四大集合20连问,抗住!

先赞后看,Java进阶一大半
业务开发究竟要使用LinkedList还是ArrayList?ArrayList查询性能更高,但LinkedList插入、删除效率更高。
LinkedList 的作者 Joshua Bloch 跑出来说了下面这句话,有趣。
我是南哥,相信对你通关面试、拿下Offer有所帮助。
敲黑板:本文总结了Java四大集合:List、Map、Set、Queue常见的面试题!
⭐⭐⭐收录在《Java学习/进阶/面试指南》:https://github/JavaSouth
1. List集合
1.1 集合概述
面试官:List集合都知道哪些对象?
作为四大集合之一的List,在业务开发中我们比较常见的是以下 3 种:ArrayList、Vector、LinkedList,业务开发我们接触最多就是容器类库了,容器类库可以说是面向对象语言最重要的类库。大家看看在工作里你比较熟悉的是哪个?

1.2 ArrayList
面试官:ArrayList为什么线程不安全?
普通的数组类型,我们是这么创建的int[] arr = new int[66]。数组可以创建固定长度的容量,不会过度浪费资源,但有优点也有缺点。如果长度设置过小,你就会看到一个大大的ArrayIndexOutOfBoundsException。
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 6
at org.codeman.Test.main(MsgExtractor.java:11)
也别把数组说得那么不堪,起码数组是线程安全的,ArrayList却是线程不安全的。另外ArrayList底层的存储容器实际上也是一个Object数组,大家看看以下源码。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
那ArrayList为什么线程不安全?原因就在下面源码这个size。
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
ArrayList底层是根据当前size的值来作为新添加元素的下标,南哥假设目前size为0,有线程A、线程B都想要添加一个元素。
线程A在下标0插入A元素,当添加成功后还没有对size进行++。此时CPU调度让线程B运行,线程B也在下标0插入B元素,覆盖了A元素。线程A、B执行到程序末尾对size进行++,此时就有问题了,大家发现了没?
size进行了两次加法变成了2,但却只有一个B元素添加到了下标0位置,后面再添加其他元素下标1也会是空的。
1.3 AarrayList面试小tip
另外ArrayList有些小知识点大家也需要记一记,面试官可能照着公司给的面试题稿子问你:
(1)ArrayList初始容量为10。
(2)ArrayList负载因子为1,也代表ArrayList底层数组满了才会扩容。而数组扩容长度为原始长度的1.5倍。
(3)ArrayList的扩容时间复杂度为O(n)。
1.4 Vector
面试官:知道线程安全的List集合吗?
Vector和ArrayList的源码说明很相似,都是告诉你它们相比数组来说是一个可调整大小的数组实现,大家看看以下源码注释。
// Resizable-array implementation of the <tt>List</tt> interface.
// List接口的可调整大小数组实现。
// The {@code Vector} class implements a growable array of objects.
// Vector类实现了一个可增长的对象数组。
那Vector和ArrayList有什么区别?南哥给大家贴下get和set方法的源码就一清二楚,Vector的元素操作都是线程安全性的,每个方法都有synchronized进行修饰,而ArrayLiset却是一个线程不安全的List集合。
// Vector源码
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized E set(int index, E element) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
两者除了线程安全性的区别,在效率上,ArrayList相比Vector来说效率更高。Vector虽然线程安全了,但每个操作方法是同步的,也意味着增加了额外的开销。
一般我们在业务开发也很少使用到Vector,至少南哥还没有在开发中使用过Vector,小伙伴有写过的吗?如果是需要保证线程安全的场景,我一般是在集合的外部方法加上锁机制,或者使用线程安全的List集合,我更多使用的是CopyOnWriteArrayList而不是Vector。
1.5 Vector面试小tip
(1)Vector初始容量为10。
(2)Vector负载因子为1,也代表Vector底层数组满了才会扩容。而数组扩容长度为原始长度的2倍。
(3)Vector的扩容时间复杂度为O(n)。
1.6 LinkedList
面试官:双向链表你说说?
LinkedList是JDK提供的一个双向链表实现,我们来看看官方源码的介绍。
List和Deque接口的双向链表实现。实现所有可选的列表操作,并允许所有元素(包括null )。
所有操作的执行方式都符合双向链表的预期。索引到列表中的操作将从列表的开头或结尾(以更接近指定索引为准)遍历列表Doubly-linked list implementation of the {@code List} and {@code Deque} interfaces. Implements all optional list operations, and permits all elements (including {@code null}).
我们来看看LinkedList的数据结构,节点类型分为头节点和尾节点。
transient Node<E> first;
transient Node<E> last;
同时每个节点有指向上一个节点的指针和下一个节点的指针。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList比较重要的知识点是为什么它也是一个线程不安全的List集合实现?这一点和上文介绍的头节点first有关。
LinkedList对元素的操作并没有使用synchronized进行同步控制,如果现在有两个线程A、B同时要使用addFist添加第一个头节点。当A线程把A元素设置为头节点后,此时的头节点还没有和旧链表建立连接。而线程B执行时又把B元素设置为了头节点,注意!此时A元素被覆盖了。
以上两个线程的两个添加操作最终却只添加了一个元素。
/**
* Inserts the specified element at the beginning of this list.
*
* @param e the element to add
*/
public void addFirst(E e) {
linkFirst(e);
}
2. Set集合
2.1 HashSet
面试官:你说说对HashSet的理解?
Set集合区别于其他三大集合的重要特性就是元素具有唯一性,南友们记不住这个特性的话,有个易记的方法。Set集合为什么要叫Set呢?因为Set集合的命名取自于我们小学数学里的集合论(Set Theory),数学集合一个很重要的概念就是每个元素的值都互不相同。
Set集合常见的有实例有:HashSet、LinkedHashSet、TreeSet,南哥先缕一缕HashSet。
// HashSet类源码
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {...}
HashSet底层实现其实是基于HashMap,HashMap的特点就是Key具有唯一性,这一点被HashSet利用了起来,每一个HashMap的Key对应的就是HashSet的元素值。来看看官方源码的解释。
此类实现Set接口,由哈希表(实际上是HashMap实例)支持。它不保证集合的迭代顺序;特别是,它不保证顺序随时间保持不变。此类允许null元素。
我们创建一个HashSet对象,实际上底层创建了一个HashMap对象。
// HashSet构造方法源码
public HashSet() {
map = new HashMap<>();
}
HashSet一共提供了以下常用方法,不得不说HahSet在业务开发中还是用的没那么多的,南哥在框架源码上看HashSet用的就比较多,比如由Java语言实现的zookeeper框架源码。
(1)添加元素
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
我们看上面add方法的源码,是不是调用了HashMap的put方法呢?而put方法添加的Key是HashSet的值,Val则是一个空的Object对象。PRESENT是这么定义的。
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
(2)判断元素是否存在
public boolean contains(Object o) {
return map.containsKey(o);
}
HashSet的contains方法同样是调用HashMap判断Key是否存在的方法:containsKey。
(3)移除元素
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
2.2 LinkedHashSet
面试官:LinkedHashSet呢?
接着轮到LinkedHashSet,同为Set集合之一,它和上文的HashSet有什么区别?南哥卖个关子。
源码对LinkedHashSet的解释。
Hash table and linked list implementation of the Set interface, with predictable iteration order. This implementation differs from HashSet in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is the order in which elements were inserted into the set (insertion-order).
源码的大概意思就是:Set接口的哈希表和链表实现,具有可预测的迭代顺序。此实现与HashSet的不同之处在于,它维护一个贯穿其所有条目的双向链表。此链表定义迭代顺序,即**元素插入集合的顺序 (**插入顺序)。
底层数据结构是一条双向链表,每个元素通过指针进行相连,也就有了按插入顺序排序的功能。
知道了LinkedHashSet的特性,看看他的构造方法。
/**
* 构造一个新的、空的链接哈希集,具有默认初始容量(16)和负载因子(0.75)。
*/
public LinkedHashSet() {
super(16, .75f, true);
}
这个super方法向上调用了底层C语言源码实现的LinedHashMap的构造方法。LinkedHashMap的特点就是元素的排序是根据插入的顺序进行排序,那LinkedHashSet也就继承了这个特性。
// C语言源码
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
LinkedHashSet的常见方法和HashSet一样,同样是add()、contains()、remove(),这里我写个简单的Demo。
public static void main(String[] args) throws IOException {
LinkedHashSet<Integer> set = new LinkedHashSet<>();
set.add(1);
System.out.println(set.contains(1));
set.remove(1);
System.out.println(set.contains(1));
}
# 运行结果
true
false
2.3 TreeSet
TreeSet和它们比有什么特性?
轮到你了,TreeSet。我们南友们很好奇为什么他叫TreeSet?
因为他是基于TreeMap实现的。。。
但根本原因不是,TreeMap的底层是通过红-黑树数据结构来实现自然排序,那TreeSet也就继承了这个特性。
官方源码对TreeSet的解释:
基于TreeMap的NavigableSet实现。元素使用其自然顺序进行排序,或者根据使用的构造函数,使用创建集合时提供的Comparator进行排序。
源码解释告诉我们,TreeSet和HashSet、LinkedHashSet不同的特性在于,元素既不像HashSet一样无序,也不是像LinkedHashSet一样是以插入顺序来排序,它是根据元素的自然顺序来进行排序。
b、c、a这三个元素插入到TreeSet中,自然顺序就和字母表顺序一样是:a、b、c。
public static void main(String[] args) throws IOException {
TreeSet<String> treeSet = new TreeSet<>();
treeSet.add("b");
treeSet.add("c");
treeSet.add("a");
System.out.println(treeSet);
}
# 运行结果
[a, b, c]
TreeSet除了拥有以下的add()、contains()、remove()方法。
// 如果指定元素尚不存在,则将其添加到此集合中。
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
// 如果此集合包含指定元素,则返回true
public boolean contains(Object o) {
return m.containsKey(o);
}
// 如果存在指定元素,则从此集合中移除该元素。
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
值得提出来的是,TreeSet还拥有first()、last(),可以方便我们提取出第一个、最后一个元素。
// 返回集合中的第一个元素。
public E first() {
return m.firstKey();
}
// 返回集合中的最后一个元素。
public E last() {
return m.lastKey();
}
2.4 TreeSet自定义排序
面试官:那TreeSet要怎么定制排序?
TreeSet的自定义排序我们要利用Comparator接口,通过向TreeSet传入自定义排序规则的Comparator来实现。
官方源码是这么解释的,南友们看一看。
// 构造一个新的空树集,根据指定的比较器进行排序。
// 插入到集合中的所有元素都必须能够通过指定的比较器相互比较: comparator. compare(e1, e2)不得对集合中的任何元素e1和e2抛出ClassCastException 。
// 如果用户尝试向集合中添加违反此约束的元素,则add调用将抛出ClassCastException
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
传入Comparator接口时,我们还需要定义compare方法的游戏规则:如果compare方法比较两个元素的大小,返回正整数代表第一个元素 > 第二个元素、返回负整数代表第一个元素 < 第二个元素、返回0代表第一个元素 = 第二个元素。
下面我写了一个Demo,Comparator接口的规则是这样:人的岁数越小,那么他排名越靠前。
public class JavaProGuideTest {
public static void main(String[] args) {
TreeSet set = new TreeSet(new Comparator() {
public int compare(Object o1, Object o2) {
Person p1 = (Person)o1;
Person p2 = (Person)o2;
return (p1.age > p2.age) ? 1 : (p1.age < p2.age) ? -1 : 0;
}
});
set.add(new Person(5));
set.add(new Person(3));
set.add(new Person(6));
System.out.println(set);
}
@Data
@AllArgsConstructor
private static class Person {
int age;
}
}
# 执行结果
[JavaProGuideTest.Person(age=3), JavaProGuideTest.Person(age=5), JavaProGuideTest.Person(age=6)]
3. Queue集合
3.1 Queue集合概述
面试官:你说说Queue集合都有什么常用类?
JDK源码对Queue集合是这么解释的,大家看看。
A collection designed for holding elements prior to processing.
专为在处理之前保存元素而设计的集合。
南哥是这么理解的,List集合用于存储常用元素、Map集合用于存储具有映射关系的元素、Set集合用于存储唯一性的元素。Queue集合呢?所有的数据结构都是为了解决业务问题而生,而Queue集合这种数据结构能够存储具有先后时间关系的元素,很适用于在业务高峰期,需要缓存当前任务的业务场景。像Kafka、RabbitMQ、RocketMQ都是队列任务这种思想。
Queue集合底层接口提供的方法很简单,一共有 6 个。
// 添加元素。没有可用元素则简单返回false
boolean offer(E e);
// 添加元素。没有可用元素则抛出IllegalStateException
boolean add(E e);
// 移除队列的头部元素。如果此队列为空则返回null 。
E poll();
// 移除队列的头部元素。该方法和poll不同之处在于,如果此队列为空,则抛出异常。
E remove();
// 检索但不移除此队列的头部。如果此队列为空,则返回null 。
E peek();
// 检索但不移除此队列的头部。该方法和peek唯一不同之处在于,如果此队列为空,则抛出异常
E element();
Queue集合常用的实现类如下,我会一一讲来。包括双端队列的两个实现类:LinkedList、ArrayDeque,优先级队列:PriorityQueue,线程安全相关的Queue实现类:LinkedBlockingQueue、ArrayBlockingQueue、ConcurrentLinkedQueue。

3.2 双端队列
面试官:双端队列的两个实现类知道吧?
双端队列是Queue集合的一个子接口,顾名思义相比普通队列来说,双端队列可以往前、也可以往后顺序插入元素。比如我下面给出一段队列的初始化。
Queue<Integer> queue = new LinkedList<>();
Deque<Integer> deque = new LinkedList<>();
queue.add(1);
deque.addLast(1);
deque.addFirst(1);
同样是new LinkedList<>()来实例化队列,如果使用双端队列Deque接口,那这个队列就可以使用addFirst、addLast等双端队列特有的方法。
有南友就会问:那ArrayQueue呢?这两者都是双端队列Deque的底层实现,但底层数据结构不同,LinkedList底层数据结构是一个双向链表,看看它有前指针next、后指针prev。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
而ArrayDeque底层数据结构是一个Object类型的数组。
transient Object[] elements;
为什么要这么设计呢?其实这两种不同的设计就可以高效适用于不同的业务场景。双向链表实现的Deque随机查找的性能差,但插入、删除元素时性能非常出色,适用于修改操作更频繁的业务场景。
而数组实现的Deque,也就是ArrayDeque,它的插入、删除操作性能不如前者,但随机查找的性能非常出色,更适用于查询操作更频繁的业务场景。
3.3 优先级队列
面试官:优先级队列有什么作用?
优先级队列的实现类叫PriorityQueue,PriorityQueue虽然属于队列的一份子,不过它违背了队列最基本的原则:FIFO先进先出原则。它背叛了组织!
PriorityQueue的特性是它并不按常规队列一样顺序存储,而是根据元素的自然顺序进行排序,使用出队列的方法也是输出当前优先级最高的元素。例如以下代码输出的一样。
public static void main(String[] args) {
Queue<Integer> queue = new PriorityQueue<>();
queue.offer(6);
queue.offer(1);
queue.offer(3);
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
}
# 执行结果
1
3
6
但如果我们直接打印PriorityQueue的所有元素,发现他其实并不是按元素的自然顺序进行存储。
public static void main(String[] args) {
Queue<Integer> queue = new PriorityQueue<>();
queue.offer(6);
queue.offer(1);
queue.offer(3);
System.out.println(queue);
}
# 执行结果
[1, 6, 3]
why?其实PriorityQueue底层数据结构是一个平衡二叉堆:transient Object[] queue,如果你直接打印,打印的是堆里面的存储元素。
对于PriorityQueue来说,它只保证你使用poll()操作时,返回的是队列中最小、或最大的元素。
3.4 阻塞队列
面试官:阻塞队列呢?
JDK提供的阻塞队列接口为BlockingQueue,南哥先说说BlockingQueue的子类实现之一:ArrayBlockingQueue。
阻塞队列的特别之处在于当生产者线程会往队列放入元素时,如果队列已满,则生产者线程会进入阻塞状态;而当消费者线程往队列取出元素时,如果队列空了,则消费者线程会进入阻塞状态。
但队列的状态从满变为不满,消费者线程会唤醒生产者线程继续生产;队列的状态从空变为不空,生产者线程会唤醒消费者线程继续消费。
所以ArrayBlockingQueue很适合用于实现生产者、消费者场景。大家看看这个Demo。
public class Test {
public static void main(String[] args) {
// 创建一个容量为 3 的ArrayBlockingQueue
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(3);
// 创建并启动生产者线程
Thread producerThread = new Thread(new Producer(queue));
Thread consumerThread = new Thread(new Consumer(queue));
producerThread.start();
consumerThread.start();
}
}
// 生产者类
class Producer implements Runnable {
private BlockingQueue<Integer> queue;
public Producer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 1; i <= 6; i++) {
System.out.println("生产者生产了: " + i);
queue.put(i);
Thread.sleep(150); // 模拟生产过程中的延迟
}
queue.put(-1); // 使用特殊值表示结束生产
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 消费者类
class Consumer implements Runnable {
private BlockingQueue<Integer> queue;
public Consumer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
while (true) {
Integer item = queue.take();
if (item == -1) {
break; // 遇到特殊值,退出循环
}
System.out.println("消费者消费了: " + item);
Thread.sleep(100); // 模拟消费过程中的延迟
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
# 执行结果
生产者生产了: 1
消费者消费了: 1
生产者生产了: 2
消费者消费了: 2
生产者生产了: 3
消费者消费了: 3
生产者生产了: 4
消费者消费了: 4
生产者生产了: 5
消费者消费了: 5
生产者生产了: 6
消费者消费了: 6
LinkedBlockingQueue也是阻塞队列的实现之一,不过它和上面的ArrayBlockingQueue区别在于底层数据结构是由双向链表进行实现。
// LinkedBlockingQueue源码双向链表
transient Node<E> head;
private transient Node<E> last;
4. Map集合
4.1 HashMap的内部结构
面试官:你说下HashMap的内部结构?
HashMap内部存储数据的对象是一个实现Entry接口的Node数组,也称为哈希桶transient Node<K,V>[] table,后面我们称Node数组为Entry数组。Entry数组初始的大小是16。
Node节点的内部属性key、value分别代表键和值,hash代表key的hash值,而next则是指向下一个链表节点的指针。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
4.2 键值的添加流程
面试官:那一个键值是怎么存储到HashMap的?
首先会调用hash方法计算key的hash值,通过key的hashCode值与key的hashCode高16位进行异或运算,使hash值更加随机与均匀。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
再通过该hash值与Entry数组的长度相与,得到要存储到的索引位置int index = (table.length - 1) & hash。如果该索引位置是空的,会把键值直接添加到表头,如果哈希冲突了则会用链表法形成一条链表。
数据添加后,会判断当前容量是否到达了threshold阈值,threshold等于负载因子loadFactor * table.length。负载因子默认是0.75,threshold第一次扩容时为0.75 * 16 = 12。
如果到达阈值了则会对Entry数组进行扩容,扩容成为原来两倍容量的Entry数组。
4.3 红黑树
面试官:HashMap链表还会转换成什么?
当链表长度 >= 8时,会把链表转换为红黑树。
是这样的,HashMap的链表元素如果数量过多,查询效率会越来越低,所以需要将链表转换为其他数据结构。而二叉搜索树这种数据结构是绝对的子树平衡,左节点比父节点小,右节点比父节点大,在极端情况会退化为链表结构。
而红黑树放弃了绝对的子树平衡,转而追求的是一种大致平衡,在极端情况下的数据查询效率更优。
# 红黑树数据结构
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
4.4 线程不安全的HashMap
面试官:HashMap为什么线程不安全?
一、在多线程环境下,可能会出现数据覆盖的问题。
例如前面提到如果索引位置为空则直接添加到表头,如下面源码所示。此时如果有两个线程同时进入if语句,线程A把数据插入到表头,接着线程B把他的数据覆盖到表头,这样就产生了数据覆盖的问题,线程A的数据相当于消失了。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
二、另外在多线程环境下,还可能会出现数据不一致的问题。
在插入数据后,判断是否需要扩容是以下源码。
if (++size > threshold)
resize();
若两个线程同时进入了++size代码块,对size的修改分为三个步骤:读取、计算、赋值。线程A、线程B同时读取了size是0,两者计算时size都为1,后面赋值时把size = 1赋值给了size两次。
但实际上期望的size应该是2,此时就出现了数据不一致的问题,Entry数组的容量会出现错误。
4.5 线程安全的ConcurrentHashMap
面试官:有线程安全的Map吗?
有的,JDK提供了线程安全的ConcurrentHashMap。
(1)ConcurrentHashMap对于底层Entry数组、size容量都添加了可见性的修饰,保证了其他线程能实时监听到该值的最新修改。
transient volatile Node<K,V>[] table;
private transient volatile int sizeCtl;
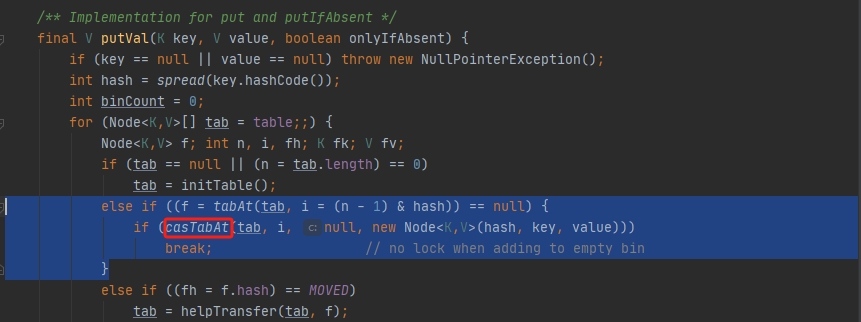
(2)在添加键值的操作,对元素级别进行加锁。若该索引位置不存在元素,则使用乐观锁CAS操作来添加值,而CAS是原子操作,不怕多线程的干扰。
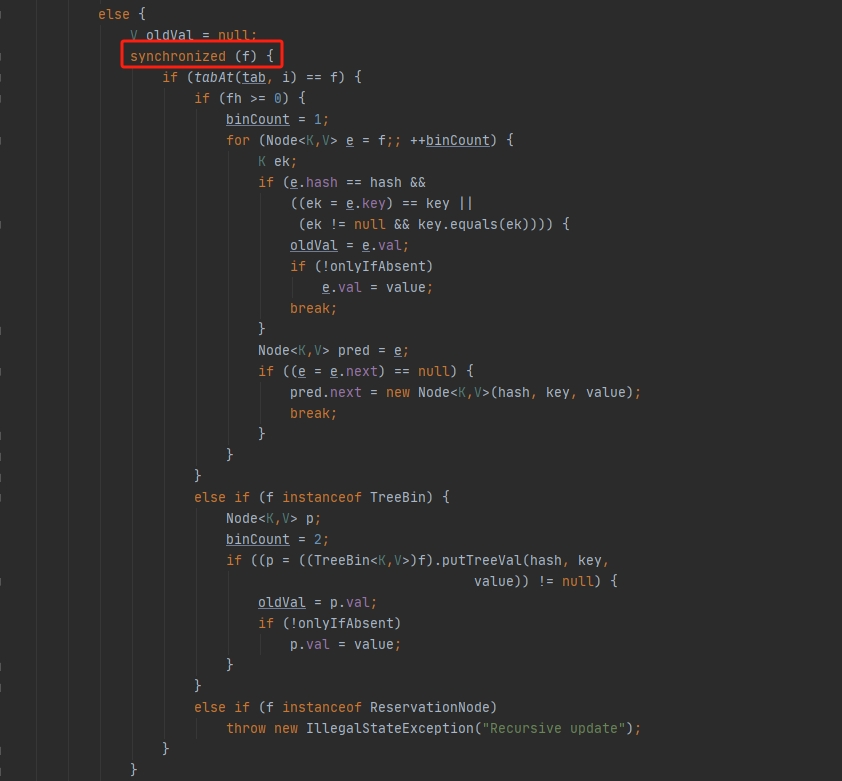
若该索引位置存在元素,则使用synchronized对该索引位置的头节点进行加锁操作,保证整条链表同一时刻只有一个线程在进行操作。
(3)另外在JDK7版本中ConcurrentHashMap的实现和JDK8不同。
JDK7版本的数据结构是大数组Segment + 小数组HashEntry,其中小数组HashEntry的每个元素是一条链表,一个Segment是一个HashEntry数组。对每个Segment即每个分段,使用ReentrantLock进行加锁操作。
可以看到JDK8版本相比JDK版本的实现锁粒度更小,且JDK8版本的链表还可以升级为查询效率高的红黑树,所以JDK7版本的ConcurrentHashMap目前被JDK8版本的代替了。
4.6 HashTable和ConcurrentHashMap区别
面试官:HashTable和ConcurrentHashMap有什么区别吗?
HashTable也是线程安全的Map,不过它不仅对修改操作添加加锁操作,获取操作也进行了加锁。
public synchronized V put(K key, V value)
public synchronized V get(Object key)
而ConcurrentHashMap没有对get进行加锁处理,不适用于强一致性的场景。例如要求获取操作必须严格获取到最新的值,这种强一致性场景则更适合使用HashTable。
另外HashTable和HashMap、ConcurrentHashMap还有以下不同。
- HashTable继承了Dictionary,而HashMap、ConcurrentHashMap继承了AbstractMap
- HashTable初始容量为11,HashMap、ConcurrentHashMap是16
- HashTable扩容为原来的2n+1,HashMap、ConcurrentHashMap是扩容为原来的2n
⭐⭐⭐本文收录在《Java学习/进阶/面试指南》:https://github/JavaSouth
我是南哥,南就南在Get到你的点赞点赞点赞。

创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️

- 点赞
- 收藏
- 关注作者
评论(0)