基于四种网络结构的WISDM数据集仿真及对比:Resnet、LSTM、Shufflenet及CNN

在上节中,我们已经详细介绍了WISDM数据集及如何使用CNN网络训练,得到了六个维度的模型仿真指标及五个维度的可视化分析,那么现在我们将训练模型推广到其他网路结构中去,通过仿真实验来对比一下不同网络之间对于WISDM数据集的训练效果。
一、四种网络的结构及介绍
1.ResNet
残差网络是一种深度学习模型,通过引入“残差学习”的概念来解决深度神经网络训练困难的问题。

ResNet沿用了VGG完整的3 × 3卷积层设计。残差块里首先有2个有相同输出通道数的3 × 3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。
核心思想:
· 残差块(Residual Block) :输入通过一个或多个卷积层后,与输入相加,形成残差。这样做可以使得网络学习到的是输入和输出之间的残差,而不是直接学习输出,从而缓解了梯度消失问题,使得网络可以成功训练更深的模型。

优点:
· 通过残差学习,可以有效地训练更深的网络,提高了模型的性能。
· 网络结构易于拓展,可以构建更复杂的模型。
缺点:
· 虽然缓解了梯度消失问题,但在某些情况下仍然可能遇到梯度爆炸的问题。
· 模型参数较多,需要较大的数据集进行训练。
网络结构:
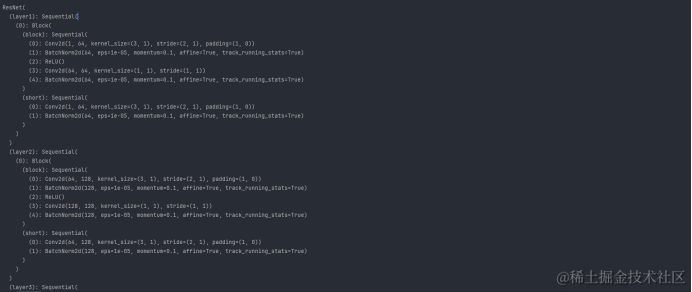
ResNet(
(layer1): Sequential(
(0): Block(
(block): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(short): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
2.长短期记忆网络(LSTM)
长短期记忆网络是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。LSTM内部逻辑结构:

核心思想:
· 门控机制(Gating Mechanism) :LSTM通过引入输入门、遗忘门和输出门来控制信息的流动,解决了传统RNN的短期记忆问题。
· 记忆单元(Memory Cell) :LSTM的核心是记忆单元,它可以添加或移除信息,从而实现长期记忆。
优点:
· 能够处理长期依赖问题,适用于时间序列数据。
· 通过门控机制,可以有效地避免梯度消失和梯度爆炸问题。
缺点:
· 参数数量较多,训练时间较长。
· 门控机制增加了模型的复杂度。
网络结构:
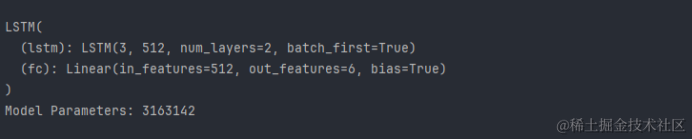
LSTM(
(lstm): LSTM(3, 512, num_layers=2, batch_first=True)
(fc): Linear(in_features=512, out_features=6, bias=True)
)
3.ShuffleNet
ShuffleNet是一种高效的卷积神经网络,它通过使用分组卷积和通道洗牌操作来减少计算量,同时保持了较高的准确率。

核心思想:
· 分组卷积:将输入通道分成多个组,每组独立进行卷积操作,然后合并结果。这样可以减少计算量和参数数量。

· 通道洗牌:在分组卷积后,通过通道洗牌操作重新混合不同组的特征图,以保持特征的多样性。

优点:
· 计算效率高,适用于资源受限的环境。
· 通过通道洗牌操作,可以在减少计算量的同时保持特征的多样性。
缺点:
· 虽然减少了计算量,但在某些复杂任务上可能不如其他网络结构表现出色。
· 分组卷积可能会牺牲一定的模型性能。
网络结构:
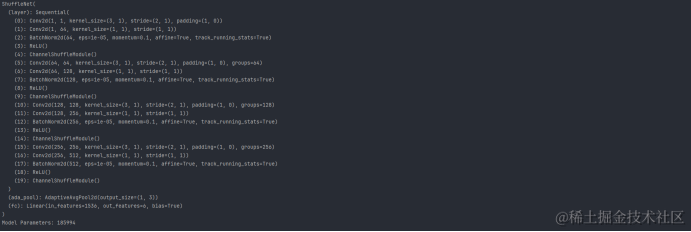
ShuffleNet(
(layer): Sequential(
(0): Conv2d(1, 1, kernel_size=(3, 1), stride=(2, 1), padding=(1, 0))
(1): Conv2d(1, 64, kernel_size=(1, 1), stride=(1, 1))
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(19): ChannelShuffleModule()
)
(ada_pool): AdaptiveAvgPool2d(output_size=(1, 3))
(fc): Linear(in_features=1536, out_features=6, bias=True)
)
4.CNN
这一种网络在上一篇文章中介绍了,这里就不再过多的讲解。
二、具体训练过程
1.Resnet
1.1 残差块(Block)
Block类是一个残差网络的基本构建块,它包含两个卷积层,分别后接批量归一化(BatchNorm)和ReLU激活函数。- 第一个卷积层的卷积核大小为 (3, 1),步长为
(stride, 1),填充为(1, 0)。 - 如果输入和输出的通道数不同,或者步长不为1,残差块会包含一个快捷连接(shortcut),它是一个1x1的卷积层,用于匹配通道数和步长。
class Block(nn.Module):
def __init__(self, inchannel, outchannel, stride):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),
nn.BatchNorm2d(outchannel),
nn.ReLU(),
nn.Conv2d(outchannel, outchannel, 1, 1, 0),
nn.BatchNorm2d(outchannel)
)
self.short = nn.Sequential()
if (inchannel != outchannel or stride != 1):
self.short = nn.Sequential(
nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),
nn.BatchNorm2d(outchannel)
)
1.2 ResNet网络
ResNet类定义了整个网络结构,它由四个残差层(layer1到layer4)组成,每一层由多个残差块组成。- 每一层的输出通道数分别是64, 128, 256, 和 512。每一层的第一个块的步长为2,用于下采样,其余块的步长为1。
- 网络的输入假设具有形状
[b, c, series, modal],其中b是批次大小,c是通道数,series是序列长度,modal是模态数(例如,图像的高度)。 - 网络最后使用一个自适应平均池化层(
AdaptiveAvgPool2d)将特征图的大小调整为(1, train_shape[-1]),然后通过一个全连接层(fc)输出类别预测。
class ResNet(nn.Module):
def __init__(self, train_shape, category):
super().__init__()
self.layer1 = self.make_layers(1, 64, 2, 1)
self.layer2 = self.make_layers(64, 128, 2, 1)
self.layer3 = self.make_layers(128, 256, 2, 1)
self.layer4 = self.make_layers(256, 512, 2, 1)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512*train_shape[-1], category)
1.3 辅助方法
make_layers方法用于创建每个残差层中的多个残差块。它接受输入通道数、输出通道数、步长和块的数量作为参数,并返回一个由这些块组成的序列。
def make_layers(self, inchannel, outchannel, stride, blocks):
layer = [Block(inchannel, outchannel, stride)]
for i in range(1, blocks):
layer.append(Block(outchannel, outchannel, 1))
return nn.Sequential(*layer)
1.4 前向传播(Forward Pass)
- 在
forward方法中,输入数据x会逐层通过残差层,然后通过自适应平均池化层和全连接层,最终输出类别预测。
def forward(self, x):
out = self.block(x) + self.short(x)
return nn.ReLU()(out)
训练过程及结果
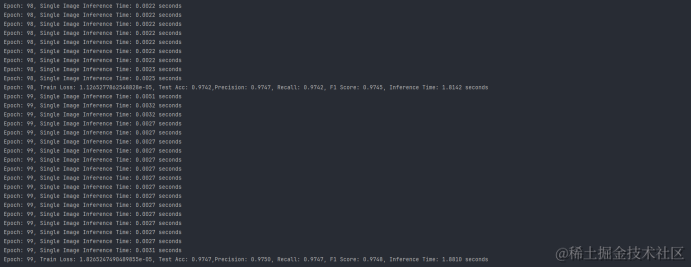
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
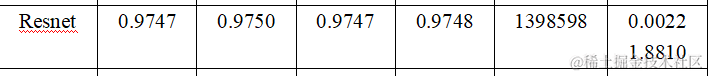
2.LSTM
LSTM网络特别适合于处理和预测时间序列数据,因为它们可以捕捉长期依赖关系,在本次实验中可以发挥出其特点,我们首先使用用LSTM层来处理序列数据,然后使用全连接层来进行分类预测。通过选取序列最后一个时间步的隐藏状态来进行分类,这是处理序列数据的一个常见做法,尤其是当序列长度固定时。
2.1 LSTM类及网络层
我们使用LSTM 类继承自 nn.Module,构造函数 __init__ 接受两个参数:train_shape 和 category。
train_shape是训练数据的形状,这里假设它是一个包含序列长度和模态数的列表或元组。category是类别的数量,即网络输出的维度,用于分类任务。
class LSTM(nn.Module):
def __init__(self, train_shape, category):
super().__init__()
self.lstm = nn.LSTM(train_shape[-1], 512, 2, batch_first=True)
self.fc = nn.Linear(512, category)
其中self.lstm 是LSTM层,其参数如下:
train_shape[-1]是输入特征的维度,即模态数。512是LSTM隐藏层的维度。2表示堆叠两个LSTM层。batch_first=True表示输入和输出的张量的第一个维度是批次大小(batch size)。
self.fc 是一个全连接层,它将LSTM层的输出映射到类别空间。它的输入维度是512(LSTM隐藏层的维度),输出维度是 category。
2.3前向传播(Forward Pass)
forward 方法定义了数据通过网络的正向传播过程。输入 x 的形状假设为 [b, c, series, modal],其中 b 是批次大小,c 是通道数(在这里为1,因为 squeeze(1) 被调用)。
x.squeeze(1) 将通道数维度移除,使得 x 的形状变为 [b, series, modal]。self.lstm(x) 将数据 x 通过LSTM层,输出一个包含隐藏状态和细胞状态的元组。
def forward(self, x):
x, _ = self.lstm(x.squeeze(1))
x = x[:, -1, :]
x = self.fc(x)
return x
训练过程及结果
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
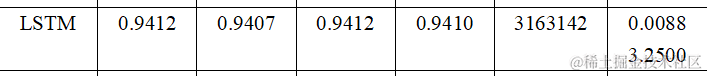
3.ShuffleNet
ShuffleNet通过深度可分离卷积和通道混合技术减少了模型的参数量和计算量,同时保持了较好的性能。这种卷积首先使用 groups 参数将输入通道分组,然后对每个组应用一个轻量级的 (kernel_size, 1) 卷积,接着是一个 1x1 的卷积来组合这些输出。在每个深度可分离卷积后面,紧跟着一个批量归一化层、一个ReLU激活函数和一个通道混合模块。
1. ChannelShuffleModule类
ChannelShuffleModule 是一个通道混合模块,它接收一个张量作为输入,并将其通道按照指定的组数进行重组和混合。在构造函数中,channels 是输入张量的通道数,groups 是要将通道分成的组数。
forward 方法首先将输入张量重塑为 (batch, groups, channel_per_group, series, modal) 的形状,然后通过 permute 重新排列这些组,最后再将其重塑回 (batch, channels, series, modal) 的形状。
class ChannelShuffleModule(nn.Module):
def __init__(self, channels, groups):
super().__init__()
'''
channels: 张量通道数
groups: 通道组数【将channels分为groups组去shuffle】
'''
assert channels % groups == 0
self.channels = channels
self.groups = groups
self.channel_per_group = self.channels // self.groups
2. ShuffleNet类
ShuffleNet 类继承自 nn.Module,定义了ShuffleNet的主体结构。
构造函数 __init__ 接受 train_shape(训练样本的形状)、category(类别数)和 kernel_size(卷积核大小)作为参数。
self.layer 是一个由多个卷积层、批量归一化层、ReLU激活函数和通道混合模块组成的序列。这些层按照顺序执行,逐步增加网络的深度并减少特征图的尺寸。
class ShuffleNet(nn.Module):
def __init__(self, train_shape, category, kernel_size=3):
super(ShuffleNet, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
nn.Conv2d(1, 64, 1, 1, 0),
nn.BatchNorm2d(64),
nn.ReLU(),
ChannelShuffleModule(channels=64, groups=8),
nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),
nn.Conv2d(64, 128, 1, 1, 0),
nn.BatchNorm2d(128),
nn.ReLU(),
ChannelShuffleModule(channels=128, groups=8),
nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),
nn.Conv2d(128, 256, 1, 1, 0),
nn.BatchNorm2d(256),
nn.ReLU(),
ChannelShuffleModule(channels=256, groups=16),
nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),
nn.Conv2d(256, 512, 1, 1, 0),
nn.BatchNorm2d(512),
nn.ReLU(),
ChannelShuffleModule(channels=512, groups=16)
)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512*train_shape[-1], category)
3. 前向传播(Forward Pass)
forward方法定义了数据通过网络的正向传播过程。- 输入
x的形状假设为[b, c, series, modal],其中b是批次大小,c是通道数,series是序列长度,modal是模态数。
首先,x通过self.layer中定义的多个卷积层和通道混合模块。
然后,使用self.ada_pool进行自适应平均池化,将特征图的series维度缩减到1。
接着,通过view方法将池化后的特征图展平,并通过一个全连接层self.fc进行分类。
def forward(self, x):
x = self.layer(x)
x = self.ada_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
训练过程及结果
从训练得到的结果我们可以发现在准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-score)、参数量(Parameters)、推理时间(Inference Time) 六个维度上分别为:
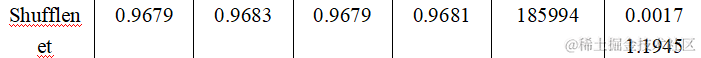
4.Cnn
上篇文章中已经具体分析,这里只给出结果:
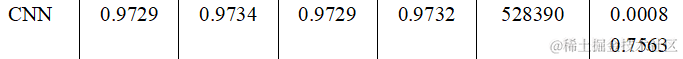
三、结果分析
将得到的四组实验数据写入表格中,进行横向深入对比:
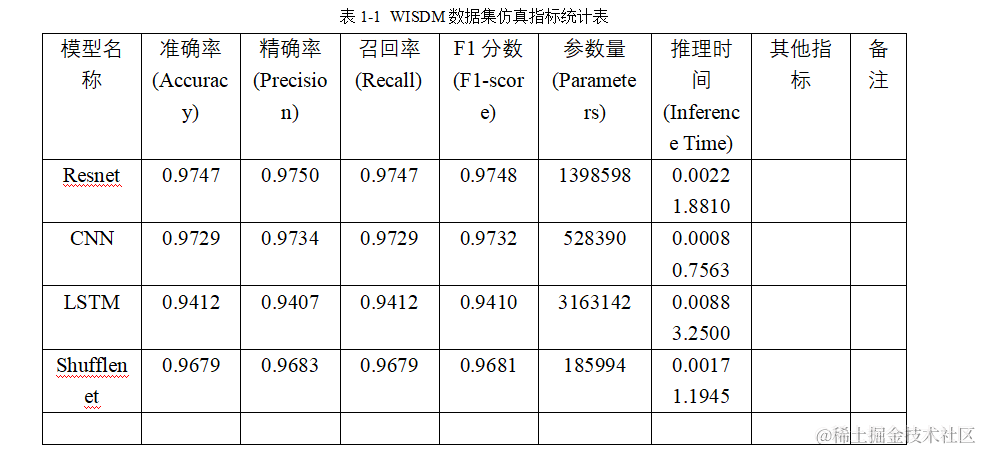
从模型参数量来看,LSTM>Resnet>CNN>Shufflenet。ResNet在性能和效率之间取得了很好的平衡;CNN在保持较高准确率的同时,具有较小的模型尺寸和较快的推理速度;LSTM适合处理时间序列数据,但计算成本较高;ShuffleNet则在资源受限的环境中表现出色,尽管其准确率略低。
以下是我们对各个模型的关键指标更详细的对比:
-
准确率 (Accuracy): 所有模型的准确率都相当高,其中ResNet最高,达到了97.47%。
-
精确率 (Precision): 精确率衡量的是预测为正类别中实际为正类别的比例。ResNet同样在这项指标上表现最佳,为97.50%。
-
召回率 (Recall): 召回率衡量的是所有实际为正类别中被正确预测为正类别的比例。ResNet的召回率也是最高的,为97.47%。
-
F1分数 (F1 Score): F1分数是精确率和召回率的调和平均值,它在两者之间取得平衡。ResNet的F1分数最高,为97.48%。
-
参数量 (Parameter Count): 参数量反映了模型的复杂度。LSTM的参数量最大,为3,163,142,而Shufflenet的参数量最小,为185,994。
-
推理时间 (Inference Time): 推理时间是指模型进行预测所需的时间。CNN的推理时间最短,为0.0008秒,而LSTM的推理时间最长,为0.0088秒。
如果对预测性能有极高的要求,ResNet可能是最佳选择。如果对速度和模型大小有更高的要求,CNN或Shufflenet可能更合适。LSTM由于其参数量最大,可能适用于需要捕获长期依赖关系的任务,但需要更多的计算资源。
深入分析
模型结构设计差异
- ResNet:其残差连接允许网络学习输入的恒等变换以及更复杂的函数。这种设计使得网络能够通过增加层数来提高性能,而不会受到梯度消失的影响。此外,残差连接有助于网络在训练过程中保持特征的一致性,这可能是ResNet在多个评价指标上表现优异的原因之一。
- LSTM:LSTM的门控机制使其能够学习长期依赖关系,这对于时间序列数据特别重要。然而,这种复杂的结构也导致了更多的参数和更高的计算成本。在训练过程中,LSTM可能需要更多的数据和调整来优化其门控单元的状态,这可能是其参数量较大和推理时间较长的原因之一。
- ShuffleNet:ShuffleNet的设计注重计算效率和模型大小。通过分组卷积和通道洗牌,ShuffleNet减少了计算量和参数数量,但这种设计可能牺牲了一些模型的表达能力,尤其是在处理复杂数据时。这可能是ShuffleNet在准确率上略低于其他模型的原因之一。
- CNN:传统的卷积神经网络通常具有较少的参数和较高的计算效率。它们在图像识别任务中表现出色,但在处理时间序列数据或需要捕捉长期依赖关系的任务中可能不如LSTM有效。
模型结构设计对训练和loss的影响
- ResNet:残差连接允许网络层之间直接的信息流动,这有助于缓解深层网络中的梯度消失问题。这种设计使得ResNet在训练时对loss的梯度更加敏感,从而在优化过程中能够更快地收敛。
- LSTM:其门控机制能够有效地捕捉长期依赖关系,但这也意味着在训练过程中需要更加细致地调整超参数,以确保模型不会陷入局部最优解。LSTM可能需要特定的loss函数来更好地利用其记忆单元,需要考虑序列中的不同时间步长对预测的贡献。
- ShuffleNet:通过分组卷积和通道洗牌,ShuffleNet减少了模型的计算复杂度,但可能牺牲了某些特征的表达能力。在训练ShuffleNet时,需要更加关注loss函数的设计,以确保模型能够在有限的参数下学习到有效的特征表示。
- CNN:标准的CNN结构通常具有较好的空间特征提取能力,但在处理时间序列数据时可能不如LSTM有效。在设计loss函数时,需要考虑如何更好地利用CNN的空间特征提取能力,例如通过设计空间敏感的loss函数。
Loss设计对模型性能的影响
- 损失函数的选择:对于不同的模型结构,需要设计不同的损失函数来更好地捕捉任务的关键特性。对于ShuffleNet,可能需要设计一个损失函数,它不仅惩罚预测错误的程度,还鼓励模型学习到更加分散的特征表示。
- 损失函数的权重分配:在多任务学习中,不同任务的loss可能需要不同的权重。在训练LSTM进行序列预测时,可能需要为预测序列的早期和晚期分配不同的权重,以确保模型能够平衡短期和长期预测的准确性。
- 自定义损失函数:在某些特定任务中,可能需要设计自定义的损失函数来更好地适应模型的特性。对于CNN,需要设计一个损失函数,它能够鼓励模型学习到更加鲁棒的特征表示,以应对图像数据中的噪声和变化。
注意:具体的代码实现和模型细节可以联系作者获取,以便进一步的研究和应用。本文首发于稀土掘金,未经允许禁止转发和二次创作,侵权必究。

- 点赞
- 收藏
- 关注作者
评论(0)