ShuffleNet通道混合轻量级网络的深入介绍和实战

ShuffleNet是一种轻量级的深度学习模型,它在保持MobileNet的Depthwise Separable Convolution(深度可分离卷积)的基础上,引入了通道混合(Channel Shuffle)机制,以进一步提升模型的性能和效率。
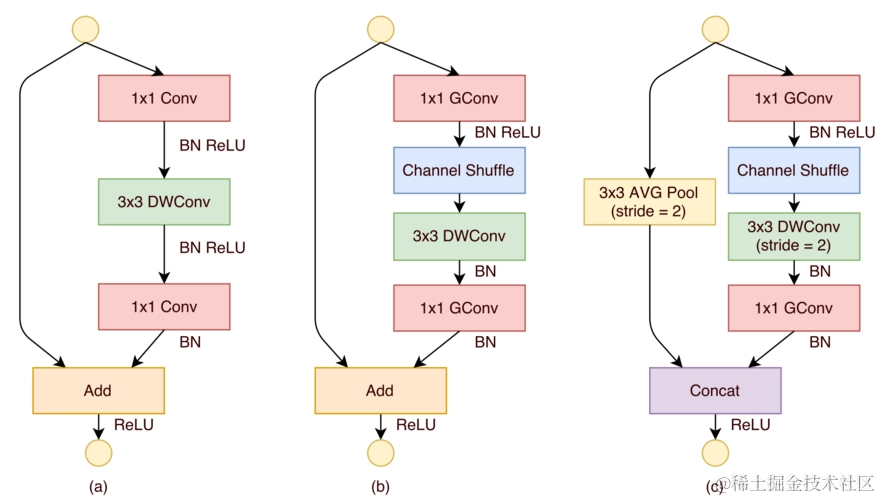
一、ShuffleNet架构详解
1. 通道混合机制(Channel Shuffle)
通道混合是ShuffleNet的核心创新之一。在深度学习模型中,卷积层的输出通道通常在空间上是高度相关的,这限制了模型的表示能力。通道混合通过在组间重新排列通道,增强了通道间的信息流动,从而提高了模型的性能。
2. 深度可分离卷积(Depthwise Separable Convolution)
ShuffleNet继承自MobileNet的深度可分离卷积,它将标准的卷积操作分解为深度卷积(每个输入通道一个滤波器)和逐点卷积(1x1卷积)。这种设计显著减少了模型的参数数量和计算量。
3. 轻量化设计
ShuffleNet专为移动和嵌入式设备设计,通过减少参数和计算量,实现了轻量化。这使得模型可以在计算资源受限的设备上高效运行。
4. 自适应平均池化(Adaptive Average Pooling)
自适应平均池化允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出,这为后续的全连接层提供了便利。
二、ShuffleNet架构
1.网络结构概述
ShuffleNet主要由以下几个部分组成:
- 输入层:接收输入数据。
- 深度可分离卷积层:减少参数数量和计算量。
- 批量归一化层:提高训练效率和稳定性。
- ReLU激活函数:引入非线性。
- 通道混合模块:增强通道间的信息流动。
- 自适应平均池化层:适应不同尺寸的输入。
- 全连接层:输出分类结果。
2.代码实现
2.1 ChannelShuffleModule 详解
ChannelShuffleModule 是 ShuffleNet 中用于增强通道间信息流动的关键组件。它通过将输入张量的通道分成多个组,并在组内进行洗牌,从而实现通道间的信息重组。
初始化方法 __init__
在初始化方法中,我们接收两个参数:channels 和 groups。channels 是输入张量的通道数,而 groups 是我们想要将这些通道分成的组数。我们通过一个断言来确保 channels 可以被 groups 整除,以保证每个组内的通道数是均匀的。
assert channels % groups == 0
接着,我们存储这些值,并计算每个组应有的通道数。
self.channel_per_group = self.channels // self.groups
前向传播方法 forward
在前向传播方法中,我们首先获取输入张量的尺寸,这包括批量大小 batch、通道数 _、序列长度 series 和模态数 modal。
batch, _, series, modal = x.size()
然后,我们将输入张量重新排列成 groups 个组,每组包含 self.channel_per_group 个通道。这一步通过 reshape 方法实现。
x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)
接下来是洗牌操作,这是通过 permute 方法实现的。我们交换 permute 方法中指定维度的顺序,从而在组内打乱通道的顺序。
x = x.permute(0, 2, 1, 3, 4)
最后,我们再次使用 reshape 方法将张量恢复到原始的形状,并将其返回。
x = x.reshape(batch, self.channels, series, modal)
return x
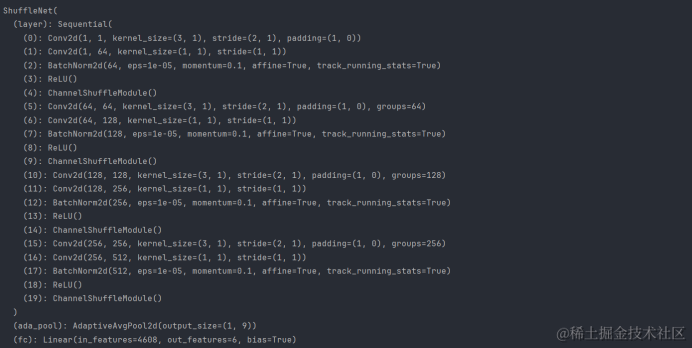
2.2 ShuffleNet 网络结构详解
ShuffleNet 类定义了整个网络的结构,它由多个组件组成,包括卷积层、批量归一化层、ReLU 激活函数、通道混合模块、自适应平均池化层和全连接层。
初始化方法 __init__
在初始化方法中,我们接收三个参数:train_shape 表示训练样本的形状,category 表示类别的数量,kernel_size 表示卷积核的尺寸。
def __init__(self, train_shape, category, kernel_size=3):
我们使用 nn.Sequential 来组织网络中的多个层,包括卷积层、批量归一化层、ReLU 激活函数和通道混合模块。
self.layer = nn.Sequential(
# 第一个卷积层,用于减少输入通道并进行空间维度的下采样
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
# ...
)
这里,我们首先使用一个深度可分离卷积来减少输入通道,并进行空间维度的下采样。然后,我们添加一个1x1的卷积层来扩展通道数,接着是批量归一化层、ReLU 激活函数和通道混合模块。
我们还添加了一个自适应平均池化层,它可以根据输入特征图的实际尺寸动态调整池化尺寸,以确保输出尺寸的一致性。
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
最后,我们添加一个全连接层,它将展平的特征图映射到最终的分类结果。
self.fc = nn.Linear(512*train_shape[-1], category)
前向传播方法 forward
在前向传播方法中,我们首先将输入数据 x 通过 self.layer 中定义的卷积层和通道混合模块。
x = self.layer(x)
然后,我们将结果通过自适应平均池化层,以获得固定尺寸的特征图。
x = self.ada_pool(x)
接下来,我们将特征图展平,以适配全连接层。
x = x.view(x.size(0), -1)
最后,我们通过全连接层 self.fc 得到最终的分类结果,并将其返回。
x = self.fc(x)
return x
完整代码
import torch.nn as nn
class ChannelShuffleModule(nn.Module):
def __init__(self, channels, groups):
super().__init__()
assert channels % groups == 0
self.channels = channels
self.groups = groups
self.channel_per_group = self.channels // self.groups
def forward(self, x):
'''
x.shape: [b, c, series, modal]
'''
batch, _, series, modal = x.size()
x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(batch, self.channels, series, modal)
return x
class ShuffleNet(nn.Module):
def __init__(self, train_shape, category, kernel_size=3):
super(ShuffleNet, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
nn.Conv2d(1, 64, 1, 1, 0),
nn.BatchNorm2d(64),
nn.ReLU(),
ChannelShuffleModule(channels=64, groups=8),
nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),
nn.Conv2d(64, 128, 1, 1, 0),
nn.BatchNorm2d(128),
nn.ReLU(),
ChannelShuffleModule(channels=128, groups=8),
nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),
nn.Conv2d(128, 256, 1, 1, 0),
nn.BatchNorm2d(256),
nn.ReLU(),
ChannelShuffleModule(channels=256, groups=16),
nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),
nn.Conv2d(256, 512, 1, 1, 0),
nn.BatchNorm2d(512),
nn.ReLU(),
ChannelShuffleModule(channels=512, groups=16)
)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512*train_shape[-1], category)
def forward(self, x):
x = self.layer(x)
x = self.ada_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
3.网络结构特点
- 深度可分离卷积:第一个卷积层使用深度可分离卷积,减少参数数量和计算量。
- 通道数的变化:通过第一个1x1卷积层将输入通道数增加到64,为后续的深度可分离卷积提供足够的输入通道。
- 批量归一化和ReLU:在每个卷积层后使用批量归一化和ReLU激活函数,提高训练效率和模型的非线性表达能力。
- 通道混合:在每个深度可分离卷积块后使用通道混合模块,增强通道间的信息流动。
- 自适应平均池化:使用自适应平均池化层将不同尺寸的特征图转换为统一尺寸,适应不同输入尺寸。
- 全连接层:最后的全连接层将展平的特征图映射到最终的分类结果。
ShuffleNet 的设计哲学在于通过轻量化的设计实现高效的特征提取。它通过深度可分离卷积和通道混合技术减少了模型的参数数量和计算量,同时保持了较高的性能。这种设计使得 ShuffleNet 非常适合在计算资源受限的移动和嵌入式设备上部署,用于图像识别和处理任务。
二、ShuffleNet训练UCI-HAR数据集
在上一篇文章中我们已经对UCI-HAR数据集进行了清洗和处理,直接应用数据集进行训练就可以:
- 选择损失函数:交叉熵损失
- 选择优化器:Adam
- 设置学习率和优化器参数
- 训练迭代:在训练集上迭代训练模型,使用验证集进行模型选择和超参数调整。
train_data = TensorDataset(X_train, Y_train)
test_data = TensorDataset(X_test, Y_test)
train_loader = DataLoader(train_data, batch_size=BS, shuffle=True)
test_loader = DataLoader(test_data, batch_size=BS, shuffle=True)
optimizer = torch.optim.AdamW(net.parameters(), lr=LR, weight_decay=0.001)
lr_sch = torch.optim.lr_scheduler.StepLR(optimizer, EP // 3, 0.5)
loss_fn = nn.CrossEntropyLoss()
scaler = GradScaler() # 在训练最开始之前实例化一个GradScaler对象
训练过程及结果:
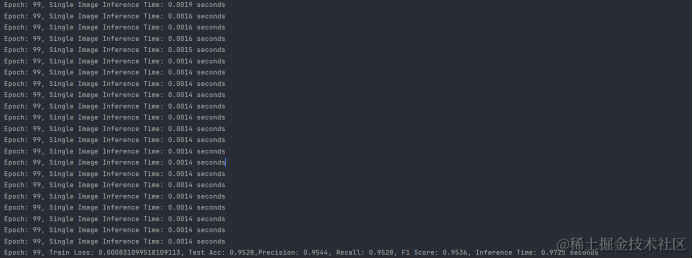
Test Acc: 0.9528,Precision: 0.9544,Recall: 0.9528,F1 Score: 0.9536,Inference Time: 0.9725 seconds
ShuffleNet模型在UCI-HAR数据集上的训练结果表明,该模型具有极高的分类准确率(95.28%),以及出色的精确率(95.44%)、召回率(95.28%)和F1分数(95.36),这些指标均显示出模型在人体活动识别任务上的优秀性能。此外,模型的推理时间仅为0.9725秒,这表明它能够快速进行预测,适合实时应用。总体而言,ShuffleNet在UCI-HAR数据集上的表现非常出色,证明了其在移动和嵌入式设备上进行高效深度学习推理的潜力。

- 点赞
- 收藏
- 关注作者
评论(0)