz 采样频率下采集数据。将 5 分钟信号分成 5 秒段,以便为每个活动获得 480(=60x8) 个信号段。
2.数据集内容
这19项活动是: 坐着(A1), 站立(A2), 仰卧和右侧(A3 和 A4), 上下楼梯(A5和A6), 站在电梯里静止不动 (A7) 在电梯(A8)中四处走动, 在停车场(A9)行走, 在跑步机上以 4 公里/小时的速度行走(在平坦和 15 度倾斜的位置)(A1 0 和 A11), 在跑步机上以 8 公里/小时的速度跑步 (A12), 在步进器(A13)上锻炼, 在交叉训练器(A14)上锻炼, 在水平和垂直位置(A15 和 A16)骑健身车, 划船 (A17), 跳跃 (A18), 和打篮球(A19)。
3.数据集文件结构
19项活动(a)(按上述顺序排列) 8 个科目 (p) 60 段 (s) 躯干 (T)、右臂 (RA)、左臂 (LA)、右腿 (RL)、左腿 (LL) 5 个单位 每个单元上有 9 个传感器(x、y、z 加速度计、x、y、z 陀螺仪、x、y、z 磁力计)。
文件夹 a01、a02、…、a19 包含 19 项活动记录的数据。 对于每个活动,子文件夹 p1、p2、…、p8 包含来自 8 个主题中每个主题的数据。 在每个子文件夹中,有 60 个文本文件 s01、s02、…、s60,每个段一个。
在每个文本文件中,有 5 个单位 x 9 个传感器 = 45 列和 5 秒 x 25 Hz = 125 行。 每列包含 125 个数据样本,这些数据样本在 5 秒的时间内从其中一个单元的传感器获取。 每行都包含从所有 45 个传感器轴在特定采样时刻采集的数据,用逗号分隔。
第 1-45 列对应于:
T_xacc、T_yacc、T_zacc、T_xgyro、…、T_ymag、T_zmag、 RA_xacc、RA_yacc、RA_zacc、RA_xgyro、…、RA_ymag、RA_zmag、 LA_xacc、LA_yacc、LA_zacc、LA_xgyro、…、LA_ymag、LA_zmag、 RL_xacc、RL_yacc、RL_zacc、RL_xgyro、…、RL_ymag、RL_zmag、 LL_xacc、LL_yacc、LL_zacc、LL_xgyro、…、LL_ymag、LL_zmag。
因此 第 1-9 列对应于单元 1 (T) 中的传感器, 第 10-18 列对应于单元 2 (RA) 中的传感器, 第 19-27 列对应于单元 3 (LA) 中的传感器, 第 28-36 列对应于单元 4 (RL) 中的传感器, 第 37-45 列对应于单元 5 (LL) 中的传感器。
- Dataset Characteristics 数据集特征
Multivariate, Time-Series 多变量,时间序列
- Subject Area 学科领域
Computer Science 计算机科学
- Associated Tasks 相关任务
Classification, Clustering 分类、聚类
- Feature Type 要素类型
Real 真正
- Instances 实例
9120
- Features 特性
5625
二、数据集处理
原数据分析: 原始文件共19个活动,每个活动都由8个受试者进行信号采集,每个受试者在每一类上采集5min的信号数据,采样频率25hz(每个txt是 125*45 的数据,包含5s时间长度,共60个txt)
预处理思路: 数据集网站的介绍中说到60个txt是有5min连续数据分割而来,因此某一类别a下同一个受试者p的60个txt数据是时序连续的。所以可以将a()p()下的所有txt数据进行时序维度拼接,选择窗口大小为125,重叠率为40%进行滑窗。
1. 环境设置
首先,确保Python环境已安装以下库:
numpy:用于数值计算。pandas:用于数据处理和CSV文件读取。os:用于操作系统功能,如文件路径处理。sys:用于访问与Python解释器紧密相关的变量和函数。
如果未安装,可以通过以下命令安装:
pip install numpy pandas
2. 数据集下载
数据集可以从UCI机器学习库下载,我们编写一个函数来自动下载并解压数据集。
import os
import zipfile
from urllib.request import urlretrieve
def download_dataset(dataset_name, file_url, dataset_dir):
# 定义文件名和下载路径
file_name = dataset_name + '.zip'
download_path = os.path.join(dataset_dir, file_name)
# 下载文件
urlretrieve(file_url, download_path)
# 解压文件
with zipfile.ZipFile(download_path, 'r') as zip_ref:
zip_ref.extractall(dataset_dir)
# 删除压缩文件
os.remove(download_path)
# 调用下载函数
download_dataset(
dataset_name='Daily_and_Sports_Activities',
file_url='http://archive.ics.uci.edu/static/public/256/daily+and+sports+activities.zip',
dataset_dir='./data'
)
3. 数据预处理
我们使用一个DASA函数来处理数据集,执行以下步骤:
3.1 参数设置
在函数开始处,我们设置了一些预处理参数:
dataset_dir:数据集存放的目录。WINDOW_SIZE:滑动窗口的大小。OVERLAP_RATE:滑动窗口的重叠率。SPLIT_RATE:训练集和测试集的分割比例。VALIDATION_SUBJECTS:用于验证的受试者编号集合。Z_SCORE:是否进行Z分数标准化。SAVE_PATH:预处理后数据的保存路径。
def DASA(dataset_dir='./data', WINDOW_SIZE=125, OVERLAP_RATE=0.4, SPLIT_RATE=(8, 2), VALIDATION_SUBJECTS={7, 8}, Z_SCORE=True, SAVE_PATH=os.path.abspath('../../HAR-datasets')):
# ... 省略其他代码 ...
3.2 数据读取与滑动窗口
接下来,我们读取原始数据,并应用滑动窗口技术来处理数据。
for label_id, adl in enumerate(adls): # 遍历每个活动
# ... 省略部分代码 ...
for participant_idx, participant in enumerate(participants): # 遍历每个受试者
# ... 省略部分代码 ...
files = sorted(os.listdir(participant))
concat_data = np.vstack([pd.read_csv(file, sep=',', header=None).to_numpy() for file in files])
cur_data = sliding_window(array=concat_data, windowsize=WINDOW_SIZE, overlaprate=OVERLAP_RATE)
这里,我们首先读取每个受试者文件夹中的所有文件,并将它们按顺序读取并垂直堆叠(np.vstack)成一个大的数组。然后,我们使用sliding_window函数对这个大数组应用滑动窗口技术,生成窗口化的数据。
3.3 数据分割
根据VALIDATION_SUBJECTS参数,我们选择留一法或平均法来分割训练集和测试集。
if VALIDATION_SUBJECTS: # 留一法
# ... 省略部分代码 ...
else: # 平均法
trainlen = int(len(cur_data) * SPLIT_RATE[0] / sum(SPLIT_RATE))
testlen = len(cur_data) - trainlen
xtrain += cur_data[:trainlen]
xtest += cur_data[trainlen:]
ytrain += [label_id] * trainlen
ytest += [label_id] * testlen
3.4 数据标准化
如果设置了Z_SCORE=True,则对数据进行Z分数标准化。
if Z_SCORE:
xtrain, xtest = z_score_standard(xtrain=xtrain, xtest=xtest)
3.5 数据保存
最后,我们将预处理后的数据保存到指定的路径。
if SAVE_PATH:
# ... 省略部分代码 ...
4. 运行预处理
最后,我们调用DASA函数来执行整个预处理流程。
if __name__ == '__main__':
DASA()
5. 结论
通过上述步骤,我们详细介绍了DASA数据集的下载、预处理、数据分割、标准化以及保存的过程。这些步骤为后续的机器学习模型训练和评估提供了准备好的数据。
请注意,上述代码中省略了一些辅助函数的实现细节,如sliding_window和z_score_standard。这些函数的具体实现将依赖于数据的具体格式和预处理需求。此外,代码中的路径和参数可能需要根据实际情况进行调整。
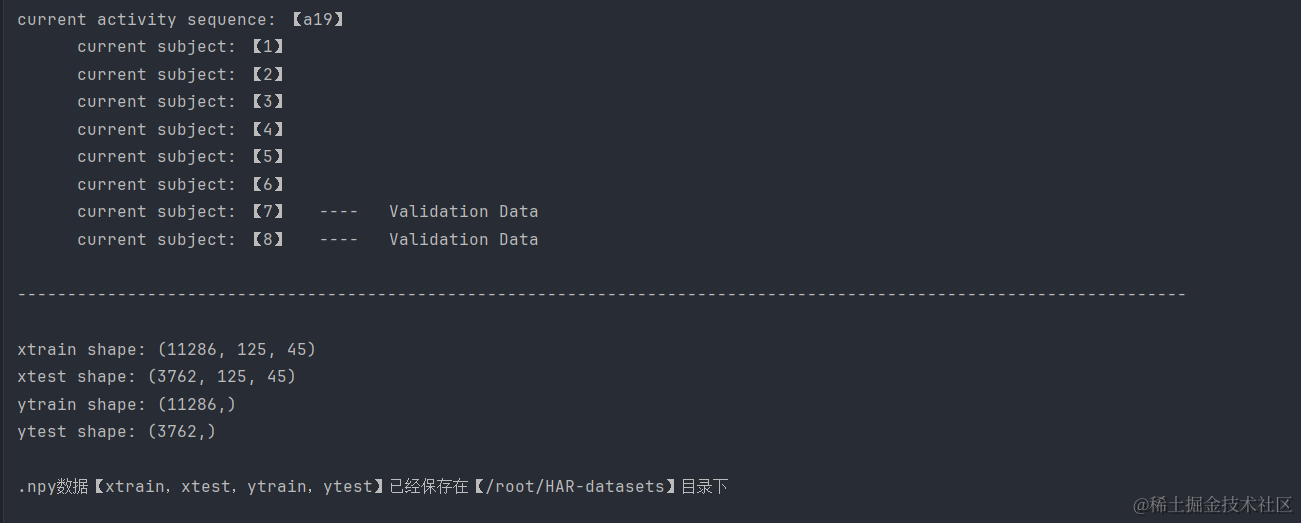
最后结果展示如下:
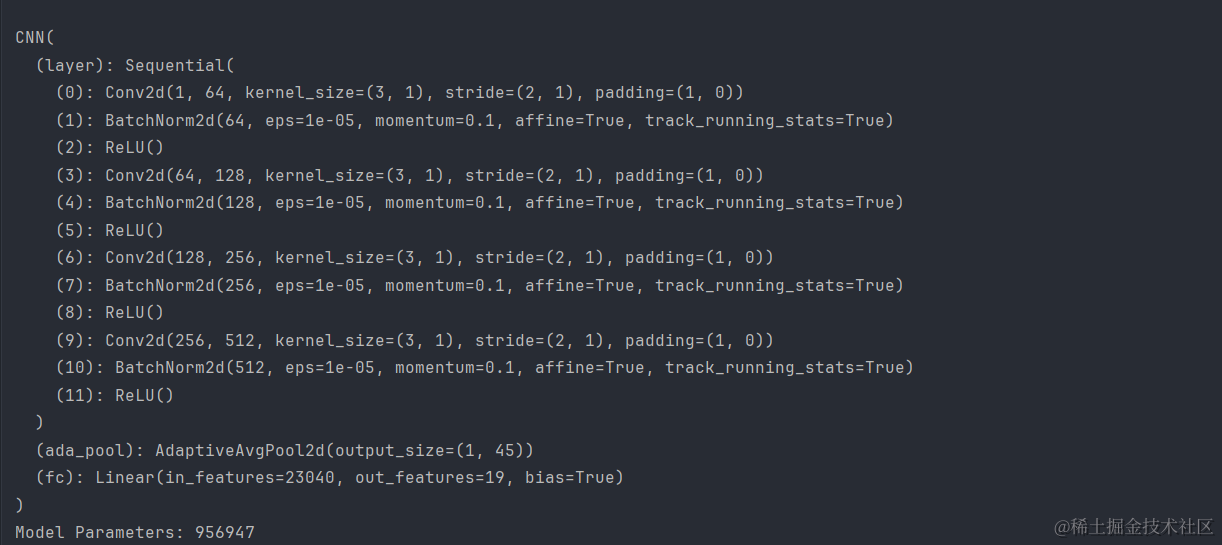
三、CNN网络训练Daily_and_Sports_Activities数据集
1.CNN网络结构
这里我们就不在过多解释,在之前的文章中已经多次提到了:
2.训练结果
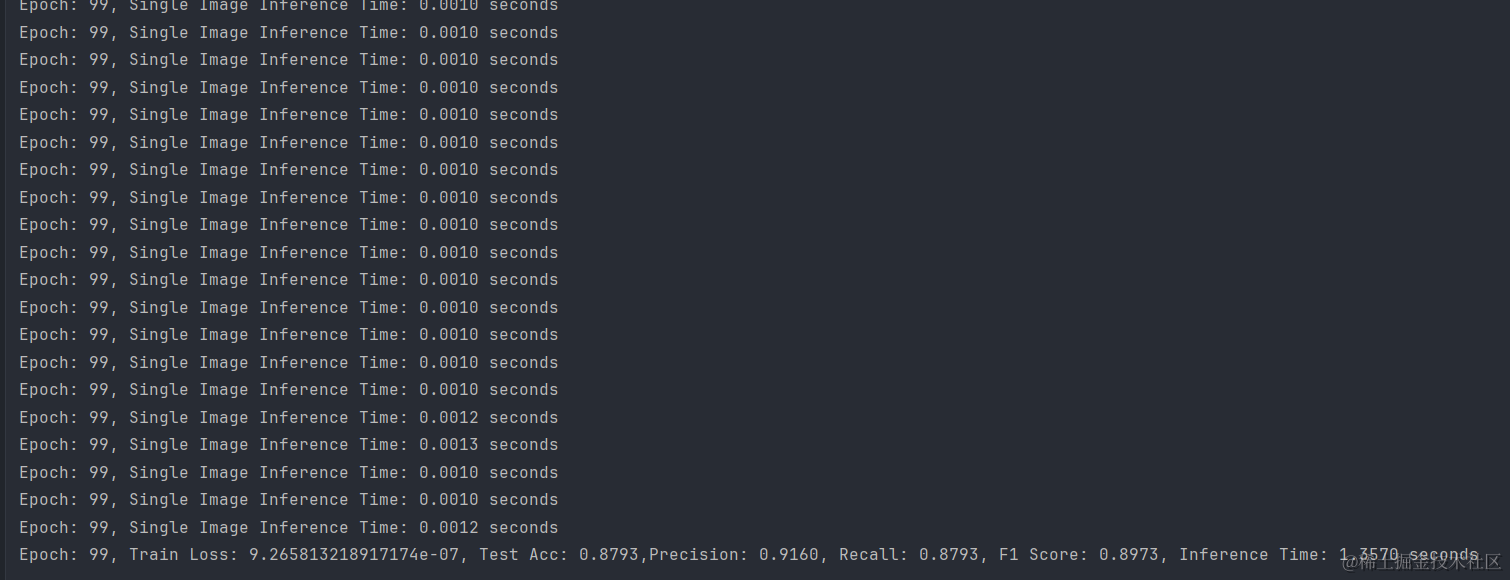
通过训练CNN网络,Daily_and_Sports_Activities数据集在测试集上达到了87.93%的准确率,模型显示出了良好的泛化能力,同时具有91.60%的精确度和87.93%的召回率,F1分数为0.8973,表明模型在精确度和召回率之间取得了较好的平衡。此外,模型的推理时间非常快,单张图片的推理时间在0.0010到0.0013秒之间,整个测试集的推理时间仅为1.3570秒,显示出模型在实际应用中的高效性。

- 点赞
- 收藏
- 关注作者
评论(0)