【MySQL】索引概念解析

1.什么是索引?
MySQL中的索引是一种数据结构,用于帮助MySQL数据库管理系统快速查询数据。索引的主要目的是提高数据检索的速度,减少数据库系统需要扫描的数据量。
优点:
- 索引可以极大的提高数据检索效率,降低数据库IO成本
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 通过索引列对数据进行排序,降低数据排序的成本,减少CPU的消耗
缺点:
- 创建索引需要消耗物理空间。对于大型数据库,索引可能会占用相当大的磁盘空间。
- 创建索引和维护索引需要消耗时间,降低表的更新效率。对表中数据进行增删改操作时,那么索引也需要动态的修改,会降低 SQL 执行效率。
适用场景:
- 具有唯一性约束的字段,比如商品编码,可以适用唯一性索引
- 频繁使用的列,如主键、外键
- 经常用于WHERE查询条件的字段,如果查询条件不是⼀个字段,可以建⽴联合索引。
- 用于GROUP BY或ORDER BY中的字段,由于索引基于B+树实现,会自动维护数据的有序性,降低数据排序的成本。
不适用场景:
-
WHERE、GROUP BY或ORDER BY用不到的字段,索引的作用是快速定位,用不到的话会额外占用空间
-
存在大量重复元素的字段,如性别,无论怎么搜索可能只会得到一半的数据。
-
表数据太少的时候,无需创建索引。
-
频繁修改的列,当对表中数据进行增删改操作时,由于索引需要维护B+树的有序性,会频繁的创建索引,影响数据库的性能。
2.索引结构选型
B+ 树非常适合作为数据库索引结构,特别是在处理大量数据的场景下,能够提供高效的查询、插入和删除操作,并且支持范围查询和顺序扫描。这些特性使得 B+ 树成为 MySQL 等数据库系统中首选的索引数据结构。
下面将针对不同的数据结构进行分析,以说明B+树为何能在众多数据结构中脱颖而出。
Hash表
MySQL 的 InnoDB 存储引擎不直接支持常规哈希索引,但有一种自适应哈希索引(Adaptive Hash Index)。这种索引结合了 B+ 树和哈希索引的特点,适应实际数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+ 树结构,存储多个键值对,减少了哈希冲突,提高了效率。
MySQL 没有采用哈希索引作为主要索引结构,主要因为哈希索引不支持顺序和范围查询。此外,每次 IO 只能取一个值,限制了查询性能。
二叉查找树(BST)
二叉查找树的性能非常依赖于它的平衡程度。
- 平衡时:查询时间复杂度为 O(log N),效率较高。
- 不平衡时:最坏情况下退化为线性链表,查询效率降至 O(N)。
AVL树
AVL 树是一种高度平衡二叉树,保证任何节点的左右子树高度之差不超过 1,查找、插入和删除的时间复杂度均为 O(log N)。AVL 树通过四种旋转操作(LL、RR、LR、RL)保持平衡,但频繁的旋转操作增加了计算开销,降低了数据库写操作的性能。
每个 AVL 树节点仅存储一个数据,每次磁盘 IO 只能读取一个节点的数据,需要多次 IO 查询多个节点的数据,影响了性能。
红黑树
红黑树是一种自平衡二叉查找树,通过颜色变换和旋转操作保持平衡,具有以下特点:
- 每个节点非红即黑;
- 根节点总是黑色;
- 每个叶子节点是黑色的空节点(NIL);
- 红色节点的子节点必须是黑色;
- 从任意节点到叶子节点的每条路径包含相同数量的黑色节点。
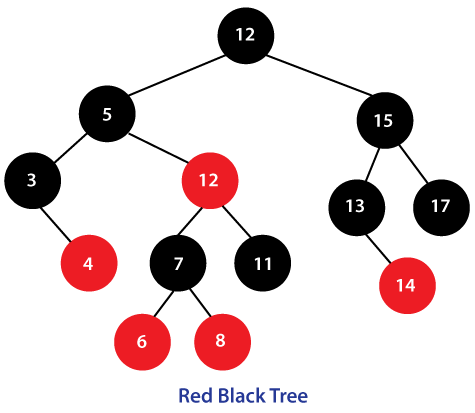
红黑树追求的是大致平衡,查询效率略低于 AVL 树,因为红黑树的平衡性较弱,可能导致树的高度较高,需要多次磁盘 IO 操作。这也是 MySQL 没有选择红黑树的原因之一。但红黑树的插入和删除操作效率高,因为只需进行 O(1) 次数的旋转和变色操作,保持基本平衡状态。
红黑树广泛应用于 TreeMap、TreeSet 和 JDK1.8 的 HashMap 底层,在内存中的表现非常优异。
B树&B+树
B 树也称 B-树,全称为 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和B+ 树中的 B 是 Balanced (平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
B 树&B+ 树两者有何异同呢?
- 存储方式不同
B 树的所有节点既存放键(key)也存放数据(data),而B+树只有叶子节点存放 key 和 data,非叶子节点只存放 key。
- 单点查询稳定性不同
B 树的查询波动较大,因为每个节点既存放索引又存放记录,有时访问到非叶子节点就能找到数据,有时需要访问叶子节点才能找到。
B+ 树的非叶子节点仅存放索引,因此可以存放更多的索引,使得 B+ 树比 B 树更「矮胖」,查询底层节点的磁盘 I/O 次数更少。
- 插入和删除效率不同
- 在B树中,当内部节点需要删除或插入时,可能会涉及到多个子节点的调整。由于B树的非叶子节点也存储数据,因此分裂或合并操作需要确保数据的完整性和树的平衡。
- 相比之下,B+树的非叶子节点只存储键信息,不存储实际的数据。因此,在分裂或合并非叶子节点时,只需要处理键信息,这使得操作相对简单且高效。并且,B+树的叶子节点包含所有实际的数据,并且它们之间通过指针相连。这使得在删除节点时,可以更容易地重新组织数据以保持树的平衡。
- 范围查询效率不同
B+ 树支持范围查询。进行范围查找时,从根节点遍历到叶子节点即可,因为数据都存储在叶子节点上,且叶子节点通过指针连接,便于范围查找。
3.索引的类型
按照底层存储方式角度划分:
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,只有InnoDB 中的主键索引属于聚簇索引。
- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
按照应用维度划分:
主键索引
加速查询 + 列值唯一 + 不可以有NULL + 表中只有一个。
CREATE TABLE tb_user (
id INT PRIMARY KEY,
name VARCHAR(50)
);普通索引
加速查询 + 列值可以重复 + 可以有NULL。
CREATE INDEX idx_name ON tb_user(name);唯一索引
加速查询 + 列值唯一 + 可以有NULL。
CREATE UNIQUE INDEX idx_email ON tb_user(email);联合索引
多个列组成一个索引,专门用于组合搜索,其效率大于多个单列索引的合并效率。
CREATE INDEX idx_cover ON tb_user(name, email);覆盖索引
一个索引包含所有需要查询的字段的值。
CREATE INDEX idx_cover ON tb_user(name, email);
SELECT name, email FROM tb_user WHERE name = 'John';全文索引
对文本的内容进行分词,进行搜索。目前只有 CHAR、VARCHAR ,TEXT 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT (title, content)
);
- 点赞
- 收藏
- 关注作者
评论(0)