并发编程基础_05

1.CPU 密集型
CPU 密集型:CPU 密集型也叫计算密集型,指的是系统的硬盘、内存性能相对 CPU 要好很多,此时,系统运作大部分的状况是 CPU Loading 100%,CPU 要读/写 I/O(硬盘/内存),I/O 在很短的时间就可以完成,而 CPU 还有许多运算要处理,CPU Loading 很高。
2.I/O 密集型
I/O 密集型:IO 密集型指的是系统的 CPU 性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写操作,此时 CPU Loading 并不高。
3.线程池与密集型关系
线程池与 CPU 密集型的关系:
一般情况下,CPU 核心数 == 最大同时执行线程数.在这种情况下(设 CPU 核心数为 n),大量客户端会发送请求到服务器,但是服务器最多只能同时执行 n 个线程.设线程池工作队列长度为 m,且 m>>n,则此时会导致 CPU 频繁切换线程来执行(如果 CPU 使用的是 FCFS,则不会频繁切换,如使用的是其他 CPU 调度算法,如时间片轮转法,最短时间优先,则可能会导致频繁的线程切换).所以这种情况下,无需设置过大的线程池工作队列,(工作队列长度 = CPU 核心数 || CPU 核心数+1) 即可.
与 I/O 密集型的关系:
1 个线程对应 1 个方法栈,线程的生命周期与方法栈相同.比如某个线程的方法栈对应的入站顺序为:controller()->service()->DAO(),由于 DAO 长时间的 I/O 操作,导致该线程一直处于工作队列,但它又不占用 CPU,则此时有 1 个 CPU 是处于空闲状态的.所以,这种情况下,应该加大线程池工作队列的长度(如果 CPU 调度算法使用的是 FCFS,则无法切换),尽量不让 CPU 空闲下来,提高 CPU 利用率
4.如何设置核心线程数和最大线程数?
-
需要进行压测
-
并发访问量是多大
-
不要用无界队列,且有界队列的最大值要合理
-
充分利用 cpu
- 一个线程处理计算型,100%
- 50%计算型,需要 2 个线程
- 25%计算型,需要 4 个线程
- 多任务操作系统,对 CPU 都是分时使用的:比如 A 任务占用 10ms,然后 B 任务占用 30ms,然后空闲 60ms,再又是 A 任务占 10ms, B 任务占 30ms,空闲 60ms;如果在一段时间内都是如此,那么这段时间内的利用率为 40%,因为整个系统中只有 40%的时间是 CPU 处理数据的时间。
-
任务的性质:CPU 密集型任务、lO 密集型任务和混合型任务。
- CPU 密集型要设置尽量少的线程数
- IO 密集型要设置尽量多的线程数
-
任务的优先级:高、中和低。
- 使用优先队列
- 建议使用有界队列,且数量合理
-
任务的执行时间:
-
长
-
中
-
短
-
-
任务的依赖性:
- 是否依赖其他系统资源,如数据库连接。
- CPU 空闲时间越长,线程数应该设置的越大,更好的利用 CPU
5.CPU 飙升 100%?
发现程序 CPU 飙升 100%,内存和 I/O 利用正常,是什么原因?如何排查?
原因:死锁
排查: dump 线程数据
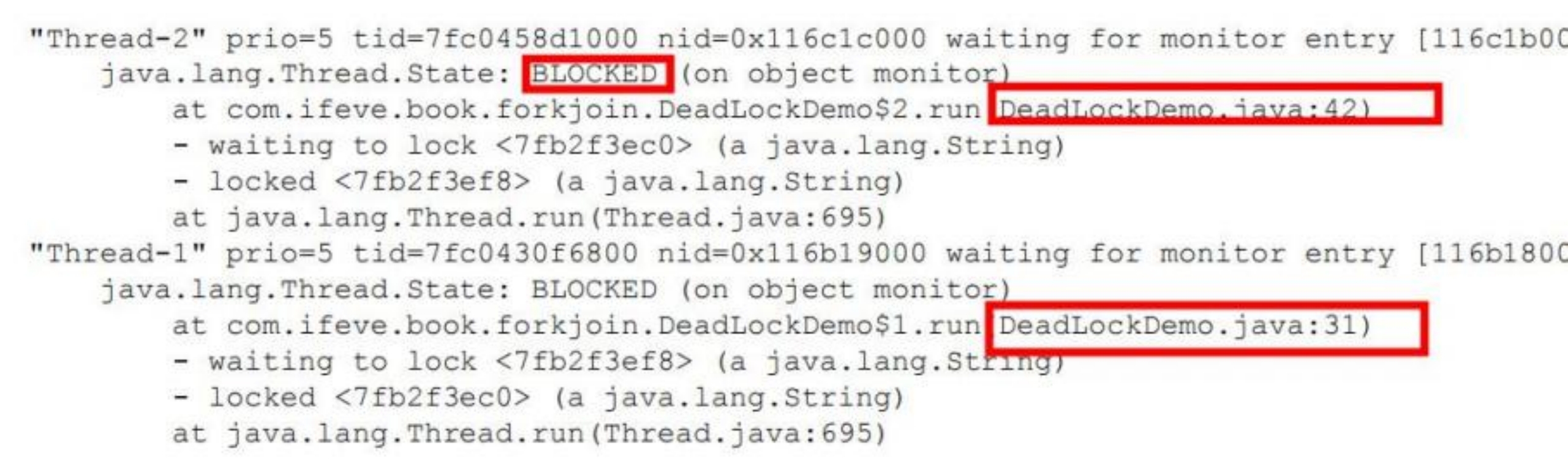
6.什么情况下单线程比多线程快?
redis 是单线程的,redis 为什么快?
首先分配 cpu 资源的单位是进程。一个进程所获得到的 cpu 资源是一定的。程序在执行的过程中消耗的是 cpu,比如一个单核 cpu,多个线程同时执行工作时,需要不断切换执行(上下文切换),单个线程时间耗费更多了,而单线程只是一个线程跑。
先来解释一下什么是上下文切换。在多任务处理系统中,作业数通常大于 CPU 数。为了让用户觉得这些任务在同时进行,CPU 给每个任务分配一定时间,把当前任务状态保存下来,当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。之后 CPU 可以回过头再处理之前被挂起任务。上下文切换就是这样一个过程,它允许 CPU 记录并恢复各种正在运行程序的状态,使它能够完成切换操作。在这个过程中,CPU 会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。
总结:线程切换是有开销的,这会导致程序运行变慢。所以单线程比多线程的运行速度更快。
7.伪共享内存顺序冲突?
什么是伪共享内存顺序冲突?如何避免?
由于存放到 CPU 缓存行的是内存块而不是单个变量,所以可能会把多个变量存放到同一个缓存行中,当多个线程同时修改这个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,此时有两个线程同时修改同一个缓存行下的两个不同的变量,这就是伪共享,也称内存顺序冲突。当出现伪共享时,CPU 必须清空流水线,会造成 CPU 比较大的开销。
如何避免:JDK1.8 之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中,例如如下代码:
public final static class FilledLong{
public volatile long value=0L;
public long pl,p2,p3,p4,p5,p6;
}
假如缓存行为 64 字节,那么我们在 FilledLong 类里填充了 6 个 long 类型的变量,一个 long 类型变量占用 8 字节,加上自己的 value 变量占用的 8 个字节,总共 56 字节.另外,这里 FilledLong 是一个类对象,而类对象的字节码的对象头占用 8 字节,所以一个 FilledLong 对象实际会占用 64 字节的内存,这正好可以放入同一个缓存行。
JDK 提供了 sun.misc Contended 注解,用来解决伪共享问题.将上面代码修改为如下。
@sun.misc.Contended
public final static class FilledLong{
public volatile longvalue=0L;
}
特别注意
在默认情况下,@Contended 注解只用于 Java 核心类,比如 rt 包下的类。如果用户类路径下的类需要使用这个注解,需要添加 JVM 参数:- XX:-RestrictContended.填充的宽度默认为 128,要自定义填充宽度则可以通过参数-XX:ContendedPaddingWidth 参数进行设置。
8.双重检查锁的单例模式
public class Juc_book_fang_11_Dcl {
private static volatile Person instance;
public static Person getInstance(){
if (instance == null){//步骤一
synchronized (Juc_book_fang_11_Dcl.class){//步骤二
if (instance == null){//步骤三
instance = new Person();//步骤四
}
return instance;
}
}
return instance;
}
}
看着图中的注释,假设线程 A 执行 getInstance 方法
步骤一: instance 为 null,则进入 if 判断;
步骤二:获取 synchronized 锁,成功,进入同步代码块;
步骤三:继续判断 instance,为 null 则进入 if 判断;
步骤四: instance = new Instance().看似是一句代码,其实是三句代码。
memory=allocate(); //1:分配对象的内存空间
ctorInstance(memory);//2:初始化对象
instance=memory; //3:设置instance指向刚分配的内存地址
上面 2 和 3 两者没有依赖关系,设置 instance 指向刚分配的内存地址和初始化对象会存在重排序.
使用 volatile 并不会解决 2 和 3 的重排序问题,因为 2 和 3 都在一个 new指令里面,内存屏障是针对指令级别的重排序,双重检查锁 volatile 禁止重排序的原理,new 指令是单一指令,也就是前面加 StoreStore 屏障,后面加 StoreLoad 屏障,后面的线程必不会读到 instance 为 null
有 2 种解决方案:
-
使用 volatile 禁止重排序,原理还是其他线程不可见
-
允许 2 和 3 重排序,但是不允许其他线程可见
- 基于类初始化
- CLASS 对象的初始化锁只能有一个线程访问,对其他线程不可见
基于类的初始化:
public class InstanceFactory {
private static class InstanceHolder {
public static Instance instance=new Instance();
}
public static Instance getinstance() {
return InstanceHolder.instance; // 这里将导致InstanceHolder类被初始化
}
}
java 中,一个类或接口类型 T 将被立即初始化的情况如下
-
T 是一个类,而且一个 T 类型的实例被创建。
-
T 是一个类,且 T 中声明的一个静态方法被调用。
-
T 中声明的一个静态字段被赋值。
-
T 中声明的一个静态字段被使用,而且这个字段不是一个常量字段。
-
T 是一个顶级类(TopLevelClass,见 Java 语言规范的§7.6),而且一个断言语句嵌套在 T 内部被执行。
在示例代码中,首次执行 getlnstance)方法的线程将导致 InstanceHolder 类被初始化(符合情况 4)。
9.long 和 double 的非原子性协定
Java 内存模型要求 lock、unlock、read、load、assign、use、store、write 这 8 个操作都具有原子性,但是对于 64 位的数据类型(double、long)定义了相对宽松的规定:允许虚拟机将没有被 volatile 修饰的 64 位数据的读写操作划分为两次的 32 位操作来进行,即允许虚拟机可以不保证 64 位数据类型的 load、store、read 和 write 操作的原子性。
非原子性协定可能导致的问题:
如果有多个线程共享一个未申明为 volatile 的 long 或 double 类型的变量,并且同时对其进行读取和修改操作,就有可能会有线程读取到"半个变量"的数值或者是一半正确一半错误的失效数据。
在实际应用中的解决:
因为上述可能造成的问题,势必在对 long 和 double 类型变量操作时要加上 volatile 关键字,实际上如下:
1、64 位的 java 虚拟机不存在这个问题,可以操作 64 位的数据
2、目前商用 JVM 基本上都会将 64 位数据的操作作为原子操作实现
所以我们编写代码时一般不需要将 long 和 double 变量专门申明为 volatile
10.CompletableFuture 使用
List<CompletableFuture<UserMessage>> futures = new ArrayList<>();
for (int i = 0; i < 1; i++) {
CompletableFuture<UserMessage> future = CompletableFuture.supplyAsync(() -> this.submitAnswerByTitle(id, title));
futures.add(future);
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.thenAccept(v -> {
for (CompletableFuture<UserMessage> future : futures) {
try {
UserMessage userMessage = future.get();
// 处理任务的返回结果
// ...
} catch (InterruptedException | ExecutionException e) {
// 处理异常
// ...
}
}
}).join();

- 点赞
- 收藏
- 关注作者
评论(0)