【Kafka】Kafka 基础知识总结

先赞后看,Java进阶一大半

各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。
⭐⭐⭐一份南哥编写的《Java学习/进阶/面试指南》:https://github/JavaSouth
1. Kafka概念
1.1 Kafka组成模块
面试官:你先说说Kafka由什么模块组成?
Kafka其实是一款基于发布与订阅模式的消息系统,如果按常理来设计,大家是不是把消息发送者的消息直接发送给消息消费者?但Kafka并不是这么设计的,Kafka消息的生产者会对消息进行分类,再发送给中间的消息服务系统,而消息消费者通过订阅某分类的消息去接受特定类型的消息。
其实这么设计的目的也是为了满足大量业务消息的接入,要是单一的消息发送和接收,那开个进程的管道通信就可以了。另外如果大家对设计模式的发布/订阅模式熟悉的话,对Kafka的设计理念会更容易理解。
总的来说,Kafka由五大模块组成,大家要理解好这些模块的功能作用:消息生产者、消息消费者、Broker、主题Topic、分区Partition。
(1)消息生产者
消息生产者是消息的创造者,每发送一条消息都会发送到特定的主题上去。
(2)消息消费者
消息生产者和消费者都是Kafka的客户端,消息消费者顾名思义作为消息的读取者、消费者。同时Kafka很灵活的一点是,一个消费者可以订阅多个主题,而且一个主题消息也可被不同消息分组的多个消费者处理。这就给我们变化多端的业务设计带来了众多可能性了,方便大家自由发挥。
(3)Broker
孤零零部署在Linux的Kafka服务器被称为Broker,也就是我上文提到的中间的消息服务系统,大家不要小瞧他,单台Broker可以轻松处理每秒百万级的消息量。Broker日常工作内容就是接收消息生产者的消息,为每条消息设置偏移量,最后提交到磁盘进行持久化保存。
(4)主题Topic
上文我们知道Kafka的消息是有分类的,而分类的标识就是主题Topic。大家可以看下具体代码落地会更容易理解,消息生产者Producer发送给clock-topic主题,消息消费者监听消费clock-topic主题下的消息。
// 消息生产者
public class Producer implements ApplicationRunner {
@Resource
private RedissonClient redissonClient;
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@Override
public void run(ApplicationArguments args) throws Exception {
RBlockingQueue<Clock> blockingFairQueue = redissonClient.getBlockingQueue("delay_queue");
while (true) {
Clock clock = blockingFairQueue.take();
kafkaTemplate.send("clock-topic", "key", clock.toString());
log.info("time out: {} , clock created: {}", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()), clock.getTime());
}
}
}
// 消息消费者
@KafkaListener(topics = "clock-topic", groupId = "kafka-group")
public void listener(ConsumerRecord<String, String> record, Acknowledgment ack) {
log.info("listener get message: " + record.value());
ack.acknowledge();
}
(5)分区Partition
每一个主题下的消息都需要提交到Broker的磁盘里,假如我们搭建了三个Broker节点组成的Kafka集群,一般情况下同一个主题下的消息会被分到三个分区进行存储。说到这,由于顺序发送的消息是存储在不同分区中,我们无法保证消息被按顺序消费,只能保证同一个分区下的消息被顺序消费.
1.2 分区
面试官:那分区有什么作用?
消费分区的作用主要就是为了提高Kafka处理消息的吞吐量,谁叫Kafka设计之初就是作为一款高吞吐量、高可用、可扩展的应用程序。
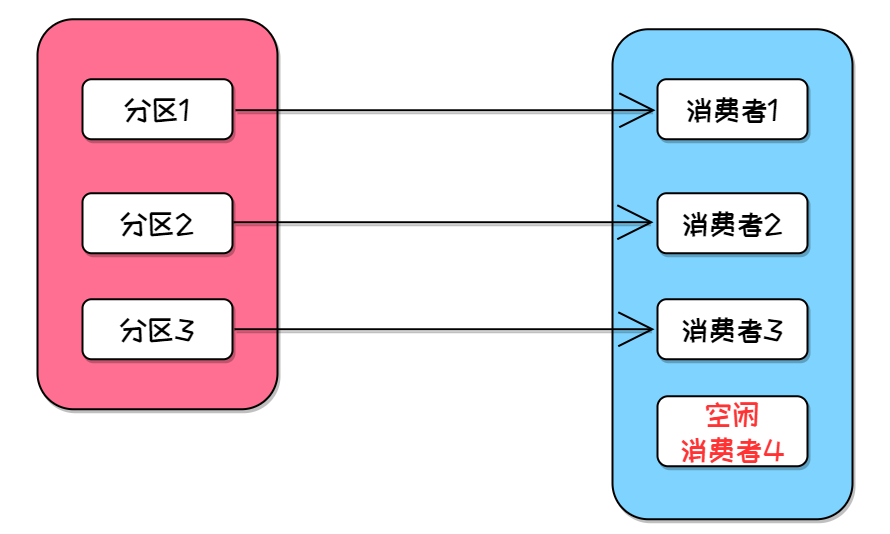
假如一个topic下有N个分区、N个消费者,每个分区会发送消息给对应的一个消费者,这样N个消费者就可以负载均衡地处理消息。
同时消息生产者会发送消息给不同分区,每个分区又是属于不同的Broker,这让Broker集群平坦压力,大大提高了Kafka的吞吐量。
大家还需要注意一点,如果一个主题下消费者的数量超过分区的数量,超过数量的消费者是会被闲置的,一般N个分区最多搭配N个消费者。
1.3 异步回调
面试官:消息生产者的异步回调,知道吧?
当我们调用send()异步发送消息时,可以指定一个回调函数,该函数会等Broker服务器响应时触发。如下源码所示,我们可以为响应参数ListenableFuture添加一个回调函数实现callback。
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord(topic, key, data);
return this.doSend(producerRecord);
}
public interface ListenableFuture<T> extends Future<T> {
void addCallback(ListenableFutureCallback<? super T> callback);
}
那这个回调函数有什么作用?我们一般用来进行异常日志的记录。
Kafka的异步提交消息相比同步提交来说不需要在Broker响应前阻塞线程,这也在一定程度提高了消息的处理速度。但异步提交我们是不知道消息的消费情况的,此时就可以通过Kafka提供的回调函数来告知程序异常情况,从而方便程序进行日志记录。
1.4 提交消息的方式
面试官:你说说消费者手动提交和自动提交有什么区别?
手动提交和自动提交是Kafka两种客户端的偏移量提交方式,提交方式的配置选项是enable.auto.commit,默认情况下该选项为ture。
偏移量提交是什么?大家可以理解为消费者通知当前最新的读取位置给到分区,也就是告诉分区哪些消息已消费了。
如果enable.auto.commit为true代表提交方式为自动提交,默认为5秒的提交时间间隔。每过5秒,消费者客户端就会自动提交最大偏移量。
如果enable.auto.commit为false代表提交方式为手动提交,我们需要让消费者客户端消费程序执行后提交当前的最大偏移量。
1.5 提交方式的优缺点
面试官:那它们都有什么优、缺点?
(1)自动提交
自动提交比较方便,我们甚至都不需要配置提交方式,不过可能会导致消息丢失或重复消费。
如果刚好到了5秒的时间间隔自动提交了最大偏移量,此时正在执行消息程序的消费者客户端崩溃了,就会导致消息丢失。
如果成功消费了消息,下一秒消费者应该自动提交,但如果此时消费者客户端奔溃,就会导致其他分区的消费者重复消费。
(1)手动提交
手动提交需要消费者客户端在消费消息后手动提交消息,手动提交的方式又分为同步提交、异步提交。
手动提交是同步提交的话,在Broker对请求做出回应之前,客户端会一直阻塞,这样的话限制应用程序的吞吐量。
手动提交是异步提交的话,不会有吞吐量的问题。不过消费者客户端发送给Broker偏移量之后,不会管Broker有没有收到消息。这种情况就要采用上文我提到的消息生产者异步回调来进行日志记录,有了日志记录方便后续bug排查,工作效率妥妥的高😏。
2. Kafka消息可靠性
2.1 Kafka高水位
面试官:知道Kafka高水位吗?
我们都知道Kafka消息保存在首领分区和分区副本中,Kafka要保证即使从分区副本读取消息也只会读取已提交的消息。Kafka的高水位就是为了这个目标而开发出来的。
如果大家对消息已提交的概念不清楚的话,可以看下以下的解释。
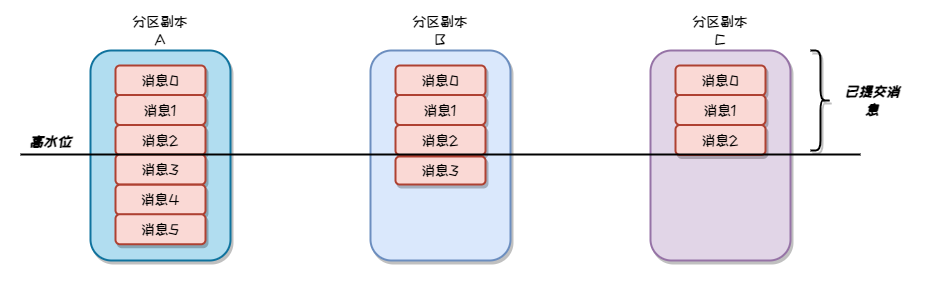
Kafka的消息只有在所有分区副本都同步该消息后,才算是已提交的消息
在分区复制的过程中,首领分区会在发送的数据里加入当前高水位。当前高水位就是复制偏移量,记录了当前已提交消息的最大偏移量。而分区副本就可以根据首领分区副本提供的高水位,来避免未提交的消息被消费者消费。
就如下图,最大偏移量的限制就像海面上的水位。
2.2 消息存储可靠性
面试官:你说说Kafka是怎么保证消息可靠性的?
大家在回答面试官问题前可以思考下,可靠性的含义是什么?
在业务系统中,消息的不丢失是最重要的,数据即是金钱。如果把客户的一条支付消息丢失,而这条支付信息的涉及的金额不菲,想想对公司的损失有多大。所以可靠性意味着对消息的存储和保护。
Kafka在这方面采用了复制机制和分区多副本架构来作为消息可靠性的核心。
(1)分区多副本架构。
Kafka的所有主题被分为了多个分区存储在多个Broker里,而每个分区可以有多个副本。例如有4个Broker节点,Broker1存储了分区首领副本,而Broker2、Broker3可以存储其分区副本。
Kafka对消息的存储有多个分区副本来支持,可以避免单点问题导致数据丢失找不回来的情况。
(2)复制机制。
在通常情况下消费者都是从首领副本里读取消息,同时会有n(复制系数)个Broker机器会去同步复制首领副本后,生成跟随者副本也就是分区副本。
如果首领副本的机器挂了,分区副本就会选举成为新的首领副本。
复制机制保证了分区副本和首领副本的数据一致性,有复制机制的加持,分区多副本架构才是可用的。
2.3 生产者消费者可靠性
面试官:还有呢?
上面所说的其实是基于Broker层面带给Kafka的可靠性保障,我们还需要在生产者、消费者层面下功夫,来使整个系统减少丢失数据的风险。
一、在生产者方面。
Kafka提供了多种发送确认模式,我们可以根据业务的可靠性需求配置合适的acks。
- ack = 0。如果消息生产者能够把消息通过网络发送出去,则认为消息已成功写入。
- ack = 1。如果首领分区收到消息并成功写入,生产者收到确认返回,则认为消息已成功写入。
- ack = all。只有在消息成功写入所有分区副本后,才认为消息已成功写入。这保证了消息的多备份。
以上的各种acks情况如果失败的话,我们可以让生产者继续重试发送消息,直到Kafka返回成功。
二、在消费者方面
大家如果能回答上文第一个面试官问题:知道Kafka高水位吗,就知道Kafka高水位保证了消费者只会读取到已提交的数据,即被写入所有分区副本的数据。所以消费者要确保的是跟踪哪些数据已读取了、哪些数据未读取。
- 消费者消费消息时会先获取一批消息,同时从最后一个偏移量开始读取,这保证了消息的顺序性。
- 消费者消费消息后会同步提交、异步提交偏移量,保证了消息不被其他消费者重复消费。
2.4 消费堆积问题
面试官:那要是Kafka消费堆积了你怎么处理?
这个问题是面试官常考的一个问题,我们要从Broker和消费者两方面来看。
一、Broker的话。
- 每个topic是分为多个分区给不同Broker进行处理,要合理分配分区数量来提高Broker的消息处理能力。比如3个Broker2个分区,可以改为3个Broker3个分区。
- 可以横向扩展Broker集群,来提高Broker的消息处理能力。
二、消费者的话。
- 可以增加消费者服务数量来提高消息消费能力。
- 在提交偏移量时,可以把同步提交改为异步提交。异步提交无需等待Kafka的确认返回,减少了同步等待Broker的时间。
2.5 Kafka控制器
面试官:知道Kafka控制器吧?
Kafka控制器其实也是一个Broker,不过它还负责选举分区首领。Kafka的控制器和Redis集群的哨兵的选举功能是一样的。
也就是在首领副本所在的分区失效后,Kafka会通过控制器来在分区副本里选举出新的首领副本。
3. Kafka事务
3.1 Kafka事务是什么
面试官:Kafka事务你说说看?
Kafka的事务主要应用在以流式处理的应用程序中,流式处理?听起来都觉得很迷糊不知道是什么东西。
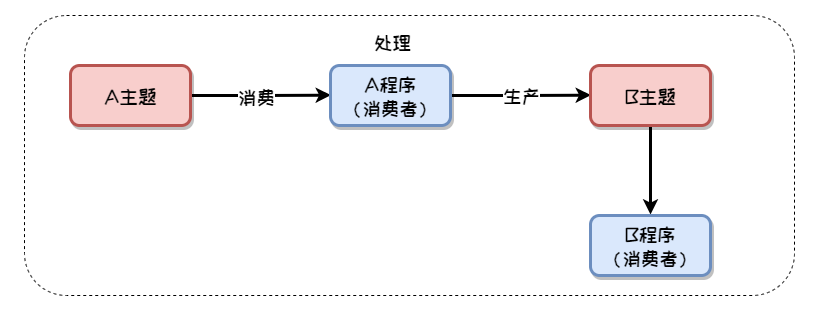
Kafka事务支持的流式处理过程一般是这样,A程序从一个A主题消费A消息,对A消息进行处理后,再把结果写入到B主题,后续B程序会对B主题的消息进行消费。也就是消费 - 处理 - 生产的过程。
这样的一个过程涉及了两个消息的消费、一个消息的生产,如何保证这整个过程的事务性,让这整个过程要么成功、要么都不成功,这就是Kafka事务要做的事情。
南哥画下流程图,帮助大家理解理解。
3.2 重复消费问题
面试官:你说的这个过程,不使用事务有什么问题?
流式处理程序的消费 - 处理 - 生产过程,如果没有事务的保证,可能会出现多种消息重复消费的问题,这就会产生各种奇奇怪怪的问题了。
特别是在金融、支付行业,整个支付过程涉及了多个流程,例如用户下单 -> 库存校验 -> 订单处理-> 实际扣费 -> 清算结算,这些业务场景采用的便是流式处理程序。涉及资金的业务场景,事务的保障就更重要了!!
我说说两个消息重复消费的场景。
还是举例上文的场景:A程序从一个A主题消费A消息,对A消息进行处理后,再把结果写入到B主题,后续B程序会对B主题的消息进行消费。
(1)程序崩溃造成的重复消费
如果A程序对A消息进行处理后,把结果写入到B主题。但在偏移量提交的时候崩溃了,此时Kafka会认为A消息还没有被消费,而A程序崩溃了Kafka会把该分区分配给新的消费者。
问题就来了,新的消费者会重新消费A消息,等于B主题被写入了两条相同的消息,A消息被消费了两次。
(2)僵尸程序造成的重复消费
如果一个消费者程序认为自己没有死亡,但因为停止向Kafka发送心跳一段时间后,Kafka认为它已经死亡了,这种程序叫做僵尸程序。
A程序从Kafka读取A消息后,它暂时挂起了,失去和Kafka的连接也不能提交偏移量。此时Kafka认为其死亡了,会把A消费分配给新的消费者消费。
但后续A程序恢复后,会继续把A消息写入B主题,仍然造成了A消费被消费了两次。
可能很多人会说,这个流程有重复消费的问题,那处理重复消费的问题不就可以了,不必引入Kafka事务这么复杂。但在金融、支付这么严谨、重要的业务场景,我们要的是整个流程哪怕有一丁点出错,整个处理流程全都要进行回滚。
3.3 Kafka事务不能处理的问题
面试官:Kafka事务有不能处理的问题吗?
当然在整个Kafka事务的过程中,会有某些操作是不能回滚的,Kafka事务并不支持处理,我们来看看。
(1)Kafka事务过程加入外部逻辑
例如A程序消费消息A的过程中,发送了一个通知邮件,那整个外部操作是不可逆的,不在事务的处理范围内。
(2)读取Kafka消息后写入数据库
这其实也可以当成一个外部处理逻辑,数据库的事务并不在Kafka事务的处理范围内。
3.4 SpringBoot使用Kafka事务
面试官:接触过SpringBoot发送Kafka事务消息吗?
在SpringBoot项目我们可以轻松使用Kafka事务,通过以下Kafka事务的支持,我们就可以保证消息的发送和偏移量的提交具有事务性,从而避免上述的重复消费问题。
(1)先引入spring-kafka依赖
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>xxx</version>
</dependency>
</dependencies>
(2)配置Kafka事务管理器和生产者工厂
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.transaction.KafkaTransactionManager;
import org.springframework.kafka.support.serializer.JsonSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(org.apache.kafka.clients.producer.ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(org.apache.kafka.clients.producer.ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(org.apache.kafka.clients.producer.ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
configProps.put(org.apache.kafka.clients.producer.ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
configProps.put(org.apache.kafka.clients.producer.ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tx-");
DefaultKafkaProducerFactory<String, Object> factory = new DefaultKafkaProducerFactory<>(configProps);
factory.setTransactionIdPrefix("tran-");
return factory;
}
@Bean
public KafkaTransactionManager<String, Object> transactionManager(ProducerFactory<String, Object> producerFactory) {
return new KafkaTransactionManager<>(producerFactory);
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate(ProducerFactory<String, Object> producerFactory) {
return new KafkaTemplate<>(producerFactory);
}
}
(3)使用KafkaTemplate发送事务性消息
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@EnableKafka
@Service
public class KafkaConsumerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Transactional
@KafkaListener(topics = "A")
public void processMessage(String message) {
// 处理从主题A接收到的消息
String processedMessage = "Processed " + message;
// 将处理后的消息发送到主题B
kafkaTemplate.send("B", processedMessage);
// 提交事务,确保消息发送和偏移量提交一起完成
}
}
我是南哥,南就南在Get到你的点赞点赞点赞。

看了就赞,Java进阶一大半。点赞 | 收藏 | 关注,各位的支持就是我创作的最大动力❤️

- 点赞
- 收藏
- 关注作者
评论(0)