数据库系统(事务并发|封锁协议|数据库安全|商业智能|SQL语句)

一、事务并发
1.1 事务概述
DBMS 运行的基本工作单位是事务,事务是用户定义的一个数据库操作序列,这些操作序列要么全做,要么全都不做,是一个不可分割的工作单位。事务具有的四个特性(ACID):
-
(操作)原子性(Atomicity):事务是数据库的逻辑工作单位,事务的所有操作在数据库中要么 全做,要么全都不做。
-
(数据)一致性(Consistency):事务的执行使数据库从一个一致性状态变成另一个一致性状态。
-
(执行)隔离性(Isolation):一个事务的执行不能被其他事务干扰。
-
(改变)持久性(Durability):指一个事务一旦提交,它对数据库的改变必须是永久的,即便系统出现故障时也是如此。
1.2 并发控制
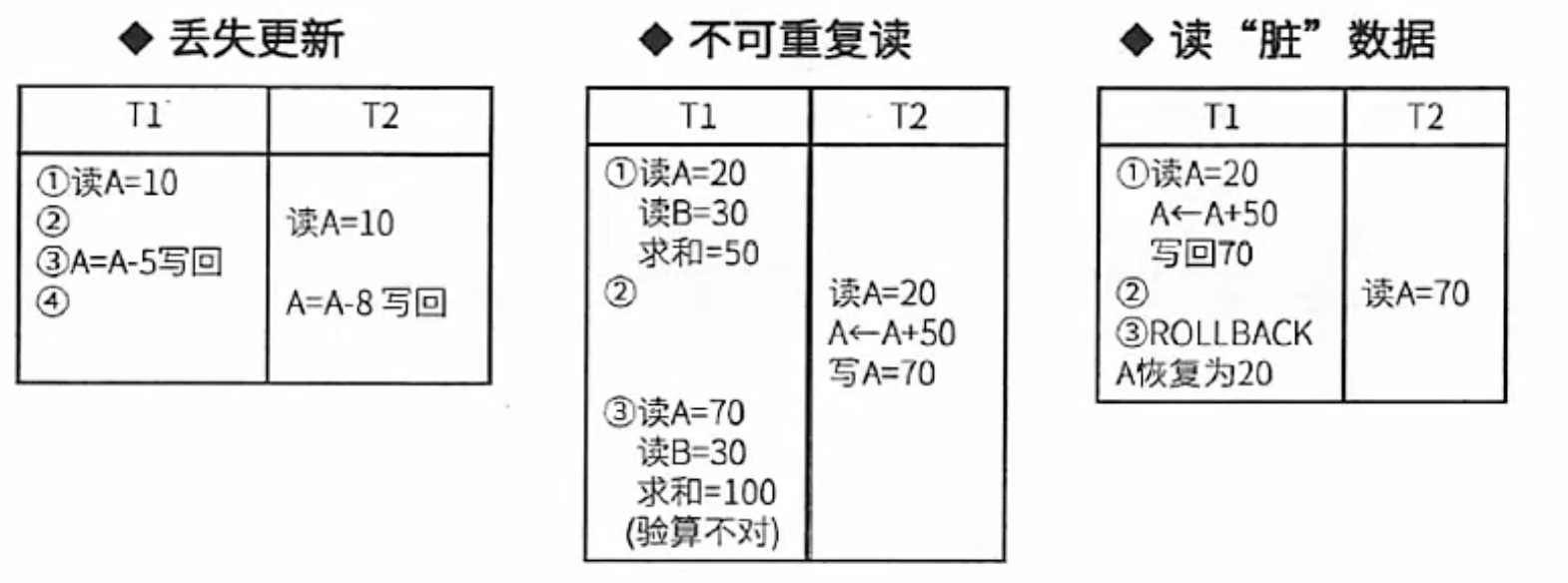
事务是并发控制的前提条件,并发控制就是控制不同的事务并发执行,提高系统效率,但是并发控制中存在下面三个问题:
-
丢失更新:事务1对数据A进行了修改并写回,事务2也对A进行了修改并写回此时事务2写回的数据会覆盖事务1写回的数据,就丢失了事务1对A的更新。即对数据A的更新会被覆盖。
-
不可重复读:事务2读A,而后事务1对数据A进行了修改并写回,此时若事务2再读A,发现数据不对。即一个事务重复读A两次,会发现数据A有误。
-
读脏数据:事务1对数据A进行了修改后,事务2读数据A,而后事务1回滚,数据A恢复了原来的值,那么事务2对数据A做的事是无效的,读到了脏数据。
1.3 封锁
1.3.1 X 封锁和 S 封锁
并发控制的主要技术是封锁,主要有两种类型的封锁,分别是 X 封锁 和 S 封锁。
-
排他型封锁(X 封锁):如果事务 T 对数据 A(可以是数据项、记录、数据集以至整个数据库)实现了 X 封锁,那么只允许事务 T 读取和修改数据 A,其他事务要等事务 T 解除 X 封锁以后,才能对数据 A 实现任何类型的封锁。可见 X 封锁只允许一个事务独锁某个数据,具有排他性。
-
共享型封锁(S 封锁):如果事务 T 对数据 A 实现了 S 封锁,那么允许事务 T 读取数据A,但不能修改数据 A,在所有 S 封锁解除之前决不允许任何事务对数据 A 实现 X 封锁。
1.3.2 三级封锁协议
-
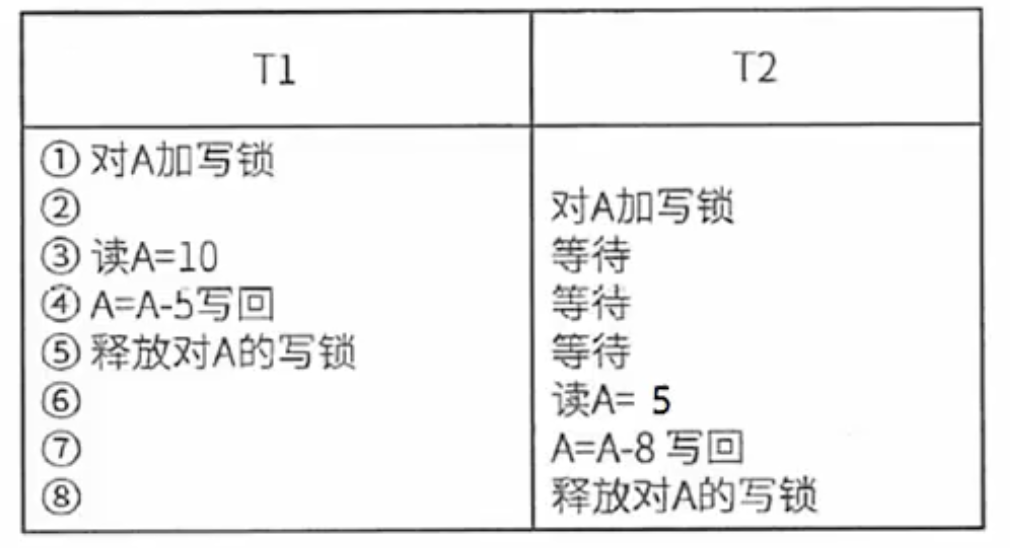
一级封锁协议:事务在修改数据R之前必须先对其加X锁,直到事务结束才释放。可解决丢失更新问题。
-
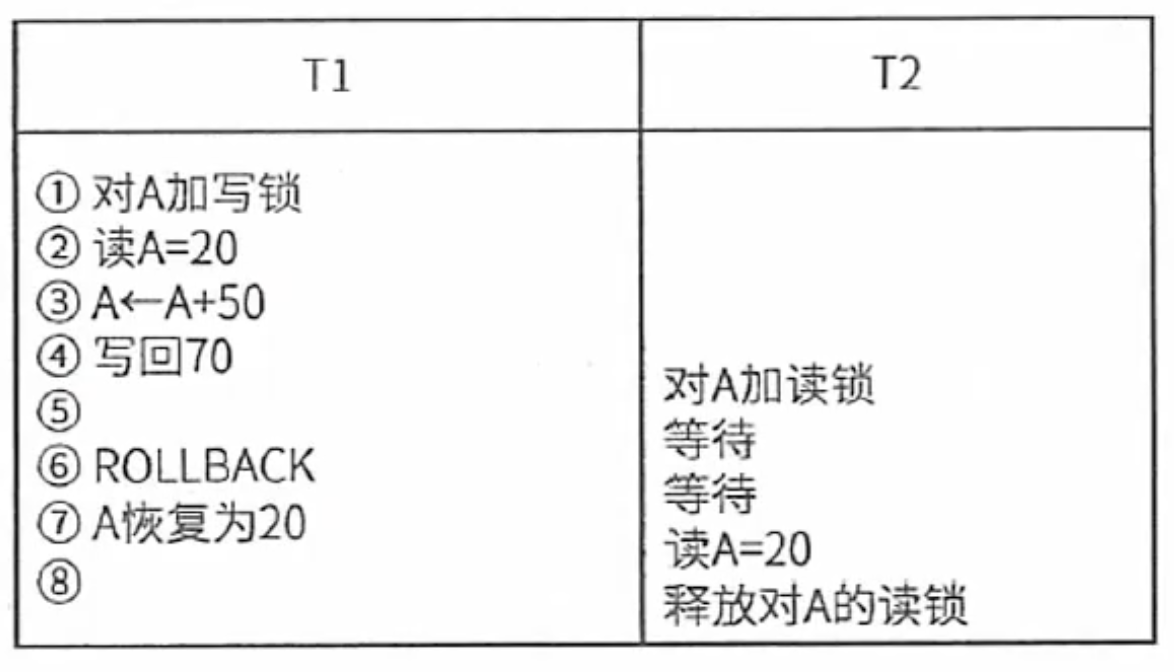
二级封锁协议:一级封锁协议的基础上加上事务T在读数据R之前必须先对其加S锁,读完后即可释放S锁。可解决丢失更新、读脏数据问题。
-
三级封锁协议:一级封锁协议加上事务T在读取数据R之前先对其加S锁,直到事务结束才释放。可解决丢失更新、读脏数据、数据重复读问题。

二、数据库安全
2.1 备份(转储)与恢复
-
备份是指通过数据转储和监理日志文件的方法监理冗余数据,DBA定期地将整个数据库复制到磁带或另一个磁盘上保存起来的过程。这些备用的数据文本称为后备副本。
-
恢复是指把数据库从错误状态恢复到某一个已知的正确状态的功能。当数据库遭到破坏后,就可以利用后备副本把数据库恢复,这时数据库只能恢复到备份时的状态,从那以后的所有更新事务必须重新运行才能恢复到故障时的状态。
2.2 备份分类
- 静态转储:即冷备份,指在转储期间不允许对数据库进行任何存取、修改操作。
-
优点是非常快速的备份方法、容易归档(直接物理复制操作)
-
缺点是只能提供到某一时间点上的恢复,不能做其他工作,不能按表或按用户恢复。
-
- 动态转储:即热备份,在转储期间允许对数据库进行存取、修改操作,因此转储和用户事务可并发执行。
-
优点是可在表空间或数据库文件级备份,数据库扔可使用,可达到秒级恢复;
-
缺点是不能出错,否则后果严重,若热备份不成功,所得结果几乎全部无效。
-
-
完全备份(海量备份):备份所有数据。
-
差量备份:仅备份上一次完全备份之后变化的数据。
-
增量备份:备份上一次备份之后变化的数据。
2.3 数据库故障
数据库的 4 类故障:事务故障、系统故障、介质故障、计算机病毒。
事务故障的恢复有两个操作:撤销事务(UNDO)和 重做事务(REDO)。
介质故障的恢复由数据库管理员装入数据库的副本和日记文件副本,再由系统执行撤销和重做操作。
日志文件:在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。
三、商业智能
商业智能(Business Intelligence,BI)是企业对商业数据的搜集、管理和分析的系统过程,目的是使企业的各级决策者获得知识或洞察力,帮助他们作出对企业更有利的决策。一般认为数据仓库、联机分析处理(OLAP)和数据挖掘是商业智能的三大组成部分。
3.1 数据仓库
数据仓库是一个面向主题的、集成的、非易失的、且随时间变化的数据集合,用于支持管理决策。数据仓库的关键特征是:面向主题、集成的、非易失的、时变的。
-
面向主题:按照一定的主题域进行组织的。
-
集成的:数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息
-
相对稳定的:数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
-
反映历史变化:数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
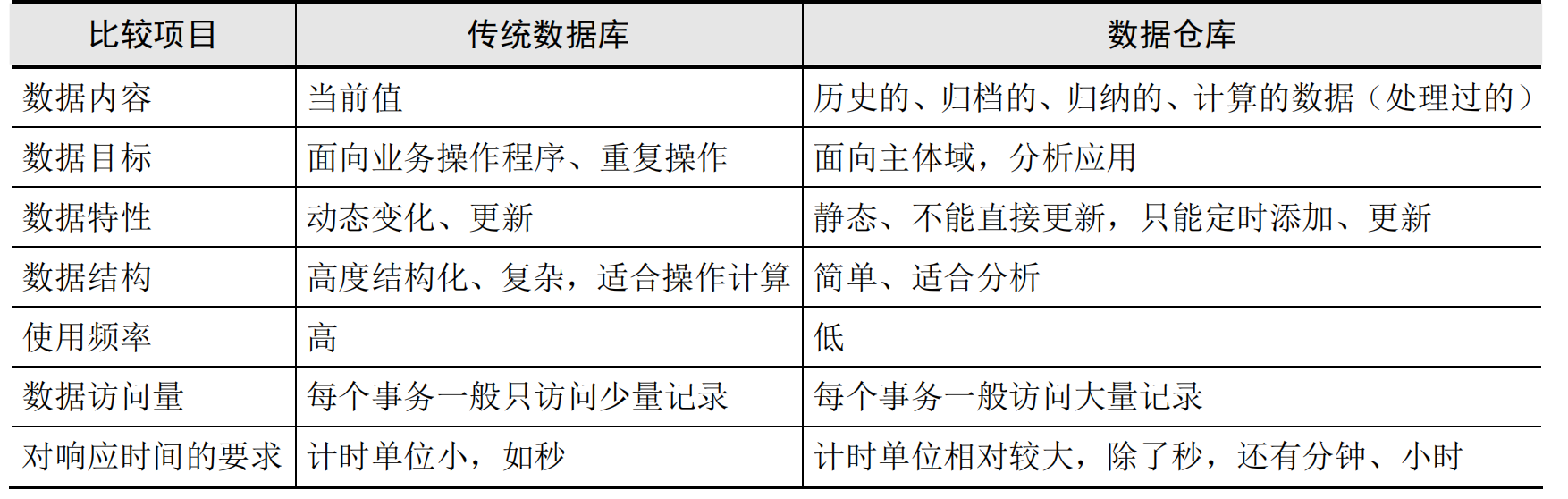
传统数据库与数据仓库的比较:
3.2 数据仓库的结构-OLAP
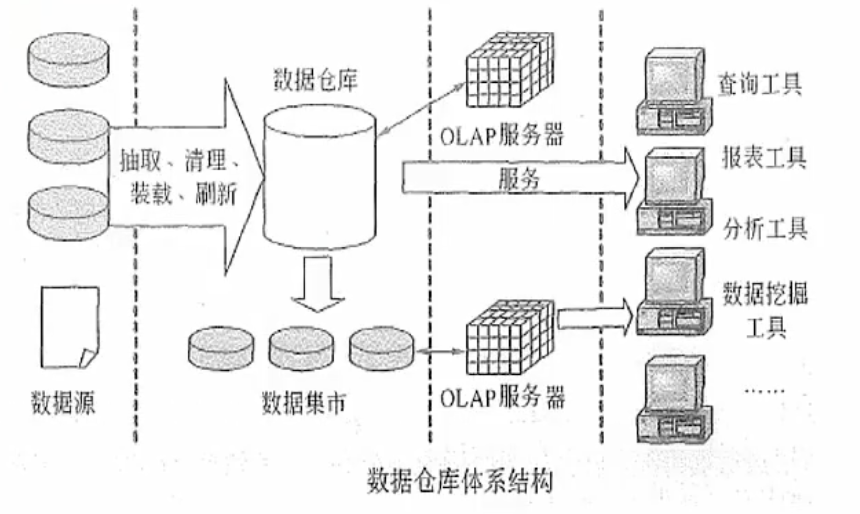
数据仓库的结构通常包含四个层次,如上图所示:
-
1.数据源:是数据仓库系统的基础,是整个系统的数据源泉。
-
2.数据的存储与管理:是整个数据仓库系统的核心。
-
3.0LAP(联机分析处理)服务器:对分析需要的数据进行有效集成,按多维模型组织,以便进行多角度、多层次的分析,并发现趋势
-
4.前端工具:主要包括各种报表工具、查询工具、数据分析工具、数据挖掘工具以及各种基于数据仓库或数据集市的应用开发工具。
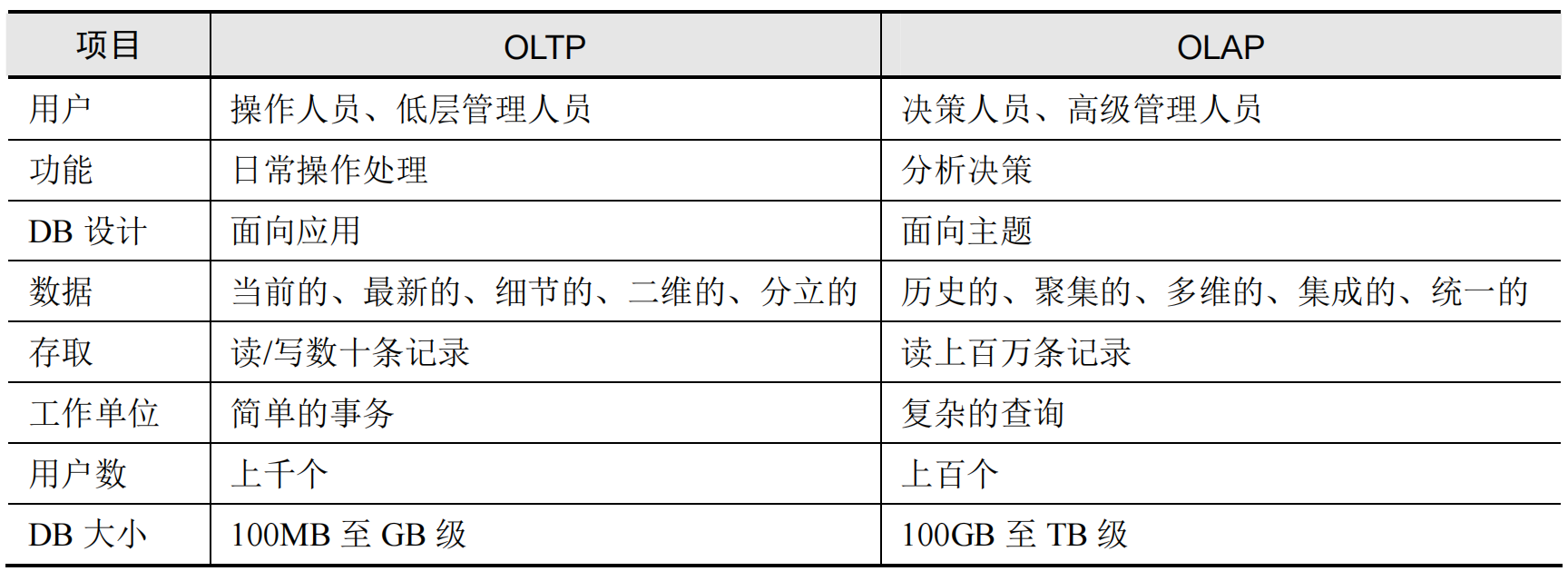
OLTP 即联机事务处理,就是关系数据库的基础;OLAP即联机分析处理,是数据仓库的核心部分。
OLTP 与 OLAP 的区别
3.3 数据挖掘
数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先知、有效和实用三个特征。先前未知的信息是指该信息是预先未曾预料到的,即数据挖掘是要发现那些不能靠直觉发现的信息或知识,甚至是违背直觉的信息或知识,挖掘出的信息越是出乎意料,就可能越有价值。
3.4 分布式数据库
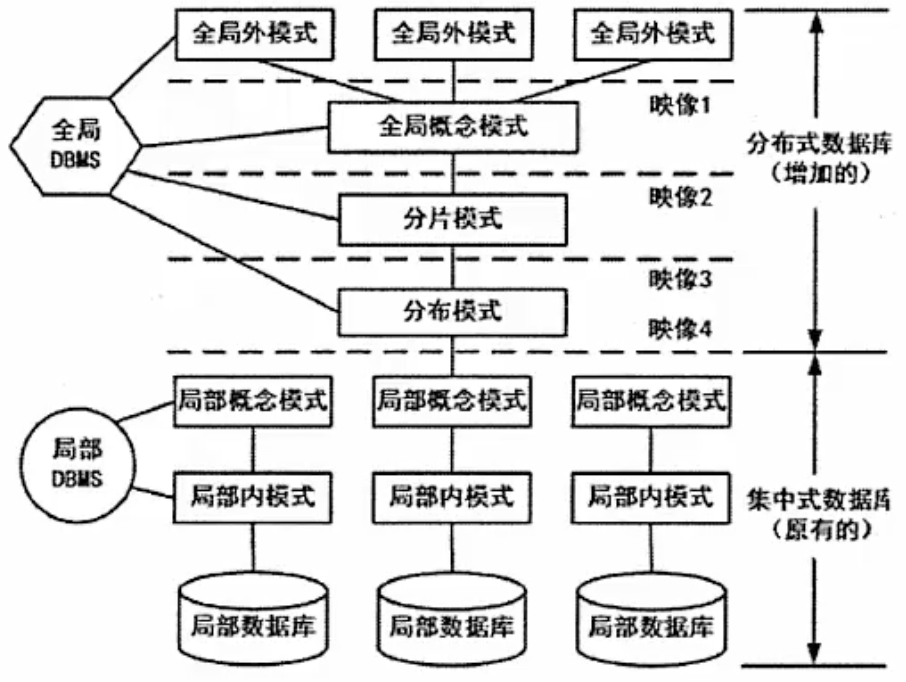
局部数据库位于不同的物理位置,使用一个全局DBMS将所有局部数据库联网管理,这就是分布式数据库。
- 分片模式
-
水平分片:将表中水平的记录分别存放在不同的地方。
-
垂直分片:将表中垂直的列值分别存放在不同的地方。
-
- 分布透明性
-
分片透明性:用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的。
-
位置透明性:应用程序不关心数据存储物理位置的改变。
-
逻辑透明性:用户或应用程序无需知道局部使用的是哪种数据模型。
-
复制透明性:用户或应用程序不关心复制的数据从何而来。
-
四、SQL语句
4.1 创建表(CREATE table)
-
PRIMARY KEY,指定主键;
-
FOREIGN KEY,指定外键。
4.2 修改表(ALTER table)
4.3 删除表(DROP table)
4.4 查询(select)
4.5 分组查询(group by)****
4.6 模糊查询(like)
-
_ 单个任意字符
-
% 0个/多个任意字符
4.7 去除重复记录查询(distinct)
4.8 排序查询(order by)
排序order by,默认为升序,降序要加关键字DESC。
4.9 表-插入数据(insert into)
有多少个字段,就要写多少个值,且是一一对应的。
4.10 表-删除数据(delete/truncate)
❝drop table 表名; 是连表一起删除
4.11 表-修改数据(updata)
4.12 聚合函数
计算和(sum)
计算最大值(max)
计算最小值(min)
计算平均值(avg)
计算个数(count)

- 点赞
- 收藏
- 关注作者
评论(0)