【愚公系列】《AIGC辅助软件开发》029-AI辅助解决各种疑难杂症:解决程序性能问题

| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
🚀前言
在软件开发的过程中,程序性能问题常常是开发者面临的重大挑战之一。无论是响应时间过长、资源消耗过高,还是系统崩溃,性能问题不仅影响用户体验,还可能导致业务损失。随着人工智能技术的不断进步,我们有了新的工具和思路来有效诊断和解决这些疑难杂症。
本文将探讨AI如何辅助开发者识别和优化程序性能问题。我们将深入分析AI在性能监测、瓶颈分析和自动化优化中的实际应用,分享一些成功案例,帮助你理解如何利用AI提升软件的效率和稳定性。无论你是初学者还是资深开发者,这篇文章都将为你提供实用的见解和方法,助你在复杂的开发环境中游刃有余。让我们一起探索AI在解决程序性能问题中的强大潜力,开启高效开发的新篇章!
🚀一、解决程序性能问题
有一次,我们遇到了一个实际问题:程序从 Redis 中读取一个存放用户 ID 及其对应属性的 map。我的需求是遍历这些用户属性的 key,获取用户分数属性,并根据分数进行筛选,以得到目标用户群。
假设有 1000 个用户,查询一次 Redis 耗时 0.1ms,总耗时为 (1 + 1000) x 0.1ms,大约为 0.1 秒。对于实时查询来说,这个耗时是可以接受的。然而,随着用户量的增加,耗时也成正比。当用户量达到 10 万时,查询 Redis 的耗时将达到 10 秒,显然不合理。
为了解决这个问题,我决定在程序中添加一个缓存,定时从 Redis 更新数据,而实时查询的请求则落在缓存上。因此,我想请 ChatGPT 帮我写一下相关的程序。我对需求描述得很明确,希望 ChatGPT 能够理解。
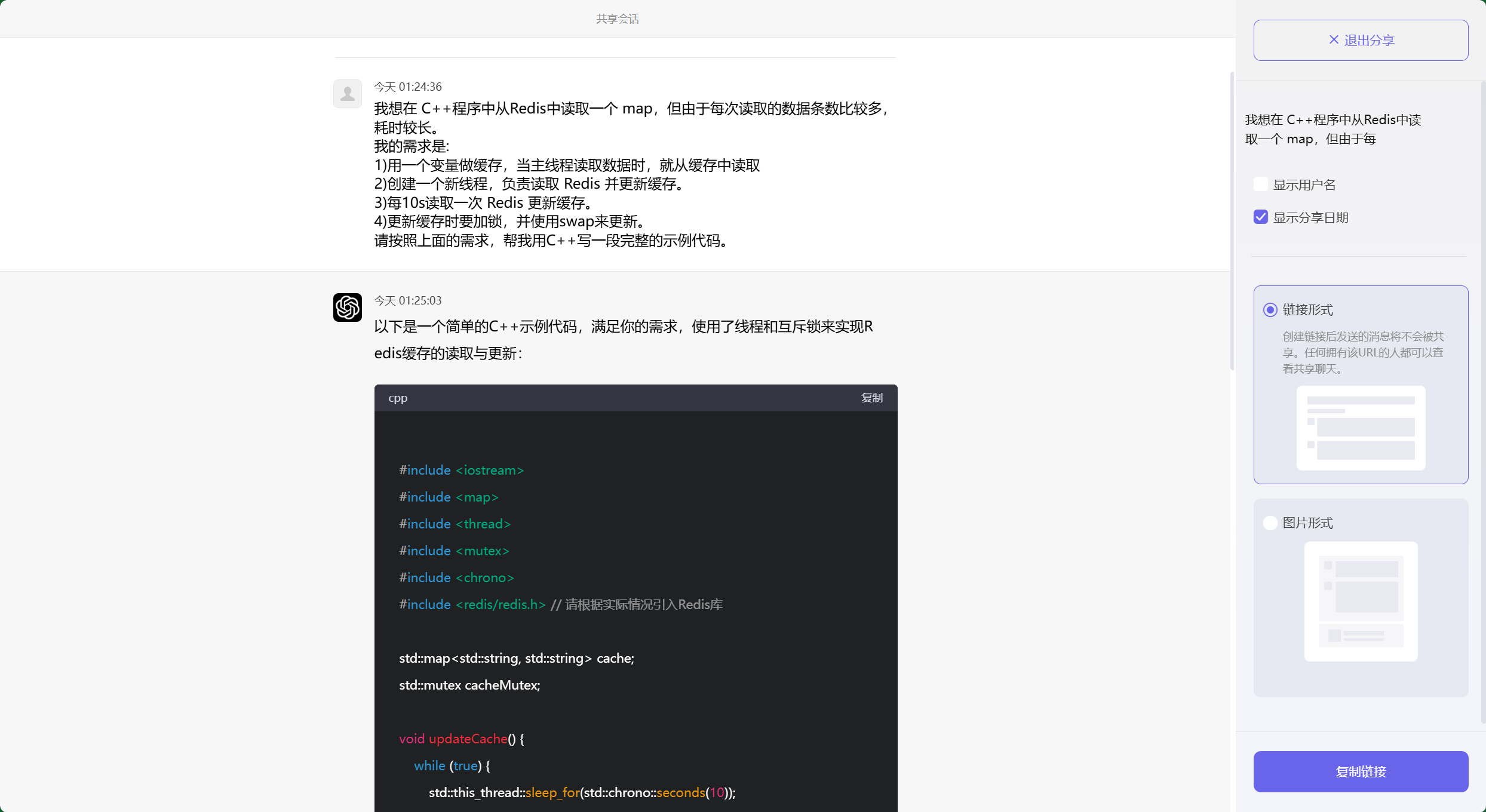
我想在 C++程序中从Redis中读取一个 map,但由于每次读取的数据条数比较多,耗时较长。
我的需求是:
1)用一个变量做缓存,当主线程读取数据时,就从缓存中读取
2)创建一个新线程,负责读取 Redis 并更新缓存。
3)每10s读取一次 Redis 更新缓存。
4)更新缓存时要加锁,并使用swap来更新。
请按照上面的需求,帮我用C++写一段完整的示例代码。
以下是一个简单的C++示例代码,满足你的需求,使用了线程和互斥锁来实现Redis缓存的读取与更新:
```cpp
#include <iostream>
#include <map>
#include <thread>
#include <mutex>
#include <chrono>
#include <redis/redis.h> // 请根据实际情况引入Redis库
std::map<std::string, std::string> cache;
std::mutex cacheMutex;
void updateCache() {
while (true) {
std::this_thread::sleep_for(std::chrono::seconds(10));
std::map<std::string, std::string> newData;
// 从Redis读取数据,假设redisClient是已连接的Redis客户端
// 这里的函数需要替换为实际的读取逻辑
// redisClient.getMap(newData);
{
std::lock_guard<std::mutex> lock(cacheMutex);
cache.swap(newData); // 使用swap更新缓存
}
std::cout << "Cache updated!" << std::endl;
}
}
std::map<std::string, std::string> getCache() {
std::lock_guard<std::mutex> lock(cacheMutex);
return cache; // 返回缓存数据
}
int main() {
// 启动更新线程
std::thread updater(updateCache);
// 主线程逻辑
while (true) {
auto data = getCache();
// 使用缓存数据
// 例如: std::cout << data["key"] << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1)); // 主线程操作频率
}
updater.join(); // 等待更新线程结束
return 0;
}
```cpp
### 注意事项
1. 请确保你正确连接到Redis,并实现`getMap`的实际读取逻辑。
2. 确保引入适合的Redis客户端库,如hiredis。
3. 处理线程安全和资源管理,确保在程序结束时正确释放资源。
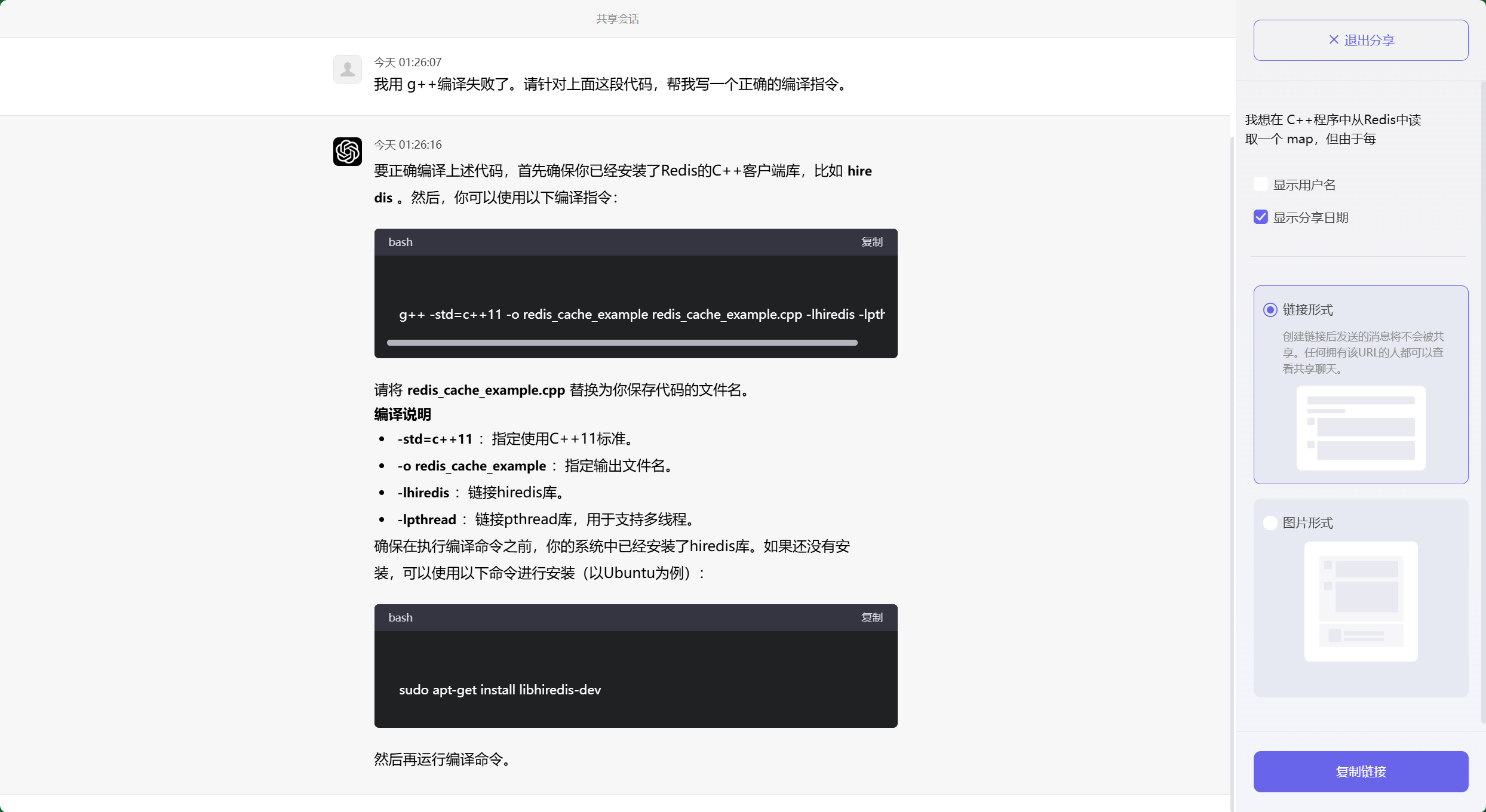
我用 g++编译失败了。请针对上面这段代码,帮我写一个正确的编译指令。
要正确编译上述代码,首先确保你已经安装了Redis的C++客户端库,比如`hiredis`。然后,你可以使用以下编译指令:
```bash
g++ -std=c++11 -o redis_cache_example redis_cache_example.cpp -lhiredis -lpthread
```bash
请将`redis_cache_example.cpp`替换为你保存代码的文件名。
### 编译说明
- `-std=c++11`:指定使用C++11标准。
- `-o redis_cache_example`:指定输出文件名。
- `-lhiredis`:链接hiredis库。
- `-lpthread`:链接pthread库,用于支持多线程。
确保在执行编译命令之前,你的系统中已经安装了hiredis库。如果还没有安装,可以使用以下命令进行安装(以Ubuntu为例):
```bash
sudo apt-get install libhiredis-dev
```bash
然后再运行编译命令。
按照ChatGPT给的编译命令,这次编译成功了。把Redis的地址改为实际地址,重新编译后,运行结果符合预期。相对之前的在搜索引擎中找方法、找答案,用ChatGPT的效率和准确度都高了很多。

- 点赞
- 收藏
- 关注作者
评论(0)