性能工具之 JMeter 常用组件介绍(五)

一、Jmeter中参数取值
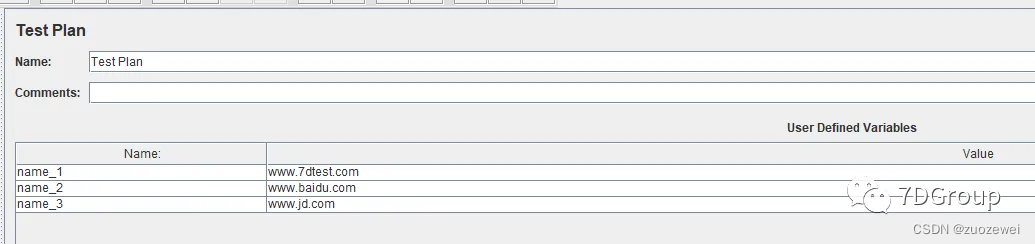
1、Test Plan中添加变量
Test Plan中设置好变量名,变量名可以在任意的位置引用,比如说在线程组中直接用${变量名}方式引用变量,步骤如下:
1、添加线程组
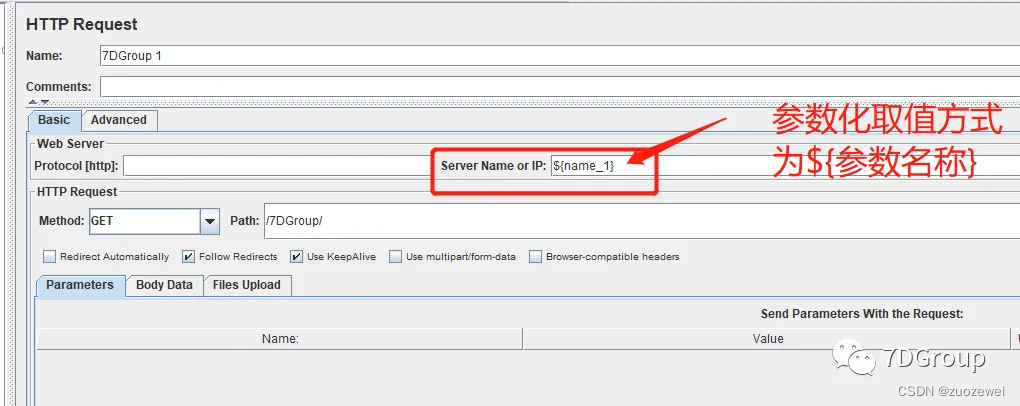
2、添加请求
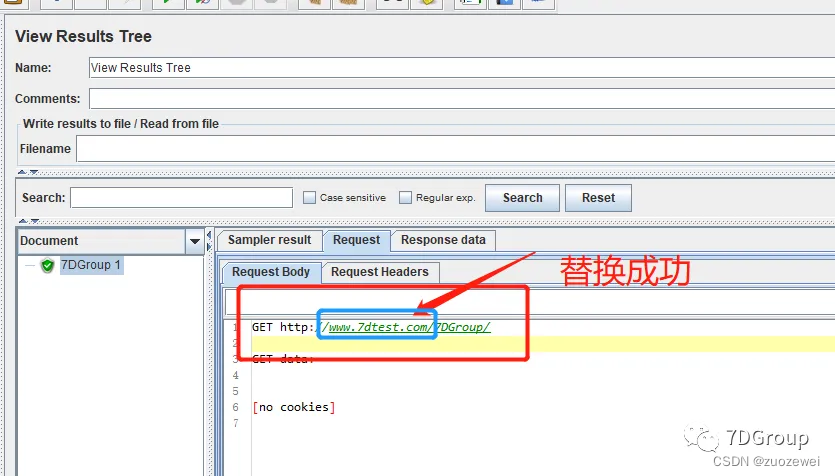
3、添加结果查看树
2、User Defined Variables
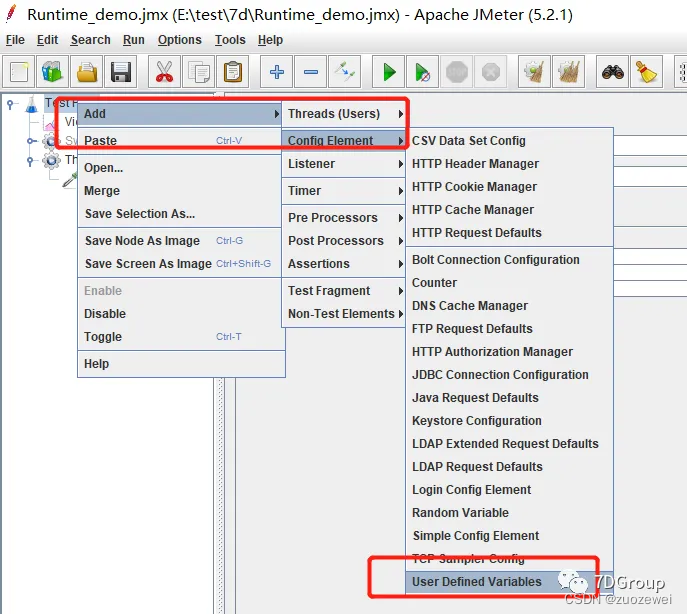
注意:User Defined Variables定义的变量和Test Plan中定义的变量一样,不管这个组件在任何位置,在整个test plan中都可以引用这些变量。
1、添加线程组
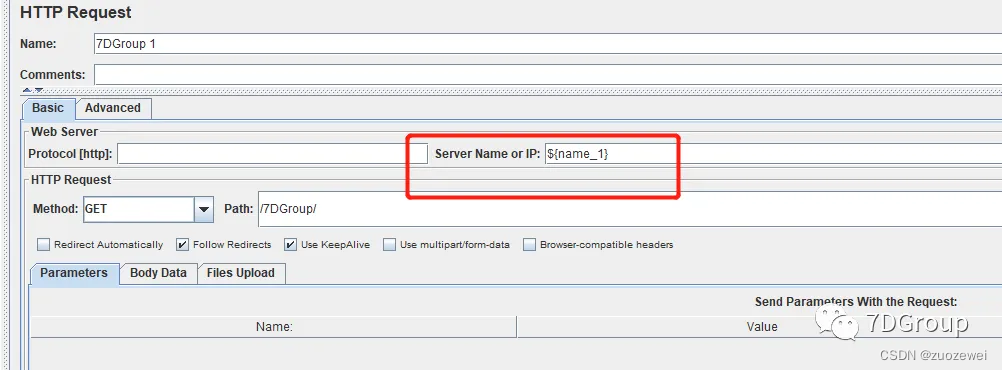
2、添加请求User Defined Variables

3、添加请求
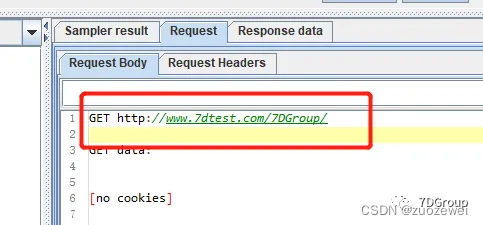
4、添加结果查看树
二、Jmeter中CSV Data Set Config
在做性能测试或者接口测试中,文件参数化最常用的工具摸过如此,咱们这次聊一聊这个工具怎么使用
-
作用:从文件中逐行读取数据,按指定的分隔符分割,赋给指定的变量。适合处理大量数据的情况
-
参数说明:
- Filename:文件路径。可以是相对路径也可以是绝对路径。可以是.txt文件也可以是.csv文件
File encoding:文件编码,默认问ANSI,其它编码根据实际情况配置Variables Names(comma-delimited):变量名,表示将每一列赋值给一个变量,有多个列时同逗号分隔,后续通过${}引用Ignore first line:忽略首行Delimiter(use "\t" for tab):分隔符,默认为逗号Allow quoted data?:数据是否带引号,默认为false,如果数据中有引号(双引号)的话就会把数据连同引号一起赋值给变量,也就是原封不动的取值;如果为true的话就会把引号去掉,将引号中的值赋给标量。Recycle on EOF?:遇到文件结束符是否再次循环,默认为True,也就是继续从文件开头取值Stop thread on EOF?:遇到文件结束符是否结束线程,默认为False也就是不停止。注意:当【Recycle on EOF?】设置为True时,此项设置无效;当【Recycle on EOF?】设置为False,此项也设置为False,那么到达文件最后在引用变量就会变为<EOF>Sharing mode:共享模式。默认为all threads,还支持current thread group / current thread /edit
共享模式总结:
all treatds:csv文件中的数据是共享的,不管是线程数还是循环次数,都会触发接口请求参数来使用csv文件中不同行的变量数据current thread group:在线程组内,线程数和循环次数都会触发接口请求参数变化current thread:循环了数据就会变化,线程数不能决定更新csv文件中的数据,循环次数才可以;
以下简单的演示:
1、添加线程组
2、添加请求CSV Data Set Config
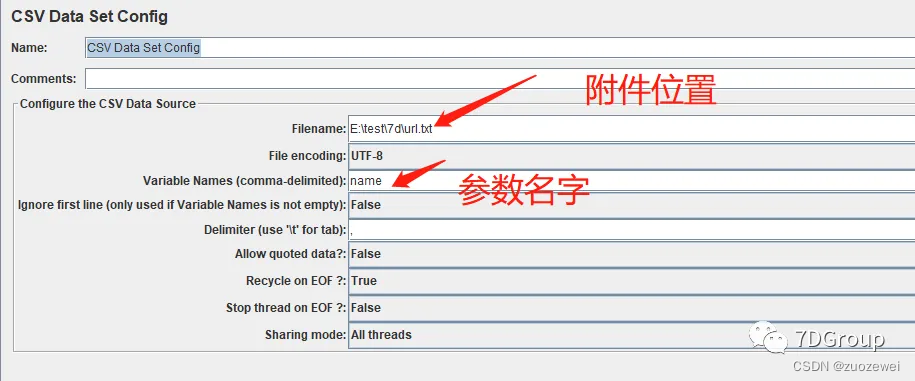
附件内容:
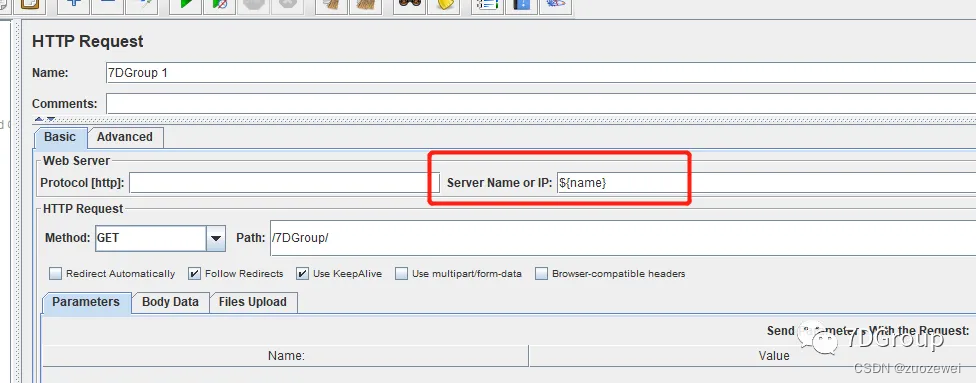
3、添加http request请求
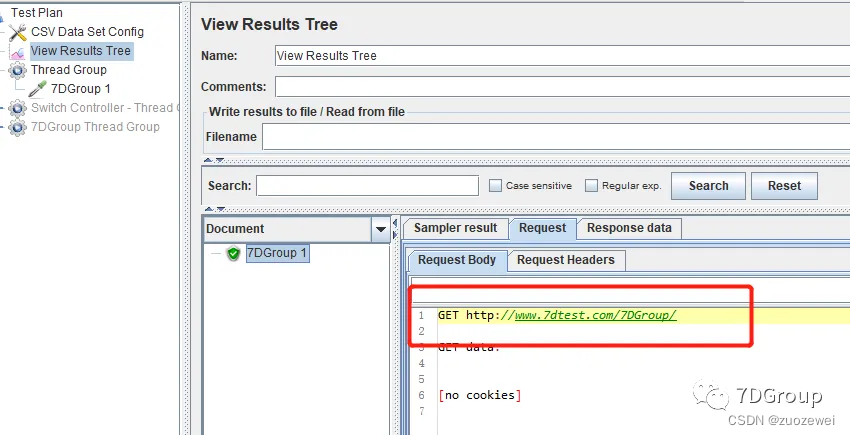
4、添加结果查看树
三、Timer:定时器
- Constant Timer 固定定时器
- Uniform Random Timer 均匀随机定时器
- Constant Throughput Timer 固定吞吐量定时器
- Gaussian Random Timer 高斯随机定时器
- JSR223 Timer JSR223定时器
- Poisson Random Timer 泊松随机定时器
- Synchronizing Timer 同步定时器
- BeanShell Timer BeanShell脚本编写定时器
- Precise Throughput Timer 精准吞吐量定时器
1、Constant Timer 固定定时器
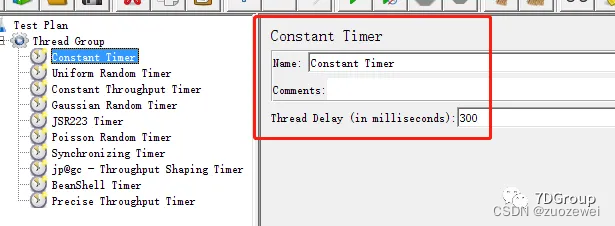
作用:通过ThreadDelay设定每个线程请求之前的等待时间(单位为毫秒)。
2、Uniform Random Timer 均匀随机定时器
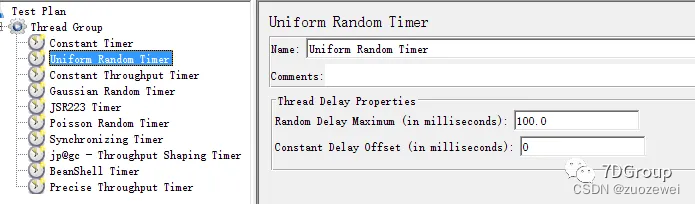
作用:它产生的延迟时间是个随机值,而各随机值出现的概率均等。总的延迟时间等于一个随机延迟时间加上一个固定延迟时间,用户可以设置随机延迟时间和固定延迟时间。
3、Constant Throughput Timer 固定吞吐量定时器
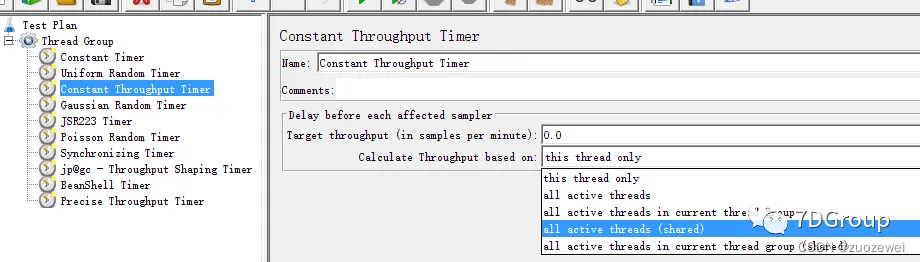
作用: 按指定的吞吐量执行,以每分钟为单位。计算吞吐量依据是最后一次线程的执行时延。
Target throughput(in samples per minute):目标吞吐量。注意这里是每分钟发送的请求数,可以选择作用的线程:当前线程、当前线程组、所有线程组等,具体含义如下:
this thread only: 设置每个线程的吞吐量。。all active threads in current thread group:吞吐量被分摊到当前线程组所有的活动线程上。每个线程将根据上次运行时间延迟。all active threads:吞吐量被分配到所有线程组的所有活动线程的总吞吐量。每个线程将根据上次运行时间延迟。在这种情况下,每个线程组需要一个具有相同设置的固定吞吐量定时器。(不常用)all active threads in current thread group (shared):同上,但是每个线程是根据组中的线程的上一次运行时间来延迟。相当于线程组组内排队。(不常用)all active threads (shared):同上,但每个线程是根据线程的上次运行时间来延迟。相当于让所有线程组整体排队。(不常用)
4、Gaussian Random Timer 高斯随机定时器
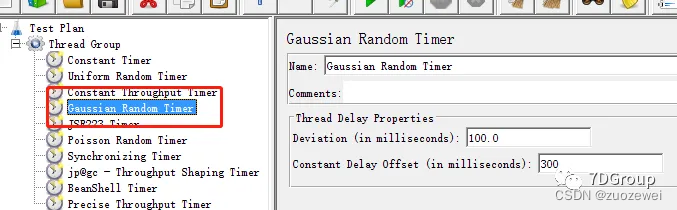
作用:每个线程的延迟时间是符合标准正态分布的随机时间停顿,那么使用这个定时器:
5、JSR223 Timer JSR223定时器
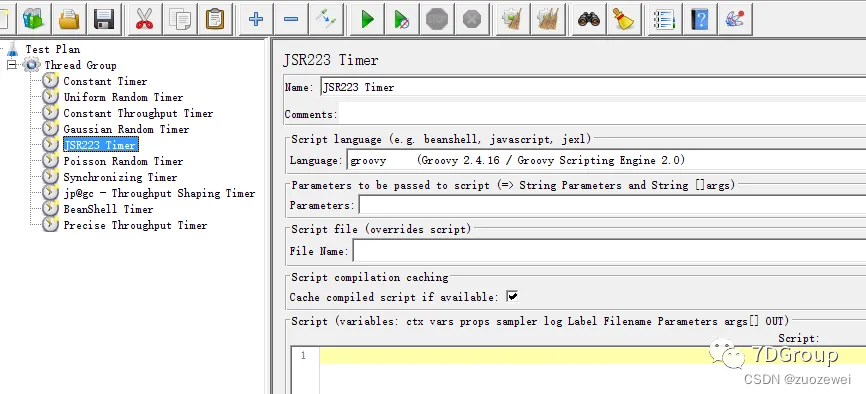
JSR223计时器可以使用JSR223脚本语言生成延迟;
参考帮助文档:
https://jmeter.apache.org/usermanual/component_reference.html#JSR223_Timer
6、Poisson Random Timer 泊松随机定时器
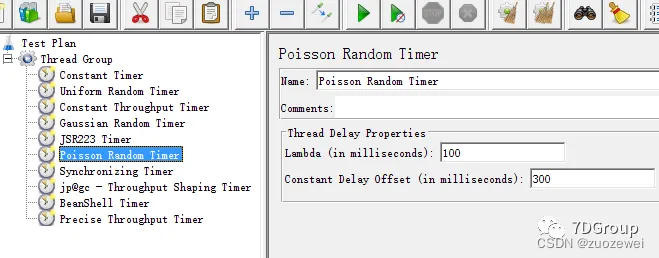
这个定时器在每个线程请求之前按随机的时间停顿,总的延迟就是泊松分布值和偏移值之和。
上面表示暂停时间会分布在100到400毫秒之间:
- (1)Lambda(in milliseconds):兰布达值
- (2)
Constant Delay Offset(in milliseconds):暂停的毫秒数减去随机延迟的毫秒数
7、Synchronizing Timer 同步定时器
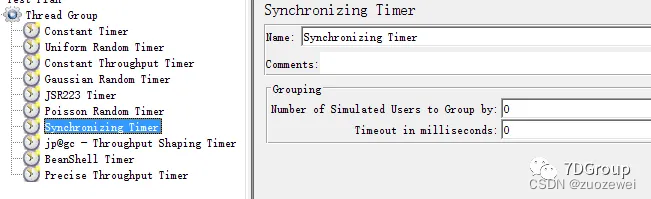
作用:用来设置集合点,其作用是:阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力
- (1)
Number of Simulated Users to Group by:模拟用户的数量,即指定同时释放的线程数数量,若设置为0,等于设置为线程组中的线程数量; - (2)
Timeout in milliseconds:超时时间,即超时多少毫秒后同时释放指定的线程数;如果设置为0,该定时器将会等待线程数达到了设置的线程数才释放,若没有达到设置的线程数会一直死等。如果大于0,那么如果超过Timeout inmilliseconds中设置的最大等待时间后还没达到设置的线程数,Timer将不再等待,释放已到达的线程。默认为0
同步定时器(Synchronizing Timer)的超时时间设置要求:
8、BeanShell Timer BeanShell脚本编写定时器
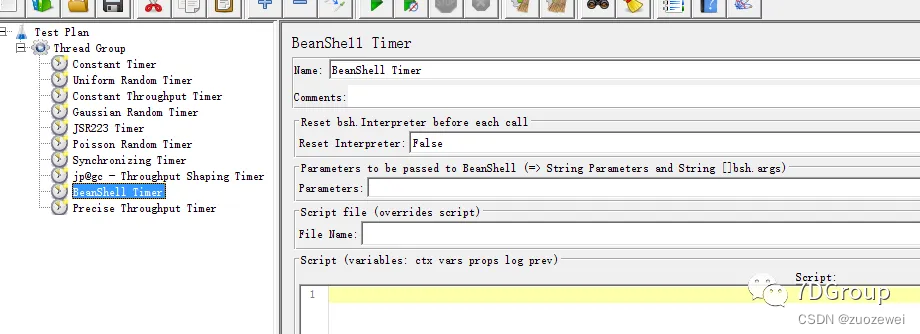
参数说明:
Reset Interpreter:每次迭代是否重置解析器,默认为false;在长时间运行的脚本中建议设置为true- Parameters:BeanShell脚本的入参。入参可以是单个变量;也可以是数组,若是字符串数组,两个元素之间用空格隔开;也可以是常量。
File Name:BeanShell脚本可以从脚本文件中读取。- Script:在Script区直接写BeanShell脚本。
简单写一demo增加一个sleep等待一分钟:
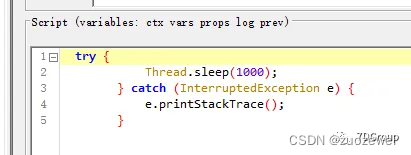
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
增加一个Java Request请求,并且增加时间验证是否按照自己设定的定时运行脚本:
Java Request ${__time(yyyy-MM-dd HH:mm:ss:SSS,)}

增加结果查看树:
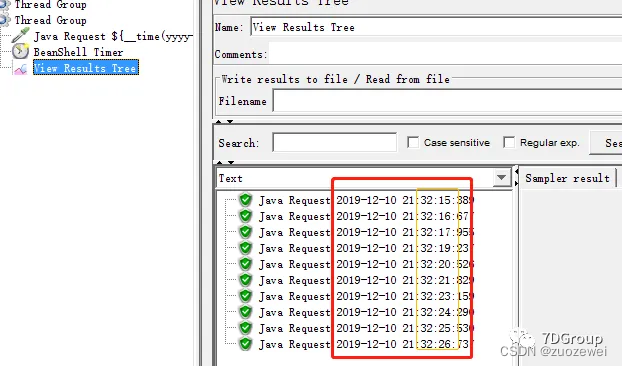
结果显示按之前设置的每个1秒钟运行
9、Precise Throughput Timer 精准吞吐量定时器
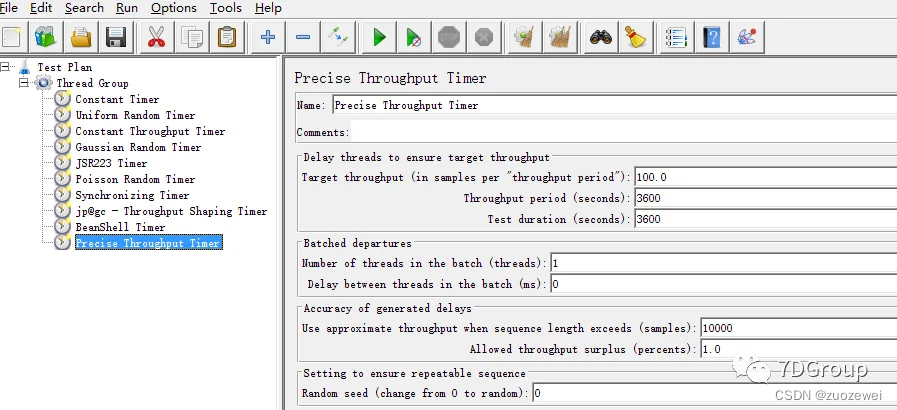
Target Throught:目标吞吐量Throught Period:表示在多长时间内发送Target Throught指定的请求数(以秒为单位)Test Druation:指定测试运行时间(以秒为单位)Number of threads in the bath:用来设置集合点,等到指定个数的请求后并发执行其它参数默认即可。

- 点赞
- 收藏
- 关注作者
评论(0)