使用Ruoyi的定时任务组件结合XxlCrawler进行数据增量同步实战-以中国地震台网为例

目录
前言
在之前的相关文章中,发表文章列表:,。在这两篇博客当中,我们介绍了XxlCralwer组件,以及如何进行爬虫反爬对抗。这两篇博客都是讲解的全量更新,即第一次全部抓取数据。在我们实际的信息爬取过程当中,肯定会有增量更新的问题,比如定期更新。不要爬取全部的数据,而只是抓取更新的数据,在进行多次的增量更新之后,就能实现数据源的数据一致性。这样的需求很常见,但是在以往的博客中很少进行提及。
本文就是在这样的需求背景下诞生的,我们需要使用XxlCrawler组件对中国地震外网的地震信息进行增量同步。在第一次全量获取数据后,后面在系统运行过程当中,不需要人工干预,我们采用自动任务的方式,将信息抓取的过程完全有程序来完成。文章首先讲解了一般数据同步的方法,然后使用代码的方式介绍在本文中使用的数据同步方法,如何进行重复数据去重,最后讲解如何进行入库,结合Ruoyi中的定时任务组件,讲解如何进行定时任务计划的制定和运行,讲解如何将定时任务和爬虫关联起来。对有对信息进行增量更新的需求有一定的参考意义。
一、数据增量更新机制
要想实现数据的动态更新,一般包含两种更新方式。即全量更新方式和增量更新方式,全量更新模式顾名思义,就是每次进行数据同步时都是全量数据同步。增量更新是基于全量更新基础之上的,每次的数据同步都采用增量的数据同步,即将变化的数据,新增的或者修改的,删除的数据同步到下游系统。下面结合中国地震台网数据,使用两种更新方式进行说明。
1、全量更新机制
全量更新通常应用在数据的首次同步上,往往第一次需要上游系统的所有数据。因此有必要对上游系统进行全量同步。同时也是因为首次同步时,下游系统中往往还没有数据,因此不需要考虑数据重复的问题。只要将爬取的数据进行新增即可。全量更新的技术难度较低,再此不再进行赘述。
2、增量更新机制
在首次同步好了全量数据以后,要想实现增量更新,数据增量同步ETL每次只处理增、删、改的变化数据,减少大量非变化数据同步。与数据全量同步ETL相比,数据增量同步ETL可以用最少的资源提高数据同步效率。其大致的思路有以下几种:
1. 时间戳:最常见的方式。但是在业务系统里,不是每张表都有时间戳。
2. 触发器:可靠性较高。但是对业务系统数据库性能损耗较大。
3. 全量对比得出增量数据更新:对源数据库的性能损耗较小。但是大数据量对比更新时,对工具的性能开销需求较大。
4. 全量对比MD5方式:建立一个结构类似的MD5临时表,通过MD5校验码比对。
5. 日志解析:常见的数据库具备日志归档等功能,从日志获取变化数据,通过代码来开发和管理。
通过之前的台网数据抓取得到的数据可以了解到,在我们的数据表格中是包含了时间字段了,因此我们可以使用基于时间戳的方案来实现台网数据的增量更新。
二、功能时序图设计
为了实现中国地震外网数据定时同步,这里我们采用面向对象分析(OOA)的模式进行。同时为了比较清晰的说明其同步机制,我们将其大致的业务调用时序图进行设计。本节即主要描述增量同步的时序图设计。
1、原始请求分析
为了简单介绍相关接口及正确获取增量数据,首先我们来看一下中国地震台网的更新接口。在其历史查询的接口列表中。我们可以看到其可以实现日期查询,具体的功能查询界面如下:

然后我们来看一下实际的请求接口,打开控制台的网络监控Tab页:
https://www.ceic.ac.cn/ajax/search?page=1&&start=2024-05-01&&end=&&jingdu1=&&jingdu2=&&weidu1=&&weidu2=&&height1=&&height2=&&zhenji1=&&zhenji2=&&callback=jQuery18005659035271001251_1714803161229&_=1714807031625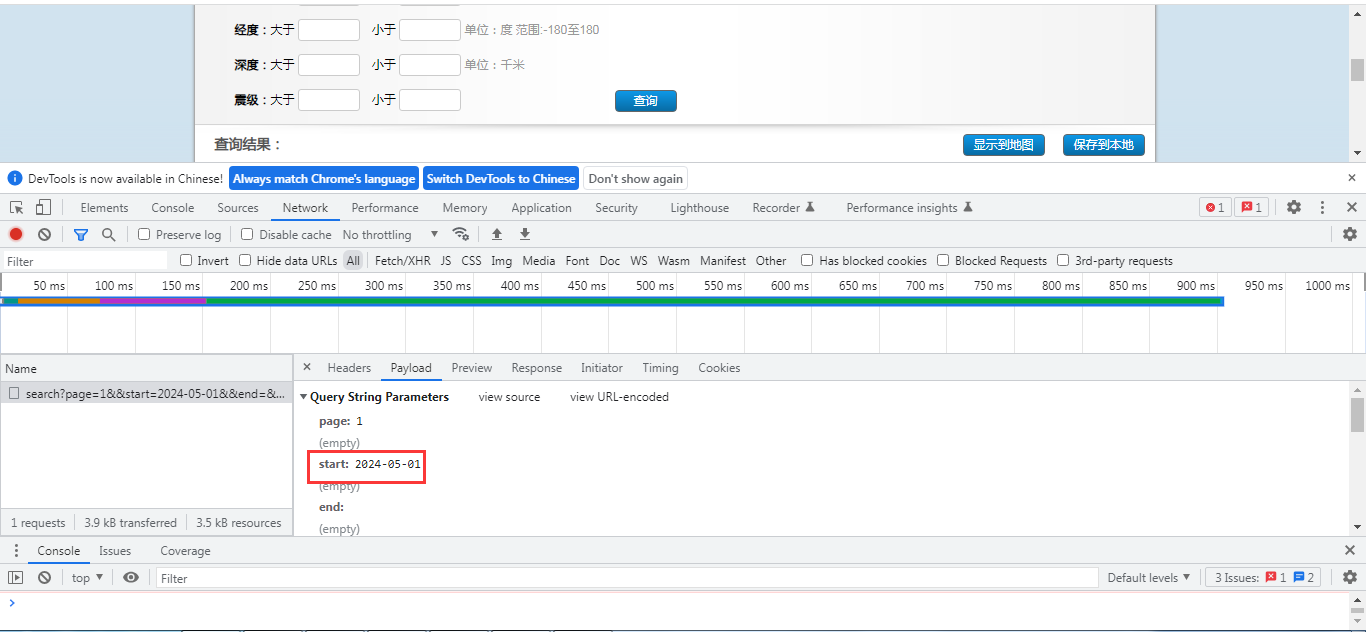
可以很明显看到,它的开始日期参数放到了start中,在start中绑定了开始查询参数。 在我们接口请求中也是利用这个时间戳字段来实现信息的增量更新。
2、业务时序图
为了实现信息请求接口的增量更新,同时在实际请求当中,可能会遇到的数据重复判断的问题,因此我们需要进行数据的去重。我们使用cata_id和epi_id进行去重处理。具体的业务时序图如下:
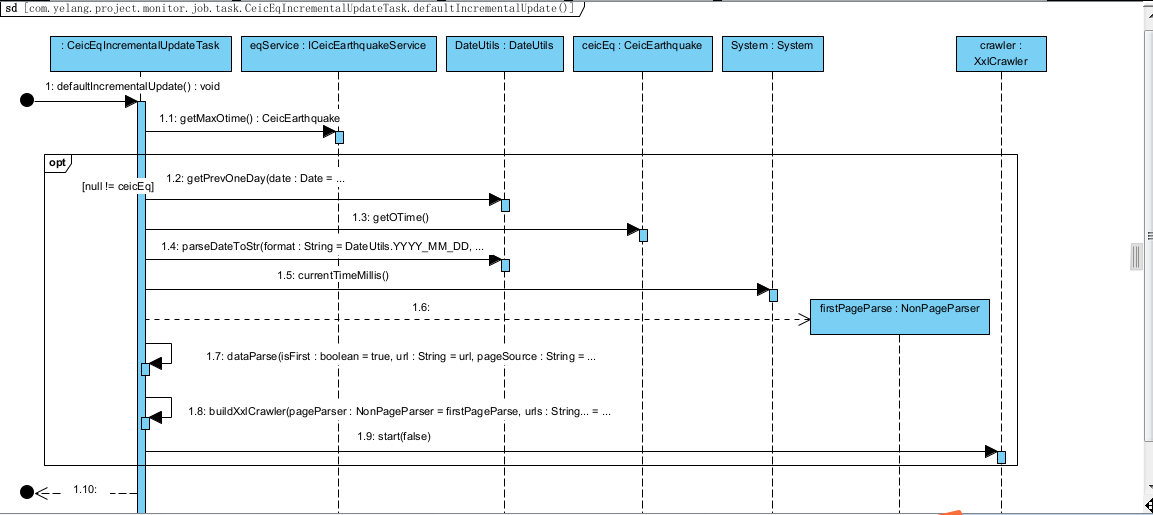
从时序图来看,大致的数据同步过程分了10步,下面针对每一步来进行简单说明:
1.1:首先从数据库中获取已经同步数据的最大日期作为同步基础时间戳。
1.2:如果基础时间戳不为空,在此时间戳之上,我们采用N-1,这么做是为了避免数据历史数据没有及时同步,这里可能会有数据重复,因此一定要进行数据去重的机制保证数据的一致性。
1.3-1.5:从数据库中获取同步时间戳和拼接系统请求时间戳的方法。
1.6:构造XxlCrawler爬取器,设置页面处理对象,进行首页信息爬取。
1.7-1.8:定义下一页爬取规则,实现自动爬取所有其它页面的数据。
1.9:启动信息抓取器,进行爬取。
三、后台定时任务的设计与实现
在明确了相关的定时任务之后,这里我们在Ruoyi的框架下进行开发,需要按照时序图设计相关的时序逻辑。完整的增量更新任务类关键代码如下:
自动任务的入口方法是defaultIncrementalUpdate(),在这里进行任务的调度。请注意数据转换的统一定义方法如下:
实现增量的逻辑是第一次请求的时候,通过返回的num来决定是否往下爬取,只有超过2页才需要进行剩余页面的请求。
使用数据库的机制进行数据重复判断的逻辑如下:
四、Ruoyi自动任务配置
这里采用Ruoyi进行自动任务配置,在自动任务框架驱动下进行数据的增量更新。因此需要我们进行任务的配置。本节将重点介绍Ruoyi的定时任务配置,以及如何关联到增量同步组件。
1、Ruoyi自动任务配置
应用程序启动后,在系统监控中打开定时任务子菜单,可以看到系统中定义的所有定时任务列表。
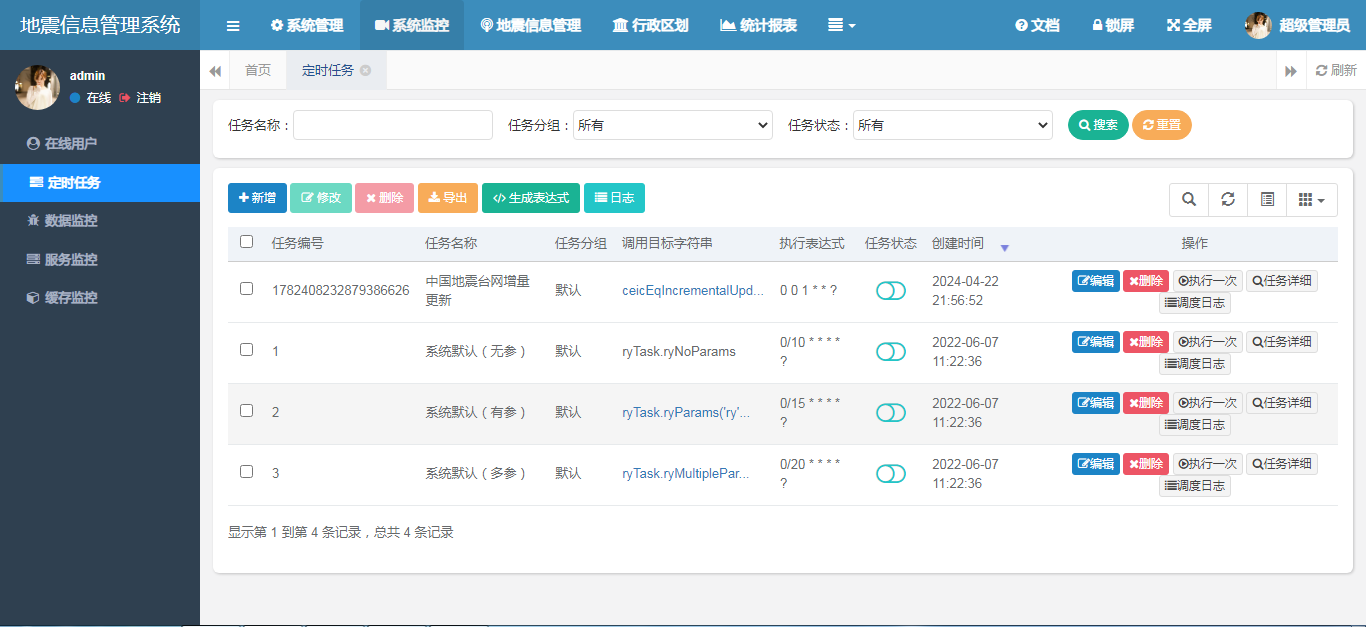
这里我已经定义了一个台网信息同步的定时任务,默认的是每天1点执行(时间频率请结合实际业务来进行配置),请不要给目标系统造成太大的异常流量。不要太频繁的发起访问。
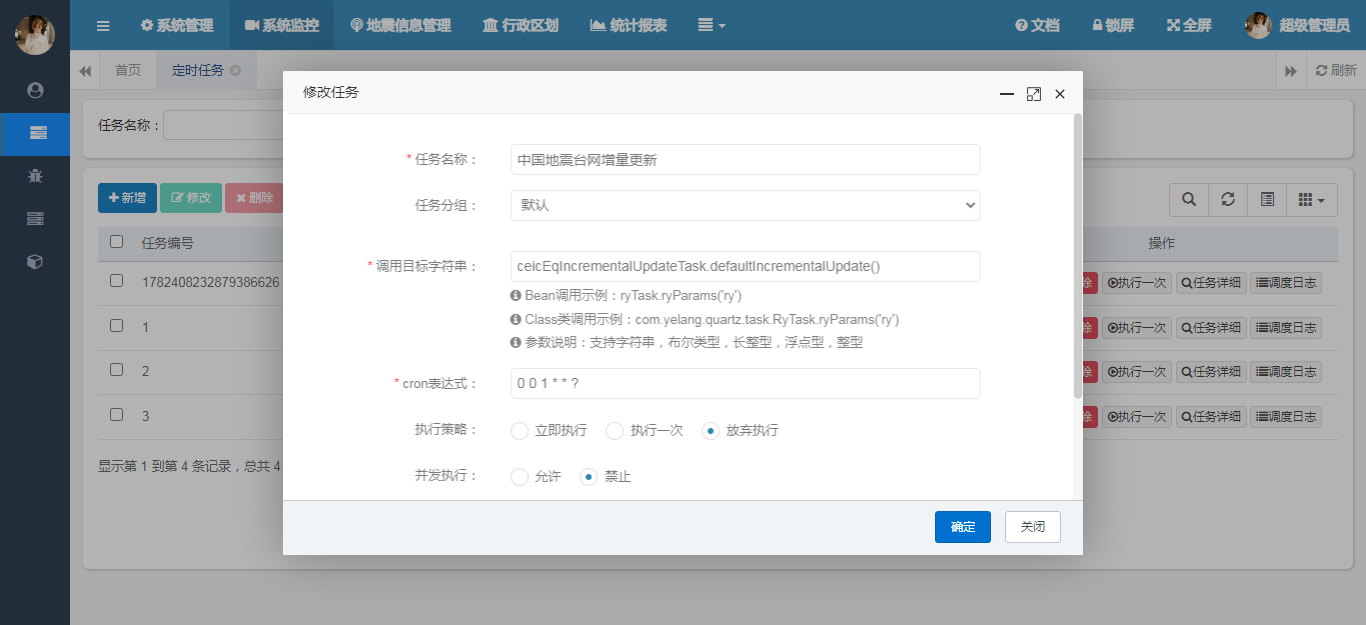
这里调用的ceicEqIncrementalUpdateTask.defaultIncrementalUpdate()。具体的调用参考如下:
Bean调用示例:ryTask.ryParams('ry');
Class类调用示例:com.yelang.quartz.task.RyTask.ryParams('ry')
参数说明:支持字符串,布尔类型,长整型,浮点型,整型。
2、任务调度
在任务创建好之后,我们可以进行任务开启,开启后,任务会自动在后台运行,在制定时间进行触发。由于我们配置的每天1点进行任务创建及运行,因此这里我们选择人工运行的模式,使用手动运行的模式。点击操作按钮中的执行一次。如下图所示:
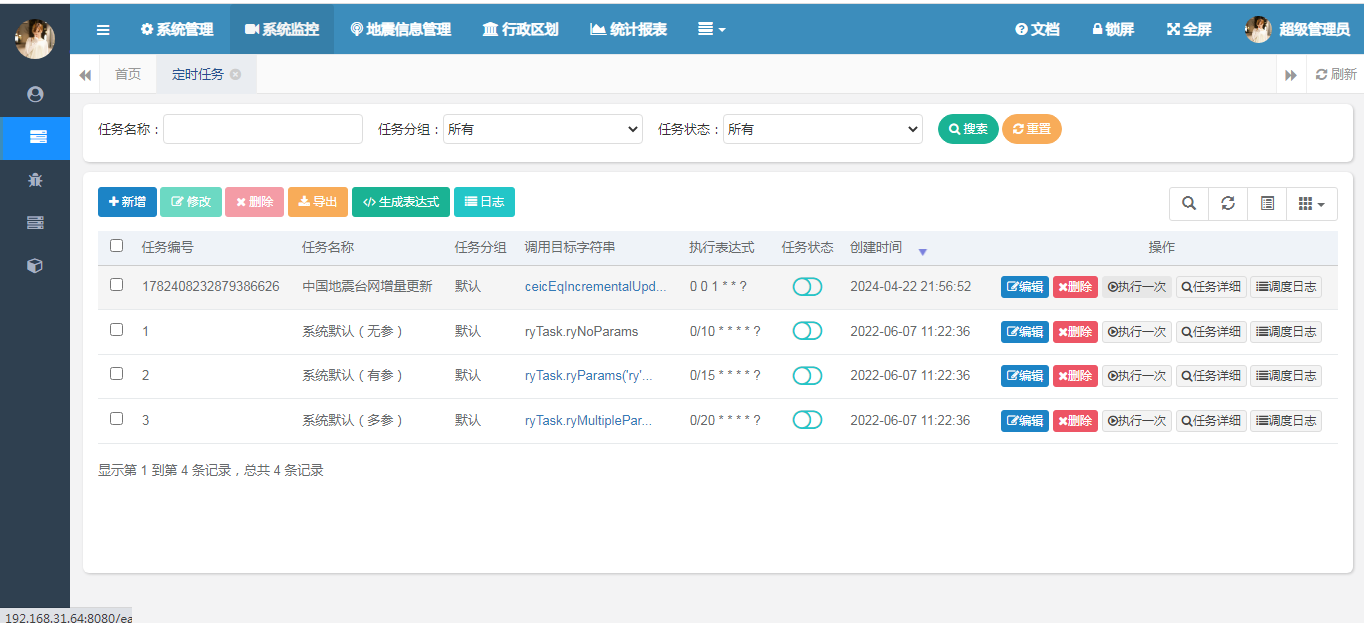
执行任务之前,我们来数据库中看一下数据的总条数是12459条:
然后我们来执行任务调度,可以看到控制台进行了信息输出:
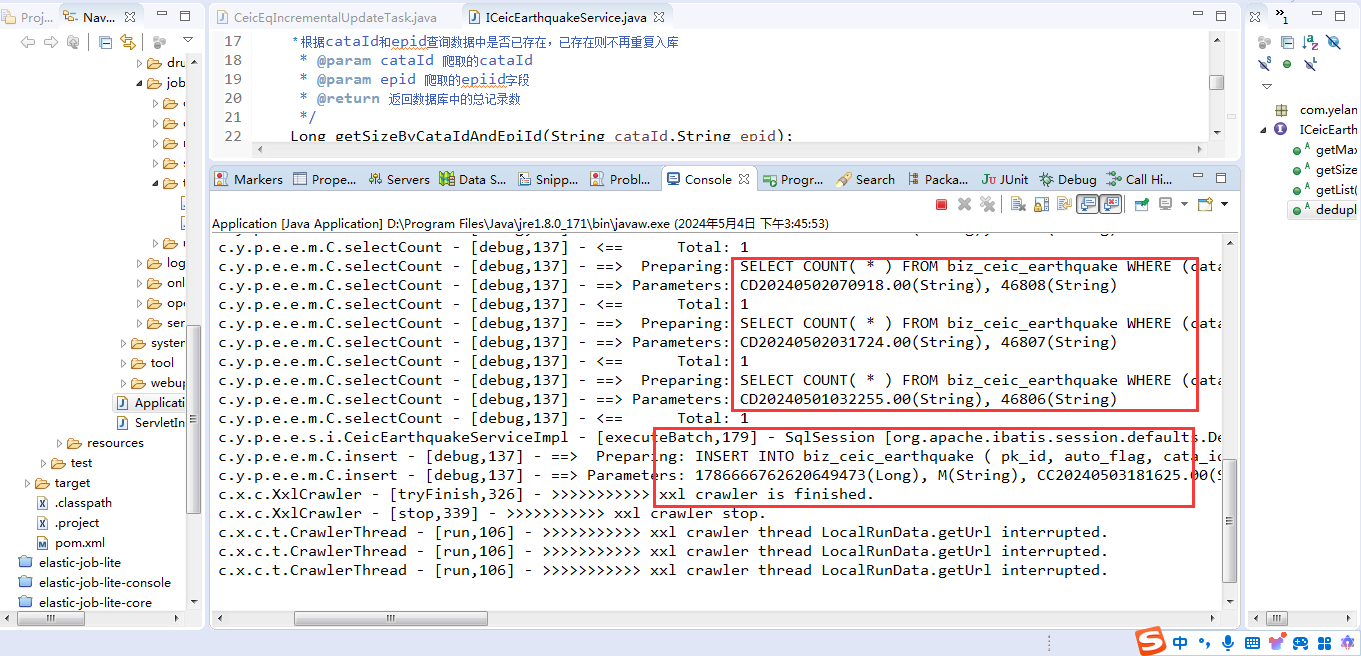
在数据库中可以看到数据总数发生了变化,变成了12460(+1),成功将最新的数据同步到了数据库中。
总结
以上就是本文的主要内容, 本文需要使用XxlCrawler组件对中国地震外网的地震信息进行增量同步。在第一次全量获取数据后,后面在系统运行过程当中,不需要人工干预,我们采用自动任务的方式,将信息抓取的过程完全有程序来完成。文章首先讲解了一般数据同步的方法,然后使用代码的方式介绍在本文中使用的数据同步方法,如何进行重复数据去重,最后讲解如何进行入库,结合Ruoyi中的定时任务组件,讲解如何进行定时任务计划的制定和运行,讲解如何将定时任务和爬虫关联起来。对有对信息进行增量更新的需求有一定的参考意义。行文仓促,难免有不足之处,如有不足之处,欢迎各位专家朋友不吝赐教,万分感谢。

- 点赞
- 收藏
- 关注作者
评论(0)