【Elasticsearch系列一】Elasticsearch安装

【摘要】 1.注意事项注意事项:内存不能太小,否则会启动失败JDK 版本需要对应,es7 需要 Java 11不能以 root 用户启动 2.安装 java11#java版本查看java -version#下载安装yum install java-11-openjdk.x86_64 -y#查看位置ls -rl $(which java)#修改环境变量vim /etc/profileexport JA...
1.注意事项
注意事项:
- 内存不能太小,否则会启动失败
- JDK 版本需要对应,es7 需要 Java 11
- 不能以 root 用户启动
2.安装 java11
#java版本查看
java -version
#下载安装
yum install java-11-openjdk.x86_64 -y
#查看位置
ls -rl $(which java)
#修改环境变量
vim /etc/profile
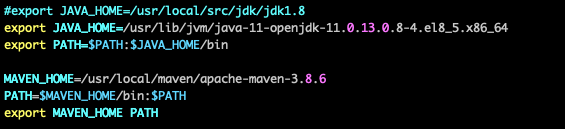
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.0.1.al8.x86_64
export PATH=$PATH:$JAVA_HOME/bin
#使生效
source /etc/profile
3.下载 es
#解压到到/usr/local/目录下
tar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz -C /usr/local/
#进入解压后的目录
cd /usr/local/elasticsearch-7.12.0
#创建文件和日志目录(日志文件已经存在)
mkdir data
修改配置:
vim config/elasticsearch.yml
cluster.name: my-application #集群名称
node.name: node-1 #节点名称
path.data: /usr/local/elasticsearch-7.12.0/data
path.logs: /usr/local/elasticsearch-7.12.0/logs
#设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
http.port: 9200 #端口
#设置在集群中的所有节点名称,这个节点名称就是之前所修改的,目前是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]
4.增加用户
#创建用户
useradd elasticsearch
#用户加密码(elastic-search1)
passwd elasticsearch
5.赋权限
#修改目录权限至新增的elasticsearch用户
chown -R elasticsearch:elasticsearch /usr/local/elasticsearch-7.12.0
6.修改系统配置
- 修改系统中允许应用最多创建多少文件等的限制权限。Linux 默认来说,一般限制应用最多创建的文件是 65535 个。但是 ES 至少需要 65536 的文件创建权限。
- 修改系统中允许用户启动的进程开启多少个线程。默认的 Linux 限制 root 用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启 1024 个线程。必须修改限制数为 4096+。因为 ES 至少需要 4096 的线程池预备。ES 在 5.x 版本之后,强制要求在 linux 中不能使用 root 用户启动 ES 进程。所以必须使用其他用户启动 ES 进程才可以。
- Linux 低版本内核为线程分配的内存是 128K。4.x 版本的内核分配的内存更大。如果虚拟机的内存是 1G,最多只能开启 3000+个线程数。至少为虚拟机分配 1.5G 以上的内存。
#修改系统配置
vim /etc/security/limits.conf
# 追加到末尾即可
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
elasticsearch soft nproc 4096
elasticsearch hard nproc 4096
7.内存权限
vim /etc/sysctl.conf
vm.max_map_count=262144
#使配置生效
/sbin/sysctl -p
8.启动
#切换用户
su elasticsearch
#进入目录
cd /usr/local/elasticsearch-7.12.0
#启动
./bin/elasticsearch
./bin/elasticsearch -d
#启动Kibana
nohup sh /usr/local/kibana/bin/kibana &
9.验证
#查询端口信息
netstat -ntlp | grep -E '9200|5601'
#linux访问
curl 127.0.0.1:9200
#浏览器访问
http://47.119.162.180:9200
#查询集群状态
http://47.119.162.180:9200/cluster/health
解释:Status:集群状态。Green所有分片可用。Yellow所有主分片可用。Red主分片不可用,集群不可用。
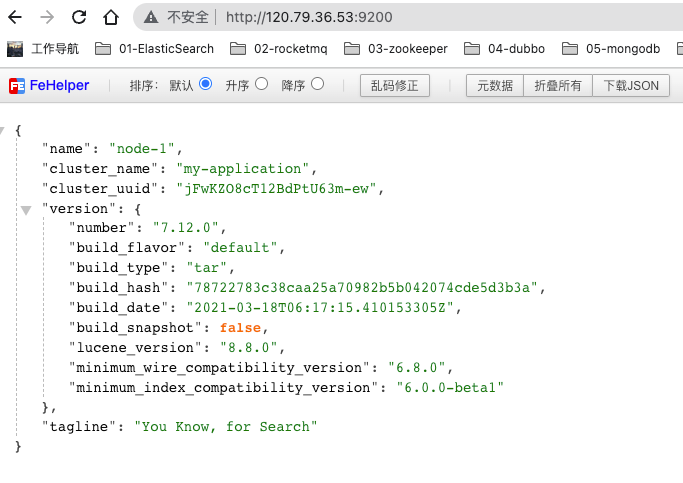
{
"name": "node-1",
"cluster_name": "my-application",
"cluster_uuid": "jFwKZO8cT12BdPtU63m-ew",
"version": {
"number": "7.12.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date": "2021-03-18T06:17:15.410153305Z",
"build_snapshot": false,
"lucene_version": "8.8.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
Elasticsearch是一个基于Apache Lucene的开源搜索引擎,它提供了分布式、多租户的搜索服务及数据分析功能。Elasticsearch的架构是面向文档的,它将所有数据存储为JSON文档,每个文档都有唯一的ID,而且处理结构化和非结构化数据非常容易。它使用诸如分片、副本、修订等技术来确保存储方案具备可靠性、高可用性和可伸缩性。Elasticsearch采用基于RESTful API(HTTP)的接口,提供非常完善的查询语句;同时还支持实时字段计算、聚合分析、搜索建议、中文分词以及Geo查询等复杂操作。
Elasticsearch的主要优点包括:
- 分布式设计:Elasticsearch天然支持分布式,可以很容易地横向扩容,处理PB级结构化或非结构化数据。
- 高效的搜索能力:Elasticsearch提供了全文搜索功能,支持模糊查询、前缀查询、通配符查询等,并且具有强大的聚合分析功能。
- 快速的查询速度:Elasticsearch的底层使用Lucene作为搜索引擎,并在此之上做了多重优化,保证了用户对数据查询的需求。
- 易用性:Elasticsearch提供了简单的RESTful API,天生的兼容多语言开发,上手容易,开箱即用。
- 丰富的生态圈:Elasticsearch有丰富的插件和工具,如Logstash、Kibana、Beats等,形成了强大的Elastic Stack生态。
Elasticsearch的使用场景包括:
- 应用搜索:为网站或应用程序提供搜索功能,如电商、社交媒体等。
- 日志记录和日志分析:收集、存储和分析服务器日志、应用日志等。
- 基础设施监控:监控服务器、网络设备等基础设施的性能指标。
- 安全分析:分析安全日志,进行入侵检测和威胁分析。
- 地理位置数据分析:处理地理空间数据,提供地理位置搜索服务。
- 商业智能:对商业数据进行分析,提供决策支持。
Elasticsearch的引入主要是为了应对大数据环境下的海量数据检索和实时分析需求,它通过分布式架构和高效的索引机制,提供了快速的搜索和分析能力。然而,Elasticsearch也存在一些潜在风险,如响应时间问题和任务恢复延迟等,需要通过优化配置和维护来降低这些风险的影响。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)