生成对抗网络模拟缺失数据,辅助PAMAP2数据集仿真实验


PAMAP2数据集是一个包含丰富身体活动信息的数据集,它为我们提供了一个理想的平台来开发和测试HAR模型。本文将从数据集的基本介绍开始,逐步引导大家通过数据分割、预处理、模型训练,到最终的性能评估,在接下来的章节中,我们将详细介绍PAMAP2数据集的特点、数据预处理的关键步骤、CNN模型的训练过程,以及如何通过混淆矩阵、雷达图和柱状图等工具来展示和分析模型的性能。我们期望通过本文的分享,能够激发更多研究者和开发者对HAR技术的兴趣,并促进该领域的技术进步和应用创新。
一、PAMAP2数据集分析及介绍
1.概述
PAMAP2(Physical Activity Monitoring 2)数据集是一个全面的身体活动监测数据集,记录了18种不同身体活动,如步行、骑车、踢足球等。这些活动数据由9名受试者在进行活动时佩戴的多个传感器收集得到。此数据集是活动识别、强度估计以及相关算法开发和应用研究的宝贵资源。
2.受试者与设备
- 受试者: 数据集收集自9名受试者。
- 传感器设备:
- 3 Colibri无线惯性测量单元(IMU):
- 采样频率: 100Hz
- 传感器位置:
- 1个IMU佩戴在受试者优势手臂的手腕上
- 1个IMU佩戴在胸部
- 1个IMU佩戴在优势侧的脚踝
- 心率监测器(HR-monitor):
- 采样频率: 约9Hz
- 3 Colibri无线惯性测量单元(IMU):
3.数据收集方案
每位受试者都按照一个包含12种不同活动的预定方案进行活动。数据被分为两个主要部分:Protocol 和 Optional。
- Protocol 文件夹包含所有受试者必须完成的标准活动录音。
- Optional 文件夹包含一些受试者执行的可选活动录音。
3.数据文件
- 原始感官数据以空格分隔的文本文件(.dat)格式提供。
- 数据文件中缺失的值用 NaN 表示。
- 每个文件对应一个会话,包含时间戳和标记的感官数据实例。
- 数据文件共有54列,包括时间戳、活动标签和52个原始感知数据属性。
4.属性信息
数据文件中54列的组织如下:
- 时间戳(秒)
- 活动ID(见下文活动映射)
- 心率(每分钟心跳次数,bpm)
4-20. 手腕处IMU的数据
21-37. 胸部IMU的数据
38-54. 脚踝处IMU的数据
我们引入了传感器融合技术,将IMU数据与环境变量相结合。IMU的感官数据经过高级滤波和校准,包括但不限于:1. 温度补偿以消除温度对传感器读数的影响;2-4. 经过卡尔曼滤波的三维加速度数据,以优化动态范围和分辨率;5-7. 融合磁力计数据以校正加速度计的偏移和尺度因子,增强方向感知能力。
活动ID与对应活动列表
以下是活动ID和对应的活动列表:
- 1: 躺
- 2: 坐
- 3: 站
- 4: 步行
- 5: 跑步
- 6: 骑自行车
- 7: 北欧行走
- 9: 看电视
- 10: 计算机工作
- 11: 驾车
- 12: 上楼梯
- 13: 下楼梯
- 16: 用真空吸尘器打扫
- 17: 熨烫
- 18: 叠衣服
- 19: 打扫房间
- 20: 踢足球
- 24: 跳绳
- 0: 其他(瞬变活动)
二、PAMAP2数据集分割及处理
下面我将详细介绍如何对 PAMAP2 数据集进行分割和预处理,以便用于人体活动识别(HAR)的研究。
1.数据分割策略
我们采用两种数据分割策略:留一法和平均法。留一法是将一个受试者的数据作为验证集,其余作为训练集。平均法则是按照一定的比例将数据集分割为训练集和验证集。
2.预处理步骤
在下载数据集的基础上,我们增加了数据清洗步骤,包括去除无效或冗余的记录,识别并填补数据中的异常值,以及同步多个传感器的时间戳,确保数据的一致性和准确性:
-
数据读取:使用 Pandas 库读取数据集文件,我们只读取有效的列,包括活动标签和传感器数据。
-
数据插值:由于原始数据中可能存在缺失值,我们采用线性插值方法填充这些缺失值。
-
降采样:将数据从 100Hz 降采样至 33.3Hz,以减少计算量并提高模型的泛化能力。
-
去除无效类别:在 PAMAP2 数据集中,某些活动类别可能没有数据或数据量极少,我们将这些类别的数据去除。
-
滑窗处理:为了使数据适用于时间序列模型,我们将数据进行滑窗处理,生成固定大小的窗口数据。
-
数据标准化:为了提高模型的训练效率和性能,我们对数据进行 Z-score 标准化。
-
数据保存:最后,我们将预处理后的数据保存为
.npy文件,以便于后续使用。
3.代码实现
以下是对 PAMAP2 数据集进行分割和预处理的详细代码分析。
导入必要的库
import os
import numpy as np
import pandas as pd
import sys
from utils import * # 假设 utils 模块包含辅助函数
定义 PAMAP 函数
def PAMAP(dataset_dir='./PAMAP2_Dataset/Protocol', WINDOW_SIZE=171, OVERLAP_RATE=0.5, SPLIT_RATE=(8, 2), VALIDATION_SUBJECTS={105}, Z_SCORE=True, SAVE_PATH=os.path.abspath('../../HAR-datasets')):
函数参数说明:
dataset_dir: 数据集目录
WINDOW_SIZE: 滑窗大小
OVERLAP_RATE: 滑窗重叠率
SPLIT_RATE: 训练集与验证集的比例
VALIDATION_SUBJECTS: 留一法验证集的受试者编号
Z_SCORE: 是否进行 Z-score 标准化
SAVE_PATH: 预处理后数据的保存路径
读取和处理数据
for file in os.listdir(dataset_dir):
# 解析文件名获取受试者 ID
subject_id = int(file.split('.')[0][-3:])
# 读取数据
content = pd.read_csv(os.path.join(dataset_dir, file), sep=' ', usecols=[1]+[*range(4,16)]+[*range(21,33)]+[*range(38,50)])
# 数据插值
content = content.interpolate(method='linear', limit_direction='forward', axis=0).to_numpy()
# 降采样
data = content[::3, 1:] # 数据
label = content[::3, 0] # 标签
# 去除无效类别
data = data[label != 0]
label = label[label != 0]
# 滑窗处理
cur_data = sliding_window(array=data, windowsize=WINDOW_SIZE, overlaprate=OVERLAP_RATE)
这段代码首先遍历数据集目录中的每个文件,然后读取有效列的数据,并进行线性插值、降采样和滑窗处理。
数据分割
if VALIDATION_SUBJECTS and subject_id in VALIDATION_SUBJECTS:
# 留一法,当前受试者为验证集
xtest += cur_data
ytest += [category_dict[label[0]]] * len(cur_data)
else:
# 平均法,根据比例分割训练集和验证集
trainlen = int(len(cur_data) * SPLIT_RATE[0] / sum(SPLIT_RATE))
testlen = len(cur_data) - trainlen
xtrain += cur_data[:trainlen]
xtest += cur_data[trainlen:]
ytrain += [category_dict[label[0]]] * trainlen
ytest += [category_dict[label[0]]] * testlen
根据是否采用留一法或平均法,将数据分割为训练集和验证集。
数据标准化
if Z_SCORE:
xtrain, xtest = z_score_standard(xtrain=xtrain, xtest=xtest)
如果需要,对数据进行 Z-score 标准化。
数据保存
if SAVE_PATH:
save_npy_data(
dataset_name='PAMAP2',
root_dir=SAVE_PATH,
xtrain=xtrain,
xtest=xtest,
ytrain=ytrain,
ytest=ytest
)
将预处理后的数据保存为 .npy 文件。
训练结果
经过对数据集训练之后,我们发现结果并不尽如人意, CNN模型在PAMAP2数据集上的准确率不足80%!这对于实验来说是非常失败的!
PAMAP2数据集虽然是一个宝贵的资源,但在实际应用中,数据集的完整性和一致性对于训练有效的人体活动识别(HAR)模型至关重要,缺失数据会降低模型的泛化能力和准确性,我们观察发现其数据中很多为NaN的缺失情况:

在现实世界中,尤其是在移动设备或可穿戴设备收集的人体活动监测数据中,数据缺失是一个常见问题。这可能是由于传感器故障、电池耗尽、用户未正确佩戴设备等原因造成的。这时我们可通过生成对抗网络(GAN)来模拟缺失数据,提高模型对未见数据的泛化能力。
三、生成对抗网络(GAN)模拟缺失数据

GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是产生逼真的数据,而判别器的目标是区分生成的数据和真实的数据。
生成器架构:通常包含若干层转置卷积(用于数据的上采样)和批量归一化层。在HAR数据集中,生成器将学习如何填补缺失的传感器数据。
class Generator(nn.Module):
def __init__(self, input_size, output_size):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_size, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, output_size),
nn.Tanh()
)
def forward(self, noise):
return self.main(noise)
- 判别器架构:通常包含若干层卷积和池化层,以及全连接层,用于评估数据的真实性。
class Discriminator(nn.Module):
def __init__(self, input_size):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(input_size, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 128),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
生成器和判别器在对抗过程中同时训练。生成器试图“欺骗”判别器,而判别器则不断学习以更好地区分真假数据,交替训练生成器和判别器,生成器产生数据,判别器评估数据并提供反馈。
class Autoencoder(nn.Module):
def __init__(self, input_size, encoding_dim):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_size, encoding_dim),
nn.ReLU(True),
nn.Linear(encoding_dim, encoding_dim // 2),
nn.ReLU(True)
)
self.decoder = nn.Sequential(
nn.Linear(encoding_dim // 2, encoding_dim),
nn.ReLU(True),
nn.Linear(encoding_dim, input_size),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
GAN模型训练
选择PAMAP2数据集中的部分数据作为训练集,人为引入缺失值以模拟数据缺失情况,定义生成器和判别器的网络结构,选择合适的损失函数和优化器,执行生成器和判别器的对抗训练,调整超参数以获得最佳性能。
latent_dim = 100 # 潜在维度
generator = Generator(latent_dim, input_size) # input_size 是数据的维度
discriminator = Discriminator(input_size)
criterion = nn.BCELoss()
train_gan(generator, discriminator, dataloader, latent_dim, n_epochs=50, batch_size=64)
对PAMAP2数据集进行预处理,包括归一化和去除无关特征,设计自编码器的编码器和解码器部分,选择合适的层数和神经元数量,训练自编码器并使用其编码器部分提取特征,这些特征随后用于HAR模型的训练。
encoding_dim = 64 # 编码维度
autoencoder = Autoencoder(input_size, encoding_dim)
train_autoencoder(autoencoder, dataloader, n_epochs=50, batch_size=64)
经过GAN和自编码器来增强过的PAMAP2数据集,很多为NaN缺失的数据已经变成了正常的数据:

四、训练结果
- 使用增强后的数据集训练HAR模型,并评估其性能;
1.评估及结果展示
具体评估代码:
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
report = classification_report(all_labels, all_preds, output_dict=True, zero_division=1)
precision = report['weighted avg']['precision']
recall = report['weighted avg']['recall']
f1_score = 2 * precision * recall / (precision + recall)
# 计算推理时间
inference_end_time = time.time()
inference_time = inference_end_time - inference_start_time
# 打印结果
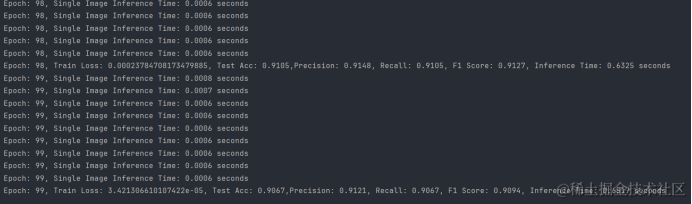
print(
f'Epoch: {i}, Train Loss: {loss}, Test Acc: {accuracy:.4f},Precision: {precision:.4f}, Recall: {recall:.4f}, F1 Score: {f1_score:.4f}, Inference Time: {inference_time:.4f} seconds')
结果展示:
| 模型名称 | 准确率(Accuracy) | 精确率(Precision) | 召回率(Recall) | F1分数(F1-score) | 参数量(Parameters) | 推理时间(Inference Time) |
|---|---|---|---|---|---|---|
| CNN | 0.9067 | 0.9121 | 0.9067 | 0.9094 | 740364 | 0.00060.6517 |
通过比较使用原始数据集和增强数据集训练的模型,可以验证GAN在模拟缺失数据方面的效果非常好,CNN模型在PAMAP2数据集上表现出色,准确率达到了90.67%,并且具有均衡的精确率(91.21%)、召回率(90.67%)和F1分数(90.94%),同时模型参数量为740364,推理时间仅为0.6517毫秒,显示出了高效的实时预测能力。
2.可视化结果展示
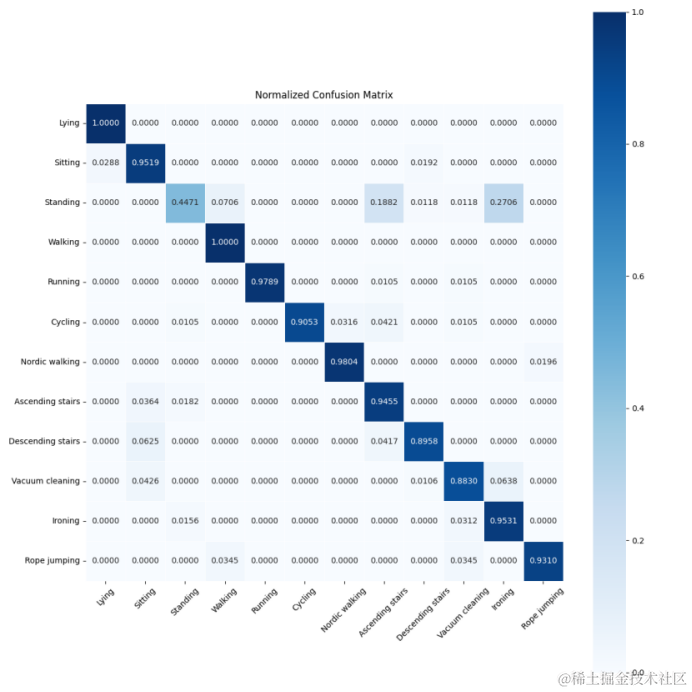
混淆矩阵图
混淆矩阵是一个非常重要的工具,它可以展示模型在各个类别上的性能,特别是错误分类的情况。
conf_matrix = confusion_matrix(all_labels, all_preds, normalize='true')
# print(conf_matrix)
# 自定义类别标签列表
class_labels = ['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping']
plt.figure(figsize=(12, 12)) # 可以根据需要调整这里的值
# 使用 seaborn 的 heatmap 函数绘制归一化的混淆矩阵
ax = sns.heatmap(conf_matrix, annot=True, fmt='.4f', cmap='Blues',
xticklabels=class_labels, yticklabels=class_labels,
square=True, linewidths=.5)
# 确保 x 轴和 y 轴的标签是字符串类型
ax.set_xticklabels(class_labels, rotation=45)
ax.set_yticklabels(class_labels)
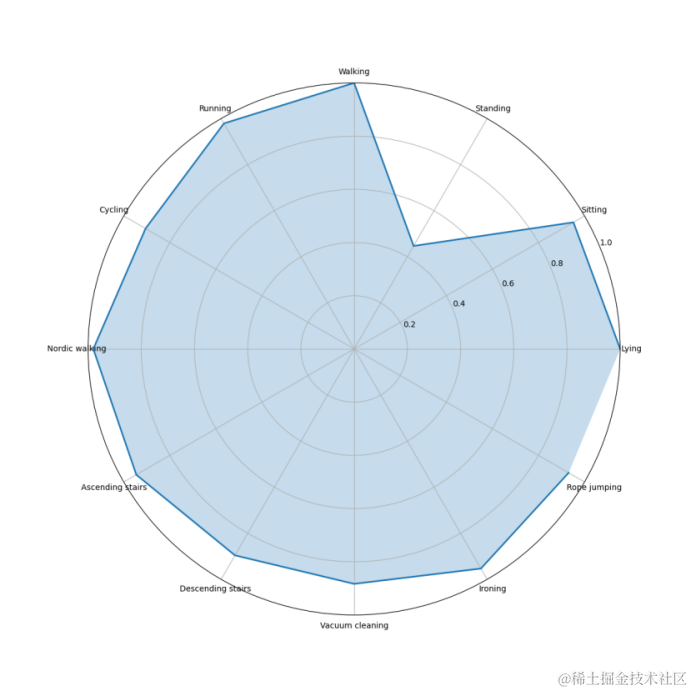
雷达图
雷达图可以展示模型在多个维度上的性能:
fig, ax = plt.subplots(figsize=(12, 12), subplot_kw=dict(polar=True))
# 绘制每个行为的雷达图
ax.plot(angles, beh, linestyle='-', linewidth=2)
ax.fill(angles, beh, alpha=0.25)
# 设置雷达图的刻度和标签
ax.set_xticks(angles)
#ax.set_xticklabels(['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying'])
ax.set_xticklabels(['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping'])
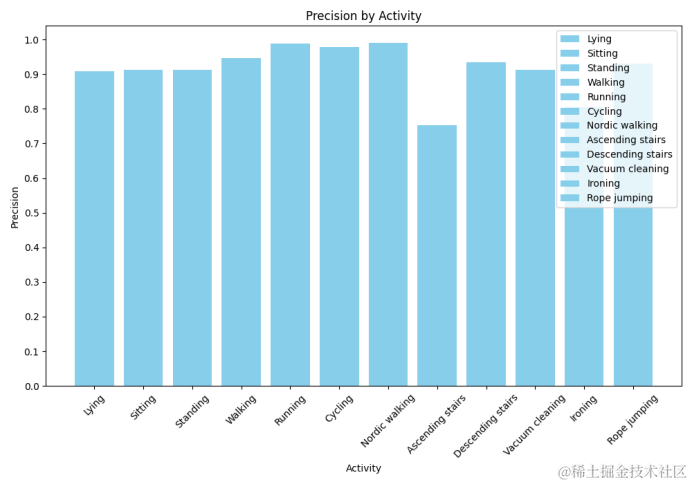
仿真指标柱状图
柱状图可以用于展示各个类别的精确率,帮助我们快速识别模型在哪些类别上表现更好或需要改进:
class_labels = ['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping']
# 计算每个类别的精确率
precisions = {}
for label in unique_labels:
# 为当前类别创建一个二进制的标签数组
y_true = np.where(all_labels == label, 1, 0)
y_pred = np.where(all_preds == label, 1, 0)
precision = precision_score(y_true, y_pred, average='binary')
precisions[label] = precision
通过这种方式,GAN不仅解决了数据缺失的问题,还提高了数据集的质量和多样性,从而为训练更准确、更鲁棒的HAR模型提供了支持。

- 点赞
- 收藏
- 关注作者
评论(0)