并发编程进阶-01

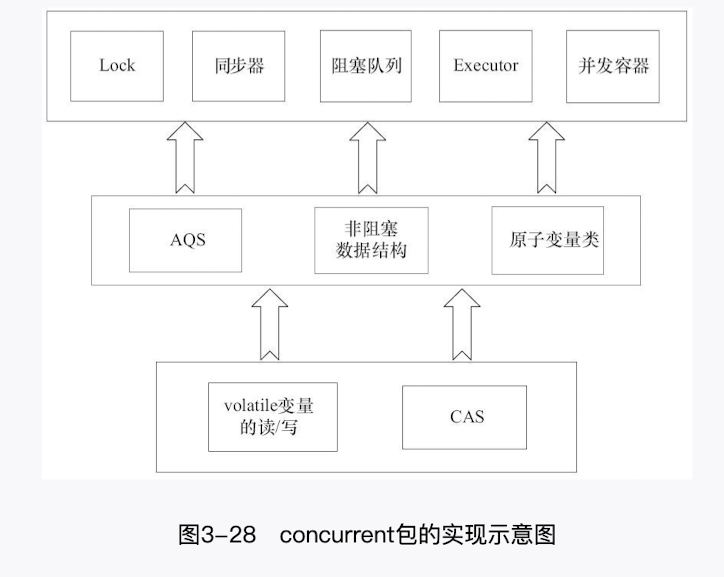
1.JUC 包概述?
juc 是 java.util.concurrent 的简称,为了支持高并发任务,在编程时可以有效减少竞争条件和死锁线程.
juc 主要包含 5 大工具包
| 工具包 | 描述 |
|---|---|
| locks | - ReentrantLock: 独占锁,同一时间只能被一个线程获取,支持重入性。 - ReentrantReadWriteLock: 读写锁,ReadLock 是共享锁,WriteLock 是独占锁。 - LockSupport: 提供阻塞和解除阻塞线程的功能,不会导致死锁。 |
| executor | - Executor: 线程池的顶级接口。 - ExecutorService: 扩展了 Executor 接口,用于管理线程池的生命周期和任务执行。 - ScheduledExecutorService: 继承自 ExecutorService,支持周期性执行任务。 - ScheduledThreadPoolExecutor: ScheduledExecutorService 的实现类,用于周期性调度任务。 |
| tools | - CountDownLatch: 一个同步辅助类,等待其他线程执行完任务后再执行。 - CyclicBarrier: 另一个同步辅助类,当所有线程都到达某个公共的屏障点时,才继续执行。 - Semaphore: 计数信号量,本质上是共享锁,通过 acquire() 获取信号量许可,通过 release() 释放许可。 |
| atomic | - AtomicBoolean: 原子操作类,提供原子更新 boolean 值的功能。 - AtomicInteger: 原子操作类,提供原子更新 int 值的功能。 |
| collections | - HashMap: 线程不安全的哈希表实现,对应的高并发类是 ConcurrentHashMap。 - ArrayList: 线程不安全的动态数组实现,对应的高并发类是 CopyOnWriteArrayList。 - HashSet: 线程不安全的哈希集合实现,对应的高并发类是 CopyOnWriteArraySet。 - Queue: 线程安全的队列实现,对应的高并发类是 ConcurrentLinkedQueue。 - SimpleDateFormat: 线程不安全的日期格式化类,对应的高并发类是 FastDateFormat 或者 DateFormatUtils。 |
请注意,JUC(Java.util.concurrent)是 Java 中处理并发编程的工具包,包含了大量用于处理多线程编程的类和接口。以上列出的工具包和类仅是其中的一部分,还有很多其他有用的工具供开发者使用。
2.并发编程逻辑
底层依赖—>中层工具—>具体实现
- 首先,声明共享变量为 volatile。
- 然后,使用 CAS 的原子条件更新来实现线程之间的同步。
- 同时,配合以 volatile 的读/写和 CAS 所具有的 volatile 读和写的内存语义来实现线程之间的通信。
3.为什么用 ConcurrentHashMap?
ConcurrentHashmap 存在的原因:
- HashMap 线程不安全的 map,多线程环境下 put 操作会出现死循环.会导致 Entry 链表变为环形结构.next 节点用不为空,就成了死循环获取 Entry.
- HashTable 效率低下
- ConcurrentHashMap 锁分段(jdk1.7)可以提高并发访问效率
ConcurrentHashmap 和 HashMap 区别:
-
HashMap 是非线程安全的,而 HashTable 和 ConcurrentHashMap 都是线程安全的
-
HashMap 的 key 和 value 均可以为 null;而 HashTable 和 ConcurrentHashMap 的 key 和 value 均不可以为 null
-
HashTable 和 ConcurrentHashMap 的区别:保证线程安全的方式不同,HashTable 是使用 synchronized,ConcurrentHashMap 在 jdk1.8 中使用 cas 和 synchronized
4.ConcurrentHashMap 数据结构?
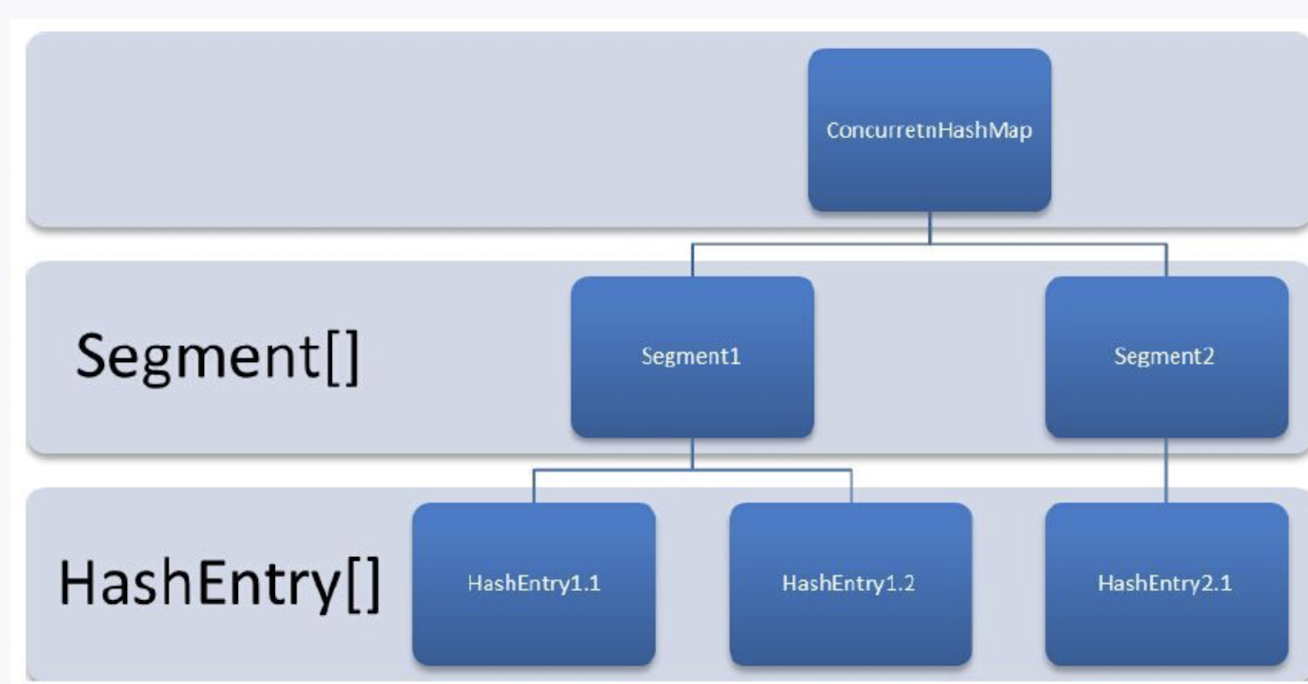
jdk1.8 之前的数据结构:
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结合组成。默认有 16 个区段。Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组。Seqment 的结构和 HashMap 类似,是一种数组和链表结构。一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得与它对应的 Segment 锁.
不同线程操作不同的 Segment 就不会出现安全问题,性能上大提升.在 jdk1.8 之前,多线程操作同一个 Segment 不能并发,在 jdk1.8 优化了.
jdk1.8 之后的数据结构:
改进:没有 Segment 区段了,和 HashMap 一致了,数组+链表+红黑树 +乐观锁 + synchronized
ConcurrentHashMap 数据结构与 1.8 中的 HashMap 保持一致,均为数组+链表+红黑树,是通过乐观锁+Synchronized 来保证线程安全的.当多线程并发向同一个散列桶添加元素时。
若散列桶为空:此时触发乐观锁机制,线程会获取到桶中的版本号,在添加节点之前,判断线程中获取的版本号与桶中实际存在的版本号是否一致,若一致,则添加成功,若不一致,则让线程自旋。
若散列桶不为空:此时使用 synchronized 来保证线程安全,先访问到的线程会给桶中的头节点加锁,从而保证线程安全。
5.ConcurrentHashMap 初始化?
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
这段代码是用来创建一个 ConcurrentHashMap(并发哈希表)实例的构造函数。让我们逐步解释它:
- 参数检查:
- 首先,代码对传入的参数进行检查,确保它们符合创建
ConcurrentHashMap的要求。 loadFactor:必须大于 0.0,因为它表示内部哈希表进行扩容的加载因子阈值。initialCapacity:必须大于等于 0,代表哈希表的初始容量。concurrencyLevel:必须大于 0,表示预估的并发更新线程数。
- 首先,代码对传入的参数进行检查,确保它们符合创建
- 设置初始容量:
- 接下来,构造函数检查
initialCapacity是否小于concurrencyLevel。如果是,它会将initialCapacity设置为concurrencyLevel。 - 这个步骤确保哈希表至少有和预估的并发更新线程数一样多的桶(存储空间),以提高并发性能。
- 接下来,构造函数检查
- 计算大小:
- 构造函数接着根据给定的
initialCapacity和loadFactor计算内部哈希表的大小。 size的计算为1.0 + initialCapacity / loadFactor。- 这个大小用来确定哈希表的容量。
- 构造函数接着根据给定的
- 确定哈希表的容量:
- 接下来,构造函数使用计算得到的
size来决定哈希表的容量。 - 如果计算得到的
size大于等于MAXIMUM_CAPACITY,则将哈希表的容量设置为MAXIMUM_CAPACITY。 - 否则,会调用
tableSizeFor()方法,根据size计算出最接近且大于size的 2 的幂次方值,并将其作为哈希表的容量。
- 接下来,构造函数使用计算得到的
- 设置
sizeCtl:- 最后,将计算得到的容量
cap赋值给sizeCtl,这是ConcurrentHashMap内部用于管理表的控制参数。
- 最后,将计算得到的容量
总体来说,这段代码创建了一个 ConcurrentHashMap 的实例,并对传入的参数进行了合法性检查,然后根据参数计算了哈希表的大小和容量。这些控制参数的设置有助于确保并发性能和哈希表的正确功能。
6.sizeCtl 的作用
sizeCtl 是 ConcurrentHashMap 内部的一个控制参数,用于控制哈希表的状态和并发扩容操作。
具体来说,sizeCtl 的作用如下:
- 控制表的初始化大小:
- 在构造函数中,我们可以看到
sizeCtl被用来设置哈希表的初始容量,它是在构造函数末尾通过this.sizeCtl = cap;进行赋值的。 cap是根据传入的initialCapacity和loadFactor计算得到的哈希表容量。
- 在构造函数中,我们可以看到
- 控制表的扩容:
sizeCtl还用于控制哈希表的并发扩容操作。当哈希表需要进行扩容时,会使用sizeCtl的值来判断当前是否有其他线程正在进行扩容操作,或者标记当前线程正在进行扩容。- sizeCtl 的值可以是负数或者正数,具体的含义如下:
- 负数:表示当前有线程正在进行扩容操作,而绝对值表示正在扩容的线程数减 1(因为扩容线程计数是从-1 开始的)。
- 0:表示当前没有进行扩容操作,且可以接受新的扩容请求。
- 正数:表示当前没有进行扩容操作,但是已经有线程发起了扩容请求,该正数值表示发起扩容请求的线程数。
- 控制并发性:
sizeCtl的负值和正值都表示当前存在扩容请求或正在扩容的情况,因此在进行扩容操作时,其他线程的访问可能需要等待。- 这样的设计可以防止多个线程同时触发扩容操作,从而避免对哈希表的结构进行重复扩容,提高了并发性能。
总结起来,sizeCtl 是 ConcurrentHashMap 内部用于控制哈希表状态、扩容操作和并发性的重要参数。它在哈希表的初始化和扩容过程中起着关键的作用,保障了 ConcurrentHashMap 的正确性和高并发性能。
7.定位数据?
首先需要找到 segment,通过散列算法对 hashCode 进行再散列找到 segment,主要是为了分布更加均匀,否则都在一个 segment 上,起不到分段锁的作用.散列函数如下,为了让高位参与到运算中.
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift)&segmentMask];
}
hash >>> segmentShift)&segmentMask // 定位Segment所使用的hash 算法
int index= hash &(tab.length -1); // 定位HashEntry所使用的hash算法
8.ConcurrentHashMap 的 get 操作?
transient volatile int count;
volatile V value;
public V get(Object key) {
int hash =hash(key.hashCode());//先进行一次再散列
return segmentFor(hash).get(key,hash);//再通过散列值定位到segment
//最后通过散列获取到元素
}
get 操作的高效之处在于整个 get 过程不需要加锁。原因是它的 get 方法里将要使用的共享变量都定义成 volatile 类型
9.ConcurrentHashMap 的 put 操作?
put 方法必须加锁,需要做 2 件事
- 是否扩容
- 查找插入位置
在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后将原数组里的元素进行再散列后插入到新的数组里。为了高效, ConcurrentHashMap 不会对整个容器进行扩容,而只对某个 segment 进行扩容(jdk1.7)。数据量相对较小,注意和 HashMap 的区别.
10.说说 ConcurrentLinkedQueue?
线程安全的非阻塞队列 ConcurrentLinkedQueue
offer(E e) 方法是 ConcurrentLinkedQueue 提供的一个添加元素的方法。它用于将指定的元素插入队列的末尾(尾部)。
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {//p是最后一个节点
if (p.casNext(null, newNode)) {//通过cas替换节点p的next节点
if (p != t) // 是否通过cas替换tail的指向
casTail(t, newNode); // Failure is OK.
return true;
}
}
else if (p == q)//tail未初始化
p = (t != (t = tail)) ? t : head;
else
p = (p != t && t != (t = tail)) ? t : q;
}
}
详细解释 ConcurrentLinkedQueue 的 offer(E e) 方法:
- 参数:
E ee是要插入队列的元素。
- 功能:
offer(E e)方法将元素e插入队列的末尾(尾部)。- 如果队列当前没有被其他线程占用或被修改,则插入操作是立即执行的。
- 如果队列当前正在被其他线程进行修改(比如扩容等操作),那么插入操作可能会被阻塞,直到队列可用为止。
- 返回值:
true:如果元素e成功插入队列。false:如果由于某种原因(例如队列已满)未能插入元素e。
- 注意事项:
ConcurrentLinkedQueue是一个无界队列,不会限制队列的容量,因此offer(E e)永远不会阻塞,除非由于资源限制或其他异常情况导致的插入失败。- 由于
ConcurrentLinkedQueue是无界的,因此在不断地添加元素的情况下,它可能会占用大量的内存。
总的来说,ConcurrentLinkedQueue 的 offer(E e) 方法用于向队列的末尾添加元素 e,它是一个非阻塞方法,可以在高并发环境下安全使用。需要注意的是,由于它是无界队列,添加元素时应当注意不要无限制地添加,以免占用过多的内存。
poll()方法是ConcurrentLinkedQueue的一个核心方法,用于从队列头部获取并移除元素。下面详细解释poll()方法的工作原理:
poll()方法用于从队列头部获取并移除元素。如果队列为空,poll()方法会返回null。poll()方法是一个非阻塞方法,它不会阻塞线程,即使队列为空。- 在执行
poll()方法时,它会检查队列头部是否有元素。 - 若队列为空(即没有任何元素),
poll()方法会立即返回null。 - 若队列非空,
poll()方法会移除队列头部的元素,并将其返回。
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
if (p != h)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
11.BlockingQueue 的实现原理?
| 方法 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() |
阻塞队列使用 Lock+多个 Condition 实现的 FIFO 的队列.多线程环境下安全的,如果队列满了,放入元素的线程会被阻塞,如果队列空了,取元素的线程会被阻塞.具体原理一起看源代码。通过 Condition 来实现队列元素的阻塞,是空还是满.
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
12.JDK 中阻塞队列
JDK 7 提供了 7 个阻塞队列,如下。
| 队列类型 | 描述 |
|---|---|
| ArrayBlockingQueue | 一个由数组结构组成的有界阻塞队列。它按照 FIFO(先进先出)原则对元素进行排序。在队列已满时,插入操作将被阻塞,直到队列有空间可用。在队列为空时,获取操作也将被阻塞,直到队列中有元素可获取。 |
| LinkedBlockingQueue | 一个由链表结构组成的有界阻塞队列。也按照 FIFO 原则对元素进行排序。与 ArrayBlockingQueue 不同的是,它没有固定的容量上限,可以在构造时指定容量,如果未指定则默认为 Integer.MAX_VALUE。当队列为空或已满时,插入和获取操作将被阻塞。 |
| PriorityBlockingQueue | 一个支持优先级排序的无界阻塞队列。元素需要实现 Comparable 接口或者通过构造时提供的 Comparator 进行比较。无论队列是否为空,获取操作都会立即返回最高优先级的元素。当队列为空时,获取操作将被阻塞。 |
| DelayQueue | 一个使用优先级队列实现的无界阻塞队列。其中的元素必须实现 Delayed 接口,只有在其指定的延迟时间到达后才能被获取。元素按照延迟时间的长短进行排序。当队列为空时,获取操作将被阻塞。 |
| SynchronousQueue | 一个不存储元素的阻塞队列。每个插入操作必须等待一个相应的移除操作,反之亦然。它在并发场景中用于线程间直接传递数据,是一种特殊的同步工具。 |
| LinkedTransferQueue | 一个由链表结构组成的无界阻塞队列。它在 LinkedBlockingQueue 的基础上添加了更高级的传输操作。除了基本的 FIFO 排序外,它还支持直接传输元素给消费者。在传输操作前后,获取操作和插入操作都可以被阻塞。 |
| LinkedBlockingDeque | 一个由链表结构组成的双向阻塞队列。可以在队列的两端进行插入和获取操作。它也可以在构造时指定容量,如果未指定则默认为 Integer.MAX_VALUE。当队列为空或已满时,插入和获取操作将被阻塞。 |
以上表格中列出的队列类型是 Java 中并发包(java.util.concurrent)中提供的主要队列实现。每种队列类型在不同的场景中都有特定的用途,开发者可以根据具体需求选择合适的队列来实现线程安全的数据传递和任务调度。

- 点赞
- 收藏
- 关注作者
评论(0)